




Cisco Data Center Infrastructure 2.5 Design Guide
projekty klastrów serwerowych z Ethernetem
ogólny przegląd serwerów i komponentów sieci używanych w modelu klastra serwerowego znajduje się w rozdziale 1 „Przegląd Architektury Centrum Danych.”Ten rozdział opisuje cel i funkcję każdej warstwy modelu klastra serwera bardziej szczegółowo. Znajdują się tu następujące sekcje:
•![]() cele techniczne
cele techniczne
•![]() rozproszone przekazywanie i opóźnienie
rozproszone przekazywanie i opóźnienie
•![]() równy koszt routingu wielościeżkowego
równy koszt routingu wielościeżkowego
•![]() projekt klastra serwerowego – Model dwupoziomowy
projekt klastra serwerowego – Model dwupoziomowy
•![]() projekt klastra serwerowego – Model trójwarstwowy
projekt klastra serwerowego – Model trójwarstwowy
•![]() zalecany sprzęt i moduły
zalecany sprzęt i moduły

Uwaga ![]() modele projektowe opisane w tym rozdziale nie zostały w pełni zweryfikowane w testach laboratoryjnych Cisco ze względu na rozmiar i zakres testów, które byłyby wymagane. Modele dwupoziomowe, które są objęte są podobne projekty, które zostały wdrożone w sieciach produkcyjnych klientów.
modele projektowe opisane w tym rozdziale nie zostały w pełni zweryfikowane w testach laboratoryjnych Cisco ze względu na rozmiar i zakres testów, które byłyby wymagane. Modele dwupoziomowe, które są objęte są podobne projekty, które zostały wdrożone w sieciach produkcyjnych klientów.
cele techniczne
podczas projektowania sieci klastrów dużych przedsiębiorstw kluczowe znaczenie ma uwzględnienie konkretnych celów. Żadne dwa klastry nie są dokładnie takie same; każdy ma swoje specyficzne wymagania i musi zostać zbadany z perspektywy zastosowania, aby określić szczególne wymagania projektowe. Wziąć pod uwagę następujące kwestie techniczne:
•![]() opóźnienie—w transporcie sieciowym opóźnienie może negatywnie wpłynąć na ogólną wydajność klastra. Wykorzystanie platform przełączających wykorzystujących architekturę przełączania o niskim opóźnieniu pomaga zapewnić optymalną wydajność. Głównym źródłem opóźnień jest stos protokołów i implementacja sprzętowa NIC używana na serwerze. Techniki optymalizacji sterowników i odciążania procesora, takie jak TCP Offload Engine (TOE) i Remote Direct Memory Access (RDMA), mogą pomóc zmniejszyć opóźnienia i zmniejszyć koszty przetwarzania na serwerze.
opóźnienie—w transporcie sieciowym opóźnienie może negatywnie wpłynąć na ogólną wydajność klastra. Wykorzystanie platform przełączających wykorzystujących architekturę przełączania o niskim opóźnieniu pomaga zapewnić optymalną wydajność. Głównym źródłem opóźnień jest stos protokołów i implementacja sprzętowa NIC używana na serwerze. Techniki optymalizacji sterowników i odciążania procesora, takie jak TCP Offload Engine (TOE) i Remote Direct Memory Access (RDMA), mogą pomóc zmniejszyć opóźnienia i zmniejszyć koszty przetwarzania na serwerze.
opóźnienie może nie zawsze być kluczowym czynnikiem w projektowaniu klastra. Na przykład niektóre klastry mogą wymagać dużej przepustowości między serwerami ze względu na dużą ilość masowego przesyłania plików, ale mogą nie polegać w dużym stopniu na komunikacji międzyprocesowej między serwerem (IPC), na co może mieć wpływ wysokie opóźnienie.
•![]() siatka / częściowa łączność siatkowa-projekty klastrów serwerów zwykle wymagają siatki lub częściowej siatki, aby umożliwić komunikację między wszystkimi węzłami w klastrze. Ta siatkowa tkanina służy do udostępniania stanu, danych i innych informacji między serwerami master-to-compute i compute-to-compute w klastrze. Siatka lub częściowa łączność siatkowa jest również zależna od zastosowania.
siatka / częściowa łączność siatkowa-projekty klastrów serwerów zwykle wymagają siatki lub częściowej siatki, aby umożliwić komunikację między wszystkimi węzłami w klastrze. Ta siatkowa tkanina służy do udostępniania stanu, danych i innych informacji między serwerami master-to-compute i compute-to-compute w klastrze. Siatka lub częściowa łączność siatkowa jest również zależna od zastosowania.
•![]() wysoka przepustowość – możliwość wysyłania dużych plików w określonym czasie może mieć kluczowe znaczenie dla działania i wydajności klastra. Klastry serwerów zazwyczaj wymagają minimalnej ilości dostępnej nieblokującej przepustowości, co przekłada się na niski model nadsubskrypcji między warstwami dostępu i rdzenia.
wysoka przepustowość – możliwość wysyłania dużych plików w określonym czasie może mieć kluczowe znaczenie dla działania i wydajności klastra. Klastry serwerów zazwyczaj wymagają minimalnej ilości dostępnej nieblokującej przepustowości, co przekłada się na niski model nadsubskrypcji między warstwami dostępu i rdzenia.
•![]() współczynnik Nadsubscription-współczynnik nadsubscription musi być sprawdzany w wielu punktach agregacji w projekcie, w tym karcie liniowej do przełączania Szerokości pasma tkaniny i przełączania wejścia tkaniny na szerokość pasma łącza w górę.
współczynnik Nadsubscription-współczynnik nadsubscription musi być sprawdzany w wielu punktach agregacji w projekcie, w tym karcie liniowej do przełączania Szerokości pasma tkaniny i przełączania wejścia tkaniny na szerokość pasma łącza w górę.
•![]() obsługa ramek Jumbo – chociaż ramki jumbo mogą nie być używane we wstępnej implementacji klastra serwerowego, jest to bardzo ważna funkcja, która jest niezbędna dla dodatkowej elastyczności lub ewentualnych przyszłych wymagań. Konstrukcja pakietów TCP / IP nakłada dodatkowe obciążenie na procesor serwera. Zastosowanie ramek jumbo może zmniejszyć liczbę pakietów, zmniejszając tym samym obciążenie.
obsługa ramek Jumbo – chociaż ramki jumbo mogą nie być używane we wstępnej implementacji klastra serwerowego, jest to bardzo ważna funkcja, która jest niezbędna dla dodatkowej elastyczności lub ewentualnych przyszłych wymagań. Konstrukcja pakietów TCP / IP nakłada dodatkowe obciążenie na procesor serwera. Zastosowanie ramek jumbo może zmniejszyć liczbę pakietów, zmniejszając tym samym obciążenie.
•![]() gęstość portów-klastry serwerów mogą wymagać skalowania do dziesiątek tysięcy portów. Jako takie wymagają platform o wysokim poziomie wydajności przełączania pakietów, dużej przepustowości tkaniny przełączającej i wysokiego poziomu gęstości portów.
gęstość portów-klastry serwerów mogą wymagać skalowania do dziesiątek tysięcy portów. Jako takie wymagają platform o wysokim poziomie wydajności przełączania pakietów, dużej przepustowości tkaniny przełączającej i wysokiego poziomu gęstości portów.
przekazywanie rozproszone i opóźnienie
przełącznik Cisco Catalyst 6500 series ma unikalną zdolność do obsługi centralnego przekazywania pakietów lub opcjonalnej architektury przekazywania rozproszonego, podczas gdy Cisco Catalyst 4948-10GE jest pojedynczą centralną konstrukcją ASIC z wydajnością przekazywania ze stałą szybkością linii. Moduły Cisco 6700 line card obsługują opcjonalny moduł karty córki o nazwie Distributed Forwarding Card (DFC). DFC umożliwia podejmowanie lokalnych decyzji dotyczących routingu na każdej karcie liniowej poprzez wdrożenie lokalnej bazy informacji o przekazywaniu danych (Fib). Stół FIB w SUP720 PFC utrzymuje synchronizację z każdym stołem Fib DFC na kartach liniowych, aby zapewnić integralność routingu w całym systemie.
gdy opcjonalna karta DFC nie jest obecna, kompaktowe wyszukiwanie nagłówka jest wysyłane do PFC3 na Sup720, aby określić, gdzie na tkaninie przełącznika przekazać każdy pakiet. Gdy występuje DFC, karta liniowa może przełączyć pakiet bezpośrednio przez tkaninę przełącznika na kartę linii docelowej bez konsultacji z Sup720. Różnica w wydajności może wynosić od 30 Mpps w całym systemie bez DFC do 48 Mpps na gniazdo z DFC. Przełącznik Catalyst 4948-10GE o stałej konfiguracji ma architekturę nieblokującą, która obsługuje wydajność do 101,18 Mpps, zapewniając doskonałą wydajność warstwy dostępu dla projektów top of rack.
wydajność opóźnień może się znacznie różnić w porównaniu z modelami przekazywania rozproszonego i centralnego. Tabela 3-1 przedstawia przykład opóźnień mierzonych na karcie liniowej 6704 z i bez DFC.
| 6704 z DFC (Port-to-Port w mikrosekundach przez Switch Fabric) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Rozmiar pakietu (B) |
||||||||||
|
latencja (ms) |
||||||||||
| 6704 bez DFC (Port-to-Port w mikrosekundach przez Switch Fabric) | ||||||||||
|
Rozmiar pakietu (B) |
||||||||||
|
latencja (ms) |
||||||||||
różnica w opóźnieniu między obsługą DFC a karta liniowa nie obsługująca DFC może nie wydawać się znacząca. Jednak w architekturze 6500 central forwarding opóźnienie może wzrosnąć wraz ze wzrostem natężenia ruchu z powodu sporu o wspólne wyszukiwanie na magistrali centralnej. W przypadku DFC ścieżka wyszukiwania jest dedykowana dla każdej karty liniowej, a opóźnienie jest stałe.
przepustowość systemu Catalyst 6500
dostępna przepustowość systemu nie zmienia się, gdy używane są DFC. DFC poprawiają przetwarzanie pakietów na sekundę (pps) całego systemu. Tabela 3-2 podsumowuje przepustowość i wydajność przepustowości modułów obsługujących DFC, oprócz starszych modułów cef256 i klasycznych magistrali.
| Konfiguracja systemu z Sup720 | przepustowość w Mpps | przepustowość w Gbps |
|
Moduły serii Classic |
do 15 Mpps (na system) |
16 G shared bus (classic bus) |
|
Moduły serii CEF256 |
do 30 Mpps (na system) |
1x 8 G (dedykowane na gniazdo) |
|
połączenie klasyki z modułami serii CEF256 lub CEF720 |
do 15 Mpps (na system) |
zależne od karty |
|
Moduły serii CEF720(6748, 6704, 6724) |
do 30 Mpps (na system) |
2x 20 G (dedykowane na gniazdo) |
|
Moduły serii CEF720 z DFC3 (6704 z DFC3, 6708 z DFC3, 6748 z DFC3 6724+DFC3) |
Sustain do 48 Mpps (na slot) |
2x 20 G (dedykowane na gniazdo) |
chociaż 6513 może być poprawnym rozwiązaniem dla warstwy dostępowej modelu dużego klastra, zauważ, że w tej obudowie znajduje się mieszanka gniazd jedno-i dwukanałowych. Gniazda od 1 do 8 są jednokanałowe, a gniazda od 9 do 13 są dwukanałowe, jak pokazano na rysunku 3-1.
rysunek 3-1 kanały Tkaniny Catalyst 6500 według obudowy i gniazda (6513 Focus
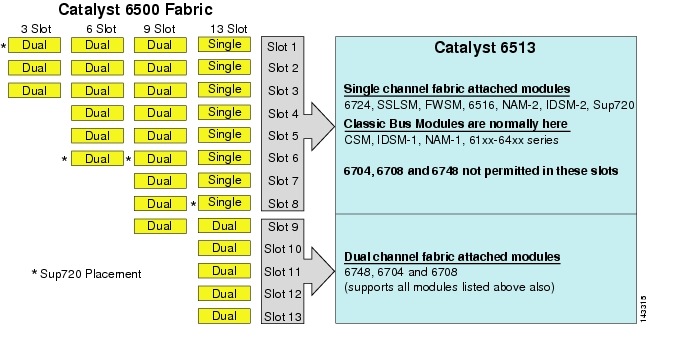
gdy używany jest Cisco Catalyst 6513, karty dwukanałowe, takie jak 6704-4 port 10gige, 6708 – 8 port 10gige i 6748-48 port SFP/copper line karty mogą być umieszczone tylko w gniazdach od 9 do 13. Jednokanałowe karty liniowe, takie jak karty 6724-24 port SFP/copper line, mogą być używane w gniazdach od 1 do 8. Sup720 Wykorzystuje gniazda 7 i 8, które są przymocowane do pojedynczego kanału 20g tkaniny. W przeciwieństwie do 6513, 6509 ma mniej dostępnych gniazd, ale może obsługiwać Moduły dwukanałowe we wszystkich gniazdach, ponieważ każde gniazdo ma dwa kanały do tkaniny przełącznika.
Uwaga ![]() ponieważ środowisko klastra serwera zwykle wymaga dużej przepustowości i niskich opóźnień, zalecamy stosowanie DFC w tego typu projektach.
ponieważ środowisko klastra serwera zwykle wymaga dużej przepustowości i niskich opóźnień, zalecamy stosowanie DFC w tego typu projektach.
Routing wielościeżkowy równy koszt
routing wielościeżkowy równy koszt (ECMP) to technologia równoważenia obciążenia, która optymalizuje przepływy na wielu ścieżkach IP między dowolnymi dwiema podsieciami w środowisku obsługującym przekazywanie Cisco Express. ECMP stosuje równoważenie obciążenia dla pakietów TCP i UDP na zasadzie per-flow. Pakiety inne niż TCP/UDP, takie jak ICMP, są dystrybuowane na zasadzie pakiet po pakiecie. ECMP jest oparty na RFC 2991 i jest wykorzystywany na innych platformach Cisco, takich jak produkty PIX i Cisco Content Services Switch (CSS). ECMP jest obsługiwany zarówno na platformach 6500, jak i 4948-10GE zalecanych w projekcie klastra serwerów.
dramatyczne zmiany wynikające z przełączania w warstwie 3 sprzętu ASICS i algorytmów hashowania Cisco Express Forwarding pomagają odróżnić ECMP od swoich poprzedników. Główną zaletą projektu ECMP dla implementacji klastrów serwerowych jest algorytm haszujący połączony z niewielkim lub zerowym obciążeniem procesora w przełączaniu warstwy 3. Algorytm hashowania Cisco Express Forwarding jest w stanie dystrybuować ziarniste przepływy na wielu kartach liniowych z szybkością liniową w sprzęcie. Domyślnym ustawieniem algorytmu haszującego jest przepływy haszujące oparte na źródłowych adresach IP warstwy 3 i docelowej oraz opcjonalnie dodanie numerów portów warstwy 4 dla dodatkowej warstwy różnicowania. Maksymalna liczba dozwolonych ścieżek ECMP to osiem.
rysunek 3-2 ilustruje 8-kierunkowy projekt klastra serwera ECMP. Aby uprościć ilustrację, pokazano tylko dwa przełączniki warstwy dostępu, ale można obsługiwać do 32 (64 10GigEs na węzeł rdzenia).
rysunek 3-2 8-kierunkowy projekt klastra serwera ECMP
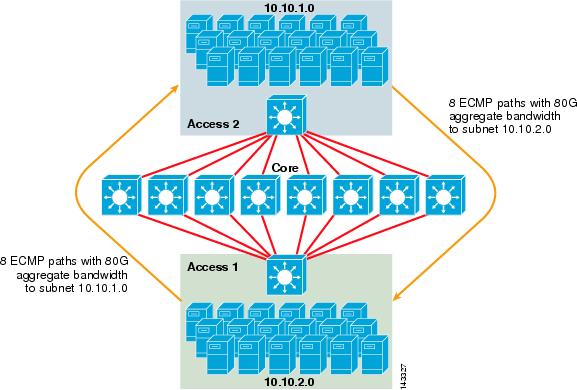
na rysunku 3-2 każdy przełącznik warstwy dostępu może obsługiwać jedną lub więcej podsieci dołączonych serwerów. Każdy przełącznik ma jedno połączenie 10GigE z każdym z ośmiu przełączników rdzeniowych za pomocą dwóch kart liniowych 6704. Ta konfiguracja zapewnia osiem ścieżek 10gige dla łącznej przepustowości 80 g Cisco Express Forwarding-enabled do dowolnej innej podsieci w tkance klastra serwera. Zapytanie Pokaż trasę ip do innej podsieci na innym przełączniku pokazuje osiem wpisów o równych kosztach.
rdzeń jest wypełniony kartami 10gige line z DFC, aby umożliwić w pełni rozproszoną szybką tkaninę przełączającą z bardzo niskim opóźnieniem portu do portu. Zapytanie Pokaż trasę ip do przełącznika warstwy dostępu pokazuje pojedynczy wpis trasy na każdym z ośmiu przełączników rdzenia.
Uwaga ![]() chociaż nie został przetestowany pod kątem tego przewodnika, jest nowy 8-portowy moduł 10 Gigabit Ethernet (WS-X6708-10g-3C), który został niedawno wprowadzony dla przełącznika serii Catalyst 6500. Ta karta linii zostanie przetestowana pod kątem włączenia do tego przewodnika w późniejszym terminie. W przypadku pytań dotyczących 8-portowej karty 10GigE, zapoznaj się z kartą danych produktu.
chociaż nie został przetestowany pod kątem tego przewodnika, jest nowy 8-portowy moduł 10 Gigabit Ethernet (WS-X6708-10g-3C), który został niedawno wprowadzony dla przełącznika serii Catalyst 6500. Ta karta linii zostanie przetestowana pod kątem włączenia do tego przewodnika w późniejszym terminie. W przypadku pytań dotyczących 8-portowej karty 10GigE, zapoznaj się z kartą danych produktu.
redundancja w projektowaniu klastra serwera
projekt klastra serwera zwykle nie jest zaimplementowany z redundantnymi procesorami CPU lub procesorami Switch fabric. Odporność jest zwykle osiągana w sposób nieodłączny w projekcie i przez sposób, w jaki klaster funkcjonuje jako całość. Jak opisano w rozdziale 1 „Przegląd Architektury Centrum Danych”, węzły obliczeniowe w klastrze są zarządzane przez węzły główne, które są odpowiedzialne za przypisywanie konkretnych zadań do każdego węzła obliczeniowego i monitorowanie ich wydajności. Jeśli węzeł obliczeniowy wypadnie z klastra, zostanie przeniesiony do dostępnego węzła i będzie nadal działał, chociaż z mniejszą mocą obliczeniową, dopóki węzeł nie będzie dostępny. Chociaż ważne jest dywersyfikowanie połączeń węzłów głównych w klastrze przez różne przełączniki dostępu, nie jest to krytyczne dla węzłów obliczeniowych.
chociaż redundantne procesory są z pewnością opcjonalne, ważne jest, aby wziąć pod uwagę gęstość portów, szczególnie w odniesieniu do portów 10GE, gdzie dostępne jest dodatkowe gniazdo zamiast redundantnego modułu Sup720.
Uwaga ![]() przykłady w tym rozdziale wykorzystują Nie redundantne konstrukcje procesorów, które umożliwiają maksymalnie 64 porty 10GE na 6509 węzła podstawowego dostępne dla połączeń uplink węzła dostępowego w oparciu o 8-portową kartę liniową 10gige 6708.
przykłady w tym rozdziale wykorzystują Nie redundantne konstrukcje procesorów, które umożliwiają maksymalnie 64 porty 10GE na 6509 węzła podstawowego dostępne dla połączeń uplink węzła dostępowego w oparciu o 8-portową kartę liniową 10gige 6708.
projektowanie klastrów serwerowych—Model dwupoziomowy
w tej sekcji opisano różne podejścia do projektowania klastrów serwerowych, które wykorzystują ECMP i rozproszony CEF. Każdy projekt pokazuje, w jaki sposób różne konfiguracje mogą osiągnąć różne poziomy nadsubskrypcji i mogą elastycznie skalować się, zaczynając od kilku węzłów, a kończąc na wielu obsługujących tysiące serwerów.
projekt klastra serwera zazwyczaj opiera się na modelu dwuwarstwowym składającym się z warstwy rdzenia i warstwy dostępu. Ponieważ cele projektu wymagają użycia warstwy 3 ECMP i rozproszonego przekazywania w celu osiągnięcia wysoce deterministycznej przepustowości i opóźnienia na serwer, trójwarstwowy model, który wprowadza inny punkt nadsubskrypcji, zwykle nie jest pożądany. Zalety modelu trójwarstwowego są opisane w Server Cluster Design-Three-Tier Model.
trzy główne obliczenia, które należy wziąć pod uwagę przy projektowaniu rozwiązania klastra serwerowego, to maksymalne połączenia z serwerem, przepustowość na serwer i współczynnik nadsubskrypcji. Projektanci klastrów mogą określać te wartości na podstawie wydajności aplikacji, sprzętu serwera i innych czynników, w tym następujących:
•![]() Maksymalna liczba połączeń GigE serwera w skali-projektanci klastrów zazwyczaj mają pojęcie o maksymalnej skali wymaganej przy początkowej koncepcji. Zaletą funkcji ECMP designs jest to, że mogą one zaczynać się od minimalnej liczby przełączników i serwerów, które spełniają określone wymagania dotyczące przepustowości, opóźnienia i nadsubskrypcji, i elastycznie rosnąć w sposób niski/niezakłócony do maksymalnej skali, zachowując te same wartości przepustowości, opóźnienia i nadsubskrypcji.
Maksymalna liczba połączeń GigE serwera w skali-projektanci klastrów zazwyczaj mają pojęcie o maksymalnej skali wymaganej przy początkowej koncepcji. Zaletą funkcji ECMP designs jest to, że mogą one zaczynać się od minimalnej liczby przełączników i serwerów, które spełniają określone wymagania dotyczące przepustowości, opóźnienia i nadsubskrypcji, i elastycznie rosnąć w sposób niski/niezakłócony do maksymalnej skali, zachowując te same wartości przepustowości, opóźnienia i nadsubskrypcji.
•![]() przybliżona przepustowość na serwer-wartość tę można określić po prostu dzieląc całkowitą zagregowaną przepustowość łącza uplink przez całkowite połączenia GigE serwera na przełączniku warstwy dostępu. Na przykład warstwę dostępową Cisco 6509 z czterema łączami uplink ECMP 10GIGE z 336 portami dostępu do serwera można obliczyć w następujący sposób:
przybliżona przepustowość na serwer-wartość tę można określić po prostu dzieląc całkowitą zagregowaną przepustowość łącza uplink przez całkowite połączenia GigE serwera na przełączniku warstwy dostępu. Na przykład warstwę dostępową Cisco 6509 z czterema łączami uplink ECMP 10GIGE z 336 portami dostępu do serwera można obliczyć w następujący sposób:
4x10gige z 336 serwerami = 120 MB / s na serwer
dostosowanie obu stron równania zmniejsza lub zwiększa przepustowość na serwer.
Uwaga ![]() jest to tylko przybliżona wartość i służy tylko jako wskazówka. Różne czynniki wpływają na rzeczywistą ilość przepustowości, którą każdy serwer ma do dyspozycji. Algorytm skrótu rozkładu obciążenia ECMP dzieli obciążenie na podstawie wartości warstwy 3 i warstwy 4 i zmienia się w zależności od wzorców ruchu. Ponadto parametry konfiguracyjne, takie jak ograniczenie szybkości, kolejkowanie i wartości QoS, mogą wpływać na rzeczywistą osiągniętą przepustowość na serwer.
jest to tylko przybliżona wartość i służy tylko jako wskazówka. Różne czynniki wpływają na rzeczywistą ilość przepustowości, którą każdy serwer ma do dyspozycji. Algorytm skrótu rozkładu obciążenia ECMP dzieli obciążenie na podstawie wartości warstwy 3 i warstwy 4 i zmienia się w zależności od wzorców ruchu. Ponadto parametry konfiguracyjne, takie jak ograniczenie szybkości, kolejkowanie i wartości QoS, mogą wpływać na rzeczywistą osiągniętą przepustowość na serwer.
•![]() Współczynnik nadsubskrypcji na serwer-wartość tę można określić po prostu dzieląc całkowitą liczbę połączeń GigE serwera przez całkowitą zagregowaną przepustowość łącza uplink na przełączniku warstwy dostępu. Na przykład warstwę dostępu 6509 z czterema łączami uplink ECMP 10GIGE z 336 portami dostępu do serwera można obliczyć w następujący sposób:
Współczynnik nadsubskrypcji na serwer-wartość tę można określić po prostu dzieląc całkowitą liczbę połączeń GigE serwera przez całkowitą zagregowaną przepustowość łącza uplink na przełączniku warstwy dostępu. Na przykład warstwę dostępu 6509 z czterema łączami uplink ECMP 10GIGE z 336 portami dostępu do serwera można obliczyć w następujący sposób:
336 połączenia GigE server z przepustowością łącza uplink 40g = 8.4: 1 współczynnik nadsubskrypcji
poniższe sekcje pokazują, jak te wartości różnią się w zależności od różnych konfiguracji sprzętu i połączeń międzysystemowych i służą jako wytyczne przy projektowaniu dużych konfiguracji klastrów.
Uwaga ![]() dla celów obliczeniowych przyjmuje się, że na przełączniku serii Catalyst 6500 nie ma karty liniowej do przełączania nadsubskrypcji tkaniny. Gniazdo dwukanałowe zapewnia maksymalną przepustowość 40g dla tkaniny przełącznika. 4-portowa karta 10GigE ze wszystkimi portami z szybkością linii przy użyciu pakietów o maksymalnym rozmiarze jest uważana za najlepszy możliwy warunek z niewielkim lub żadnym nadsubskrypcją. Rzeczywista ilość dostępnej przepustowości tkaniny przełącznika różni się w zależności od średnich rozmiarów pakietów. Obliczenia te trzeba by ponownie obliczyć, jeśli używasz 8-portowej karty WS-X6708 10GigE, która jest przeceniona na 2: 1.
dla celów obliczeniowych przyjmuje się, że na przełączniku serii Catalyst 6500 nie ma karty liniowej do przełączania nadsubskrypcji tkaniny. Gniazdo dwukanałowe zapewnia maksymalną przepustowość 40g dla tkaniny przełącznika. 4-portowa karta 10GigE ze wszystkimi portami z szybkością linii przy użyciu pakietów o maksymalnym rozmiarze jest uważana za najlepszy możliwy warunek z niewielkim lub żadnym nadsubskrypcją. Rzeczywista ilość dostępnej przepustowości tkaniny przełącznika różni się w zależności od średnich rozmiarów pakietów. Obliczenia te trzeba by ponownie obliczyć, jeśli używasz 8-portowej karty WS-X6708 10GigE, która jest przeceniona na 2: 1.
4 – i 8-drożne projekty ECMP z modularnym dostępem
poniższe cztery przykłady projektowe przedstawiają różne metody budowania i skalowania dwupoziomowego modelu klastra serwerów przy użyciu 4-i 8-drożnego ECMP. Główne kwestie do rozważenia to liczba głównych węzłów i maksymalna liczba łącza uplink, ponieważ mają one bezpośredni wpływ na maksymalną skalę, przepustowość na serwer i wartości nadsubskrypcji.
Uwaga ![]() chociaż nie został przetestowany pod kątem tego przewodnika, jest nowy 8-portowy moduł 10 Gigabit Ethernet (WS-X6708-10g-3C), który został niedawno wprowadzony dla przełącznika serii Catalyst 6500. Ta karta linii zostanie przetestowana pod kątem włączenia do przewodnika w późniejszym terminie. W przypadku pytań dotyczących 8-portowej karty 10GigE, zapoznaj się z kartą danych produktu.
chociaż nie został przetestowany pod kątem tego przewodnika, jest nowy 8-portowy moduł 10 Gigabit Ethernet (WS-X6708-10g-3C), który został niedawno wprowadzony dla przełącznika serii Catalyst 6500. Ta karta linii zostanie przetestowana pod kątem włączenia do przewodnika w późniejszym terminie. W przypadku pytań dotyczących 8-portowej karty 10GigE, zapoznaj się z kartą danych produktu.
Uwaga ![]() łącza niezbędne do podłączenia klastra serwera do sieci zewnętrznej kampusu lub sieci metra nie są pokazane w tych przykładach projektowych, ale należy je rozważyć.
łącza niezbędne do podłączenia klastra serwera do sieci zewnętrznej kampusu lub sieci metra nie są pokazane w tych przykładach projektowych, ale należy je rozważyć.
rysunek 3-3 przedstawia przykład, w którym dwa główne węzły są używane do zapewnienia 4-kierunkowego rozwiązania ECMP.
rysunek 3-3 4-kierunkowy ECMP wykorzystujący dwa podstawowe węzły
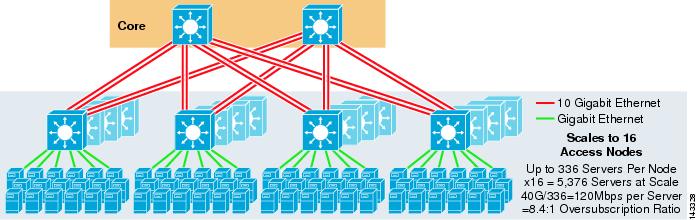
zaletą tego podejścia jest to, że mniejsza liczba podstawowych przełączników może obsługiwać dużą liczbę serwerów. Możliwą wadą jest wysoka nadsubskrypcja-niska przepustowość na wartość serwera i duża ekspozycja na awarię węzła rdzenia. Zauważ, że łącza uplink są pojedynczymi łączami Uplink L3 i nie są Etherchannelami.
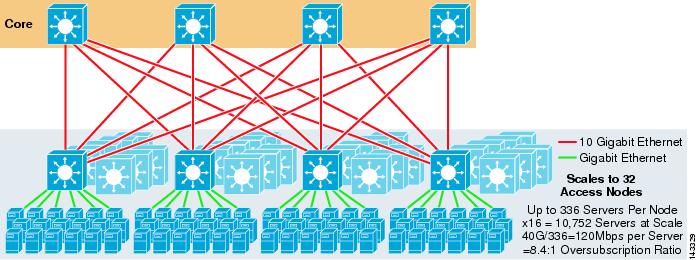
rysunek 3-4 pokazuje, jak dodanie dwóch głównych węzłów do poprzedniego projektu może znacznie zwiększyć maksymalną skalę przy zachowaniu tych samych nadsubskrypcji i wartości przepustowości na serwer.
rysunek 3-4 4-kierunkowy ECMP wykorzystujący cztery podstawowe węzły
rysunek 3-5 przedstawia 8-kierunkowy projekt ECMP wykorzystujący dwa podstawowe węzły.
rysunek 3-5 8-kierunkowy ECMP wykorzystujący dwa podstawowe węzły
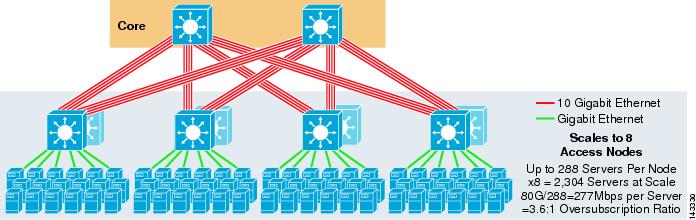
zgodnie z oczekiwaniami, dodatkowa przepustowość łącza w górę dramatycznie zwiększa przepustowość na serwer i zmniejsza współczynnik nadsubskrypcji na serwer. Zauważ, że dodatkowe sloty zajęte w każdym przełączniku warstwy dostępu do obsługi 8-drożnych łączów uplink zmniejszają maksymalną skalę, ponieważ liczba serwerów na przełącznik jest zmniejszona do 288. Zauważ, że łącza uplink są pojedynczymi łączami Uplink L3 i nie są Etherchannelami.
rysunek 3-6 przedstawia 8-kierunkowy projekt ECMP z ośmioma węzłami rdzenia.
rysunek 3-6 8-kierunkowy ECMP wykorzystujący osiem głównych węzłów
pokazuje to, w jaki sposób dodanie czterech głównych węzłów do tego samego poprzedniego projektu może znacznie zwiększyć maksymalną skalę przy zachowaniu tego samego nadsubskrypcji i przepustowości na wartości serwera.
dwukierunkowa konstrukcja ECMP z dostępem 1RU
w wielu środowiskach klastrowych przełączanie serwerów w szafie rack za pomocą małych przełączników na górze każdej szafy serwerowej jest pożądane lub wymagane ze względu na okablowanie, kwestie administracyjne, problemy związane z nieruchomościami lub w celu osiągnięcia określonych celów modelu wdrożenia.
rysunek 3-7 pokazuje przykład, w którym dwa główne węzły są używane do zapewnienia dwukierunkowego rozwiązania ECMP z przełącznikami dostępowymi 1RU 4948-10GE.
rysunek 3-7 2-drożny ECMP wykorzystujący dwa podstawowe węzły i dostęp 1RU
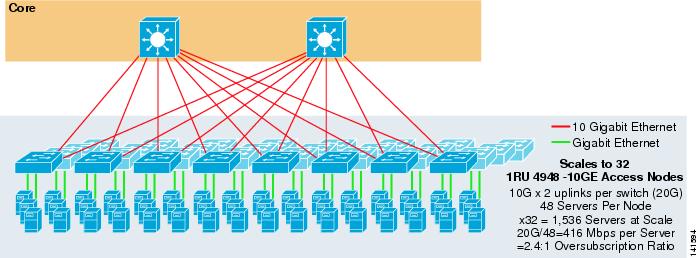
maksymalna skala jest ograniczona do 1536 serwerów, ale zapewnia ponad 400 MB / s przepustowości przy niskim współczynniku nadsubskrypcji. Ponieważ 4948 ma tylko dwa łącza 10gige, ten projekt nie może wykraczać poza te wartości.
Uwaga ![]() więcej informacji na temat przełączania serwerów w szafie rack znajduje się w Rozdziale 3 „projekty klastrów serwerów z Ethernetem.”
więcej informacji na temat przełączania serwerów w szafie rack znajduje się w Rozdziale 3 „projekty klastrów serwerów z Ethernetem.”
projekt klastra serwera—Model trójwarstwowy
chociaż model dwuwarstwowy jest najczęściej stosowany w projektach dużych klastrów, można również użyć modelu trójwarstwowego. Model trójwarstwowy jest zwykle używany do obsługi implementacji dużych klastrów serwerowych za pomocą przełączników 1RU lub modularnych warstw dostępu.
rysunek 3-8 przedstawia przykład na dużą skalę wykorzystujący 8-kierunkowy ECMP z przełącznikami rdzeniowymi i agregacyjnymi 6500 oraz przełącznikami warstwy dostępowej 1RU 4948-10GE.
rysunek 3-8 trójwarstwowy Model z 8-kierunkowym ECMP
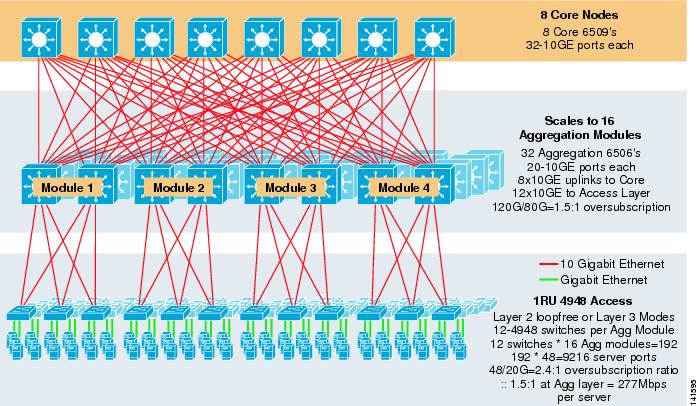
maksymalna skala to ponad 9200 serwerów o przepustowości 277 Mb / s z niskim współczynnikiem nadsubskrypcji. Korzyści z trójpoziomowego podejścia wykorzystującego przełączniki dostępu 1RU obejmują następujące:
•![]() modele wdrażania 1RU – jak wspomniano wcześniej, wiele wdrożeń modeli dużych klastrów wymaga podejścia 1RU w celu uproszczenia instalacji. Na przykład ASP rozwija szafy serwerów w czasie skalowania dużych aplikacji klastrowych. Regał serwerowy jest wstępnie zmontowany i etapowany poza siedzibą, dzięki czemu można go szybko zainstalować i dodać do działającego klastra. Zwykle wiąże się to z osobą trzecią, która buduje Szafy Rack, wstępnie konfiguruje serwery i wstępnie podłącza je za pomocą zasilania i Ethernetu do przełącznika 1RU. Stojak rolki do centrum danych i jest po prostu podłączony i dodany do klastra po podłączeniu łącza uplink.
modele wdrażania 1RU – jak wspomniano wcześniej, wiele wdrożeń modeli dużych klastrów wymaga podejścia 1RU w celu uproszczenia instalacji. Na przykład ASP rozwija szafy serwerów w czasie skalowania dużych aplikacji klastrowych. Regał serwerowy jest wstępnie zmontowany i etapowany poza siedzibą, dzięki czemu można go szybko zainstalować i dodać do działającego klastra. Zwykle wiąże się to z osobą trzecią, która buduje Szafy Rack, wstępnie konfiguruje serwery i wstępnie podłącza je za pomocą zasilania i Ethernetu do przełącznika 1RU. Stojak rolki do centrum danych i jest po prostu podłączony i dodany do klastra po podłączeniu łącza uplink.
bez warstwy agregującej maksymalny rozmiar modelu dostępu 1RU jest ograniczony do nieco ponad 1500 serwerów. Dodanie warstwy agregującej umożliwia skalowanie modelu dostępu 1RU do znacznie większego rozmiaru, przy jednoczesnym wykorzystaniu modelu ECMP.
•![]() centralizacja przełączników rdzeniowych i agregacyjnych – dzięki przełącznikom 1RU umieszczonym w szafach rack możliwa jest centralizacja większych przełączników rdzeniowych i agregacyjnych. Może to uprościć infrastrukturę zasilania i okablowania oraz poprawić wykorzystanie nieruchomości w szafach.
centralizacja przełączników rdzeniowych i agregacyjnych – dzięki przełącznikom 1RU umieszczonym w szafach rack możliwa jest centralizacja większych przełączników rdzeniowych i agregacyjnych. Może to uprościć infrastrukturę zasilania i okablowania oraz poprawić wykorzystanie nieruchomości w szafach.
•![]() pozwala na topologię bez pętli warstwy 2-duża sieć klastrów wykorzystująca dostęp ECMP warstwy 3 może wykorzystywać dużo przestrzeni adresowej na łączach uplink i może zwiększyć złożoność projektu. Jest to szczególnie ważne w przypadku korzystania z publicznej przestrzeni adresowej. Trójwarstwowe podejście modelowe dobrze nadaje się do topologii dostępu bez pętli warstwy 2, która zmniejsza liczbę wymaganych podsieci.
pozwala na topologię bez pętli warstwy 2-duża sieć klastrów wykorzystująca dostęp ECMP warstwy 3 może wykorzystywać dużo przestrzeni adresowej na łączach uplink i może zwiększyć złożoność projektu. Jest to szczególnie ważne w przypadku korzystania z publicznej przestrzeni adresowej. Trójwarstwowe podejście modelowe dobrze nadaje się do topologii dostępu bez pętli warstwy 2, która zmniejsza liczbę wymaganych podsieci.
gdy używany jest model bez pętli warstwy 2, ważne jest użycie redundantnego domyślnego protokołu bramy, takiego jak HSRP lub GLBP, aby wyeliminować pojedynczy punkt awarii w przypadku awarii węzła agregacji. W tym projekcie Moduły agregacji nie są ze sobą połączone, co pozwala na bez pętli projekt warstwy 2, który może wykorzystywać GLBP do automatycznego równoważenia obciążenia bramy domyślnej serwera. GLBP automatycznie dystrybuuje domyślne przypisanie bramy serwerów między dwoma węzłami w module agregacji. Po dotarciu pakietu do warstwy agregującej, jest on równoważony przez rdzeń za pomocą 8-kierunkowej tkaniny ECMP. Chociaż GLBP nie zapewnia haszu rozkładu obciążenia warstwy 3/warstwy 4 podobnego do CEF, jest to alternatywa, która może być używana z topologią dostępu warstwy 2.
Obliczanie nadsubskrypcji
model trójwarstwowy wprowadza dwa punkty nadsubskrypcji na warstwach dostępu i agregacji, w porównaniu z modelem dwuwarstwowym, który ma tylko jeden punkt nadsubskrypcji na warstwie dostępu. Aby prawidłowo obliczyć przybliżoną przepustowość na serwer i współczynnik nadsubskrypcji, wykonaj następujące dwa kroki, które wykorzystują rysunek 3-8 jako przykład:
Krok 1 ![]() Oblicz współczynnik nadsubskrypcji i przepustowość na serwer zarówno dla warstwy agregacji, jak i dostępu niezależnie.
Oblicz współczynnik nadsubskrypcji i przepustowość na serwer zarówno dla warstwy agregacji, jak i dostępu niezależnie.
•![]() Warstwa dostępu
Warstwa dostępu
–![]() Oversubscription-dołączone serwery 48ge / łącza uplink 20g do agregacji = 2.4:1
Oversubscription-dołączone serwery 48ge / łącza uplink 20g do agregacji = 2.4:1
–![]() przepustowość na serwer-20g uplinków do agregacji / 48gg dołączonych serwerów = 416Mbps
przepustowość na serwer-20g uplinków do agregacji / 48gg dołączonych serwerów = 416Mbps
•![]() warstwa Agregacyjna
warstwa Agregacyjna
–![]() Oversubscription – 120g downlinks to access / 80g uplinks to core = 1.5:1
Oversubscription – 120g downlinks to access / 80g uplinks to core = 1.5:1
Krok 2 ![]() Oblicz połączony współczynnik nadpisania i przepustowość na serwer.
Oblicz połączony współczynnik nadpisania i przepustowość na serwer.
rzeczywisty współczynnik nadsubskrypcji jest sumą dwóch punktów nadsubskrypcji na warstwach dostępu i agregacji.
1.5*2.4 = 3.6:1
aby określić rzeczywistą przepustowość na wartość serwera, użyj wzoru algebraicznego dla proporcji:
a:b = c: d
przepustowość na serwer w warstwie dostępu została określona na 416 Mb / s na serwer. Ponieważ współczynnik nadsubskrypcji warstwy agregacji wynosi 1,5:1, można zastosować powyższy wzór w następujący sposób:
416:1 = x: 1.5
x=~264 Mb / s na serwer
zalecany sprzęt i moduły
zalecane platformy do projektowania modelu klastra serwerów składają się z rodziny Cisco Catalyst 6500 z modułem procesora Sup720 i przełącznikiem Catalyst 4948-10GE 1RU. Wysoka szybkość przełączania, duża tkanina przełącznika, niskie opóźnienia, rozproszone przekazywanie i gęstość 10GigE sprawiają, że Przełącznik serii Catalyst 6500 jest idealny dla wszystkich warstw tego modelu. Współczynnik kształtu 1RU w połączeniu z przesyłaniem drutu, łączami uplink 10GE i bardzo niskim stałym opóźnieniem sprawia, że 4948-10GE jest doskonałym rozwiązaniem top of rack dla warstwy dostępu.
polecam:
•![]() Sup720-Sup720 może składać się zarówno z PFC3A (domyślnie), jak i nowszych kart pochodnych typu PFC3B.
Sup720-Sup720 może składać się zarówno z PFC3A (domyślnie), jak i nowszych kart pochodnych typu PFC3B.
•![]() karty liniowe-wszystkie karty liniowe powinny być serii 6700 i powinny być włączone do przekazywania rozproszonego za pomocą kart dfc3a lub dfc3b córki.
karty liniowe-wszystkie karty liniowe powinny być serii 6700 i powinny być włączone do przekazywania rozproszonego za pomocą kart dfc3a lub dfc3b córki.
Uwaga ![]() dzięki zastosowaniu wszystkich modułów serii cef720 dołączonych do tkaniny, globalny Tryb przełączania jest kompaktowy, co pozwala systemowi pracować na najwyższym poziomie wydajności. Catalyst 6509 może obsługiwać 10 modułów GigE we wszystkich pozycjach, ponieważ każde gniazdo obsługuje dwa kanały do przełącznika (Cisco Catalyst 6513 tego nie obsługuje).
dzięki zastosowaniu wszystkich modułów serii cef720 dołączonych do tkaniny, globalny Tryb przełączania jest kompaktowy, co pozwala systemowi pracować na najwyższym poziomie wydajności. Catalyst 6509 może obsługiwać 10 modułów GigE we wszystkich pozycjach, ponieważ każde gniazdo obsługuje dwa kanały do przełącznika (Cisco Catalyst 6513 tego nie obsługuje).
•![]() Cisco Catalyst 4948-10GE—4948-10GE zapewnia wysokowydajne rozwiązanie warstwy dostępu, które może wykorzystywać łącza uplink ECMP i 10GIGE. Nie są wymagane żadne specjalne wymagania. Model 4948-10GE może korzystać z obrazu Cisco IOS warstwy 2 lub obrazu Cisco IOS warstwy 2/3, co pozwala na optymalne dopasowanie w obu środowiskach.
Cisco Catalyst 4948-10GE—4948-10GE zapewnia wysokowydajne rozwiązanie warstwy dostępu, które może wykorzystywać łącza uplink ECMP i 10GIGE. Nie są wymagane żadne specjalne wymagania. Model 4948-10GE może korzystać z obrazu Cisco IOS warstwy 2 lub obrazu Cisco IOS warstwy 2/3, co pozwala na optymalne dopasowanie w obu środowiskach.