




Cisco Data Center Infrastructure 2.5 Design Guide
Server Cluster Design Med Ethernet
en oversikt på høyt nivå over servere og nettverkskomponenter som brukes i server cluster-modellen, finnes I Kapittel 1 » Oversikt Over Datasenterarkitektur.»Dette kapittelet beskriver formålet og funksjonen til hvert lag av serverklyngemodellen i større detalj. Følgende avsnitt er inkludert:
•![]() Tekniske Mål
Tekniske Mål
•![]() Distribuert Videresending og Ventetid
Distribuert Videresending og Ventetid
•![]() Lik Kostnad Multi-Bane Ruting
Lik Kostnad Multi-Bane Ruting
•![]() Server Cluster Design-To-Lags Modell
Server Cluster Design-To-Lags Modell
•![]() Server Cluster Design-Tre-Lags Modell
Server Cluster Design-Tre-Lags Modell
•![]() Anbefalt Maskinvare Og Moduler
Anbefalt Maskinvare Og Moduler

Merk ![]() designmodellene som dekkes i dette kapittelet, er ikke fullstendig verifisert I Cisco lab testing på grunn av størrelsen og omfanget av testing som ville være nødvendig. De to-tier modellene som er dekket, er lignende design som er implementert i kundeproduksjonsnettverk.
designmodellene som dekkes i dette kapittelet, er ikke fullstendig verifisert I Cisco lab testing på grunn av størrelsen og omfanget av testing som ville være nødvendig. De to-tier modellene som er dekket, er lignende design som er implementert i kundeproduksjonsnettverk.
Tekniske Mål
når du utformer et stort virksomhetsklyngenettverk, er det viktig å vurdere spesifikke mål. Ingen to klynger er nøyaktig like; hver har sine egne spesifikke krav og må undersøkes fra et applikasjonsperspektiv for å bestemme de spesielle designkravene. Ta hensyn til følgende tekniske hensyn:
•![]() Ventetid-i nettverkstransporten kan ventetid påvirke den generelle klyngeytelsen negativt. Ved hjelp av svitsjeplattformer som benytter en lav latens svitsjearkitektur bidrar til å sikre optimal ytelse. Hovedkilden til latens er protokollstakken og nic-maskinvareimplementeringen som brukes på serveren. Driveroptimalisering og CPU-avlastningsteknikker, for eksempel TCP Offload Engine (TOE) og REMOTE Direct Memory Access (RDMA), kan bidra til å redusere ventetid og redusere behandlingsoverhead på serveren.
Ventetid-i nettverkstransporten kan ventetid påvirke den generelle klyngeytelsen negativt. Ved hjelp av svitsjeplattformer som benytter en lav latens svitsjearkitektur bidrar til å sikre optimal ytelse. Hovedkilden til latens er protokollstakken og nic-maskinvareimplementeringen som brukes på serveren. Driveroptimalisering og CPU-avlastningsteknikker, for eksempel TCP Offload Engine (TOE) og REMOTE Direct Memory Access (RDMA), kan bidra til å redusere ventetid og redusere behandlingsoverhead på serveren.
Latens er kanskje ikke alltid en kritisk faktor i klyngeutformingen. Noen klynger kan for eksempel kreve høy båndbredde mellom servere på grunn av en stor mengde massefiloverføring, men er kanskje ikke avhengige av ipc-meldinger (interprosess Communication) fra server til server, som kan påvirkes av høy ventetid.
•![]() Mesh / partial mesh connectivity-Server cluster design krever vanligvis en mesh eller delvis mesh stoff for å tillate kommunikasjon mellom alle noder i klyngen. Dette maskestoffet brukes til å dele tilstand, data og annen informasjon mellom master-to-compute og compute-to-compute-servere i klyngen. Mesh eller delvis mesh-tilkobling er også applikasjonsavhengig.
Mesh / partial mesh connectivity-Server cluster design krever vanligvis en mesh eller delvis mesh stoff for å tillate kommunikasjon mellom alle noder i klyngen. Dette maskestoffet brukes til å dele tilstand, data og annen informasjon mellom master-to-compute og compute-to-compute-servere i klyngen. Mesh eller delvis mesh-tilkobling er også applikasjonsavhengig.
•![]() Høy gjennomstrømning-muligheten til å sende en stor fil i en bestemt tidsperiode kan være avgjørende for klyngedrift og ytelse. Serverklynger krever vanligvis et minimum av tilgjengelig ikke-blokkerende båndbredde, noe som oversettes til en lav overskriftsmodell mellom access-og kjernelagene.
Høy gjennomstrømning-muligheten til å sende en stor fil i en bestemt tidsperiode kan være avgjørende for klyngedrift og ytelse. Serverklynger krever vanligvis et minimum av tilgjengelig ikke-blokkerende båndbredde, noe som oversettes til en lav overskriftsmodell mellom access-og kjernelagene.
•![]() Overskrift ratio-overskrift ratio må undersøkes på flere aggregering poeng i design, inkludert linjen kortet for å bytte stoff båndbredde og bryteren stoff inngang til uplink båndbredde.
Overskrift ratio-overskrift ratio må undersøkes på flere aggregering poeng i design, inkludert linjen kortet for å bytte stoff båndbredde og bryteren stoff inngang til uplink båndbredde.
•![]() jumbo frame support – selv om jumbo frames kanskje ikke brukes i den første implementeringen av en serverklynge, er det en svært viktig funksjon som er nødvendig for ekstra fleksibilitet eller for mulige fremtidige krav. TCP / IP-pakkekonstruksjonen plasserer ekstra overhead på serverens CPU. Bruken av jumbo rammer kan redusere antall pakker, og dermed redusere denne overhead.
jumbo frame support – selv om jumbo frames kanskje ikke brukes i den første implementeringen av en serverklynge, er det en svært viktig funksjon som er nødvendig for ekstra fleksibilitet eller for mulige fremtidige krav. TCP / IP-pakkekonstruksjonen plasserer ekstra overhead på serverens CPU. Bruken av jumbo rammer kan redusere antall pakker, og dermed redusere denne overhead.
•![]() Port tetthet-Serverklynger må kanskje skaleres til titusenvis av porter. Som sådan krever de plattformer med et høyt nivå av pakkebytteytelse, en stor mengde bryterstoffbåndbredde og et høyt nivå av porttetthet.
Port tetthet-Serverklynger må kanskje skaleres til titusenvis av porter. Som sådan krever de plattformer med et høyt nivå av pakkebytteytelse, en stor mengde bryterstoffbåndbredde og et høyt nivå av porttetthet.
Distribuert Videresending Og Ventetid
Cisco Catalyst 6500-Seriebryteren har den unike muligheten til å støtte en sentral pakkeforsendelse eller valgfri distribuert videresendingsarkitektur, mens Cisco Catalyst 4948 – 10ge er en enkelt sentral asic-design med videresendingsytelse med fast linjefrekvens. Cisco 6700-linjekortmodulene støtter en valgfri datterkortmodul kalt Et Distribuert Videresendingskort (DFC). DFC tillater lokale rutingsbeslutninger på hvert linjekort ved å implementere en LOKAL Videresendingsinformasjonsbase (FIB). FIB-tabellen På Sup720 PFC opprettholder synkronisering med hvert DFC FIB-bord på linjekortene for å sikre rutingintegritet over hele systemet.
når det valgfrie dfc-kortet ikke er til stede, sendes et kompakt topptekstoppslag til PFC3 På Sup720 for å bestemme hvor på bryterstoffet for å videresende hver pakke. Når EN DFC er til stede, kan linjekortet bytte en pakke rett over bryterstoffet til destinasjonslinjekortet uten Å konsultere Sup720. Forskjellen i ytelse kan være fra 30 Mpps system-wide uten DFCs til 48 Mpps per spor med DFCs. Den faste konfigurasjonen Catalyst 4948 – 10ge-bryteren har en ledningshastighet, ikke-blokkerende arkitektur som støtter opptil 101.18 Mpps ytelse, noe som gir overlegen tilgangslagsytelse for toppen av rackdesign.
Latensytelsen kan variere betydelig når man sammenligner distribuerte og sentrale videresendingsmodeller. Tabell 3-1 gir et eksempel på ventetider målt over et 6704 linjekort med Og uten DFCs.
| 6704 MED DFC (Port-Til-Port I Mikrosekunder Gjennom Bryter Stoff) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Pakkestørrelse (B) |
||||||||||
|
Latens (ms)) |
||||||||||
| 6704 uten DFC (Port-Til-Port I Mikrosekunder Gjennom Bryter Stoff) | ||||||||||
|
Pakkestørrelse (B) |
||||||||||
|
Latens (ms)) |
||||||||||
forskjellen i ventetid mellom EN dfc-aktivert og ikke-DFC-aktivert linjekort vises kanskje ikke signifikant. I en 6500 central forwarding-arkitektur kan imidlertid ventetiden øke etter hvert som trafikkratene øker på grunn av påstanden om det delte oppslaget på den sentrale bussen. Med EN DFC er oppslagsbanen dedikert til hvert linjekort, og ventetiden er konstant.
Catalyst 6500 Systembåndbredde
tilgjengelig systembåndbredde endres ikke når Dfcer brukes. DFCs forbedre pakker per sekund (pps) behandling av det totale systemet. Tabell 3-2 oppsummerer gjennomstrømning og båndbredde ytelse for moduler som støtter DFCs, i tillegg til de eldre CEF256 og classic bus moduler.
| Systemkonfigurasjon Med Sup720 | Gjennomstrømning I Mpps | Båndbredde I Gbps |
|
klassiske serien moduler |
Opptil 15 Mpps (per system) |
16 G delt buss (klassisk buss) |
|
CEF256 Serie moduler |
Opptil 30 Mpps (per system) |
1x 8 G (dedikert per spor) |
|
blanding av classic med CEF256-eller CEF720-Seriemoduler |
Opptil 15 Mpps (per system) |
Kort avhengig |
|
CEF720-Serien moduler (6748, 6704, 6724) |
Opptil 30 Mpps (per system) |
2×20 G (dedikert per spor) |
|
CEF720-Serien moduler MED DFC3 (6704 MED DFC3, 6708 MED DFC3, 6748 MED DFC3 6724 + DFC3) |
Sustain opptil 48 Mpps (per spor) |
2×20 G (dedikert per spor) |
Selv om 6513 kan v re en gyldig losning for tilgangslaget i den store klyngemodellen, merk at det er en blanding av enkelt-og tokanalspor i dette chassiset. Slots 1 til 8 er enkeltkanal og slots 9 til 13 er tokanal, som vist i Figur 3-1.
Figur 3-1 Catalyst 6500 Stoffkanaler Av Chassis Og Spor (6513 Focus
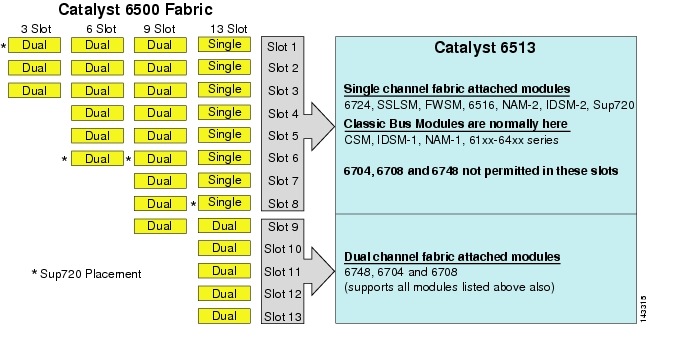
når En Cisco Catalyst 6513 brukes, kan tokanalskortene, for eksempel 6704-4-porten 10GigE, 6708-8-porten 10GigE og 6748-48-porten SFP / kobberlinjekort bare plasseres i spor 9 til 13. Enkeltkanallinjekortene som 6724-24 port SFP / kobber linjekort kan brukes i spor 1 til 8. Den Sup720 bruker slots 7 og 8, som er enkeltkanal 20G stoff festet. I motsetning til 6513 har 6509 færre tilgjengelige spor, men kan støtte tokanalsmoduler i alle spor fordi hvert spor har to kanaler til bryterstoffet.
Merk ![]() fordi serverklyngemiljøet vanligvis krever høy båndbredde med lav latensegenskaper, anbefaler vi at Du bruker Dfcer i disse typene design.
fordi serverklyngemiljøet vanligvis krever høy båndbredde med lav latensegenskaper, anbefaler vi at Du bruker Dfcer i disse typene design.
Equal Cost Multi-Path Routing
Equal cost multi-path (ECMP) routing er en lastbalanseringsteknologi som optimaliserer flyter over FLERE IP-baner mellom to undernett i Et Cisco Express Forwarding-aktivert miljø. ECMP bruker lastbalansering for TCP-og UDP-pakker på en per-flow basis. Ikke-TCP/UDP-pakker, FOR EKSEMPEL ICMP, distribueres på pakke-for-pakke basis. ECMP er basert PÅ RFC 2991 og er utnyttet på Andre Cisco-plattformer, for eksempel PIX og Cisco Content Services Switch (CSS) – produkter. ECMP støttes på både 6500-og 4948-10ge-plattformene som anbefales i serverklyngen.
de dramatiske endringene som følge Av Layer 3 switching hardware ASICs og Cisco Express Forwarding hashing algoritmer bidrar til å skille ECMP fra forgjengerteknologiene. Hovedfordelen i EN ECMP-design for serverklyngeimplementeringer er hashingalgoritmen kombinert med liten ELLER ingen CPU overhead i Layer 3 switching. Cisco Express Forwarding hashing-algoritmen er i stand til å distribuere granulære strømmer over flere linjekort med linjehastighet i maskinvare. Standardinnstillingen for hashingalgoritmen er å hash-strømmer basert PÅ Lag 3 kilde-destinasjon IP-adresser, og eventuelt legge Til lag 4 portnumre for et ekstra lag av differensiering. Maksimalt antall TILLATTE ECMP-baner er åtte.
Figur 3-2 illustrerer EN 8-veis ECMP server cluster design. For å forenkle illustrasjonen vises bare to tilgangslagbrytere, men opptil 32 kan støttes (64 10GigEs per kjernenode).
Figur 3-2 8-Veis ECMP Server Cluster Design
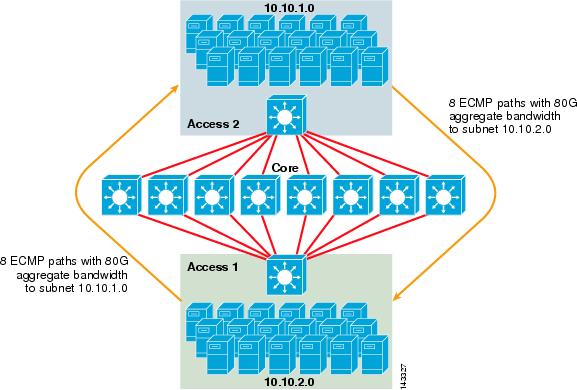
I Figur 3-2 kan hver tilgangslagbryter støtte ett eller flere undernett av vedlagte servere. Hver bryter har en enkelt 10GigE tilkobling til hver av de atte kjernebryterne ved hjelp av to 6704 linjekort. Denne konfigurasjonen gir åtte baner av 10GigE for totalt 80 G Cisco Express Forwarding-aktivert bandbredde til et annet delnett i server cluster fabric. En vis ip-rutespørring til et annet delnett på en annen bryter viser åtte likeverdige oppføringer.
kjernen er befolket med 10gige linjekort med DFCs for å muliggjøre et fullt distribuert høyhastighetsbryterstoff med svært lav port-til-port latens. En vis ip-rutespørring til en access – lagbryter viser en enkelt ruteoppføring på hver av de åtte kjernebryterne.
Merk ![]() selv Om den ikke er testet for denne veiledningen, er det en ny 8-port 10 Gigabit Ethernet-modul (WS-X6708-10g-3C) som nylig er introdusert for Catalyst 6500-Seriebryteren. Dette linjekortet vil bli testet for inkludering i denne veiledningen på et senere tidspunkt. For spørsmål om 8-port 10GigE-kortet, se produktdatabladet.
selv Om den ikke er testet for denne veiledningen, er det en ny 8-port 10 Gigabit Ethernet-modul (WS-X6708-10g-3C) som nylig er introdusert for Catalyst 6500-Seriebryteren. Dette linjekortet vil bli testet for inkludering i denne veiledningen på et senere tidspunkt. For spørsmål om 8-port 10GigE-kortet, se produktdatabladet.
Redundans I Serverklyngeutformingen
serverklyngeutformingen implementeres vanligvis ikke med redundant CPU eller switch fabric-prosessorer. Resiliency oppnås vanligvis iboende i design og ved metoden klyngen fungerer som en helhet. Som beskrevet I Kapittel 1 «Oversikt Over Datasenterarkitektur», administreres beregningsnodene i klyngen av hovednoder som er ansvarlige for å tilordne bestemte jobber til hver beregningsnode og overvåke ytelsen. Hvis en beregningsnode faller ut av klyngen, tilordnes den til en tilgjengelig node og fortsetter å fungere, men med mindre prosessorkraft, til noden er tilgjengelig. Selv om det er viktig å diversifisere hovednodetilkoblinger i klyngen på tvers av ulike tilgangsbrytere, er det ikke kritisk for beregningsnodene.
selv om redundante Cpuer er absolutt valgfrie, er det viktig a vurdere porttetthet, spesielt med hensyn TIL 10GE-porter, hvor et ekstra spor er tilgjengelig i stedet for en redundant Sup720-modul.
Merk ![]() eksemplene i dette kapittelet bruker IKKE-redundante CPU-design, som tillater maksimalt 64 10ge-porter per 6509 kjernenode tilgjengelig for tilgangsnode uplink-tilkoblinger basert på bruk av et 6708 8-port 10GigE linjekort.
eksemplene i dette kapittelet bruker IKKE-redundante CPU-design, som tillater maksimalt 64 10ge-porter per 6509 kjernenode tilgjengelig for tilgangsnode uplink-tilkoblinger basert på bruk av et 6708 8-port 10GigE linjekort.
Utforming Av Serverklynger-Todelt Modell
denne delen beskriver de ulike tilnærmingene til en serverklyngdesign som utnytter ECMP og distribuert CEF. Hvert design demonstrerer hvordan forskjellige konfigurasjoner kan oppnå ulike overtegningsnivåer og kan skalere på en fleksibel måte, og starter med noen få noder og vokser til mange som støtter tusenvis av servere.
serverklyngeutformingen følger vanligvis en todelt modell bestående av kjerne-og tilgangslag. Fordi designmålene krever BRUK Av Layer 3 ECMP og distribuert videresending for å oppnå en svært deterministisk båndbredde og ventetid per server, er en tre-lags modell som introduserer et annet punkt med overskrift vanligvis ikke ønskelig. Fordelene med en tre-lags modell er beskrevet I Server Cluster Design-Tre-Lags Modell.
de tre hovedberegningene du bør vurdere når du utformer en serverklyngeløsning, er maksimale servertilkoblinger, båndbredde per server og overskriftsforhold. Klyngedesignere kan bestemme disse verdiene basert på programytelse, servermaskinvare og andre faktorer, inkludert følgende:
•![]() Maksimalt antall server gige tilkoblinger i skala-Cluster designere har vanligvis en ide om maksimal skala som kreves ved første konsept. EN fordel MED MÅTEN ECMP-design fungerer på, er at DE kan starte med et minimum antall brytere og servere som oppfyller en bestemt båndbredde, latens og overskriftskrav, og fleksibelt vokse på en lav/ikke-forstyrrende måte til maksimal skala samtidig som de opprettholder samme båndbredde, latens og overskriftsverdier.
Maksimalt antall server gige tilkoblinger i skala-Cluster designere har vanligvis en ide om maksimal skala som kreves ved første konsept. EN fordel MED MÅTEN ECMP-design fungerer på, er at DE kan starte med et minimum antall brytere og servere som oppfyller en bestemt båndbredde, latens og overskriftskrav, og fleksibelt vokse på en lav/ikke-forstyrrende måte til maksimal skala samtidig som de opprettholder samme båndbredde, latens og overskriftsverdier.
•![]() Omtrentlig båndbredde per server-denne verdien kan bestemmes ved ganske enkelt å dele den totale aggregerte uplink-båndbredden med de totale server GigE-tilkoblingene på tilgangslagsvitsjen. For eksempel kan et tilgangslag Cisco 6509 med fire 10GIGE ECMP uplinks med 336 servertilgangsporter beregnes som følger:
Omtrentlig båndbredde per server-denne verdien kan bestemmes ved ganske enkelt å dele den totale aggregerte uplink-båndbredden med de totale server GigE-tilkoblingene på tilgangslagsvitsjen. For eksempel kan et tilgangslag Cisco 6509 med fire 10GIGE ECMP uplinks med 336 servertilgangsporter beregnes som følger:
4x10GigE Uplinks med 336 servere = 120 Mbps per server
Justering av hver side av ligningen reduserer eller øker mengden båndbredde per server.
Merk ![]() Dette er bare en omtrentlig verdi Og tjener bare som en retningslinje. Ulike faktorer påvirker den faktiske mengden båndbredde som hver server har tilgjengelig. ECMP load-distribution hash-algoritmen deler belastning basert på Lag 3 pluss lag 4-verdier og varierer basert på trafikkmønstre. Konfigurasjonsparametere som hastighetsbegrensning, kø og qos-verdier kan også påvirke den faktiske oppnådde båndbredden per server.
Dette er bare en omtrentlig verdi Og tjener bare som en retningslinje. Ulike faktorer påvirker den faktiske mengden båndbredde som hver server har tilgjengelig. ECMP load-distribution hash-algoritmen deler belastning basert på Lag 3 pluss lag 4-verdier og varierer basert på trafikkmønstre. Konfigurasjonsparametere som hastighetsbegrensning, kø og qos-verdier kan også påvirke den faktiske oppnådde båndbredden per server.
•![]() Overabonnement ratio per server – denne verdien kan bestemmes ved ganske enkelt å dele det totale antall server GigE tilkoblinger av den totale aggregerte uplink båndbredde på access layer switch. For eksempel kan et access layer 6509 med fire 10GIGE ECMP uplinks med 336 servertilgangsporter beregnes som følger:
Overabonnement ratio per server – denne verdien kan bestemmes ved ganske enkelt å dele det totale antall server GigE tilkoblinger av den totale aggregerte uplink båndbredde på access layer switch. For eksempel kan et access layer 6509 med fire 10GIGE ECMP uplinks med 336 servertilgangsporter beregnes som følger:
336 gige servertilkoblinger MED 40G uplink båndbredde = 8.4:1 overskriftsforhold
de følgende avsnittene viser hvordan disse verdiene varierer, basert på forskjellige maskinvare-og samtrafikkkonfigurasjoner, og fungerer som en retningslinje når du utformer store klyngekonfigurasjoner.
Merk ![]() for beregningsformål antas det at det ikke er noe linjekort for å bytte overskrift av stoff på Catalyst 6500 Series-bryteren. Dual channel-sporet gir 40G maksimal bandbredde til switch-stoffet. Et 4-port 10gige kort med alle porter ved linjefrekvens ved hjelp av maksimale storrelsespakker regnes som best mulig tilstand med liten eller ingen overskrift. Den faktiske mengden switch fabric båndbredde tilgjengelig varierer, basert på gjennomsnittlige pakkestørrelser. Disse beregningene må omregnes hvis DU skulle bruke WS-X6708 8-port 10GigE-kortet som er overtegnet på 2: 1.
for beregningsformål antas det at det ikke er noe linjekort for å bytte overskrift av stoff på Catalyst 6500 Series-bryteren. Dual channel-sporet gir 40G maksimal bandbredde til switch-stoffet. Et 4-port 10gige kort med alle porter ved linjefrekvens ved hjelp av maksimale storrelsespakker regnes som best mulig tilstand med liten eller ingen overskrift. Den faktiske mengden switch fabric båndbredde tilgjengelig varierer, basert på gjennomsnittlige pakkestørrelser. Disse beregningene må omregnes hvis DU skulle bruke WS-X6708 8-port 10GigE-kortet som er overtegnet på 2: 1.
4-Og 8-Veis ECMP-Design Med Modulær Tilgang
følgende fire designeksempler demonstrerer ulike metoder for å bygge og skalere todelt serverklyngemodell ved hjelp av 4-veis OG 8-veis ECMP. Hovedproblemene å vurdere er antall kjernenoder og maksimalt antall uplinks, fordi disse direkte påvirker maksimal skala, båndbredde per server og overskriftsverdier.
Merk ![]() selv Om den ikke er testet for denne veiledningen, er det en ny 8-port 10 Gigabit Ethernet-Modul (WS-X6708-10g-3C) som nylig er introdusert for Catalyst 6500-Seriebryteren. Dette linjekortet vil bli testet for inkludering i guiden på et senere tidspunkt. For spørsmål om 8-port 10GigE-kortet, se produktdatabladet.
selv Om den ikke er testet for denne veiledningen, er det en ny 8-port 10 Gigabit Ethernet-Modul (WS-X6708-10g-3C) som nylig er introdusert for Catalyst 6500-Seriebryteren. Dette linjekortet vil bli testet for inkludering i guiden på et senere tidspunkt. For spørsmål om 8-port 10GigE-kortet, se produktdatabladet.
Merk ![]() koblingene som er nødvendige For å koble serverklyngen til et utenfor campus eller metro-nettverk, vises ikke i disse designeksemplene, men bør vurderes.
koblingene som er nødvendige For å koble serverklyngen til et utenfor campus eller metro-nettverk, vises ikke i disse designeksemplene, men bør vurderes.
Figur 3-3 gir et eksempel der to kjernenoder brukes til å gi en 4-veis ECMP-løsning.
Figur 3-3 4-Veis ECMP ved Hjelp Av To Kjernenoder
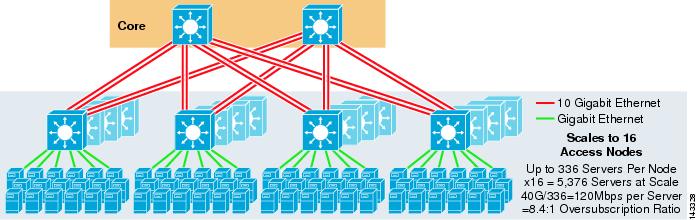
en fordel med denne tilnærmingen er at et mindre antall kjernebrytere kan støtte et stort antall servere. Den mulige ulempen er en høy overskrift-lav båndbredde per serververdi og stor eksponering for en kjerneknodefeil. Merk at uplinks er individuelle L3 uplinks og er ikke EtherChannels.
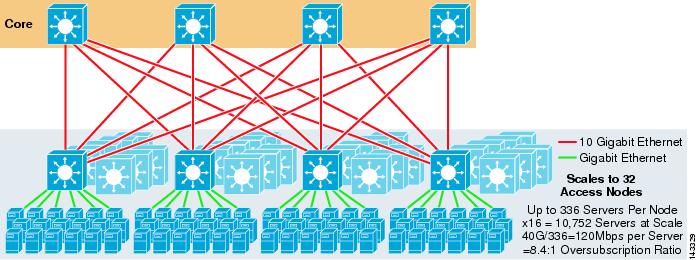
Figur 3-4 viser hvordan å legge til to kjernenoder i det forrige designet kan øke maksimalskalaen dramatisk, samtidig som de samme verdiene for overskrift og båndbredde per server opprettholdes.
Figur 3-4 4-Veis ECMP ved Hjelp Av Fire Kjernenoder
Figur 3-5 viser en 8-veis ECMP-design ved hjelp av to kjernenoder.
Figur 3-5 8-Veis ECMP ved Hjelp Av To Kjernenoder
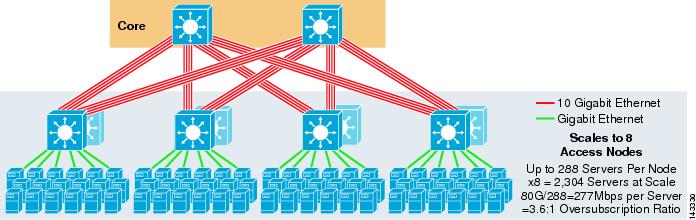
som forventet øker den ekstra båndbredden for opplink dramatisk båndbredden per server og reduserer overskriftsforholdet per server. Legg merke til hvordan de ekstra sporene som tas i hver access layer-bryter for a stotte 8-veis uplinks, reduserer maksimal skala ettersom antall servere per bryter reduseres til 288. Merk at uplinks er individuelle L3 uplinks og er ikke EtherChannels.
Figur 3-6 viser EN 8-veis ECMP-design med åtte kjernenoder.
Figur 3-6 8-Veis ECMP ved Hjelp Av Åtte Kjernenoder
dette demonstrerer hvordan å legge til fire kjernenoder i samme tidligere design kan øke maksimalskalaen dramatisk, samtidig som man opprettholder samme overskrift og båndbredde per serververdier.
2-Veis ECMP-Design Med 1ru-Tilgang
i mange klyngemiljøer er rackbasert serverbytte ved hjelp av små svitsjer øverst på hver serverhylle ønsket eller påkrevd på grunn av kabling, administrative problemer, eiendomsproblemer eller for å oppfylle bestemte mål for distribusjonsmodellen.
Figur 3-7 viser et eksempel der to kjernenoder brukes til å gi EN 2-veis ECMP-løsning MED 1ru 4948-10ge tilgangsbrytere.
Figur 3-7 2-Veis ECMP ved Hjelp Av To Kjernenoder Og 1ru-Tilgang
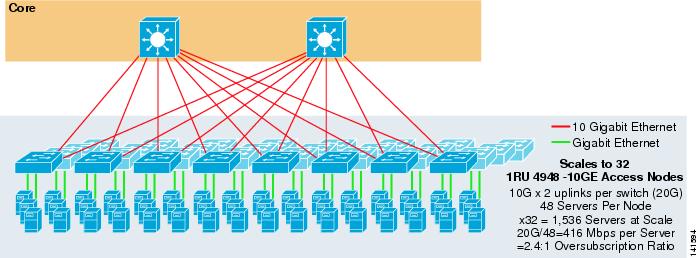
maksimal skala er begrenset til 1536 servere, men gir over 400 Mbps båndbredde med lavt overskriftsforhold. Fordi 4948 har bare to 10gige uplinks, kan dette designet ikke skalere utover disse verdiene.
Merk ![]() Mer informasjon Om rack-basert server switching er gitt I Kapittel 3 » Server Cluster Design Med Ethernet .»
Mer informasjon Om rack-basert server switching er gitt I Kapittel 3 » Server Cluster Design Med Ethernet .»
Server Cluster Design-Tre-Lags Modell
Selv om en to-lags modell er mest vanlig i store klynger design, kan en tre-lags modell også brukes. Tre-lags modellen brukes vanligvis til å støtte store serverklynge implementeringer ved HJELP AV 1ru eller modulære tilgangslagsvitsjer.
Figur 3-8 viser et storskala eksempel som utnytter 8-veis ECMP med 6500 kjerne-og aggregeringsbrytere og 1ru 4948-10ge tilgangslagbrytere.
Figur 3-8 Tre-Lags Modell med 8-Veis ECMP
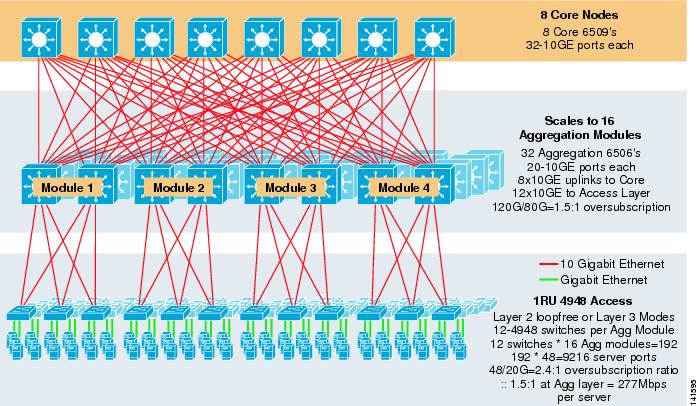
maksimal skala er over 9200 servere med 277 Mbps båndbredde med lavt overskriftsforhold. Fordeler med tre-lags tilnærming ved HJELP av 1ru tilgangsbrytere inkluderer følgende:
•![]() 1ru deployment models-som nevnt tidligere, krever mange store cluster modell distribusjoner en 1ru tilnærming for forenklet installasjon. FOR eksempel ruller EN ASP ut racks av servere om gangen når de skalerer store klyngeprogrammer. Serverstativet er forhåndsmontert og iscenesatt offsite slik at det raskt kan installeres og legges til den løpende klyngen. Dette innebærer vanligvis en tredjepart som bygger stativene, forhåndskonfigurerer serverne, og forkabler dem med strøm og Ethernet TIL EN 1ru-bryter. Stativet ruller inn i datasenteret og er ganske enkelt plugget inn og lagt til klyngen etter tilkobling av uplinks.
1ru deployment models-som nevnt tidligere, krever mange store cluster modell distribusjoner en 1ru tilnærming for forenklet installasjon. FOR eksempel ruller EN ASP ut racks av servere om gangen når de skalerer store klyngeprogrammer. Serverstativet er forhåndsmontert og iscenesatt offsite slik at det raskt kan installeres og legges til den løpende klyngen. Dette innebærer vanligvis en tredjepart som bygger stativene, forhåndskonfigurerer serverne, og forkabler dem med strøm og Ethernet TIL EN 1ru-bryter. Stativet ruller inn i datasenteret og er ganske enkelt plugget inn og lagt til klyngen etter tilkobling av uplinks.
uten et aggregeringslag er maksimal størrelse PÅ 1ru-tilgangsmodellen begrenset til litt over 1500 servere. Ved å legge til et aggregeringslag kan 1ru-tilgangsmodellen skaleres til en mye større størrelse samtidig som ECMP-modellen utnyttes.
•![]() Sentralisering av kjerne-og aggregeringsbrytere – MED 1ru-brytere utplassert i rekkene, er det mulig å sentralisere de større kjerne-og aggregeringsmodulære bryterne. Dette kan forenkle strøm og kabling infrastruktur og forbedre rack eiendomsmegling bruk.
Sentralisering av kjerne-og aggregeringsbrytere – MED 1ru-brytere utplassert i rekkene, er det mulig å sentralisere de større kjerne-og aggregeringsmodulære bryterne. Dette kan forenkle strøm og kabling infrastruktur og forbedre rack eiendomsmegling bruk.
•![]() Tillater layer 2 loop-free topology – et stort klyngenettverk som bruker Layer 3 ECMP-tilgang, kan bruke mye adresseplass på uplinks og kan legge til kompleksitet i designet. Dette er spesielt viktig hvis offentlig adresseområde brukes. Tre-lags modell tilnærming gir seg godt til Et Lag 2 loop-fri tilgang topologi som reduserer antall subnett som kreves.
Tillater layer 2 loop-free topology – et stort klyngenettverk som bruker Layer 3 ECMP-tilgang, kan bruke mye adresseplass på uplinks og kan legge til kompleksitet i designet. Dette er spesielt viktig hvis offentlig adresseområde brukes. Tre-lags modell tilnærming gir seg godt til Et Lag 2 loop-fri tilgang topologi som reduserer antall subnett som kreves.
når en lag 2-sløyfefri modell brukes, er det viktig å bruke en redundant standard gateway-protokoll som HSRP eller GLBP for å eliminere et enkelt feilpunkt hvis en aggregeringsnode mislykkes. I dette designet er aggregeringsmodulene ikke sammenkoblet, noe som tillater en sløyfefri Layer 2-design som kan utnytte GLBP for automatisk server standard gateway lastbalansering. GLBP distribuerer automatisk serverens standard gateway-tildeling mellom de to nodene i aggregeringsmodulen. Etter at en pakke ankommer aggregering laget, er det balansert over kjernen ved hjelp av 8-veis ECMP stoff. SELV OM GLBP ikke gir Et Lag 3/Lag 4 lastfordelingshash som LIGNER CEF, er DET et alternativ som kan brukes med En Layer 2 access topology.
Beregning Av Overskrift
modellen på tre nivåer introduserer to punkter med overskrift på access-og aggregeringslagene, sammenlignet med modellen på to nivåer som bare har ett punkt med overskrift på access-laget. For å beregne den omtrentlige båndbredden per server og overskriftsforholdet riktig, utfør følgende to trinn, som bruker Figur 3-8 som et eksempel:
Trinn 1 ![]() Beregn overskriftsforholdet og båndbredden per server for både aggregerings-og tilgangslagene uavhengig.
Beregn overskriftsforholdet og båndbredden per server for både aggregerings-og tilgangslagene uavhengig.
•![]() Access layer
Access layer
–![]() Overskrift – 48ge vedlagte servere / 20G uplinks til aggregering = 2.4:1
Overskrift – 48ge vedlagte servere / 20G uplinks til aggregering = 2.4:1
–![]() Båndbredde per server – 20g uplinks til aggregering / 48GigE vedlagte servere = 416Mbps
Båndbredde per server – 20g uplinks til aggregering / 48GigE vedlagte servere = 416Mbps
•![]() Aggregering lag
Aggregering lag
–![]() Overskrift – 120g nedkoblinger til tilgang / 80G uplinks til kjerne = 1.5:1
Overskrift – 120g nedkoblinger til tilgang / 80G uplinks til kjerne = 1.5:1
Trinn 2 ![]() Beregn det kombinerte overskriftsforholdet og båndbredden per server.
Beregn det kombinerte overskriftsforholdet og båndbredden per server.
det faktiske overskriftsforholdet er summen av de to overskriftspunktene på tilgangs – og aggregeringslagene.
1.5*2.4 = 3.6:1
hvis du vil bestemme den sanne båndbredden per serververdi, bruker du den algebraiske formelen for proporsjoner:
a: b = c: d
båndbredden per server på access-laget er fastslått å være 416 Mbps per server. Fordi aggregering lag overskrift forholdet er 1,5: 1, kan du bruke formelen ovenfor som følger:
416:1 = x:1.5
x = ~264 Mbps per server
Anbefalt Maskinvare Og Moduler
de anbefalte plattformene for serverklyngemodellutformingen består av Cisco Catalyst 6500-familien Med Sup720-prosessormodulen og Catalyst 4948-10ge 1RU-bryteren. Den høye bryterhastigheten, storbryterduk, lav latens, distribuert videresending og 10gige tetthet gjør Catalyst 6500-Seriebryteren ideell for alle lag i denne modellen. 1ru formfaktor kombinert med wire hastighet videresending, 10ge uplinks, og svært lav konstant ventetid gjør 4948-10GE en utmerket toppen av rack løsning for tilgang laget.
følgende anbefales:
•![]() Sup720-Sup720 kan bestå av BÅDE PFC3A (standard) eller nyere PFC3B type datterkort.
Sup720-Sup720 kan bestå av BÅDE PFC3A (standard) eller nyere PFC3B type datterkort.
•![]() Linjekort – alle linjekort skal være 6700-Serien og skal alle være aktivert for distribuert videresending med dfc3a-eller DFC3B-datterkortene.
Linjekort – alle linjekort skal være 6700-Serien og skal alle være aktivert for distribuert videresending med dfc3a-eller DFC3B-datterkortene.
Merk ![]() ved å bruke alle STOFFTILKOBLEDE CEF720-seriemoduler, er global switching mode kompakt, noe som gjør at systemet kan operere på sitt høyeste ytelsesnivå. Catalyst 6509 kan stotte 10 gige moduler i alle posisjoner fordi hvert spor stotter to kanaler til bryterstoffet (Cisco Catalyst 6513 stotter ikke dette).
ved å bruke alle STOFFTILKOBLEDE CEF720-seriemoduler, er global switching mode kompakt, noe som gjør at systemet kan operere på sitt høyeste ytelsesnivå. Catalyst 6509 kan stotte 10 gige moduler i alle posisjoner fordi hvert spor stotter to kanaler til bryterstoffet (Cisco Catalyst 6513 stotter ikke dette).
•![]() Cisco Catalyst 4948-10ge-Den 4948-10ge gir en hoy ytelse tilgang lag losning som kan utnytte ECMP og 10GIGE uplinks. Ingen spesielle krav er nodvendige. 4948 – 10GE kan bruke Et Layer 2 Cisco IOS-bilde eller Et Layer 2/3 Cisco IOS-bilde, noe som gir en optimal passform i begge miljøer.
Cisco Catalyst 4948-10ge-Den 4948-10ge gir en hoy ytelse tilgang lag losning som kan utnytte ECMP og 10GIGE uplinks. Ingen spesielle krav er nodvendige. 4948 – 10GE kan bruke Et Layer 2 Cisco IOS-bilde eller Et Layer 2/3 Cisco IOS-bilde, noe som gir en optimal passform i begge miljøer.