




Cisco Data Center Infrastructure 2.5 Design Guide
Server Cluster Designs with Ethernet
een overzicht op hoog niveau van de servers en netwerkcomponenten die worden gebruikt in het server cluster model wordt gegeven in Hoofdstuk 1 “Data Center Architecture Overview.”Dit hoofdstuk beschrijft het doel en de functie van elke laag van het serverclustermodel in meer detail. De volgende secties zijn opgenomen:
•![]() Technische Doelstellingen
Technische Doelstellingen
•![]() Verspreid Doorsturen en Latency
Verspreid Doorsturen en Latency
•![]() Gelijke Kosten Multi-Pad Routering
Gelijke Kosten Multi-Pad Routering
•![]() Server Cluster Ontwerp—Two-Tier Model
Server Cluster Ontwerp—Two-Tier Model
•![]() Server Cluster Ontwerp—Three-Tier Model
Server Cluster Ontwerp—Three-Tier Model
•![]() Aanbevolen Hardware en Modules
Aanbevolen Hardware en Modules

Opmerking ![]() De design-modellen die in dit hoofdstuk niet volledig geverifieerd in het Cisco laboratorium testen vanwege de omvang en reikwijdte van het onderzoek dat nodig zou zijn. De twee-tier modellen die worden gedekt zijn soortgelijke ontwerpen die zijn geïmplementeerd in de klant productie netwerken.
De design-modellen die in dit hoofdstuk niet volledig geverifieerd in het Cisco laboratorium testen vanwege de omvang en reikwijdte van het onderzoek dat nodig zou zijn. De twee-tier modellen die worden gedekt zijn soortgelijke ontwerpen die zijn geïmplementeerd in de klant productie netwerken.
technische doelstellingen
bij het ontwerpen van een clusternetwerk voor grote ondernemingen is het van cruciaal belang specifieke doelstellingen te overwegen. Geen twee clusters zijn precies hetzelfde; elk heeft zijn eigen specifieke eisen en moet worden onderzocht vanuit een toepassingsperspectief om de specifieke ontwerpvereisten te bepalen. Houd rekening met de volgende technische overwegingen:
•![]() Latency-in het netwerktransport kan latency een negatieve invloed hebben op de algehele clusterprestaties. Het gebruik van switching platforms die gebruik maken van een low-latency switching architectuur helpt om optimale prestaties te garanderen. De belangrijkste bron van latency is de protocol stack en Nic hardware implementatie die op de server wordt gebruikt. Driver optimalisatie en CPU offload technieken, zoals TCP Offload Engine (TOE) en Remote Direct Memory Access (RDMA), kunnen helpen latency te verminderen en de verwerking overhead op de server te verminderen.
Latency-in het netwerktransport kan latency een negatieve invloed hebben op de algehele clusterprestaties. Het gebruik van switching platforms die gebruik maken van een low-latency switching architectuur helpt om optimale prestaties te garanderen. De belangrijkste bron van latency is de protocol stack en Nic hardware implementatie die op de server wordt gebruikt. Driver optimalisatie en CPU offload technieken, zoals TCP Offload Engine (TOE) en Remote Direct Memory Access (RDMA), kunnen helpen latency te verminderen en de verwerking overhead op de server te verminderen.
latentie is misschien niet altijd een kritieke factor in het clusterontwerp. Sommige clusters vereisen bijvoorbeeld een hoge bandbreedte tussen servers vanwege een grote hoeveelheid bestandsoverdracht in bulk, maar zijn mogelijk niet sterk afhankelijk van IPC-berichten (server-to-server Inter-Process Communication), wat kan worden beïnvloed door hoge latency.
•![]() Mesh / gedeeltelijke mesh connectiviteit-Server cluster ontwerpen vereisen meestal een mesh of gedeeltelijke mesh weefsel om communicatie tussen alle knooppunten in het cluster mogelijk te maken. Dit mesh-weefsel wordt gebruikt om staat, gegevens en andere informatie te delen tussen master-to-compute-en compute-to-compute-servers in het cluster. Mesh of gedeeltelijke mesh connectiviteit is ook applicatie-afhankelijk.
Mesh / gedeeltelijke mesh connectiviteit-Server cluster ontwerpen vereisen meestal een mesh of gedeeltelijke mesh weefsel om communicatie tussen alle knooppunten in het cluster mogelijk te maken. Dit mesh-weefsel wordt gebruikt om staat, gegevens en andere informatie te delen tussen master-to-compute-en compute-to-compute-servers in het cluster. Mesh of gedeeltelijke mesh connectiviteit is ook applicatie-afhankelijk.
•![]() hoge doorvoer-de mogelijkheid om een groot bestand in een bepaalde tijd te verzenden kan van cruciaal belang zijn voor clusterwerking en prestaties. Serverclusters vereisen doorgaans een minimale hoeveelheid beschikbare niet-blokkerende bandbreedte, wat zich vertaalt in een model met een lage oversubscriptie tussen de Access-en core-lagen.
hoge doorvoer-de mogelijkheid om een groot bestand in een bepaalde tijd te verzenden kan van cruciaal belang zijn voor clusterwerking en prestaties. Serverclusters vereisen doorgaans een minimale hoeveelheid beschikbare niet-blokkerende bandbreedte, wat zich vertaalt in een model met een lage oversubscriptie tussen de Access-en core-lagen.
•![]() Oversubscriptie ratio-de oversubscriptie ratio moet worden onderzocht op meerdere aggregatiepunten in het ontwerp, met inbegrip van de lijnkaart om stof bandbreedte te schakelen en de schakelaar stof input uplink bandbreedte.
Oversubscriptie ratio-de oversubscriptie ratio moet worden onderzocht op meerdere aggregatiepunten in het ontwerp, met inbegrip van de lijnkaart om stof bandbreedte te schakelen en de schakelaar stof input uplink bandbreedte.
•![]() Jumbo frame ondersteuning – hoewel jumbo frames misschien niet worden gebruikt bij de eerste implementatie van een servercluster, is het een zeer belangrijke functie die nodig is voor extra flexibiliteit of voor mogelijke toekomstige vereisten. De TCP / IP pakketconstructie plaatst extra overhead op de server CPU. Het gebruik van jumbo frames kan het aantal pakketten verminderen, waardoor deze overhead wordt verminderd.
Jumbo frame ondersteuning – hoewel jumbo frames misschien niet worden gebruikt bij de eerste implementatie van een servercluster, is het een zeer belangrijke functie die nodig is voor extra flexibiliteit of voor mogelijke toekomstige vereisten. De TCP / IP pakketconstructie plaatst extra overhead op de server CPU. Het gebruik van jumbo frames kan het aantal pakketten verminderen, waardoor deze overhead wordt verminderd.
•![]() poortdichtheid-serverclusters moeten mogelijk opschalen naar tienduizenden poorten. Als zodanig vereisen ze platforms met een hoog niveau van pakketschakelprestaties, een grote hoeveelheid switch fabric bandbreedte en een hoge poortdichtheid.
poortdichtheid-serverclusters moeten mogelijk opschalen naar tienduizenden poorten. Als zodanig vereisen ze platforms met een hoog niveau van pakketschakelprestaties, een grote hoeveelheid switch fabric bandbreedte en een hoge poortdichtheid.
Distributed Forwarding en Latency
de Cisco Catalyst 6500 serie switch heeft de unieke mogelijkheid om een centrale pakketdoorsturing of optionele gedistribueerde doorstuurarchitectuur te ondersteunen, terwijl de Cisco Catalyst 4948-10GE een enkel centraal ASIC ontwerp is met vaste doorstuurprestaties. De Cisco 6700 line card modules ondersteunen een optionele dochter kaart module genaamd een Distributed Forwarding Card (DFC). De DFC maakt het mogelijk om lokale routeringsbeslissingen te nemen op elke lijnkaart door een local Forwarding Information Base (FIB) te implementeren. De FIB-tabel op de Sup720 PFC onderhoudt synchronisatie met elke DFC-Fib-tabel op de lijnkaarten om de integriteit van de routering over het hele systeem te garanderen.
wanneer de optionele DFC-kaart niet aanwezig is, wordt een compact-header-lookup naar de PFC3 op de Sup720 gestuurd om te bepalen waar op de schakelstof elk pakket moet worden doorgestuurd. Wanneer er een DFC aanwezig is, kan de line card een pakket direct over de switch fabric naar de destination line card schakelen zonder de Sup720 te raadplegen. Het prestatieverschil kan variëren van 30 Mpps systeembrede zonder DFCs tot 48 Mpps per sleuf met DFCs. De vaste configuratie Catalyst 4948-10GE switch heeft een draadsnelheid, non-blocking architectuur ondersteunt tot 101.18 MPP prestaties, het verstrekken van superieure access layer prestaties voor top van rack ontwerpen.
Latency prestaties kunnen aanzienlijk variëren bij het vergelijken van de gedistribueerde en centrale forwarding modellen. Tabel 3-1 geeft een voorbeeld van latencies gemeten over een 6704 lijnkaart met en zonder DFC ‘ s.
| 6704 met DFC (Poort-tot-Poort in Microseconden door Switch Fabric) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Pakket afmetingen (B) |
||||||||||
|
Latency (ms) |
||||||||||
| 6704 zonder DFC (Poort-tot-Poort in Microseconden door Switch Fabric) | ||||||||||
|
Pakket afmetingen (B) |
||||||||||
|
Latency (ms) |
||||||||||
Het verschil in vertraging tussen een DFC-en ingeschakeld niet-DFC-ingeschakelde lijnkaart lijkt mogelijk niet significant. Echter, in een 6500 centrale forwarding architectuur, latency kan toenemen als de verkeerstarieven stijgen als gevolg van de stelling voor de gedeelde lookup op de centrale bus. Met een DFC wordt het opzoekpad toegewezen aan elke regelkaart en is de latentie constant.
Catalyst 6500 systeembandbreedte
de beschikbare systeembandbreedte verandert niet wanneer DFK ‘ s worden gebruikt. De DFCs verbeteren de packets per seconde (pps) verwerking van het totale systeem. Tabel 3-2 geeft een overzicht van de doorvoer en bandbreedteprestaties voor modules die DFC ‘ s ondersteunen, naast de oudere CEF256-en klassieke busmodules.
| Systeem Configuratie met Sup720 | Doorvoer in Mpps | Bandbreedte in Gbps |
|
Classic serie modules |
Tot 15 Mpps (per systeem) |
16 G gedeelde bus (classic-bus) |
|
CEF256 Serie modules |
tot 30 Mpps (per systeem) |
1x 8 G (gewijd per slot) |
|
Mix van klassiek met CEF256 of CEF720 Serie modules |
tot 15 Mpps (per systeem) |
afhankelijk Kaart |
|
CEF720 Serie modules (6748, 6704, 6724) |
tot 30 Mpps (per systeem) |
2x 20 G (gewijd per slot) |
|
CEF720 Serie modules met DFC3 (6704 met DFC3, 6708 met DFC3, 6748 met DFC3 6724+DFC3) |
Steunen tot 48 MPP ‘ s (per slot) |
2x 20 G (gewijd per sleuf) |
hoewel de 6513 een geldige oplossing zou kunnen zijn voor de toegangslaag van het grote clustermodel, merk op dat er een mengsel van enkele en dubbele kanaalsleuven in dit chassis is. Slots 1 tot en met 8 zijn enkelkanaals en slots 9 tot en met 13 zijn dubbelkanaals, zoals weergegeven in Figuur 3-1.
figuur 3-1 Catalyst 6500 Fabric Channels per Chassis en Slot (6513 Focus
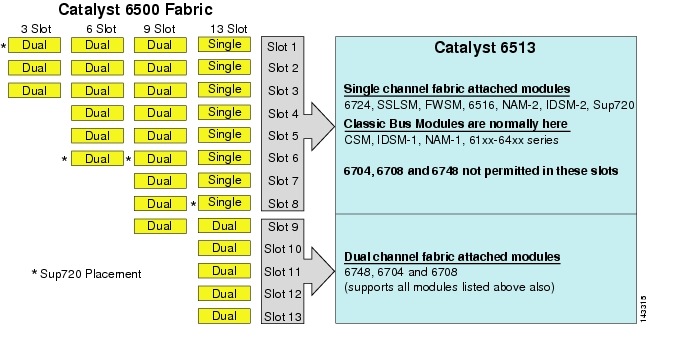
wanneer een Cisco Catalyst 6513 wordt gebruikt, kunnen de dual channel kaarten, zoals de 6704-4 poort 10GigE, de 6708 – 8 poort 10GigE, en de 6748-48 poort SFP/copper line kaarten alleen in slots 9 tot 13 worden geplaatst. De single channel line kaarten zoals de 6724-24 poort SFP / copper line kaarten kunnen worden gebruikt in sleuven 1 tot 8. De Sup720 maakt gebruik van sleuven 7 en 8, die een kanaal 20G stof bevestigd. In tegenstelling tot de 6513, de 6509 heeft minder beschikbare slots, maar kan ondersteuning bieden voor dual channel modules in alle slots, omdat elke sleuf heeft twee kanalen naar de schakelaar Weefsel.
Note ![]() omdat de serverclusteromgeving gewoonlijk een hoge bandbreedte met lage latency-kenmerken vereist, raden we aan om DFC ‘ s in dit soort ontwerpen te gebruiken.
omdat de serverclusteromgeving gewoonlijk een hoge bandbreedte met lage latency-kenmerken vereist, raden we aan om DFC ‘ s in dit soort ontwerpen te gebruiken.
Equal Cost Multi-Path Routing
Equal cost multi-path routing (Ecmp) is een load balancing-technologie die stromen optimaliseert over meerdere IP-paden tussen twee subnetten in een Cisco Express Forwarding-omgeving. ECMP past load balancing toe voor TCP-en UDP-pakketten op een per-flow basis. Niet-TCP/UDP-pakketten, zoals ICMP, worden per pakket verdeeld. ECMP is gebaseerd op RFC 2991 en wordt gebruikt op andere Cisco-platforms, zoals de PIX-en Cisco Content Services switch (CSS) – producten. ECMP wordt ondersteund op zowel de 6500-als 4948-10GE-platforms die worden aanbevolen in het serverclusterontwerp.
de dramatische veranderingen die het gevolg zijn van Asics en Cisco Express Forwarding hashing-algoritmen van Layer 3-hardware helpen om ECMP te onderscheiden van zijn voorganger technologieën. Het belangrijkste voordeel van een ECMP-ontwerp voor serverclusterimplementaties is het hashing-algoritme gecombineerd met weinig tot geen CPU-overhead in Layer 3-switching. Het Cisco Express Forwarding hashing-algoritme is in staat om granulaire stromen over meerdere lijnkaarten te distribueren met lijnsnelheid in hardware. De standaardinstelling hashing algoritme is om hash stromen op basis van Layer 3 bron-bestemming IP-adressen, en optioneel het toevoegen van Layer 4 poortnummers voor een extra laag van differentiatie. Het maximum aantal toegestane ECMP-paden is acht.
figuur 3-2 illustreert een 8-weg ECMP-serverclusterontwerp. Om de illustratie te vereenvoudigen, worden slechts twee access layer switches getoond, maar tot 32 kunnen worden ondersteund (64 10GigEs per core node).
figuur 3-2 ECMP-Serverclusterontwerp met 8 richtingen
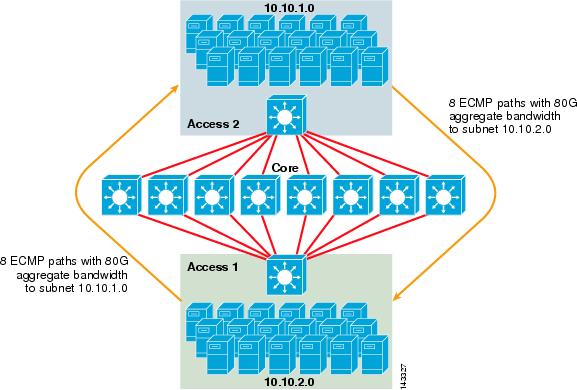
in Figuur 3-2 kan elke schakelaar voor toegangslaag een of meer subnetten van aangesloten servers ondersteunen. Elke schakelaar heeft een enkele 10gige verbinding met elk van de acht kernschakelaars met behulp van twee 6704 lijnkaarten. Deze configuratie biedt acht paden van 10GigE voor een totaal van 80 G Cisco Express Forwarding-enabled bandbreedte naar elk ander subnet in de server cluster Weefsel. Een show ip route query naar een ander subnet op een andere switch toont acht gelijke kosten inzendingen.
de kern is gevuld met 10gige lijnkaarten met DFC ‘ s om een volledig gedistribueerde snelle schakelstof met een zeer lage latentie tussen poorten mogelijk te maken. Een show ip route query naar een access layer switch toont een enkele route ingang op elk van de acht core switches.
opmerking ![]() hoewel het niet is getest voor deze gids, is er een nieuwe 8-poort 10 Gigabit Ethernet module (WS-X6708-10G-3C) die onlangs is geïntroduceerd voor de Catalyst 6500 serie switch. Deze lijnkaart zal worden getest voor opname in deze gids op een later tijdstip. Voor vragen over de 8-port 10gige kaart, zie het product data sheet.
hoewel het niet is getest voor deze gids, is er een nieuwe 8-poort 10 Gigabit Ethernet module (WS-X6708-10G-3C) die onlangs is geïntroduceerd voor de Catalyst 6500 serie switch. Deze lijnkaart zal worden getest voor opname in deze gids op een later tijdstip. Voor vragen over de 8-port 10gige kaart, zie het product data sheet.
redundantie in het Serverclusterontwerp
het serverclusterontwerp wordt doorgaans Niet geïmplementeerd met redundante CPU-of switch fabric-processors. Veerkracht wordt typisch inherent bereikt in het ontwerp en door de methode die het cluster als geheel functioneert. Zoals beschreven in Hoofdstuk 1 “overzicht van de datacenterarchitectuur” worden de rekenknooppunten in het cluster beheerd door masterknooppunten die verantwoordelijk zijn voor het toewijzen van specifieke taken aan elk rekenknooppunt en het bewaken van hun prestaties. Als een compute-knooppunt uit het cluster valt, wordt het opnieuw toegewezen aan een Beschikbaar knooppunt en blijft het werken, zij het met minder rekenkracht, totdat het knooppunt beschikbaar is. Hoewel het belangrijk is om de hoofdknooppuntverbindingen in het cluster te diversifiëren over verschillende toegangsschakelaars, is dit niet van cruciaal belang voor de rekenknooppunten.
hoewel redundante CPU ‘ s zeker optioneel zijn, is het belangrijk om poortdichtheid te overwegen, met name voor 10GE-poorten, waar een extra slot beschikbaar is in plaats van een redundante Sup720-module.
opmerking ![]() de voorbeelden in dit hoofdstuk maken gebruik van niet-redundante CPU-ontwerpen, die maximaal 64 10GE-poorten per 6509 core node mogelijk maken die beschikbaar zijn voor toegangsknooppunten uplinkverbindingen op basis van het gebruik van een 6708 8-poorts 10gige lijnkaart.
de voorbeelden in dit hoofdstuk maken gebruik van niet-redundante CPU-ontwerpen, die maximaal 64 10GE-poorten per 6509 core node mogelijk maken die beschikbaar zijn voor toegangsknooppunten uplinkverbindingen op basis van het gebruik van een 6708 8-poorts 10gige lijnkaart.
Server Cluster Design—Two-Tier Model
dit gedeelte beschrijft de verschillende benaderingen van een server cluster design die ECMP en gedistribueerde CEF gebruikt. Elk ontwerp laat zien hoe verschillende configuraties verschillende overinschrijvingsniveaus kunnen bereiken en op een flexibele manier kunnen schalen, te beginnen met een paar knooppunten en te groeien tot vele die duizenden servers ondersteunen.
het serverclusterontwerp volgt doorgaans een twee-tiermodel dat bestaat uit kern-en toegangslagen. Omdat de ontwerpdoelstellingen het gebruik van laag 3 ECMP en gedistribueerde forwarding vereisen om een zeer deterministische bandbreedte en latentie per server te bereiken, is een drie-tier model dat een ander punt van overscriptie introduceert meestal niet wenselijk. De voordelen van een three-tier model worden beschreven in Server Cluster Design-Three-Tier Model.
de drie belangrijkste berekeningen waarmee rekening moet worden gehouden bij het ontwerpen van een serverclusteroplossing zijn maximale serververbindingen, bandbreedte per server en oversubscriptieverhouding. Clusterontwerpers kunnen deze waarden bepalen op basis van de prestaties van toepassingen, serverhardware en andere factoren, waaronder de volgende::
•![]() Maximum aantal server GigE verbindingen op schaal-Cluster ontwerpers hebben meestal een idee van de maximale schaal vereist bij het eerste concept. Een voordeel van de manier waarop ECMP ontwerpt, is dat ze kunnen beginnen met een minimaal aantal switches en servers die voldoen aan een bepaalde bandbreedte -, latency-en oversubscriptievereisten, en flexibel kunnen groeien op een lage/niet-verstorende manier tot maximale schaal met behoud van dezelfde bandbreedte -, latency-en oversubscriptiewaarden.
Maximum aantal server GigE verbindingen op schaal-Cluster ontwerpers hebben meestal een idee van de maximale schaal vereist bij het eerste concept. Een voordeel van de manier waarop ECMP ontwerpt, is dat ze kunnen beginnen met een minimaal aantal switches en servers die voldoen aan een bepaalde bandbreedte -, latency-en oversubscriptievereisten, en flexibel kunnen groeien op een lage/niet-verstorende manier tot maximale schaal met behoud van dezelfde bandbreedte -, latency-en oversubscriptiewaarden.
•![]() geschatte bandbreedte per server-deze waarde kan worden bepaald door simpelweg de totale geaggregeerde uplinkbandbreedte te delen door de totale server GigE-verbindingen op de access layer-switch. Bijvoorbeeld, een access layer Cisco 6509 met vier 10GIGE ECMP uplinks met 336 Server toegangspoorten kan als volgt worden berekend:
geschatte bandbreedte per server-deze waarde kan worden bepaald door simpelweg de totale geaggregeerde uplinkbandbreedte te delen door de totale server GigE-verbindingen op de access layer-switch. Bijvoorbeeld, een access layer Cisco 6509 met vier 10GIGE ECMP uplinks met 336 Server toegangspoorten kan als volgt worden berekend:
4x10GigE Uplinks met 336 servers = 120 Mbps per server
het aanpassen van beide zijden van de vergelijking vermindert of verhoogt de hoeveelheid bandbreedte per server.
Noot ![]() Dit is slechts een benaderende waarde en dient alleen als richtlijn. Verschillende factoren beïnvloeden de werkelijke hoeveelheid bandbreedte die elke server beschikbaar heeft. Het ecmp load-distribution hash algoritme verdeelt belasting op basis van laag 3 plus laag 4 waarden en varieert op basis van verkeerspatronen. Ook kunnen configuratieparameters zoals snelheidsbeperking, wachtrij en QoS-waarden de daadwerkelijk bereikte bandbreedte per server beïnvloeden.
Dit is slechts een benaderende waarde en dient alleen als richtlijn. Verschillende factoren beïnvloeden de werkelijke hoeveelheid bandbreedte die elke server beschikbaar heeft. Het ecmp load-distribution hash algoritme verdeelt belasting op basis van laag 3 plus laag 4 waarden en varieert op basis van verkeerspatronen. Ook kunnen configuratieparameters zoals snelheidsbeperking, wachtrij en QoS-waarden de daadwerkelijk bereikte bandbreedte per server beïnvloeden.
•![]() Overabonnement ratio per server-deze waarde kan worden bepaald door simpelweg het totale aantal server GigE verbindingen te delen door de totale geaggregeerde uplink bandbreedte op de access layer switch. Bijvoorbeeld, een access layer 6509 met vier 10GIGE ECMP uplinks met 336 Server toegangspoorten kan als volgt worden berekend:
Overabonnement ratio per server-deze waarde kan worden bepaald door simpelweg het totale aantal server GigE verbindingen te delen door de totale geaggregeerde uplink bandbreedte op de access layer switch. Bijvoorbeeld, een access layer 6509 met vier 10GIGE ECMP uplinks met 336 Server toegangspoorten kan als volgt worden berekend:
336 GigE server verbindingen met 40G uplink bandwidth = 8.4: 1 oversubscriptie ratio
de volgende secties laten zien hoe deze waarden variëren, gebaseerd op verschillende hardware en interconnectie configuraties, en dienen als richtlijn bij het ontwerpen van grote cluster configuraties.
Noot ![]() voor de berekening wordt ervan uitgegaan dat er geen lijnkaart is om de stofoversubscriptie op de schakelaar van de Catalyst 6500-serie over te schakelen. De dual channel sleuf biedt 40G maximale bandbreedte aan de schakelstof. Een 4-poorts 10gige kaart met alle poorten op lijnsnelheid met maximale grootte pakketten wordt beschouwd als de best mogelijke voorwaarde met weinig of geen overabscriptie. De werkelijke hoeveelheid beschikbare switch fabric bandbreedte varieert, gebaseerd op de gemiddelde pakketgroottes. Deze berekeningen zouden opnieuw berekend moeten worden als je de WS-X6708 8-port 10GigE kaart zou gebruiken die overgeschreven is op 2:1.
voor de berekening wordt ervan uitgegaan dat er geen lijnkaart is om de stofoversubscriptie op de schakelaar van de Catalyst 6500-serie over te schakelen. De dual channel sleuf biedt 40G maximale bandbreedte aan de schakelstof. Een 4-poorts 10gige kaart met alle poorten op lijnsnelheid met maximale grootte pakketten wordt beschouwd als de best mogelijke voorwaarde met weinig of geen overabscriptie. De werkelijke hoeveelheid beschikbare switch fabric bandbreedte varieert, gebaseerd op de gemiddelde pakketgroottes. Deze berekeningen zouden opnieuw berekend moeten worden als je de WS-X6708 8-port 10GigE kaart zou gebruiken die overgeschreven is op 2:1.
4 – en 8-weg ECMP-ontwerpen met modulaire toegang
de volgende vier ontwerpvoorbeelden demonstreren verschillende methoden voor het bouwen en schalen van het Dual-tier server cluster model met behulp van 4-weg en 8-weg ECMP. De belangrijkste problemen om te overwegen zijn het aantal kernknooppunten en het maximum aantal uplinks, omdat deze direct van invloed zijn op de maximale schaal, bandbreedte per server, en oversubscriptie waarden.
opmerking ![]() hoewel het niet is getest voor deze gids, is er een nieuwe 8-poort 10 Gigabit Ethernet Module (WS-X6708-10G-3C) die onlangs is geïntroduceerd voor de Catalyst 6500 serie switch. Deze lijnkaart zal worden getest voor opname in de gids op een later tijdstip. Voor vragen over de 8-port 10gige kaart, zie het product data sheet.
hoewel het niet is getest voor deze gids, is er een nieuwe 8-poort 10 Gigabit Ethernet Module (WS-X6708-10G-3C) die onlangs is geïntroduceerd voor de Catalyst 6500 serie switch. Deze lijnkaart zal worden getest voor opname in de gids op een later tijdstip. Voor vragen over de 8-port 10gige kaart, zie het product data sheet.
Note ![]() de verbindingen die nodig zijn om het servercluster te verbinden met een netwerk buiten de campus of metro worden niet weergegeven in deze ontwerpvoorbeelden, maar moeten worden overwogen.
de verbindingen die nodig zijn om het servercluster te verbinden met een netwerk buiten de campus of metro worden niet weergegeven in deze ontwerpvoorbeelden, maar moeten worden overwogen.
figuur 3-3 geeft een voorbeeld waarin twee kernknooppunten worden gebruikt om een 4-weg ECMP-oplossing te bieden.
figuur 3-3 4-Weg ECMP met twee Kernknooppunten
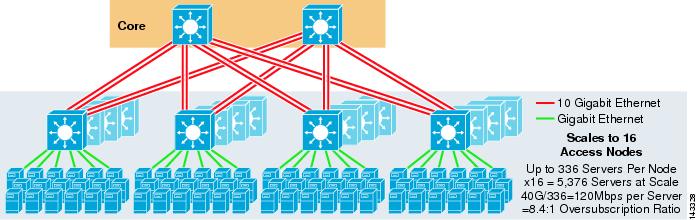
een voordeel van deze aanpak is dat een kleiner aantal kernswitches een groot aantal servers kan ondersteunen. Het mogelijke nadeel is een hoge oversubscriptie-lage bandbreedte per serverwaarde en grote blootstelling aan een kernknooppuntfout. Merk op dat de uplinks individuele L3 uplinks zijn en geen Etherkanalen zijn.
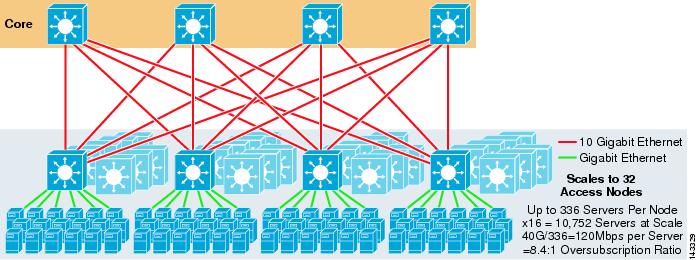
figuur 3-4 laat zien hoe het toevoegen van twee kernknooppunten aan het vorige ontwerp de maximale schaal dramatisch kan verhogen met behoud van dezelfde oversubscriptie en bandbreedte per server waarden.
figuur 3-4 4-Weg ECMP met vier Kernknooppunten
figuur 3-5 toont een 8-weg ECMP-ontwerp met twee kernknooppunten.
figuur 3-5 8-weg ECMP met twee Kernknooppunten
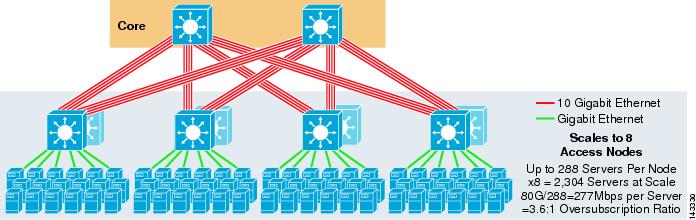
zoals verwacht, verhoogt de extra uplinkbandbreedte de bandbreedte per server aanzienlijk en vermindert de oversubscriptieverhouding per server. Merk op hoe de extra sleuven die in elke access layer switch worden genomen om de 8-weg uplinks te ondersteunen, de maximale schaal vermindert omdat het aantal servers per switch wordt teruggebracht tot 288. Merk op dat de uplinks individuele L3 uplinks zijn en geen Etherkanalen zijn.
figuur 3-6 toont een 8-weg ECMP-ontwerp met acht kernknooppunten.
figuur 3-6 8-weg ECMP met acht Kernknooppunten
dit laat zien hoe het toevoegen van vier kernknooppunten aan hetzelfde vorige ontwerp de maximale schaal drastisch kan verhogen met behoud van dezelfde overabonnement en bandbreedte per server waarden.
2-weg ECMP-ontwerp met 1RU-toegang
in veel clusteromgevingen is rack-based server switching met behulp van kleine switches aan de bovenkant van elk serverrek gewenst of vereist vanwege bekabeling, administratieve problemen, vastgoedproblemen of om te voldoen aan specifieke implementatiemodellen.
figuur 3-7 toont een voorbeeld waarin twee kernknooppunten worden gebruikt om een 2-weg ECMP-oplossing met 1RU 4948-10GE-toegangsschakelaars te leveren.
figuur 3-7 2-weg ECMP met twee Kernknooppunten en 1RU-toegang
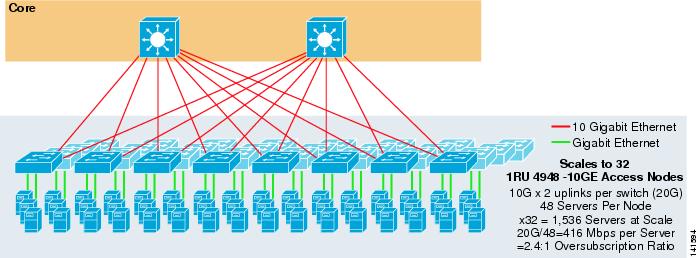
de maximale schaal is beperkt tot 1536 servers, maar biedt meer dan 400 Mbps bandbreedte met een lage oversubscriptieverhouding. Omdat de 4948 slechts twee 10gige uplinks heeft, kan dit ontwerp niet verder schalen dan deze waarden.
Note ![]() meer informatie over serverwisselen op basis van rack is te vinden in hoofdstuk 3 “Serverclusterontwerpen met Ethernet.”
meer informatie over serverwisselen op basis van rack is te vinden in hoofdstuk 3 “Serverclusterontwerpen met Ethernet.”
Server Cluster Design-Three-Tier Model
hoewel een two-tier model het meest voorkomt in grote clusterontwerpen, kan ook een three-tier model worden gebruikt. Het drie-tier model wordt meestal gebruikt voor het ondersteunen van grote server cluster implementaties met behulp van 1RU of modulaire access layer switches.
figuur 3-8 toont een grootschalig voorbeeld van 8-weg ECMP met 6500 kern – en aggregatieschakelaars en 1RU 4948-10GE access layer switches.
figuur 3-8 drie-Tier Model met 8-weg ECMP
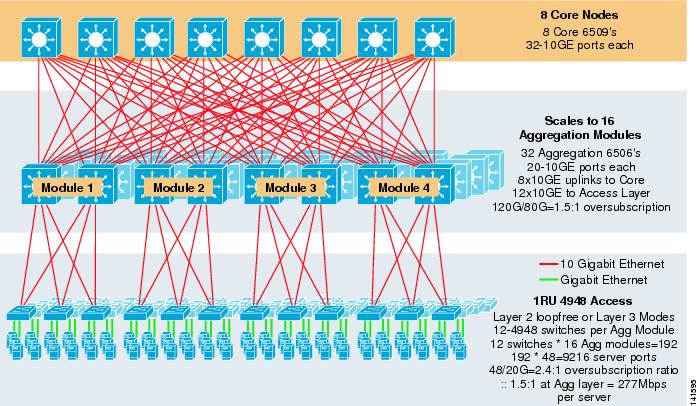
de maximale schaal is meer dan 9200 servers met 277 Mbps bandbreedte met een lage oversubscriptie ratio. Voordelen van de three-tier approach met 1RU access switches zijn onder andere::
•![]() 1RU deployment models-zoals eerder vermeld, vereisen veel grote cluster model implementaties een 1RU aanpak voor vereenvoudigde installatie. Bijvoorbeeld, een ASP rolt racks van servers op een moment als ze schaal grote cluster toepassingen. Het serverrek is voorgemonteerd en offsite geënsceneerd, zodat het snel kan worden geïnstalleerd en aan het actieve cluster kan worden toegevoegd. Meestal gaat het om een derde partij die de racks bouwt, de servers vooraf configureert en ze voorkabelt met stroom en Ethernet naar een 1RU switch. Het rack rolt in het datacenter en wordt eenvoudig aangesloten en toegevoegd aan het cluster na het aansluiten van de uplinks.
1RU deployment models-zoals eerder vermeld, vereisen veel grote cluster model implementaties een 1RU aanpak voor vereenvoudigde installatie. Bijvoorbeeld, een ASP rolt racks van servers op een moment als ze schaal grote cluster toepassingen. Het serverrek is voorgemonteerd en offsite geënsceneerd, zodat het snel kan worden geïnstalleerd en aan het actieve cluster kan worden toegevoegd. Meestal gaat het om een derde partij die de racks bouwt, de servers vooraf configureert en ze voorkabelt met stroom en Ethernet naar een 1RU switch. Het rack rolt in het datacenter en wordt eenvoudig aangesloten en toegevoegd aan het cluster na het aansluiten van de uplinks.
zonder aggregatielaag is de maximale grootte van het 1RU-toegangsmodel beperkt tot iets meer dan 1500 servers. Door een aggregatielaag toe te voegen, kan het 1RU access-model worden geschaald naar een veel groter formaat, terwijl het ECMP-model nog steeds wordt gebruikt.
•![]() centralisatie van kern-en aggregatieschakelaars – met 1RU-schakelaars in de racks is het mogelijk om de grotere kern-en aggregatiemodulaire schakelaars te centraliseren. Dit kan stroom-en bekabelingsinfrastructuur vereenvoudigen en het gebruik van rack real estate verbeteren.
centralisatie van kern-en aggregatieschakelaars – met 1RU-schakelaars in de racks is het mogelijk om de grotere kern-en aggregatiemodulaire schakelaars te centraliseren. Dit kan stroom-en bekabelingsinfrastructuur vereenvoudigen en het gebruik van rack real estate verbeteren.
•![]() laat Layer 2 loop-vrije topologie toe – een groot clusternetwerk dat Layer 3 ECMP-toegang gebruikt, kan veel adresruimte op de uplinks gebruiken en kan complexiteit aan het ontwerp toevoegen. Dit is met name belangrijk als er gebruik wordt gemaakt van Public address space. De drie-tier model aanpak leent zich goed voor een Layer 2 loop-free access topologie die het aantal subnetten vereist vermindert.
laat Layer 2 loop-vrije topologie toe – een groot clusternetwerk dat Layer 3 ECMP-toegang gebruikt, kan veel adresruimte op de uplinks gebruiken en kan complexiteit aan het ontwerp toevoegen. Dit is met name belangrijk als er gebruik wordt gemaakt van Public address space. De drie-tier model aanpak leent zich goed voor een Layer 2 loop-free access topologie die het aantal subnetten vereist vermindert.
wanneer een Layer 2 loop-free model wordt gebruikt, is het belangrijk om een redundant standaard gateway protocol zoals HSRP of GLBP te gebruiken om een enkel storingspunt te elimineren als een aggregatieknooppunt faalt. In dit ontwerp zijn de aggregatiemodules niet onderling verbonden, waardoor een lusvrij Layer 2-ontwerp mogelijk is dat gebruik kan maken van GLBP voor automatische server standaard gateway load balancing. GLBP distribueert automatisch de standaard gateway-toewijzing voor servers tussen de twee knooppunten in de aggregatiemodule. Nadat een pakket bij de aggregatielaag aankomt, wordt het gebalanceerd over de kern met behulp van de 8-weg ECMP-stof. Hoewel GLBP geen Layer 3/Layer 4 load distribution hash bevat die vergelijkbaar is met CEF, is het een alternatief dat gebruikt kan worden met een Layer 2 access topology.
berekening van overinschrijving
het drie-tier-model introduceert twee punten van overinschrijving op de access-en aggregatielagen, in vergelijking met het twee-tier-model dat slechts één punt van overinschrijving op de access-laag heeft. Om de geschatte bandbreedte per server en de oversubscriptieverhouding correct te berekenen, voert u de volgende twee stappen uit, waarbij figuur 3-8 als voorbeeld wordt gebruikt:
Stap 1 ![]() Bereken onafhankelijk van elkaar de oversubscriptieverhouding en de bandbreedte per server voor zowel de aggregatie-als toegangslagen.
Bereken onafhankelijk van elkaar de oversubscriptieverhouding en de bandbreedte per server voor zowel de aggregatie-als toegangslagen.
•![]() Toegang tot laag
Toegang tot laag
–![]() Overinschrijving—48GE verbonden servers/20G uplinks aggregatie = 2.4:1
Overinschrijving—48GE verbonden servers/20G uplinks aggregatie = 2.4:1
–![]() Bandbreedte per server—20G-uplinks aggregatie/48GigE gekoppelde servers = 416Mbps
Bandbreedte per server—20G-uplinks aggregatie/48GigE gekoppelde servers = 416Mbps
•![]() Aggregatie laag
Aggregatie laag
–![]() Overinschrijving—120G downlinks om toegang te krijgen tot/80G uplinks naar de kern = 1.5:1
Overinschrijving—120G downlinks om toegang te krijgen tot/80G uplinks naar de kern = 1.5:1
Stap 2 ![]() Bereken de gecombineerde overinschrijving ratio en bandbreedte per server.
Bereken de gecombineerde overinschrijving ratio en bandbreedte per server.
de werkelijke overinschrijvingsratio is de som van de twee punten van overinschrijving op de toegangs-en aggregatielagen.
1.5*2.4 = 3.6:1
gebruik de algebraïsche formule voor verhoudingen:
a: b = c: d
de bandbreedte per server op de toegangslaag is vastgesteld op 416 Mbps per server. Omdat de oversubscriptieverhouding van de aggregatielaag 1,5:1 is, kunt u de bovenstaande formule als volgt toepassen:
416:1 = x: 1.5
x= ~ 264 Mbps per server
aanbevolen Hardware en Modules
de aanbevolen platforms voor het serverclustermodel bestaan uit de Cisco Catalyst 6500-familie met de Sup720-processormodule en de Catalyst 4948-10GE 1RU-switch. De hoge schakelsnelheid, grote schakelstof, lage latency, gedistribueerde forwarding en 10gige dichtheid maakt de Catalyst 6500 serie switch ideaal voor alle lagen van dit model. De 1RU vormfactor gecombineerd met draadsnelheid forwarding, 10GE uplinks en zeer lage constante latentie maakt de 4948-10GE een uitstekende top of rack oplossing voor de access layer.
het volgende wordt aanbevolen:
•![]() Sup720-de Sup720 kan bestaan uit zowel PFC3A (standaard) of de nieuwere pfc3b type dochter kaarten.
Sup720-de Sup720 kan bestaan uit zowel PFC3A (standaard) of de nieuwere pfc3b type dochter kaarten.
•![]() Line cards – alle line cards moeten 6700 serie zijn en moeten allemaal zijn ingeschakeld voor gedistribueerde forwarding met de dfc3a of dfc3b dochter kaarten.
Line cards – alle line cards moeten 6700 serie zijn en moeten allemaal zijn ingeschakeld voor gedistribueerde forwarding met de dfc3a of dfc3b dochter kaarten.
Note ![]() door gebruik te maken van alle aan de stof bevestigde CEF720-serie modules is de Globale schakelmodus compact, waardoor het systeem op het hoogste prestatieniveau kan werken. De Catalyst 6509 kan 10 GigE modules in alle posities ondersteunen omdat elke sleuf dubbele kanalen ondersteunt naar het schakelweefsel (de Cisco Catalyst 6513 ondersteunt dit niet).
door gebruik te maken van alle aan de stof bevestigde CEF720-serie modules is de Globale schakelmodus compact, waardoor het systeem op het hoogste prestatieniveau kan werken. De Catalyst 6509 kan 10 GigE modules in alle posities ondersteunen omdat elke sleuf dubbele kanalen ondersteunt naar het schakelweefsel (de Cisco Catalyst 6513 ondersteunt dit niet).
•![]() Cisco Catalyst 4948-10GE-de 4948-10GE biedt een high performance access layer oplossing die gebruik kan maken van ECMP en 10GigE uplinks. Er zijn geen speciale vereisten nodig. De 4948-10GE kan een laag 2 Cisco IOS-afbeelding of een laag 2/3 Cisco IOS-afbeelding gebruiken, waardoor een optimale pasvorm in beide omgevingen mogelijk is.
Cisco Catalyst 4948-10GE-de 4948-10GE biedt een high performance access layer oplossing die gebruik kan maken van ECMP en 10GigE uplinks. Er zijn geen speciale vereisten nodig. De 4948-10GE kan een laag 2 Cisco IOS-afbeelding of een laag 2/3 Cisco IOS-afbeelding gebruiken, waardoor een optimale pasvorm in beide omgevingen mogelijk is.