




Crawl Errors: The Next Generation
måndag, Mars 12, 2012
Crawl errors är en av de mest populära funktionerna i verktyg för webbansvariga, och idag rullar vi ut några mycket betydande förbättringar som gör det ännu mer användbart.
vi upptäcker och rapporterar nu många nya typer av fel. För att hjälpa till att förstå de nya uppgifterna har vi delat upp felen i två delar: webbplatsfel och URL-fel.
Webbplatsfel
Webbplatsfel är fel som inte är specifika för en viss URL—de påverkar hela din webbplats. Dessa inkluderar DNS-upplösningsfel, anslutningsproblem med din webbserver och problem med att hämta dina robotar.txt-fil. Vi brukade rapportera dessa fel via URL, men det var inte mycket meningsfullt eftersom de inte är specifika för enskilda webbadresser—i själva verket hindrar de Googlebot från att ens begära en URL! Istället håller vi nu reda på felfrekvensen för varje typ av webbplatsövergripande fel. Vi kommer också att försöka skicka varningar när dessa fel blir tillräckligt ofta att de motiverar uppmärksamhet.
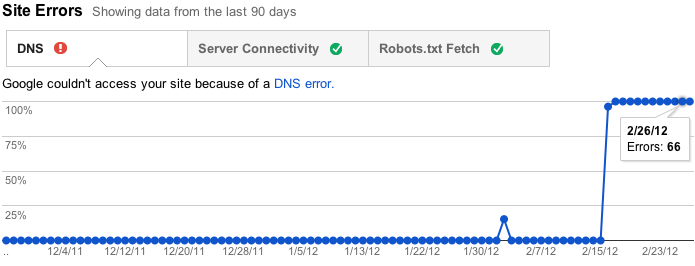
dessutom, om du inte har (och har inte nyligen haft) några problem i dessa områden, vilket är fallet för många platser, vi kommer inte bry dig med detta avsnitt. Istället visar vi bara några vänliga bockar för att låta dig veta att allt är hunky-dory.

URL-fel
URL-fel är fel som är specifika för en viss sida. Det betyder att när Googlebot försökte genomsöka webbadressen kunde den lösa din DNS, ansluta till din server, hämta och läsa dina robotar.txt-fil, och begär sedan den här webbadressen, men något gick fel efter det. Vi delar upp URL-felen i olika kategorier baserat på vad som orsakade felet. Om din webbplats serverar Google Nyheter eller mobildata (CHTML/XHTML) visar vi separata kategorier för dessa fel.

mindre är mer
vi brukade visa dig högst 100 000 fel av varje typ. Att försöka konsumera all denna information var som att dricka från en brandslang, och du hade inget sätt att veta vilka av dessa fel som var viktiga (din hemsida är nere) eller mindre viktig (någons personliga webbplats gjorde ett typsnitt i en länk till din webbplats). Det fanns inget realistiskt sätt att se alla 100 000 fel—inget sätt att sortera, söka eller markera dina framsteg. I den nya versionen av den här funktionen har vi fokuserat på att försöka ge dig bara de viktigaste felen på framsidan. För varje kategori ger vi dig vad vi tycker är de 1000 viktigaste och mest handlingsbara felen. Du kan sortera och filtrera dessa top 1000 fel, låt oss veta när du tror att du har åtgärdat dem, och visa information om dem.
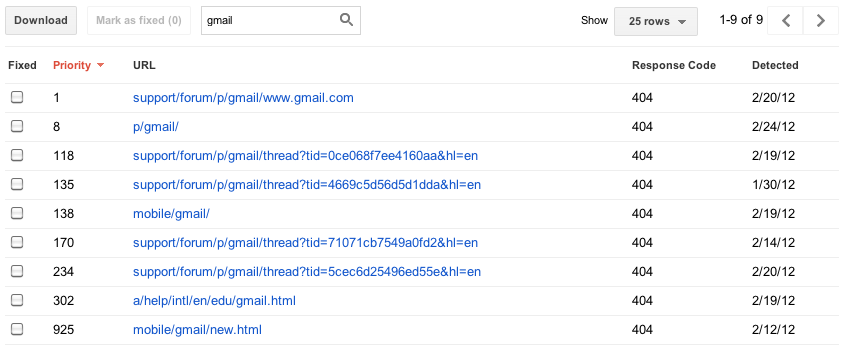
vissa webbplatser har mer än 1000 fel av en viss typ, så du kan fortfarande se det totala antalet fel du har av varje typ, samt ett diagram som visar historiska data som går tillbaka 90 dagar. För dem som oroar sig för att 1000 fel detaljer plus en total sammanlagd räkning inte kommer att räcka, överväger vi att lägga till programmatisk åtkomst (ett API) så att du kan ladda ner varje sista fel du har, så ge oss feedback om du behöver mer.
vi har också tagit bort listan över sidor som blockeras av robotar.txt, för medan dessa ibland kan vara användbara för att diagnostisera ett problem med dina robotar.txt-fil, de är ofta sidor du avsiktligt blockerat. Vi ville verkligen fokusera på fel, så leta efter information om robotade webbadresser för att dyka upp snart i funktionen ”Crawler access” under ”Site configuration”.
Dyk in i detaljerna
genom att klicka på en enskild fel-URL från huvudlistan visas en detaljruta med ytterligare information, inklusive när vi senast försökte genomsöka webbadressen, när vi först märkte ett problem och en kort förklaring av felet.

från informationsfönstret kan du klicka på länken för webbadressen som orsakade felet för att se själv vad som händer när du försöker besöka den. Du kan också markera felet som ”fixat” (mer om det senare!), visa hjälpinnehåll för feltypen, lista webbplatskartor som innehåller webbadressen, se andra sidor som länkar till den här webbadressen och till och med har Googlebot hämtat webbadressen just nu, antingen för mer information eller för att dubbelkontrollera att din korrigering fungerade.

vidta åtgärder!
en sak som vi verkligen är glada över i den här nya versionen av Crawl errors-funktionen är att du verkligen kan fokusera på att fixa det som är viktigast först. Vi har rankat felen så att de högst upp i prioriteringslistan kommer att vara sådana där det finns något du kan göra, oavsett om det är att fixa trasiga länkar på din egen webbplats, fixa fel i din serverprogramvara, uppdatera dina webbplatskartor för att beskära döda webbadresser eller lägga till en 301-omdirigering för att få användare till den ”riktiga” sidan. Vi bestämmer detta baserat på en mängd faktorer, inklusive om du inkluderade webbadressen i en webbplatskarta, hur många platser den är länkad från (och om någon av dem också finns på din webbplats) och om webbadressen har fått någon trafik nyligen från sökning.
när du tror att du har åtgärdat problemet (du kan testa din fix genom att hämta webbadressen som Googlebot) kan du meddela oss genom att markera felet som ”fixat” om du är en användare med fullständiga åtkomstbehörigheter. Detta tar bort felet från din lista. I framtiden kommer de fel som du har markerat som fasta inte att inkluderas i listan över toppfel, såvida vi inte har stött på samma fel när vi försöker genomsöka en URL igen.
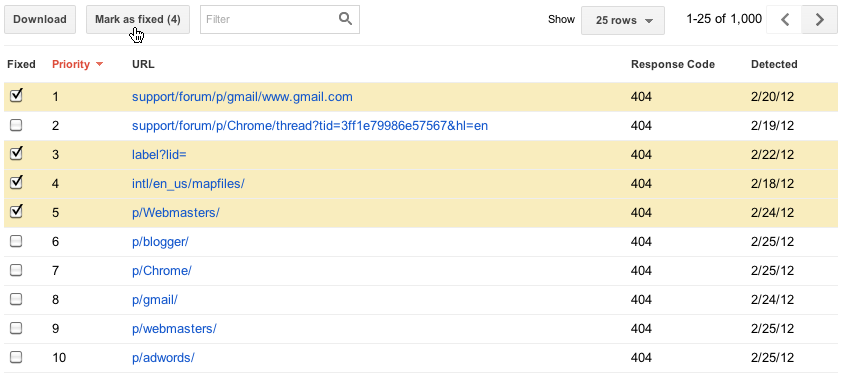
vi har lagt mycket arbete på den nya Crawl errors-funktionen, så vi hoppas att det kommer att vara mycket användbart för dig. Låt oss veta vad du tycker och om du har några förslag, besök vårt forum!
skrivet av Kurt Dresner, team för verktyg för webbansvariga