




Crawling-Fehler: Die nächste Generation
Montag, 12. März 2012
Crawling-Fehler ist eine der beliebtesten Funktionen in Webmaster-Tools, und heute rollen wir einige sehr wichtige Verbesserungen, die es noch nützlicher machen.
Wir erkennen und melden jetzt viele neue Arten von Fehlern. Um die neuen Daten besser zu verstehen, haben wir die Fehler in zwei Teile unterteilt: Site-Fehler und URL-Fehler.
Websitefehler
Websitefehler sind Fehler, die nicht für eine bestimmte URL spezifisch sind — sie betreffen Ihre gesamte Website. Dazu gehören DNS-Auflösungsfehler, Verbindungsprobleme mit Ihrem Webserver und Probleme beim Abrufen Ihrer Robots.txt-Datei. Früher haben wir diese Fehler per URL gemeldet, aber das machte nicht viel Sinn, da sie nicht spezifisch für einzelne URLs sind — tatsächlich verhindern sie, dass Googlebot überhaupt eine URL anfordert! Stattdessen verfolgen wir jetzt die Ausfallraten für jede Art von standortweitem Fehler. Wir werden auch versuchen, Ihnen Benachrichtigungen zu senden, wenn diese Fehler häufig genug auftreten, dass sie Aufmerksamkeit erfordern.
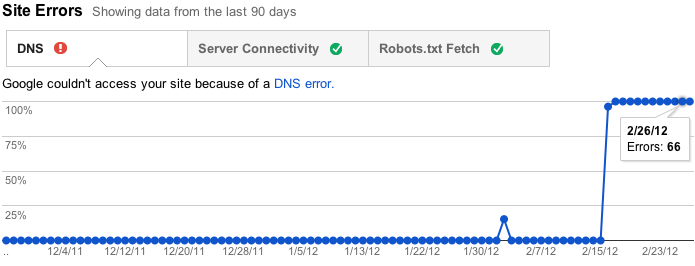
Wenn Sie in diesen Bereichen keine Probleme haben (und in letzter Zeit auch keine hatten), wie dies bei vielen Websites der Fall ist, werden wir Sie in diesem Abschnitt nicht stören. Stattdessen zeigen wir Ihnen nur ein paar freundliche Häkchen, damit Sie wissen, dass alles gut ist.

URL-Fehler
URL-Fehler sind Fehler, die für eine bestimmte Seite spezifisch sind. Dies bedeutet, dass Googlebot, als er versuchte, die URL zu crawlen, Ihren DNS auflösen, eine Verbindung zu Ihrem Server herstellen, Ihre Roboter abrufen und lesen konnte.txt-Datei, und fordern Sie dann diese URL an, aber danach ist etwas schief gelaufen. Wir unterteilen die URL-Fehler in verschiedene Kategorien, je nachdem, was den Fehler verursacht hat. Wenn Ihre Website Google News- oder Mobile-Daten (CHTML / XHTML) bereitstellt, werden für diese Fehler separate Kategorien angezeigt.

Weniger ist mehr
Früher haben wir Ihnen höchstens 100.000 Fehler jedes Typs angezeigt. Der Versuch, all diese Informationen zu konsumieren, war wie aus einem Feuerwehrschlauch zu trinken, und Sie hatten keine Möglichkeit zu wissen, welche dieser Fehler wichtig waren (Ihre Homepage ist nicht erreichbar) oder weniger wichtig (jemandes persönliche Website hat einen Tippfehler in einem Link zu Ihrer Website gemacht). Es gab keine realistische Möglichkeit, alle 100.000 Fehler anzuzeigen — keine Möglichkeit, Ihren Fortschritt zu sortieren, zu suchen oder zu markieren. In der neuen Version dieser Funktion haben wir uns darauf konzentriert, Ihnen nur die wichtigsten Fehler im Voraus mitzuteilen. Für jede Kategorie geben wir Ihnen, was wir denken, sind die 1000 wichtigsten und umsetzbare Fehler. Sie können diese Top-1000-Fehler sortieren und filtern, uns mitteilen, wann Sie glauben, sie behoben zu haben, und Details zu ihnen anzeigen.
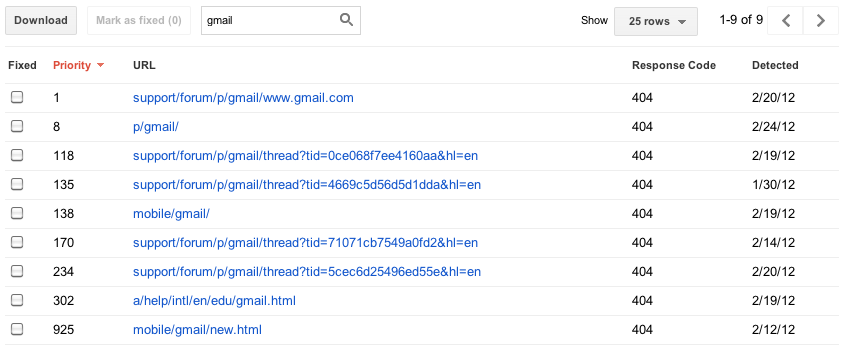
Einige Websites weisen mehr als 1000 Fehler eines bestimmten Typs auf, sodass Sie weiterhin die Gesamtzahl der Fehler jedes Typs sowie ein Diagramm mit historischen Daten anzeigen können, die 90 Tage zurückreichen. Für diejenigen, die befürchten, dass 1000 Fehlerdetails plus eine Gesamtsumme nicht ausreichen, erwägen wir, programmatischen Zugriff (eine API) hinzuzufügen, damit Sie jeden letzten Fehler herunterladen können.
Wir haben auch die Liste der von Robotern blockierten Seiten entfernt.txt, denn diese können manchmal nützlich sein, um ein Problem mit Ihren Robotern zu diagnostizieren.txt-Datei, sie sind häufig Seiten, die Sie absichtlich blockiert. Wir wollten uns wirklich auf Fehler konzentrieren, also suchen Sie nach Informationen zu Roboted URLs, die bald in der Funktion „Crawler Access“ unter „Site configuration“ angezeigt werden.
Tauchen Sie ein in die Details
Wenn Sie in der Hauptliste auf eine einzelne Fehler-URL klicken, wird ein Detailbereich mit zusätzlichen Informationen angezeigt, z. B. wann wir das letzte Mal versucht haben, die URL zu crawlen, wann wir zum ersten Mal ein Problem festgestellt haben, und eine kurze Erklärung des Fehlers.

Im Detailbereich können Sie auf den Link für die URL klicken, die den Fehler verursacht hat, um selbst zu sehen, was passiert, wenn Sie versuchen, sie zu besuchen. Sie können den Fehler auch als „behoben“ markieren (dazu später mehr!), Hilfeinhalte für den Fehlertyp anzeigen, Sitemaps auflisten, die die URL enthalten, andere Seiten anzeigen, die auf diese URL verlinken, und sogar den Googlebot die URL jetzt abrufen lassen, um weitere Informationen zu erhalten oder um zu überprüfen, ob Ihr Fix funktioniert hat.

Handeln Sie!
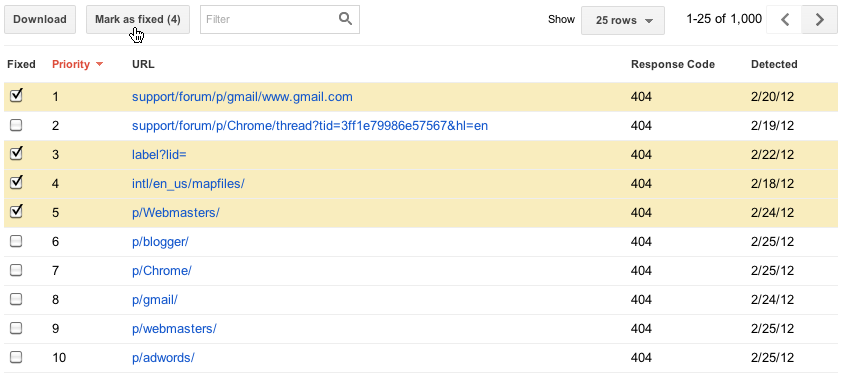
Eine Sache, über die wir uns in dieser neuen Version der Crawling-Fehler-Funktion wirklich freuen, ist, dass Sie sich wirklich darauf konzentrieren können, das Wichtigste zuerst zu beheben. Wir haben die Fehler so eingestuft, dass diejenigen, die ganz oben auf der Prioritätenliste stehen, diejenigen sind, bei denen Sie etwas tun können, sei es die Behebung defekter Links auf Ihrer eigenen Website, die Behebung von Fehlern in Ihrer Serversoftware, die Aktualisierung Ihrer Sitemaps, um tote URLs zu löschen, oder das Hinzufügen einer 301-Weiterleitung, um Benutzer auf die „echte“ Seite zu bringen. Wir bestimmen dies anhand einer Vielzahl von Faktoren, einschließlich der Frage, ob Sie die URL in eine Sitemap aufgenommen haben oder nicht, von wie vielen Stellen aus sie verlinkt ist (und ob sich eine davon auch auf Ihrer Website befindet) und ob die URL in letzter Zeit Traffic von der Suche erhalten hat.
Sobald Sie glauben, das Problem behoben zu haben (Sie können Ihren Fix testen, indem Sie die URL als Googlebot abrufen), können Sie uns dies mitteilen, indem Sie den Fehler als „behoben“ markieren, wenn Sie ein Benutzer mit vollen Zugriffsberechtigungen sind. Dadurch wird der Fehler aus Ihrer Liste entfernt. In Zukunft werden die Fehler, die Sie als behoben markiert haben, nicht mehr in die oberste Fehlerliste aufgenommen, es sei denn, wir haben denselben Fehler beim erneuten Crawlen einer URL festgestellt.
Wir haben viel Arbeit in die neue Crawling-Fehler-Funktion gesteckt, daher hoffen wir, dass sie Ihnen sehr nützlich sein wird. Lassen Sie uns wissen, was Sie denken und wenn Sie Vorschläge haben, besuchen Sie bitte unser Forum!
Geschrieben von Kurt Dresner, Webmaster Tools Team