




Cisco Data Center Infrastructure2.5Design Guide
イーサネットを使用したサーバクラスタ設計
サーバクラスタモデルで使用されるサーバとネットワークコンポーネントの概要は、第1章”データセンターアーキテクチャの概要”で説明されています。”この章では、サーバークラスタモデルの各層の目的と機能をより詳細に説明します。 次のセクションが含まれています:
•![]() 技術的な目的
技術的な目的
•![]() 分散転送と遅延
分散転送と遅延
•![]() 等コストのマルチパスルーティング
等コストのマルチパスルーティング
•![]() サーバークラスター設計-二層モデル
サーバークラスター設計-二層モデル
•![]() サーバークラスター設計-三層モデル
サーバークラスター設計-三層モデル
•![]() 推奨されるハードウェアおよびモジュール
推奨されるハードウェアおよびモジュール

注![]() この章で説明する設計モデルは、必要なテストの規模と範囲のため、Cisco lab testingでは完全に検証されていません。 カバーされている二層モデルは、顧客の生産ネットワークに実装されている同様の設計です。
この章で説明する設計モデルは、必要なテストの規模と範囲のため、Cisco lab testingでは完全に検証されていません。 カバーされている二層モデルは、顧客の生産ネットワークに実装されている同様の設計です。
技術目標
大規模なエンタープライズクラスターネットワークを設計する際には、具体的な目標を検討することが重要です。 それぞれに固有の要件があり、特定の設計要件を決定するためにアプリケーションの観点から検討する必要があります。 次の技術的な考慮事項を考慮してください:
•![]() 遅延-ネットワークトランスポートでは、遅延がクラスター全体のパフォーマンスに悪影響を与える可能性があります。 低遅延スイッチングアーキテクチャを採用したスイッチングプラットフォームを使用すると、最適なパフォーマ レイテンシの主な原因は、サーバーで使用されるプロトコルスタックとNICハードウェア実装です。 TCPオフロードエンジン(TOE)やリモートダイレクトメモリアクセス(RDMA)などのドライバの最適化とCPUオフロード技術は、レイテンシを減らし、サーバー上の処理オーバヘッドを削減するのに役立ちます。
遅延-ネットワークトランスポートでは、遅延がクラスター全体のパフォーマンスに悪影響を与える可能性があります。 低遅延スイッチングアーキテクチャを採用したスイッチングプラットフォームを使用すると、最適なパフォーマ レイテンシの主な原因は、サーバーで使用されるプロトコルスタックとNICハードウェア実装です。 TCPオフロードエンジン(TOE)やリモートダイレクトメモリアクセス(RDMA)などのドライバの最適化とCPUオフロード技術は、レイテンシを減らし、サーバー上の処理オーバヘッドを削減するのに役立ちます。
レイテンシは、クラスター設計において常に重要な要素であるとは限りません。 たとえば、一部のクラスターでは、大量の一括ファイル転送のためにサーバー間で高い帯域幅が必要になる場合がありますが、サーバー間プロセス間通信(IPC)メッセー
•![]() メッシュ/部分メッシュ接続-サーバークラスターの設計では、通常、クラスタ内のすべてのノード間の通信を許可するためにメッシュまたは部分メッシュファブリックが必要です。 このメッシュファブリックは、クラスター内のマスター-ツー-コンピューティングサーバーとコンピューティング-ツー-コンピューティングサーバー間で状態、データ、およ メッシュまたは部分メッシュ接続もアプリケーションに依存します。
メッシュ/部分メッシュ接続-サーバークラスターの設計では、通常、クラスタ内のすべてのノード間の通信を許可するためにメッシュまたは部分メッシュファブリックが必要です。 このメッシュファブリックは、クラスター内のマスター-ツー-コンピューティングサーバーとコンピューティング-ツー-コンピューティングサーバー間で状態、データ、およ メッシュまたは部分メッシュ接続もアプリケーションに依存します。
•![]() 高スループット-特定の時間内に大きなファイルを送信する機能は、クラスターの操作とパフォーマンスにとって重要です。 サーバークラスターは、通常、利用可能な非ブロッキング帯域幅の最小量を必要とし、アクセス層とコア層の間の低オーバーサブスクリプションモデルに変換
高スループット-特定の時間内に大きなファイルを送信する機能は、クラスターの操作とパフォーマンスにとって重要です。 サーバークラスターは、通常、利用可能な非ブロッキング帯域幅の最小量を必要とし、アクセス層とコア層の間の低オーバーサブスクリプションモデルに変換
•![]() オーバーサブスクリプション比-ファブリック帯域幅を切り替えるラインカードやアップリンク帯域幅へのスイッチファブリック入力など、設計内の複数のアグリゲーションポイントでオーバーサブスクリプション比を調べる必要があります。
オーバーサブスクリプション比-ファブリック帯域幅を切り替えるラインカードやアップリンク帯域幅へのスイッチファブリック入力など、設計内の複数のアグリゲーションポイントでオーバーサブスクリプション比を調べる必要があります。
•![]() ジャンボフレームのサポート-ジャンボフレームは、サーバークラスターの初期実装では使用されない場合がありますが、追加の柔軟性や将来の可能性のある要件のために必要な非常に重要な機能です。 TCP/IPパケットの構築は、サーバー CPUに追加のオーバーヘッドを配置します。 ジャンボフレームを使用すると、パケットの数を減らすことができ、このオーバーヘッドを削減できます。
ジャンボフレームのサポート-ジャンボフレームは、サーバークラスターの初期実装では使用されない場合がありますが、追加の柔軟性や将来の可能性のある要件のために必要な非常に重要な機能です。 TCP/IPパケットの構築は、サーバー CPUに追加のオーバーヘッドを配置します。 ジャンボフレームを使用すると、パケットの数を減らすことができ、このオーバーヘッドを削減できます。
•![]() ポート密度-サーバークラスタは数万のポートに拡張する必要がある場合があります。 そのため、高いパケットスイッチング性能、大量のスイッチファブリック帯域幅、および高レベルのポート密度を備えたプラットフォームが必要になります。
ポート密度-サーバークラスタは数万のポートに拡張する必要がある場合があります。 そのため、高いパケットスイッチング性能、大量のスイッチファブリック帯域幅、および高レベルのポート密度を備えたプラットフォームが必要になります。
Distributed Forwarding and Latency
Cisco Catalyst6500シリーズスイッチは、中央パケット転送またはオプションの分散転送アーキテクチャをサポートするユニークな機能を備えていますが、Cisco Catalyst4948-10GEは、固定回線レート転送性能を備えた単一の中央ASIC設計です。 Cisco6700ラインカードモジュールは、Distributed Forwarding Card(DFC;Distributed Forwarding Card)と呼ばれるオプションのドーターカードモジュールをサポートします。 DFCは、ローカル転送情報ベース(FIB)を実装することにより、各ラインカードでローカルルーティングの決定を行うことを許可します。 Sup720PFC上のFIBテーブルは、ラインカード上の各DFC FIBテーブルとの同期を維持して、システム全体のルーティングの整合性を確保します。
オプションのDFCカードが存在しない場合、コンパクトヘッダルックアップがSup720のPFC3に送信され、スイッチファブリック上のどこで各パケットを転送す DFCが存在する場合、ラインカードは、Sup720に相談せずに、スイッチファブリックを介してパケットを宛先ラインカードに直接切り替えることができます。 パフォーマンスの違いは、Dfcを使用しないシステム全体で30Mppsから、Dfcを使用するスロットあたり48Mppsになります。 固定構成のCatalyst4948-10GEスイッチには、ワイヤレート、最大101.18Mppsの性能をサポートするノンブロッキングアーキテクチャがあり、ラック設計のトップに優れたア
分散型転送モデルと中央転送モデルを比較すると、レイテンシのパフォーマンスが大きく異なる場合があります。 表3-1に、Dfcの有無にかかわらず6704ラインカードで測定されたレイテンシの例を示します。
| 6704 DFCを使って(スイッチ生地を通したマイクロ秒の港に港) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
パケットサイズ(B) |
||||||||||
|
レイテンシ(ミリ秒) |
||||||||||
| 6704 DFCなし(スイッチ-ファブリックを介したマイクロ秒単位のポート-ツー-ポート) | ||||||||||
|
パケットサイズ(B) |
||||||||||
|
レイテンシ(ミリ秒) |
||||||||||
DFC対応とdfc対応とのレイテンシの違い 非DFC対応ラインカードは重要な表示されない場合があります。 ただし、6500中央転送アーキテクチャでは、中央バス上の共有参照の競合のために、トラフィック率が増加するにつれて遅延が増加する可能性があります。 DFCでは、ルックアップパスは各ラインカード専用であり、レイテンシは一定です。 Catalyst6500システム帯域幅dfcを使用しても、使用可能なシステム帯域幅は変更されません。 Dfcは、システム全体のpps(packets per second)処理を改善します。 表3-2は、古いCEF256および従来のバスモジュールに加えて、Dfcをサポートするモジュールのスループットと帯域幅のパフォーマンスをまとめたものです。
| Sup720によるシステム構成 | Mppsでのスループット | 帯域幅Gbpsでのスループット | |
|
クラシックシリーズモジュール |
最大15Mpps(システムごと)) |
16 G共用バス(クラシックバス) |
|
|
CEF256シリーズモジュール |
最大30Mpps(システムごと)) |
1x8G(スロットごとに専用) |
|
|
cef256またはCEF720シリーズモジュールとの古典の組合せ |
最大15Mpps(システムごと)) |
カード依存 |
|
|
CEF720シリーズモジュール(6748, 6704, 6724) |
最大30Mpps(システムごと)) |
2x20g(スロットあたり専用) |
|
|
CEF720シリーズモジュール、DFC3搭載(6704、DFC3搭載、6708、DFC3搭載、6748、DFC3 6724+DFC3) |
サスティーン 最大48Mpps(スロットあたり)) |
2x20g(スロットあたり専用) |
6513は大規模クラスタモデルのアクセス層に有効なソリューションである可能性がありますが、このシャーシにはシングルチャネルスロットとデュアルチャネルスロットが混在していることに注意してください。 図3-1に示すように、スロット1~8はシングルチャネル、スロット9~13はデュアルチャネルです。 Cisco Catalyst6513を使用する場合、6704-4ポート10GigE、6708-8ポート10GigE、および6748-48ポートSFP/copperラインカードなどのデュアルチャネルカードは、スロット9 13にのみ配置できます。 6724-24ポートSFP/copperラインカードなどの単一チャネルラインカードは、スロット1 8で使用できます。 Sup720は接続される単一チャネル20Gの生地であるスロット7および8を使用する。 6513とは対照的に、6509は使用可能なスロットが少なくなりますが、各スロットにはスイッチファブリックへのデュアルチャネルがあるため、すべてのス
注![]() サーバークラスタ環境では、通常、低レイテンシ特性を持つ高帯域幅が必要なため、これらのタイプの設計ではDfcを使用することをお勧めします。
サーバークラスタ環境では、通常、低レイテンシ特性を持つ高帯域幅が必要なため、これらのタイプの設計ではDfcを使用することをお勧めします。
Equal Cost Multi-Path Routing
EQUAL cost multi-path(ECMP)routingは、Cisco Express Forwardingが有効な環境内の任意の2つのサブネット間の複数のIPパスにわたるフローを最適化する負荷分散技術です。 ECMPは、フローごとにTCPおよびUDPパケットの負荷分散を適用します。 ICMPなどの非TCP/UDPパケットは、パケットごとに分散されます。 ECMPはRFC2991に基づいており、PIXやCisco Content Services Switch(CSS)製品などの他のシスコプラットフォームで活用されています。 ECMPは、サーバクラスタ設計で推奨される6500および4948-10GEプラットフォームの両方でサポートされます。
レイヤ3スイッチングハードウェアAsicとCisco Express Forwarding hashingアルゴリズムに起因する劇的な変更は、ECMPをその前身の技術と区別するのに役立ちます。 サーバークラスター実装のECMP設計の主な利点は、レイヤ3スイッチングにおけるCPUオーバーヘッドがほとんどまたはまったくないハッシングアルゴリズムです。 Cisco Express Forwarding hashing algorithmは、ハードウェアのラインレートで複数のラインカードにきめ細かなフローを分散できます。 ハッシュアルゴリズムの既定の設定では、レイヤ3の送信元と宛先のIPアドレスに基づいてフローをハッシュし、オプションでレイヤ4のポート番号を追加して差別化を追加します。 許可されるECMPパスの最大数は8です。
図3-2は、8方向ECMPサーバクラスタの設計を示しています。 図を簡単にするために、2つのアクセスレイヤスイッチのみが示されていますが、最大32までサポートできます(コアノードあたり64 10Giges)。
図3-2 8方向ECMPサーバクラスタの設計
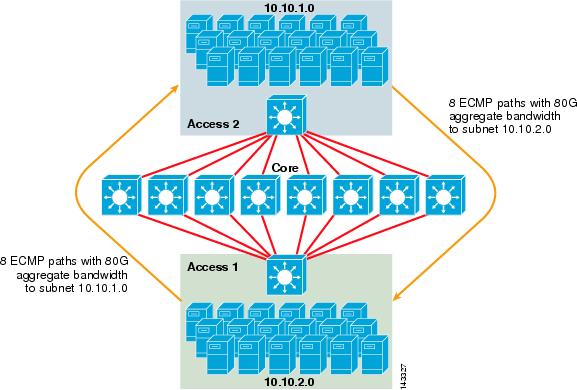
図3-2では、各アクセスレイヤスイッチは接続されたサーバの1つ以上のサブネットをサポートできます。 各スイッチに2つの6704ラインカードを使用して8つの中心スイッチのそれぞれへの単一の10GigE接続があります。 この設定では、サーバクラスタファブリック内の他のサブネットへの合計80GのCisco Express Forwarding対応帯域幅に対して10GigEの8つのパスが提供されます。 別のスイッチ上の別のサブネットへのshow ip routeクエリには、8つの等コストエントリが表示されます。
コアにはDFCsを搭載した10gigeラインカードが搭載されており、ポート間レイテンシが非常に低い完全分散高速スイッチングファブリックを可能にします。 アクセスレイヤスイッチへのshow ip routeクエリには、8つのコアスイッチのそれぞれに単一のルートエントリが表示されます。 注このガイドではテストされていませんが、Catalyst6500シリーズスイッチ用に最近導入された新しい8ポート10ギガビットイーサネットモジュールWS-X6708-10G-3C このラインカードは、後日、このガイドに記載されているかどうかテストされます。 8ポート10GigEカードに関するご質問は、製品データシートを参照してください。
サーバークラスタ設計における冗長性
サーバークラスタ設計は、通常、冗長CPUまたはスイッチファブリックプロセッサでは実装されません。 復元性は、典型的には、設計において本質的に達成され、方法によって、クラスタ全体として機能する。 第1章”データセンターアーキテクチャの概要”で説明したように、クラスタ内の計算ノードは、各計算ノードに特定のジョブを割り当て、そのパフォーマンスを監 計算ノードがクラスターから削除されると、使用可能なノードに再割り当てされ、処理能力は低くなりますが、ノードが使用可能になるまで動作を続けます。 異なるアクセススイッチ間でクラスタ内のマスターノード接続を多様化することは重要ですが、計算ノードにとっては重要ではありません。
冗長Cpuは確かにオプションですが、ポート密度、特に冗長Sup720モジュールの代わりに余分なスロットが利用可能な10GEポートに関しては、ポート密度を考慮す
注![]() この章の例では、非冗長CPU設計を使用しており、6708 8ポート10GIGEラインカードの使用に基づいて、アクセスノードのアップリンク接続に使用可能な6509コアノードあたり最大64個の10GEポートを許可しています。
この章の例では、非冗長CPU設計を使用しており、6708 8ポート10GIGEラインカードの使用に基づいて、アクセスノードのアップリンク接続に使用可能な6509コアノードあたり最大64個の10GEポートを許可しています。
サーバークラスター設計—二層モデル
このセクションでは、ECMPと分散CEFを活用したサーバークラスター設計のさまざまなアプローチについて説明します。 各設計では、異なる構成がさまざまなオーバーサブスクリプション-レベルを達成し、柔軟な方法で拡張できる方法を示しています。
サーバークラスターの設計は、通常、コア層とアクセス層で構成される二層モデルに従います。 設計目標では、サーバごとに非常に確定的な帯域幅と遅延を実現するためにレイヤ3ECMPと分散転送を使用する必要があるため、別のオーバーサブスクリプショ 三層モデルの利点については、”サーバークラスターの設計—三層モデル”を参照してください。
サーバークラスタソリューションを設計する際に考慮すべき主な計算は、最大サーバー接続、サーバーあたりの帯域幅、およびオーバーサブスクリプション比です。 クラスター設計者は、アプリケーションのパフォーマンス、サーバーハードウェア、および次のようなその他の要因に基づいて、これらの値を決定できます:
•![]() スケールでのサーバー GigE接続の最大数-クラスタ設計者は、通常、最初の概念で必要な最大スケールのアイデアを持っています。 ECMP設計の機能の利点は、特定の帯域幅、レイテンシ、およびオーバーサブスクリプションの要件を満たす最小数のスイッチおよびサーバーから開始でき、同じ帯域幅、レイテンシ、およびオーバーサブスクリプションの値を維持しながら、低/非破壊的な方法で柔軟に最大スケールまで拡張できることです。
スケールでのサーバー GigE接続の最大数-クラスタ設計者は、通常、最初の概念で必要な最大スケールのアイデアを持っています。 ECMP設計の機能の利点は、特定の帯域幅、レイテンシ、およびオーバーサブスクリプションの要件を満たす最小数のスイッチおよびサーバーから開始でき、同じ帯域幅、レイテンシ、およびオーバーサブスクリプションの値を維持しながら、低/非破壊的な方法で柔軟に最大スケールまで拡張できることです。
•![]() •Approximate bandwidth per serverこの値は、集約されたアップリンクの合計帯域幅を、アクセスレイヤスイッチ上のサーバGigE接続の合計で除算するだけで決定できます。 たとえば、336個のサーバアクセスポートを持つ4つの10GigE ECMPアップリンクを持つアクセスレイヤCisco6509は、次のように計算できます。
•Approximate bandwidth per serverこの値は、集約されたアップリンクの合計帯域幅を、アクセスレイヤスイッチ上のサーバGigE接続の合計で除算するだけで決定できます。 たとえば、336個のサーバアクセスポートを持つ4つの10GigE ECMPアップリンクを持つアクセスレイヤCisco6509は、次のように計算できます。
336個のサーバを持つ4x10GigEアップリンク=サーバあたり120Mbps
式のいずれかの側を調整すると、サーバあたりの帯域幅の量が減少または増加します。
注![]() これはおおよその値であり、ガイドラインとしてのみ機能します。 さまざまな要因が、各サーバーが利用可能な実際の帯域幅に影響します。 ECMP負荷分散ハッシュアルゴリズムは、レイヤ3とレイヤ4の値に基づいて負荷を分割し、トラフィックパターンに基づいて変化します。 また、レート制限、キューイング、およびQoS値などの設定パラメータは、サーバごとに実際に達成される帯域幅に影響を与える可能性があります。
これはおおよその値であり、ガイドラインとしてのみ機能します。 さまざまな要因が、各サーバーが利用可能な実際の帯域幅に影響します。 ECMP負荷分散ハッシュアルゴリズムは、レイヤ3とレイヤ4の値に基づいて負荷を分割し、トラフィックパターンに基づいて変化します。 また、レート制限、キューイング、およびQoS値などの設定パラメータは、サーバごとに実際に達成される帯域幅に影響を与える可能性があります。
•![]() Oversubscription ratio per server-この値は、サーバー GigE接続の合計数をアクセスレイヤスイッチ上の集約されたアップリンク帯域幅の合計で除算するだけで決定できます。 たとえば、10gige ECMPアップリンクが336個のサーバーアクセスポートを持つアクセスレイヤ6509は、
Oversubscription ratio per server-この値は、サーバー GigE接続の合計数をアクセスレイヤスイッチ上の集約されたアップリンク帯域幅の合計で除算するだけで決定できます。 たとえば、10gige ECMPアップリンクが336個のサーバーアクセスポートを持つアクセスレイヤ6509は、
336GigEサーバー接続が40Gアップリンク帯域幅=8.4:1オーバーサブスクリプション比
以下のセクションでは、ハードウェアおよび相互接続構成の違いに基づいてこれらの値がどのように変化するかを示しており、大規模なクラスタ構成を設計する際のガイドラインとして機能します。
注![]() 計算のために、Catalyst6500シリーズスイッチにファブリックのオーバーサブスクリプションを切り替えるラインカードがないことが前提とされています。 デュアルチャネルスロットはスイッチ生地に40G最高の帯域幅を提供します。 最大サイズのパケットを使用してラインレートですべてのポートを持つ4ポート10gigeカードは、オーバーサブスクリプションがほとんど、あるいはまったくな 使用可能なスイッチファブリック帯域幅の実際の量は、平均パケットサイズに基づいて異なります。 2:1でオーバーサブスクライブされるWS-X6708 8ポート10GigEカードを使用する場合は、これらの計算を再計算する必要があります。
計算のために、Catalyst6500シリーズスイッチにファブリックのオーバーサブスクリプションを切り替えるラインカードがないことが前提とされています。 デュアルチャネルスロットはスイッチ生地に40G最高の帯域幅を提供します。 最大サイズのパケットを使用してラインレートですべてのポートを持つ4ポート10gigeカードは、オーバーサブスクリプションがほとんど、あるいはまったくな 使用可能なスイッチファブリック帯域幅の実際の量は、平均パケットサイズに基づいて異なります。 2:1でオーバーサブスクライブされるWS-X6708 8ポート10GigEカードを使用する場合は、これらの計算を再計算する必要があります。
モジュラーアクセスを使用した4ウェイおよび8ウェイECMP設計
以下の四つの設計例は、4ウェイおよび8ウェイECMPを使用して二層サーバクラスターモデ 考慮すべき主な問題は、コアノードの数とアップリンクの最大数です。これは、最大スケール、サーバーあたりの帯域幅、およびオーバーサブスクリプションの値に直接影響するためです。 注このガイドではテストされていませんが、Catalyst6500シリーズスイッチ用に最近導入された新しい8ポート10ギガビットイーサネットモジュールWS-X6708-10G-3C このラインカードは、後日、ガイドに記載されているかどうかテストされます。 8ポート10GigEカードに関するご質問は、製品データシートを参照してください。
注![]() サーバークラスターを外部キャンパスまたはメトロネットワークに接続するために必要なリンクは、これらの設計例には示されていませんが、考慮すべき
サーバークラスターを外部キャンパスまたはメトロネットワークに接続するために必要なリンクは、これらの設計例には示されていませんが、考慮すべき
図3-3は、4方向ECMPソリューションを提供するために二つのコアノードを使用する例を示しています。
図3-3 2つのコアノードを使用した4ウェイECMP
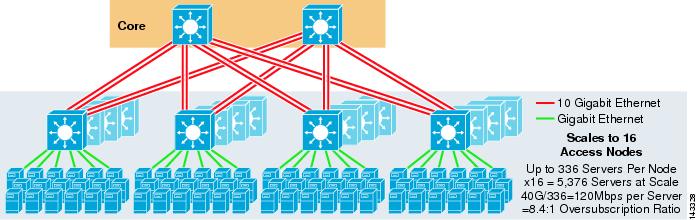
このアプローチの利点は、少数のコアスイッチで多数のサーバをサポートできることです。 考えられる欠点は、サーバー値ごとの帯域幅が低く、コアノードの障害に大きな影響を与えるという、オーバーサブスクリプションが高いことです。 アップリンクは個々のL3アップリンクであり、Etherchannelではないことに注意してください。
図3-4は、以前の設計に二つのコアノードを追加すると、同じオーバーサブスクリプションとサーバーごとの帯域幅の値を維持しながら、最大スケールを劇的に増
図3-4 4つのコアノードを使用した4方向ECMP
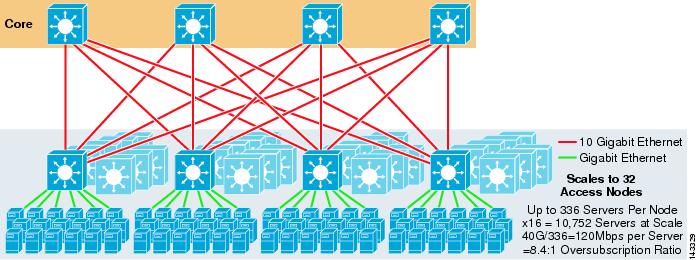
図3-5に、2つのコアノードを使用した8方向ECMP設計を示します。
図3-5 2つのコアノードを使用した8ウェイECMP
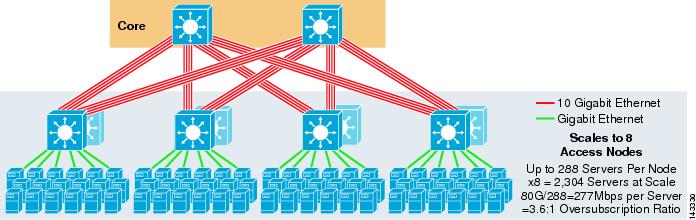
予想どおり、追加のアップリンク帯域幅はサーバーごとの帯域幅を劇的に増加させ、サーバーごとのオーバーサブスクリプ 8方向アップリンクをサポートするために各アクセスレイヤスイッチで追加のスロットを使用すると、スイッチごとのサーバ数が288に減少するため、最 アップリンクは個々のL3アップリンクであり、Etherchannelではないことに注意してください。
図3-6に、8つのコアノードを持つ8方向ECMP設計を示します。
図3-6 8つのコアノードを使用した8ウェイECMP
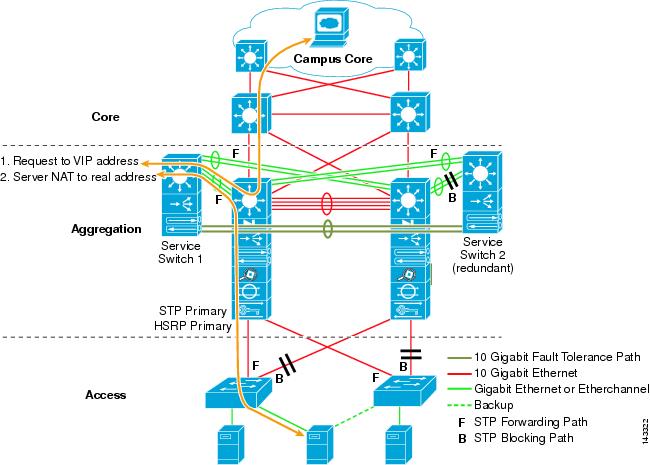
これは、同じ以前の設計に四つのコアノードを追加すると、同じオーバーサブスクリプションとサーバーごとの帯域幅の値を維持しながら、最大スケールを劇的に増加させることができる方法を示しています。
1RUアクセスによる2ウェイECMP設計
多くのクラスター環境では、ケーブル配線、管理、不動産の問題、または特定の展開モデルの目標を達成するために、各サーバーラックの上部にある小さなスイッチを使用したラックベースのサーバースイッチングが望まれているか、または必要とされています。
図3-7に、1RU4948-10GEアクセススイッチを備えた2ウェイECMPソリューションを提供するために2つのコアノードを使用する例を示します。
図3-7 2つのコアノードと1RUアクセスを使用した2ウェイECMP
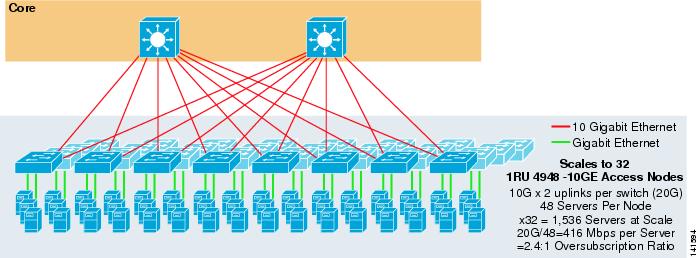
最大規模は1536台のサーバに制限されますが、オーバーサブスクリプション比が低い400Mbps 4948には2つの10GigEアップリンクしかないため、この設計ではこれらの値を超えて拡張することはできません。
注![]() ラックベースのサーバー切り替えの詳細については、第3章”イーサネットを使用したサーバークラスタ設計”を参照してください。”
ラックベースのサーバー切り替えの詳細については、第3章”イーサネットを使用したサーバークラスタ設計”を参照してください。”
サーバークラスタデザイン—三層モデル
大規模なクラスタ設計では二層モデルが最も一般的ですが、三層モデルも使用できます。 3層モデルは、通常、1RUまたはモジュラーアクセスレイヤスイッチを使用した大規模なサーバークラスター実装をサポートするために使用されます。
図3-8に、6500コアおよび集約スイッチおよび1RU4948-10GEアクセスレイヤスイッチを使用した8ウェイECMPを活用した大規模な例を示します。
図3-8 8ウェイECMPを搭載した三層モデル
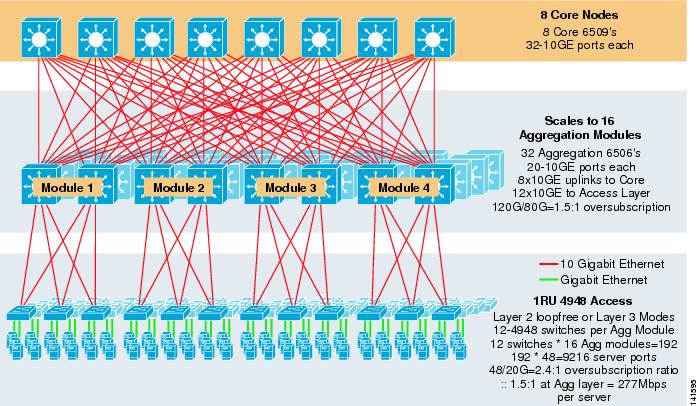
最大スケールは9200台を超え、帯域幅は277Mbpsで、オーバーサブスクリプション比は低いです。 1RUアクセススイッチを使用した三層アプローチの利点は次のとおりです:
•![]() 1RU展開モデル-前述したように、多くの大規模なクラスターモデル展開では、インストールを簡素化するために1RUアプローチが必要です。 たとえば、ASPは、大規模なクラスターアプリケーションをスケールするときに、サーバーのラックを一度にロールアウトします。 サーバーラックは、実行中のクラスターに迅速にインストールして追加できるように、事前に組み立てられ、オフサイトでステージングされます。 これには、通常、ラックを構築し、サーバーを事前に構成し、電源とイーサネットを1RUスイッチに事前にケーブル接続するサードパーティが含まれます。 ラックはデータセンターにロールし、アップリンクを接続した後に単に接続され、クラスタに追加されます。
1RU展開モデル-前述したように、多くの大規模なクラスターモデル展開では、インストールを簡素化するために1RUアプローチが必要です。 たとえば、ASPは、大規模なクラスターアプリケーションをスケールするときに、サーバーのラックを一度にロールアウトします。 サーバーラックは、実行中のクラスターに迅速にインストールして追加できるように、事前に組み立てられ、オフサイトでステージングされます。 これには、通常、ラックを構築し、サーバーを事前に構成し、電源とイーサネットを1RUスイッチに事前にケーブル接続するサードパーティが含まれます。 ラックはデータセンターにロールし、アップリンクを接続した後に単に接続され、クラスタに追加されます。
集約レイヤーがない場合、1RUアクセスモデルの最大サイズは1500台のサーバーに制限されます。 集約レイヤーを追加すると、1RUアクセスモデルはECMPモデルを引き続き活用しながら、はるかに大きなサイズに拡張できます。
•![]() 中心および集合スイッチの集中化—棚で配置されて1RUスイッチがより大きい中心および集合モジュラースイッチを集中させることは可能である。 これにより、電力とケーブルのインフラストラクチャが簡素化され、ラック不動産の使用が改善されます。
中心および集合スイッチの集中化—棚で配置されて1RUスイッチがより大きい中心および集合モジュラースイッチを集中させることは可能である。 これにより、電力とケーブルのインフラストラクチャが簡素化され、ラック不動産の使用が改善されます。
•![]() レイヤ3ECMPアクセスを使用する大規模なクラスタネットワークでは、アップリンクで多くのアドレス空間を使用でき、設計が複雑になる可能性があ これは、パブリック-アドレス-スペースが使用される場合に特に重要です。 三層モデルのアプローチは、必要なサブネットの数を減らすレイヤ2ループフリーアクセストポロジに適しています。
レイヤ3ECMPアクセスを使用する大規模なクラスタネットワークでは、アップリンクで多くのアドレス空間を使用でき、設計が複雑になる可能性があ これは、パブリック-アドレス-スペースが使用される場合に特に重要です。 三層モデルのアプローチは、必要なサブネットの数を減らすレイヤ2ループフリーアクセストポロジに適しています。
レイヤ2ループフリーモデルを使用する場合、集約ノードに障害が発生した場合に、HSRPやGLBPなどの冗長デフォルトゲートウェイプロトコルを使用して、単 この設計では、集約モジュールは相互接続されていないため、GLBPを利用してサーバーのデフォルトゲートウェイの負荷分散を自動化できるループフリーのレイヤ2 GLBPは、集約モジュール内の二つのノード間でサーバーのデフォルトゲートウェイ割り当てを自動的に配布します。 パケットが集約層に到着した後、8-way ECMPファブリックを使用してコア全体でバランスが取られます。 GLBPはCEFと同様のレイヤ3/レイヤ4負荷分散ハッシュを提供しませんが、レイヤ2アクセストポロジで使用できる代替手段です。
オーバーサブスクリプションの計算
三層モデルは、アクセス層に単一のオーバーサブスクリプションのポイントのみを持つ二層モデルと比較して、アクセス層とアグリゲーション層に二つのオーバーサブスクリプションのポイントを導入しています。 図3-8を例にして、
ステップ1![]() 集約レイヤとアクセスレイヤの両方について、オーバーサブスクリプション比とサーバあたりの帯域幅を個別に計算します。
集約レイヤとアクセスレイヤの両方について、オーバーサブスクリプション比とサーバあたりの帯域幅を個別に計算します。
•![]() アクセス層
アクセス層
–![]() オーバーサブスクリプション-48GE接続サーバー/20Gアップリンクから集約= 2.4:1
オーバーサブスクリプション-48GE接続サーバー/20Gアップリンクから集約= 2.4:1
–![]() サーバごとの帯域幅-集約への20Gアップリンク/48GigE接続サーバ=416Mbps
サーバごとの帯域幅-集約への20Gアップリンク/48GigE接続サーバ=416Mbps
•![]() アグリゲーション層
アグリゲーション層
–![]() オーバーサブスクリプション-アクセスへの120Gダウンリンク/コアへの80Gアップリンク= 1.5:1
オーバーサブスクリプション-アクセスへの120Gダウンリンク/コアへの80Gアップリンク= 1.5:1
ステップ2![]() サーバごとのオーバーサブスクリプション率と帯域幅の合計を計算します。
サーバごとのオーバーサブスクリプション率と帯域幅の合計を計算します。
実際のオーバーサブスクリプション比は、アクセス層と集約層でのオーバーサブスクリプションの二つのポイントの合計です。
1.5*2.4 = 3.6:1
a:b=c:d
アクセスレイヤにおけるサーバあたりの帯域幅は、サーバあたり416Mbpsと決定されています。 集計レイヤーのオーバーサブスクリプション比は1.5:1であるため、上記の式を次のように適用できます:
416:1 = x:1.サーバクラスタモデル設計の推奨プラットフォームは、Cisco Catalyst6500ファミリとSup720プロセッサモジュール、およびCatalyst4948-10GE1RUスイッチで構成されています。 高い切換え率、大きいスイッチ生地、低い潜伏、分散転送および10gige密度は触媒をこのモデルのすべての層のための6500のシリーズスイッチ理想にする。 ワイヤー率の促進、10GEアップリンクおよび非常に低い一定した潜伏と結合される1RU形式要素は4948-10GEにアクセス層のための棚の解決の優秀な上をする。
以下が推奨されます:
•![]() •Sup720Sup720は、pfc3a(デフォルト)または新しいPFC3Bタイプのドーターカードの両方で構成できます。
•Sup720Sup720は、pfc3a(デフォルト)または新しいPFC3Bタイプのドーターカードの両方で構成できます。
•![]() •ラインカードすべてのラインカードは6700シリーズで、すべてdfc3AまたはDFC3Bドータカードで分散転送を有効にする必要があります。
•ラインカードすべてのラインカードは6700シリーズで、すべてdfc3AまたはDFC3Bドータカードで分散転送を有効にする必要があります。
注![]() すべてのファブリック接続CEF720シリーズモジュールを使用することにより、グローバルスイッチングモードはコンパクトであり、システムは最高のパフォーマ Catalyst6509は、各スロットがスイッチファブリックへのデュアルチャネルをサポートするため、すべての位置で10個のGigEモジュールをサポートできます(Cisco Catalyst6513はこれをサポートしていません)。
すべてのファブリック接続CEF720シリーズモジュールを使用することにより、グローバルスイッチングモードはコンパクトであり、システムは最高のパフォーマ Catalyst6509は、各スロットがスイッチファブリックへのデュアルチャネルをサポートするため、すべての位置で10個のGigEモジュールをサポートできます(Cisco Catalyst6513はこれをサポートしていません)。
•![]() Cisco Catalyst4948—10GE-4948-10GEは、ECMPおよび10GigEアップリンクを活用できる高性能アクセスレイヤソリューションを提供します。 特別な条件は必要ではないです。 4948-10GEでは、レイヤ2Cisco IOSイメージまたはレイヤ2/3Cisco IOSイメージを使用できるため、どちらの環境でも最適に適合できます。
Cisco Catalyst4948—10GE-4948-10GEは、ECMPおよび10GigEアップリンクを活用できる高性能アクセスレイヤソリューションを提供します。 特別な条件は必要ではないです。 4948-10GEでは、レイヤ2Cisco IOSイメージまたはレイヤ2/3Cisco IOSイメージを使用できるため、どちらの環境でも最適に適合できます。