




Cisco data Center Infrastructure 2.5 Design Guide
Serverklusterdesigner med Ethernet
en översikt på hög nivå över servrarna och nätverkskomponenterna som används i serverklustermodellen finns i kapitel 1 ”Data Center Architecture Overview.”I det här kapitlet beskrivs syftet och funktionen för varje lager i serverklustermodellen mer detaljerat. Följande avsnitt ingår:
•![]() tekniska mål
tekniska mål
•![]() distribuerad vidarebefordran och latens
distribuerad vidarebefordran och latens
•![]() lika kostnad Multi-Path Routing
lika kostnad Multi-Path Routing
•![]() Serverklusterdesign-Tvåstegsmodell
Serverklusterdesign-Tvåstegsmodell
•![]() Serverklusterdesign-trestegsmodell
Serverklusterdesign-trestegsmodell
•![]() Rekommenderad hårdvara och moduler
Rekommenderad hårdvara och moduler

Obs ![]() designmodellerna som omfattas av detta kapitel har inte verifierats fullständigt i Cisco lab-testning på grund av storleken och omfattningen av testning som skulle krävas. De tvåstegsmodeller som omfattas är liknande mönster som har implementerats i kundproduktionsnätverk.
designmodellerna som omfattas av detta kapitel har inte verifierats fullständigt i Cisco lab-testning på grund av storleken och omfattningen av testning som skulle krävas. De tvåstegsmodeller som omfattas är liknande mönster som har implementerats i kundproduktionsnätverk.
tekniska mål
vid utformning av ett stort företagsklusternätverk är det viktigt att överväga specifika mål. Inga två kluster är exakt lika; var och en har sina egna specifika krav och måste undersökas ur ett applikationsperspektiv för att bestämma de specifika designkraven. Ta hänsyn till följande tekniska överväganden:
•![]() latens-i nätverkstransporten kan latens påverka den totala klusterprestandan negativt. Att använda kopplingsplattformar som använder en låg latens-omkopplingsarkitektur hjälper till att säkerställa optimal prestanda. Den huvudsakliga källan till latens är protokollstacken och Nic-hårdvaruimplementering som används på servern. Drivrutinsoptimering och CPU-avlastningstekniker, som TCP Offload Engine (TOE) och Remote Direct Memory Access (RDMA), kan hjälpa till att minska latensen och minska bearbetningskostnaderna på servern.
latens-i nätverkstransporten kan latens påverka den totala klusterprestandan negativt. Att använda kopplingsplattformar som använder en låg latens-omkopplingsarkitektur hjälper till att säkerställa optimal prestanda. Den huvudsakliga källan till latens är protokollstacken och Nic-hårdvaruimplementering som används på servern. Drivrutinsoptimering och CPU-avlastningstekniker, som TCP Offload Engine (TOE) och Remote Direct Memory Access (RDMA), kan hjälpa till att minska latensen och minska bearbetningskostnaderna på servern.
Latency kanske inte alltid är en kritisk faktor i klusterdesignen. Till exempel kan vissa kluster kräva hög bandbredd mellan servrar på grund av en stor mängd massfilöverföring, men kanske inte är beroende av server-till-server Inter-Process Communication (IPC) – meddelanden, vilket kan påverkas av hög latens.
•![]() Mesh / partial mesh connectivity-Serverklusterdesigner kräver vanligtvis ett nät eller partiellt nätväv för att tillåta kommunikation mellan alla noder i klustret. Detta masktyg används för att dela tillstånd, data och annan information mellan master-to-compute och compute-to-compute-servrar i klustret. Mesh eller partiell mesh-anslutning är också applikationsberoende.
Mesh / partial mesh connectivity-Serverklusterdesigner kräver vanligtvis ett nät eller partiellt nätväv för att tillåta kommunikation mellan alla noder i klustret. Detta masktyg används för att dela tillstånd, data och annan information mellan master-to-compute och compute-to-compute-servrar i klustret. Mesh eller partiell mesh-anslutning är också applikationsberoende.
•![]() hög genomströmning-möjligheten att skicka en stor fil under en viss tid kan vara avgörande för klusteroperation och prestanda. Serverkluster kräver vanligtvis en minimal mängd tillgänglig icke-blockerande bandbredd, vilket översätts till en låg överteckningsmodell mellan åtkomst-och kärnlagren.
hög genomströmning-möjligheten att skicka en stor fil under en viss tid kan vara avgörande för klusteroperation och prestanda. Serverkluster kräver vanligtvis en minimal mängd tillgänglig icke-blockerande bandbredd, vilket översätts till en låg överteckningsmodell mellan åtkomst-och kärnlagren.
•![]() överteckningsförhållande-överteckningsförhållandet måste undersökas vid flera aggregeringspunkter i konstruktionen, inklusive linjekortet för att byta tygbandbredd och omkopplaren tygingång till upplänksbandbredd.
överteckningsförhållande-överteckningsförhållandet måste undersökas vid flera aggregeringspunkter i konstruktionen, inklusive linjekortet för att byta tygbandbredd och omkopplaren tygingång till upplänksbandbredd.
•![]() Jumbo frame support – även om jumbo frames kanske inte används vid den första implementeringen av ett serverkluster, är det en mycket viktig funktion som är nödvändig för ytterligare flexibilitet eller för eventuella framtida krav. TCP / IP-paketkonstruktionen placerar ytterligare kostnader på serverns CPU. Användningen av jumbo ramar kan minska antalet paket, vilket minskar denna overhead.
Jumbo frame support – även om jumbo frames kanske inte används vid den första implementeringen av ett serverkluster, är det en mycket viktig funktion som är nödvändig för ytterligare flexibilitet eller för eventuella framtida krav. TCP / IP-paketkonstruktionen placerar ytterligare kostnader på serverns CPU. Användningen av jumbo ramar kan minska antalet paket, vilket minskar denna overhead.
•![]() porttäthet – serverkluster kan behöva skala till tiotusentals portar. Som sådan, de kräver plattformar med en hög nivå av paketomkopplingsprestanda, en stor mängd switch Tyg bandbredd, och en hög nivå av porttäthet.
porttäthet – serverkluster kan behöva skala till tiotusentals portar. Som sådan, de kräver plattformar med en hög nivå av paketomkopplingsprestanda, en stor mängd switch Tyg bandbredd, och en hög nivå av porttäthet.
distribuerad vidarebefordran och latens
Cisco Catalyst 6500 Series switch har den unika förmågan att stödja en central paket vidarebefordran eller valfri distribuerad vidarebefordran arkitektur, medan Cisco Catalyst 4948-10GE är en enda central ASIC design med fast linje hastighet vidarebefordran prestanda. Cisco 6700 linjekortmoduler stöder en valfri dotterkortmodul som kallas ett distribuerat Vidarebefordringskort (DFC). DFC tillåter lokala routingbeslut att inträffa på varje linjekort genom att implementera en lokal Vidarebefordringsinformationsbas (FIB). Fib-tabellen på Sup720 PFC upprätthåller synkronisering med varje DFC FIB-tabell på linjekorten för att säkerställa routningsintegritet över systemet.
när det valfria DFC-kortet inte finns, skickas en kompakt header-sökning till PFC3 på Sup720 för att bestämma var på switch-tyget för att vidarebefordra varje paket. När en DFC är närvarande kan linjekortet byta ett paket direkt över omkopplaren till destinationslinjekortet utan att konsultera Sup720. Skillnaden i prestanda kan vara från 30 Mpps systemomfattande utan DFC till 48 Mpps per kortplats med DFC. Den fasta konfigurationskatalysatorn 4948 – 10GE-omkopplaren har en trådhastighet, icke-blockerande arkitektur som stöder upp till 101.18 Mpps-prestanda, vilket ger överlägsen åtkomstskiktsprestanda för toppen av rackdesign.
Latensprestanda kan variera avsevärt när man jämför distribuerade och centrala vidarebefordringsmodeller. Tabell 3-1 ger ett exempel på latenser mätt över en 6704 linjekort med och utan DFC.
| 6704 med DFC (Port-to-Port i mikrosekunder genom Switch Tyg) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Paketstorlek (B) |
||||||||||
|
Latency (ms) |
||||||||||
| 6704 utan DFC (Port-to-Port i mikrosekunder genom Switch Tyg) | ||||||||||
|
Paketstorlek (B) |
||||||||||
|
Latency (ms) |
||||||||||
skillnaden i latens mellan en DFC-aktiverad och icke-DFC-aktiverat linjekort kanske inte verkar betydande. Men i en 6500 central forwarding-arkitektur kan latensen öka när trafikhastigheterna ökar på grund av striden om den delade sökningen på centralbussen. Med en DFC är sökvägen tillägnad varje radkort och latensen är konstant.
Catalyst 6500 Systembandbredd
den tillgängliga systembandbredden ändras inte när DFC används. DFC: erna förbättrar behandlingen av paket per sekund (pps) av det övergripande systemet. Tabell 3-2 sammanfattar genomströmning och bandbredd prestanda för moduler som stöder DFC, utöver de äldre CEF256 och klassiska bussmoduler.
| systemkonfiguration med Sup720 | genomströmning i MPP | bandbredd i Gbps |
|
klassiska serien moduler |
upp till 15 Mpps (per system) |
16 g delad buss (klassisk buss) |
|
CEF256 serie moduler |
upp till 30 Mpps (per system) |
1x 8 G (dedikerad per slits) |
|
blandning av classic med CEF256 eller CEF720-serien moduler |
upp till 15 Mpps (per system) |
Kortberoende |
|
CEF720-serien moduler (6748, 6704, 6724) |
upp till 30 Mpps (per system) |
2x 20 G (dedikerad per slits) |
|
CEF720 serie moduler med DFC3 (6704 med DFC3, 6708 med DFC3, 6748 med DFC3 6724 + DFC3) |
Sustain upp till 48 Mpps (per kortplats) |
2x 20 G (dedikerad per slits) |
även om 6513 kan vara en giltig lösning för åtkomstskiktet i den stora klustermodellen, notera att det finns en blandning av enkel-och dubbelkanalslitsar i detta chassi. Spelautomater 1 till 8 är enda kanal och spelautomater 9 till 13 är dubbla kanaler, såsom visas i Figur 3-1.
figur 3-1 Catalyst 6500 Tyg kanaler genom chassi och slits (6513 fokus
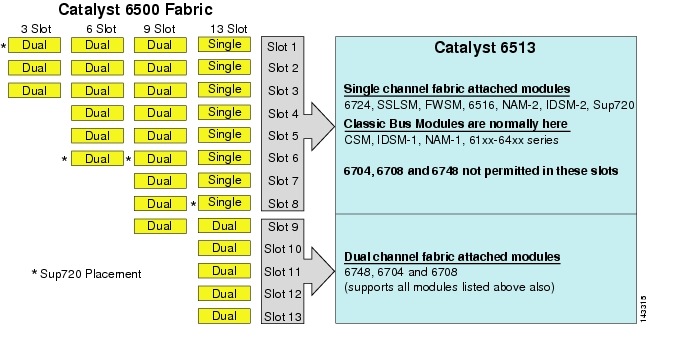
när en Cisco Catalyst 6513 används, de dubbla kanalkort, såsom 6704-4 port 10gige, den 6708 – 8 port 10gige, och den 6748-48 port SFP/koppar linjekort kan placeras endast i slitsar 9 till 13. De enda kanal linjekort som 6724-24 port SFP / koppar linjekort kan användas i slitsar 1 till 8. Sup720 använder slitsar 7 och 8, som är enkanal 20g tyg fäst. Till skillnad från 6513 har 6509 färre tillgängliga slitsar men kan stödja dubbelkanalmoduler i alla slitsar eftersom varje slits har dubbla kanaler till switch-tyget.
Obs ![]() eftersom serverklustermiljön vanligtvis kräver hög bandbredd med låg latensegenskaper rekommenderar vi att du använder DFC i dessa typer av mönster.
eftersom serverklustermiljön vanligtvis kräver hög bandbredd med låg latensegenskaper rekommenderar vi att du använder DFC i dessa typer av mönster.
Equal Cost Multi-Path Routing
Equal cost multi-path (ECMP) routing är en lastbalanseringsteknik som optimerar flöden över flera IP-vägar mellan två subnät i en Cisco Express Forwarding-aktiverad miljö. ECMP tillämpar lastbalansering för TCP – och UDP-paket per flöde. Icke-TCP/UDP-paket, såsom ICMP, distribueras på paket-för-paket-basis. ECMP är baserat på RFC 2991 och utnyttjas på andra Cisco-plattformar, till exempel Pix-och Cisco Content Services Switch (CSS) – produkterna. ECMP stöds på både 6500-och 4948-10GE-plattformarna som rekommenderas i serverklusterdesignen.
de dramatiska förändringar till följd av lager 3 byta hårdvara ASIC och Cisco Express Forwarding hashing algoritmer hjälper till att skilja ECMP från sin föregångare teknik. Den största fördelen i en ECMP-design för serverklusterimplementeringar är hashingalgoritmen kombinerad med liten eller ingen CPU-overhead i Layer 3-växling. Cisco Express Forwarding hashing-algoritmen kan distribuera granulära flöden över flera linjekort med linjehastighet i hårdvara. Standardinställningen för hashingalgoritmen är att hashflöden baseras på IP-adresser för lager 3-källa och destination, och eventuellt lägga till lager 4-portnummer för ytterligare ett differentieringslager. Det maximala antalet tillåtna ECMP-banor är åtta.
figur 3-2 illustrerar en 8-vägs ECMP – serverklusterdesign. För att förenkla illustrationen visas endast två åtkomstlageromkopplare, men upp till 32 kan stödjas (64 10giges per kärnnod).
figur 3-2 8-vägs ECMP – Serverklusterdesign
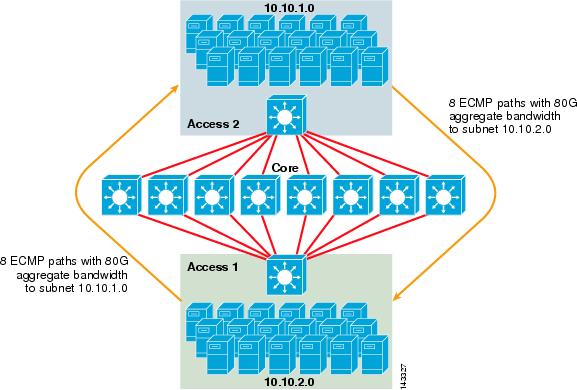
i Figur 3-2 kan varje åtkomstlagerbrytare stödja ett eller flera undernät av anslutna servrar. Varje omkopplare har en enda 10gige anslutning till var och en av de åtta kärnbrytare med användning av två 6704 linjekort. Denna konfiguration ger åtta vägar 10GigE för totalt 80 G Cisco Express Forwarding-aktiverad bandbredd till någon annan delnät i serverkluster tyget. En show ip-ruttfråga till ett annat delnät på en annan switch visar åtta poster med samma kostnad.
kärnan är befolkade med 10gige linjekort med DFC för att möjliggöra en fullt distribuerad höghastighets omkopplings tyg med mycket låg port-till-port latens. En show ip-ruttfråga till en åtkomstlagerbrytare visar en enda ruttpost på var och en av de åtta kärnbrytarna.
Obs ![]() även om det inte har testats för den här guiden, det finns en ny 8-port 10 Gigabit Ethernet-modul (WS-X6708-10g-3C) som nyligen har införts för Catalyst 6500 Series switch. Detta linjekort kommer att testas för att inkluderas i den här guiden vid ett senare tillfälle. För frågor om 8-port 10gige-kortet, se produktdatabladet.
även om det inte har testats för den här guiden, det finns en ny 8-port 10 Gigabit Ethernet-modul (WS-X6708-10g-3C) som nyligen har införts för Catalyst 6500 Series switch. Detta linjekort kommer att testas för att inkluderas i den här guiden vid ett senare tillfälle. För frågor om 8-port 10gige-kortet, se produktdatabladet.
redundans i Serverklusterdesignen
serverklusterdesignen implementeras vanligtvis inte med redundanta CPU-eller switch fabric-processorer. Elasticitet uppnås vanligtvis i sig i designen och med metoden fungerar klustret som helhet. Som beskrivs i kapitel 1 ”Översikt över Datacenterarkitektur” hanteras beräkningsnoderna i klustret av huvudnoder som ansvarar för att tilldela specifika jobb till varje beräkningsnod och övervaka deras prestanda. Om en beräkningsnod faller ut ur klustret, omfördelas den till en tillgänglig nod och fortsätter att fungera, men med mindre processorkraft, tills noden är tillgänglig. Även om det är viktigt att diversifiera huvudnodanslutningar i klustret över olika åtkomstomkopplare, är det inte kritiskt för beräkningsnoderna.
även om redundanta processorer verkligen är valfria är det viktigt att överväga porttäthet, särskilt med avseende på 10GE-portar, där en extra kortplats finns i stället för en redundant Sup720-modul.
notera ![]() exemplen i detta kapitel använder icke-redundanta CPU-konstruktioner, som tillåter maximalt 64 10GE-portar per 6509 kärnnod tillgänglig för åtkomstnod upplänk anslutningar baserade på användning av en 6708 8-port 10gige linjekort.
exemplen i detta kapitel använder icke-redundanta CPU-konstruktioner, som tillåter maximalt 64 10GE-portar per 6509 kärnnod tillgänglig för åtkomstnod upplänk anslutningar baserade på användning av en 6708 8-port 10gige linjekort.
Serverklusterdesign-Tvåstegsmodell
det här avsnittet beskriver de olika metoderna för en serverklusterdesign som utnyttjar ECMP och distribuerad CEF. Varje design visar hur olika konfigurationer kan uppnå olika överteckningsnivåer och kan skala på ett flexibelt sätt, börjar med några noder och växer till många som stöder tusentals servrar.
serverklusterdesignen följer vanligtvis en tvåstegsmodell bestående av kärn-och åtkomstlager. Eftersom designmålen kräver användning av lager 3 ECMP och distribuerad vidarebefordran för att uppnå en mycket deterministisk bandbredd och latens per server, är en trestegsmodell som introducerar en annan punkt för överteckning vanligtvis inte önskvärd. Fördelarna med en trestegsmodell beskrivs i Serverklusterdesign—trestegsmodell.
de tre huvudberäkningarna att tänka på när man utformar en serverklusterlösning är maximala serveranslutningar, bandbredd per server och överteckningsförhållande. Klusterdesigners kan bestämma dessa värden baserat på applikationsprestanda, serverhårdvara och andra faktorer, inklusive följande:
•![]() maximalt antal server GigE-anslutningar i skala-Klusterdesigners har vanligtvis en uppfattning om den maximala skalan som krävs vid det ursprungliga konceptet. En fördel med hur ECMP designs fungerar är att de kan börja med ett minimalt antal switchar och servrar som uppfyller ett visst krav på bandbredd, latens och överteckning och flexibelt växa på ett lågt/icke-störande sätt till maximal skala samtidigt som samma bandbredd, latens och överteckningsvärden bibehålls.
maximalt antal server GigE-anslutningar i skala-Klusterdesigners har vanligtvis en uppfattning om den maximala skalan som krävs vid det ursprungliga konceptet. En fördel med hur ECMP designs fungerar är att de kan börja med ett minimalt antal switchar och servrar som uppfyller ett visst krav på bandbredd, latens och överteckning och flexibelt växa på ett lågt/icke-störande sätt till maximal skala samtidigt som samma bandbredd, latens och överteckningsvärden bibehålls.
•![]() ungefärlig bandbredd per server—detta värde kan bestämmas genom att helt enkelt dividera den totala aggregerade upplänksbandbredden med de totala server GigE-anslutningarna på åtkomstlageromkopplaren. Till exempel kan ett åtkomstlager Cisco 6509 med fyra 10GIGE ECMP upplänkar med 336 server accessportar beräknas på följande sätt:
ungefärlig bandbredd per server—detta värde kan bestämmas genom att helt enkelt dividera den totala aggregerade upplänksbandbredden med de totala server GigE-anslutningarna på åtkomstlageromkopplaren. Till exempel kan ett åtkomstlager Cisco 6509 med fyra 10GIGE ECMP upplänkar med 336 server accessportar beräknas på följande sätt:
4x10gige upplänkar med 336 servrar = 120 Mbps per server
justera endera sidan av ekvationen minskar eller Ökar mängden bandbredd per server.
Obs ![]() Detta är bara ett ungefärligt värde och fungerar endast som riktlinje. Olika faktorer påverkar den faktiska mängden bandbredd som varje server har tillgänglig. ECMP-belastningsfördelningshashalgoritmen delar upp belastningen baserat på Layer 3 plus Layer 4-värden och varierar baserat på trafikmönster. Konfigurationsparametrar som hastighetsbegränsning, kö och QoS-värden kan också påverka den faktiska uppnådda bandbredden per server.
Detta är bara ett ungefärligt värde och fungerar endast som riktlinje. Olika faktorer påverkar den faktiska mängden bandbredd som varje server har tillgänglig. ECMP-belastningsfördelningshashalgoritmen delar upp belastningen baserat på Layer 3 plus Layer 4-värden och varierar baserat på trafikmönster. Konfigurationsparametrar som hastighetsbegränsning, kö och QoS-värden kan också påverka den faktiska uppnådda bandbredden per server.
•![]() Överteckningsförhållande per server – detta värde kan bestämmas genom att helt enkelt dividera det totala antalet server GigE-anslutningar med den totala aggregerade upplänksbandbredden på åtkomstlageromkopplaren. Till exempel kan ett åtkomstlager 6509 med fyra 10GIGE ECMP-upplänkar med 336 serveråtkomstportar beräknas enligt följande:
Överteckningsförhållande per server – detta värde kan bestämmas genom att helt enkelt dividera det totala antalet server GigE-anslutningar med den totala aggregerade upplänksbandbredden på åtkomstlageromkopplaren. Till exempel kan ett åtkomstlager 6509 med fyra 10GIGE ECMP-upplänkar med 336 serveråtkomstportar beräknas enligt följande:
336 GigE-serveranslutningar med 40g upplänk bandbredd = 8.4:1 överteckningsförhållande
följande avsnitt visar hur dessa värden varierar, baserat på olika hårdvaru-och sammankopplingskonfigurationer, och fungerar som riktlinje vid utformning av stora klusterkonfigurationer.
Obs ![]() för beräkningsändamål antas det att det inte finns något linjekort för att byta tygöverteckning på Catalyst 6500-serien. Den dubbla kanalplatsen ger 40g maximal bandbredd till switch-tyget. En 4-port 10gige kort med alla portar på linjehastighet med maximal storlek paket anses vara den bästa möjliga skick med liten eller ingen överteckning. Den faktiska mängden switch Tyg bandbredd tillgängliga varierar, baserat på genomsnittliga paketstorlekar. Dessa beräkningar skulle behöva beräknas om du skulle använda ws-X6708 8-port 10gige kort som övertecknas på 2: 1.
för beräkningsändamål antas det att det inte finns något linjekort för att byta tygöverteckning på Catalyst 6500-serien. Den dubbla kanalplatsen ger 40g maximal bandbredd till switch-tyget. En 4-port 10gige kort med alla portar på linjehastighet med maximal storlek paket anses vara den bästa möjliga skick med liten eller ingen överteckning. Den faktiska mängden switch Tyg bandbredd tillgängliga varierar, baserat på genomsnittliga paketstorlekar. Dessa beräkningar skulle behöva beräknas om du skulle använda ws-X6708 8-port 10gige kort som övertecknas på 2: 1.
4-och 8-vägs ECMP-konstruktioner med modulär åtkomst
följande fyra designexempel visar olika metoder för att bygga och skala två-tier-serverklustermodellen med 4-vägs och 8-vägs ECMP. De viktigaste frågorna att tänka på är antalet kärnnoder och det maximala antalet upplänkar, eftersom dessa direkt påverkar maximal skala, bandbredd per server och överteckningsvärden.
Obs ![]() även om det inte har testats för den här guiden, det finns en ny 8-port 10 Gigabit Ethernet-modul (WS-X6708-10g-3C) som nyligen har införts för Catalyst 6500 Series switch. Detta linjekort kommer att testas för att inkluderas i guiden vid ett senare tillfälle. För frågor om 8-port 10gige-kortet, se produktdatabladet.
även om det inte har testats för den här guiden, det finns en ny 8-port 10 Gigabit Ethernet-modul (WS-X6708-10g-3C) som nyligen har införts för Catalyst 6500 Series switch. Detta linjekort kommer att testas för att inkluderas i guiden vid ett senare tillfälle. För frågor om 8-port 10gige-kortet, se produktdatabladet.
Obs ![]() länkarna som krävs för att ansluta serverklustret till ett externt campus-eller tunnelbanenät visas inte i dessa designexempel men bör övervägas.
länkarna som krävs för att ansluta serverklustret till ett externt campus-eller tunnelbanenät visas inte i dessa designexempel men bör övervägas.
figur 3-3 ger ett exempel där två kärnnoder används för att tillhandahålla en 4-vägs ECMP-lösning.
figur 3-3 4-vägs ECMP med två Kärnnoder
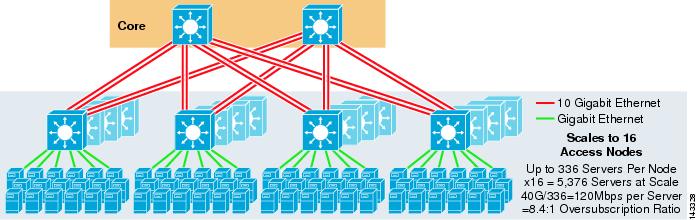
en fördel med detta tillvägagångssätt är att ett mindre antal kärnbrytare kan stödja ett stort antal servrar. Den möjliga nackdelen är en hög överteckning-låg bandbredd per servervärde och stor exponering för ett kärnnodfel. Observera att upplänkarna är individuella L3-upplänkar och inte EtherChannels.
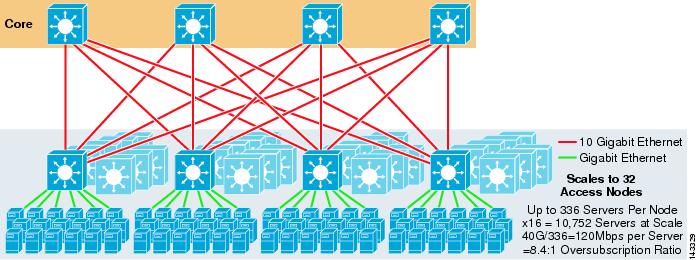
figur 3-4 visar hur att lägga till två kärnnoder till den tidigare designen dramatiskt kan öka den maximala skalan samtidigt som samma överprenumeration och bandbredd per servervärden bibehålls.
figur 3-4 4-vägs ECMP med fyra Kärnnoder
figur 3-5 visar en 8-vägs ECMP-design med två kärnnoder.
figur 3-5 8-vägs ECMP med två Kärnnoder
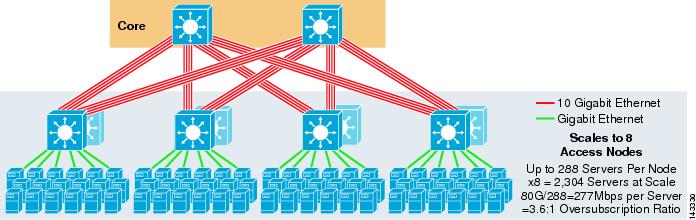
som förväntat ökar den extra upplänksbandbredden dramatiskt bandbredden per server och minskar överteckningsförhållandet per server. Observera hur de extra slitsarna som tas i varje åtkomstlageromkopplare för att stödja 8-vägs upplänkar minskar den maximala skalan eftersom antalet servrar per omkopplare reduceras till 288. Observera att upplänkarna är individuella L3-upplänkar och inte EtherChannels.
figur 3-6 visar en 8-vägs ECMP-design med åtta kärnnoder.
figur 3-6 8-vägs ECMP med åtta Kärnnoder
detta visar hur tillägg av fyra kärnnoder till samma tidigare design dramatiskt kan öka den maximala skalan samtidigt som samma överteckning och bandbredd per servervärden bibehålls.
2-vägs ECMP-Design med 1RU-åtkomst
i många klustermiljöer önskas eller krävs rackbaserad serveromkoppling med små omkopplare högst upp på varje serverrack på grund av kablage, administrativa problem, fastighetsproblem eller för att uppfylla särskilda implementeringsmodellmål.
figur 3-7 visar ett exempel där två kärnnoder används för att tillhandahålla en 2-vägs ECMP-lösning med 1RU 4948-10GE-åtkomstbrytare.
figur 3-7 2-vägs ECMP med två Kärnnoder och 1RU-åtkomst
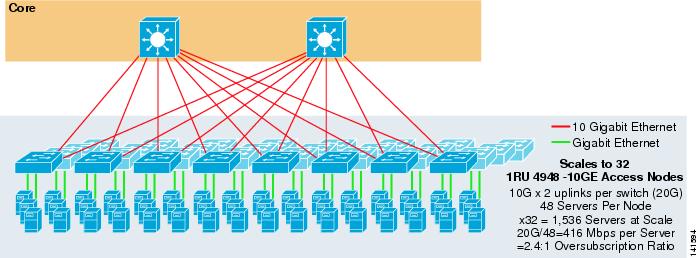
den maximala skalan är begränsad till 1536-servrar men ger över 400 Mbps bandbredd med ett lågt överteckningsförhållande. Eftersom 4948 har endast två 10gige upplänkar, denna design kan inte skala utöver dessa värden.
Obs ![]() mer information om rackbaserad serverväxling finns i kapitel 3 ” Serverklusterdesign med Ethernet.”
mer information om rackbaserad serverväxling finns i kapitel 3 ” Serverklusterdesign med Ethernet.”
Serverklusterdesign-trestegsmodell
även om en tvåstegsmodell är vanligast i stora klusterdesigner, kan en trestegsmodell också användas. Trestegsmodellen används vanligtvis för att stödja stora serverklusterimplementeringar med 1RU eller modulära åtkomstlageromkopplare.
figur 3-8 visar ett storskaligt exempel som utnyttjar 8-vägs ECMP med 6500 kärn-och aggregeringsbrytare och 1RU 4948-10GE åtkomstskiktbrytare.
figur 3-8 trestegsmodell med 8-vägs ECMP
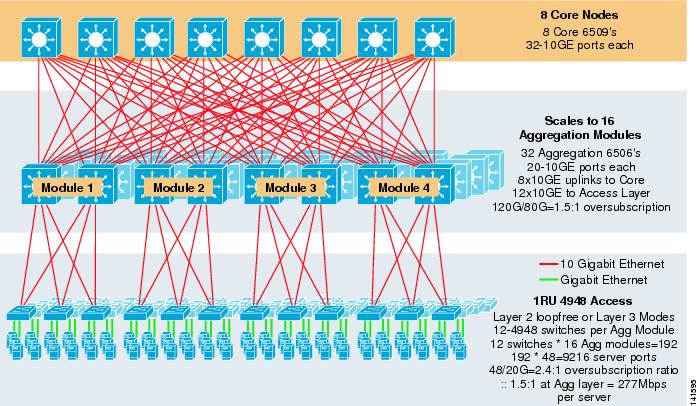
den maximala skalan är över 9200 servrar med 277 Mbps bandbredd med lågt överteckningsförhållande. Fördelarna med trestegsmetoden med 1RU-åtkomstbrytare inkluderar följande:
•![]() 1RU deployment models-som tidigare nämnts kräver många stora klustermodelldistributioner en 1RU-metod för förenklad installation. Till exempel rullar en ASP ut rack av servrar i taget när de skalar stora klusterapplikationer. Serverracket är förmonterat och iscensatt offsite så att det snabbt kan installeras och läggas till det löpande klustret. Detta innebär vanligtvis en tredje part som bygger rack, förkonfigurerar servrarna och förkablar dem med ström och Ethernet till en 1RU-switch. Racket rullar in i datacentret och ansluts helt enkelt och läggs till i klustret efter anslutning av upplänkarna.
1RU deployment models-som tidigare nämnts kräver många stora klustermodelldistributioner en 1RU-metod för förenklad installation. Till exempel rullar en ASP ut rack av servrar i taget när de skalar stora klusterapplikationer. Serverracket är förmonterat och iscensatt offsite så att det snabbt kan installeras och läggas till det löpande klustret. Detta innebär vanligtvis en tredje part som bygger rack, förkonfigurerar servrarna och förkablar dem med ström och Ethernet till en 1RU-switch. Racket rullar in i datacentret och ansluts helt enkelt och läggs till i klustret efter anslutning av upplänkarna.
utan ett aggregeringslager är den maximala storleken på 1RU-åtkomstmodellen begränsad till drygt 1500 servrar. Genom att lägga till ett aggregeringslager kan 1RU-åtkomstmodellen skala till en mycket större storlek medan den fortfarande utnyttjar ECMP-modellen.
•![]() centralisering av kärn—och aggregeringsomkopplare-med 1RU-omkopplare utplacerade i racken är det möjligt att centralisera de större kärn-och aggregeringsmodulära omkopplarna. Detta kan förenkla kraft-och kabelinfrastruktur och förbättra användningen av rackfastigheter.
centralisering av kärn—och aggregeringsomkopplare-med 1RU-omkopplare utplacerade i racken är det möjligt att centralisera de större kärn-och aggregeringsmodulära omkopplarna. Detta kan förenkla kraft-och kabelinfrastruktur och förbättra användningen av rackfastigheter.
•![]() tillåter Layer 2 loop-free topology—ett stort klusternätverk med Layer 3 ECMP-åtkomst kan använda mycket adressutrymme på upplänkarna och kan lägga till komplexitet i designen. Detta är särskilt viktigt om det offentliga adressutrymmet används. Den tre-tier modell strategi lämpar sig väl för ett lager 2 loop-fri tillgång topologi som minskar antalet subnät som krävs.
tillåter Layer 2 loop-free topology—ett stort klusternätverk med Layer 3 ECMP-åtkomst kan använda mycket adressutrymme på upplänkarna och kan lägga till komplexitet i designen. Detta är särskilt viktigt om det offentliga adressutrymmet används. Den tre-tier modell strategi lämpar sig väl för ett lager 2 loop-fri tillgång topologi som minskar antalet subnät som krävs.
när en Layer 2-slingfri modell används är det viktigt att använda ett redundant standardgateway-protokoll som HSRP eller GLBP för att eliminera en enda felpunkt om en aggregeringsnod misslyckas. I denna design är aggregeringsmodulerna inte sammankopplade, vilket möjliggör en slingfri lager 2-design som kan utnyttja GLBP för automatisk serverstandard gateway lastbalansering. GLBP distribuerar automatiskt serverns standardgatewaytilldelning mellan de två noderna i aggregeringsmodulen. Efter att ett paket anländer till aggregeringsskiktet balanseras det över kärnan med 8-vägs ECMP-tyget. Även GLBP inte ger ett skikt 3 / skikt 4 lastfördelning hash liknar CEF, det är ett alternativ som kan användas med ett skikt 2 tillgång topologi.
beräkning av överteckning
trestegsmodellen introducerar två punkter för överteckning vid åtkomst-och aggregeringsskikten, jämfört med tvåstegsmodellen som bara har en enda punkt för överteckning vid åtkomstskiktet. För att korrekt beräkna den ungefärliga bandbredden per server och överteckningsförhållandet, utför följande två steg, som använder figur 3-8 som ett exempel:
Steg 1 ![]() beräkna överteckningsförhållandet och bandbredden per server för både aggregerings-och åtkomstlagren oberoende.
beräkna överteckningsförhållandet och bandbredden per server för både aggregerings-och åtkomstlagren oberoende.
•![]() Access layer
Access layer
–![]() överteckning – 48ge anslutna servrar / 20G upplänkar till aggregering = 2.4:1
överteckning – 48ge anslutna servrar / 20G upplänkar till aggregering = 2.4:1
–![]() bandbredd per server – 20g upplänkar till aggregering / 48GigE anslutna servrar = 416Mbps
bandbredd per server – 20g upplänkar till aggregering / 48GigE anslutna servrar = 416Mbps
•![]() Aggregeringslager
Aggregeringslager
–![]() överteckning – 120g nedlänkar till access / 80G upplänkar till core = 1.5:1
överteckning – 120g nedlänkar till access / 80G upplänkar till core = 1.5:1
steg 2 ![]() beräkna det kombinerade överteckningsförhållandet och bandbredden per server.
beräkna det kombinerade överteckningsförhållandet och bandbredden per server.
det faktiska överteckningsförhållandet är summan av de två punkterna för överteckning vid åtkomst-och aggregeringsskikten.
1.5*2.4 = 3.6:1
för att bestämma den verkliga bandbredden per servervärde, använd den algebraiska formeln för proportioner:
a:b = c:d
bandbredden per server vid åtkomstskiktet har bestämts vara 416 Mbps per server. Eftersom överteckningsförhållandet för aggregeringsskiktet är 1,5: 1 kan du använda ovanstående formel enligt följande:
416:1 = x:1.5
x = ~264 Mbps per server
Rekommenderad hårdvara och moduler
de rekommenderade plattformarna för serverklustermodelldesignen består av Cisco Catalyst 6500-familjen med sup720-processormodulen och Catalyst 4948-10GE 1RU-omkopplaren. Den höga omkopplingshastighet, stor switch Tyg, låg latens, distribuerad vidarebefordran, och 10gige densitet gör Catalyst 6500 Series switch idealisk för alla lager av denna modell. 1RU-formfaktorn kombinerad med vidarebefordran av trådhastighet, 10GE-upplänkar och mycket låg konstant latens gör 4948-10GE till en utmärkt topp av racklösning för åtkomstskiktet.
följande rekommenderas:
•![]() Sup720-den Sup720 kan bestå av både PFC3A (standard) eller nyare pfc3b typ dotterkort.
Sup720-den Sup720 kan bestå av både PFC3A (standard) eller nyare pfc3b typ dotterkort.
•![]() linjekort – alla linjekort ska vara 6700-serien och ska alla vara aktiverade för distribuerad vidarebefordran med dfc3a-eller DFC3B-dotterkorten.
linjekort – alla linjekort ska vara 6700-serien och ska alla vara aktiverade för distribuerad vidarebefordran med dfc3a-eller DFC3B-dotterkorten.
Obs ![]() genom att använda alla TYGMONTERADE CEF720-seriemoduler är det globala växlingsläget kompakt, vilket gör att systemet kan fungera på högsta prestandanivå. Katalysatorn 6509 kan stödja 10 GigE moduler i alla lägen eftersom varje slits stöder dubbla kanaler till omkopplaren tyget (Cisco Catalyst 6513 stöder inte detta).
genom att använda alla TYGMONTERADE CEF720-seriemoduler är det globala växlingsläget kompakt, vilket gör att systemet kan fungera på högsta prestandanivå. Katalysatorn 6509 kan stödja 10 GigE moduler i alla lägen eftersom varje slits stöder dubbla kanaler till omkopplaren tyget (Cisco Catalyst 6513 stöder inte detta).
•![]() Cisco Catalyst 4948-10GE-den 4948-10GE ger en högpresterande åtkomstlager lösning som kan utnyttja ECMP och 10gige upplänkar. Inga speciella krav är nödvändiga. 4948 – 10GE kan använda en Layer 2 Cisco IOS-bild eller ett Layer 2/3 Cisco IOS-bild, vilket möjliggör en optimal passform i båda miljöerna.
Cisco Catalyst 4948-10GE-den 4948-10GE ger en högpresterande åtkomstlager lösning som kan utnyttja ECMP och 10gige upplänkar. Inga speciella krav är nödvändiga. 4948 – 10GE kan använda en Layer 2 Cisco IOS-bild eller ett Layer 2/3 Cisco IOS-bild, vilket möjliggör en optimal passform i båda miljöerna.