




Cisco Data Center Infrastructure 2.5 Design Guide
server Cluster Designs with Ethernet
o prezentare generală la nivel înalt a serverelor și componentelor de rețea utilizate în modelul de cluster server este furnizată în Capitolul 1 „Prezentare generală a arhitecturii centrelor de date.”Acest capitol descrie scopul și funcția fiecărui strat al modelului de cluster server în detaliu. Sunt incluse următoarele secțiuni:
•![]() obiective tehnice
obiective tehnice
•![]() redirecționare distribuită și latență
redirecționare distribuită și latență
•![]() cost egal multi-cale de rutare
cost egal multi-cale de rutare
•![]() server Cluster Design – model pe două niveluri
server Cluster Design – model pe două niveluri
•![]() server Cluster Design – model pe trei niveluri
server Cluster Design – model pe trei niveluri
•![]() Hardware și module recomandate
Hardware și module recomandate

notă ![]() modelele de proiectare acoperite în acest capitol nu au fost complet verificate în testele Cisco lab din cauza dimensiunii și domeniului de testare care ar fi necesare. Modelele pe două niveluri care sunt acoperite sunt modele similare care au fost implementate în rețelele de producție ale clienților.
modelele de proiectare acoperite în acest capitol nu au fost complet verificate în testele Cisco lab din cauza dimensiunii și domeniului de testare care ar fi necesare. Modelele pe două niveluri care sunt acoperite sunt modele similare care au fost implementate în rețelele de producție ale clienților.
obiective tehnice
atunci când se proiectează o rețea de clustere pentru întreprinderi mari, este esențial să se ia în considerare obiective specifice. Nu există două clustere identice; fiecare are propriile cerințe specifice și trebuie examinat din perspectiva aplicației pentru a determina cerințele specifice de proiectare. Luați în considerare următoarele considerente tehnice:
•![]() latență-în transportul de rețea, latența poate afecta negativ performanța generală a clusterului. Utilizarea platformelor de comutare care utilizează o arhitectură de comutare cu latență redusă ajută la asigurarea unei performanțe optime. Principala sursă de latență este stiva de protocol și implementarea hardware Nic utilizată pe server. Optimizarea driverului și tehnicile de descărcare a procesorului, cum ar fi TCP Outload Engine (TOE) și Remote Direct Memory Access (RDMA), pot ajuta la scăderea latenței și la reducerea cheltuielilor de procesare pe server.
latență-în transportul de rețea, latența poate afecta negativ performanța generală a clusterului. Utilizarea platformelor de comutare care utilizează o arhitectură de comutare cu latență redusă ajută la asigurarea unei performanțe optime. Principala sursă de latență este stiva de protocol și implementarea hardware Nic utilizată pe server. Optimizarea driverului și tehnicile de descărcare a procesorului, cum ar fi TCP Outload Engine (TOE) și Remote Direct Memory Access (RDMA), pot ajuta la scăderea latenței și la reducerea cheltuielilor de procesare pe server.
latența ar putea să nu fie întotdeauna un factor critic în proiectarea clusterului. De exemplu, unele clustere ar putea necesita lățime de bandă mare între servere din cauza unei cantități mari de transfer de fișiere în bloc, dar s-ar putea să nu se bazeze foarte mult pe comunicarea inter-proces server-server (IPC) mesagerie, care poate fi afectată de latență ridicată.
•![]() conectivitate Mesh / partial mesh-proiectele clusterului de servere necesită de obicei o plasă sau o țesătură parțială de plasă pentru a permite comunicarea între toate nodurile din cluster. Această țesătură de plasă este utilizată pentru a partaja starea, datele și alte informații între serverele master-to-compute și compute-to-compute din cluster. Conectivitatea Mesh sau parțial mesh este, de asemenea, dependentă de aplicație.
conectivitate Mesh / partial mesh-proiectele clusterului de servere necesită de obicei o plasă sau o țesătură parțială de plasă pentru a permite comunicarea între toate nodurile din cluster. Această țesătură de plasă este utilizată pentru a partaja starea, datele și alte informații între serverele master-to-compute și compute-to-compute din cluster. Conectivitatea Mesh sau parțial mesh este, de asemenea, dependentă de aplicație.
•![]() randament ridicat-capacitatea de a trimite un fișier mare într-o anumită perioadă de timp poate fi esențială pentru funcționarea și performanța clusterului. Clusterele de servere necesită de obicei o cantitate minimă de lățime de bandă disponibilă care nu blochează, ceea ce se traduce într-un model redus de suprasubscriere între straturile access și core.
randament ridicat-capacitatea de a trimite un fișier mare într-o anumită perioadă de timp poate fi esențială pentru funcționarea și performanța clusterului. Clusterele de servere necesită de obicei o cantitate minimă de lățime de bandă disponibilă care nu blochează, ceea ce se traduce într-un model redus de suprasubscriere între straturile access și core.
•![]() raport suprasubscriere – raportul suprasubscriere trebuie examinat la mai multe puncte de agregare din proiectare, inclusiv cardul de linie pentru a comuta lățimea de bandă a țesăturii și intrarea țesăturii de comutare la lățimea de bandă uplink.
raport suprasubscriere – raportul suprasubscriere trebuie examinat la mai multe puncte de agregare din proiectare, inclusiv cardul de linie pentru a comuta lățimea de bandă a țesăturii și intrarea țesăturii de comutare la lățimea de bandă uplink.
•![]() Suport cadru Jumbo – deși cadrele jumbo ar putea să nu fie utilizate în implementarea inițială a unui cluster de servere, este o caracteristică foarte importantă care este necesară pentru o flexibilitate suplimentară sau pentru posibile cerințe viitoare. Construcția pachetelor TCP / IP plasează cheltuieli suplimentare pe CPU-ul serverului. Utilizarea cadrelor jumbo poate reduce numărul de pachete, reducând astfel această regie.
Suport cadru Jumbo – deși cadrele jumbo ar putea să nu fie utilizate în implementarea inițială a unui cluster de servere, este o caracteristică foarte importantă care este necesară pentru o flexibilitate suplimentară sau pentru posibile cerințe viitoare. Construcția pachetelor TCP / IP plasează cheltuieli suplimentare pe CPU-ul serverului. Utilizarea cadrelor jumbo poate reduce numărul de pachete, reducând astfel această regie.
•![]() densitatea porturilor-clusterele de servere ar putea avea nevoie să se scaleze la zeci de mii de porturi. Ca atare, acestea necesită platforme cu un nivel ridicat de performanță de comutare a pachetelor, o cantitate mare de lățime de bandă a țesăturii de comutare și un nivel ridicat de densitate a portului.
densitatea porturilor-clusterele de servere ar putea avea nevoie să se scaleze la zeci de mii de porturi. Ca atare, acestea necesită platforme cu un nivel ridicat de performanță de comutare a pachetelor, o cantitate mare de lățime de bandă a țesăturii de comutare și un nivel ridicat de densitate a portului.
redirecționare distribuită și latență
comutatorul Cisco Catalyst 6500 Series are capacitatea unică de a susține o redirecționare centrală a pachetelor sau o arhitectură de redirecționare distribuită opțională, în timp ce Cisco Catalyst 4948-10GE este un singur design Central ASIC cu performanță de redirecționare a ratei de linie fixă. Modulele de card Cisco 6700 line acceptă un modul opțional de card fiică numit Card de redirecționare distribuit (DFC). DFC permite luarea deciziilor de rutare locală pe fiecare card de linie prin implementarea unei baze de informații locale de redirecționare (FIB). Tabelul FIB de pe Sup720 PFC menține sincronizarea cu fiecare tabel FIB DFC de pe cardurile de linie pentru a asigura integritatea rutării în întregul sistem.
atunci când cardul DFC opțional nu este prezent, o căutare antet compact este trimis la PFC3 pe Sup720 pentru a determina în cazul în care pe tesatura comutator pentru a transmite fiecare pachet. Când este prezent un DFC, cardul de linie poate comuta un pachet direct pe țesătura comutatorului pe cardul de linie de destinație fără a consulta Sup720. Diferența de performanță poate fi de la 30 Mpps la nivel de sistem fără DFC la 48 Mpps pe slot cu DFC. Comutatorul fix de configurare Catalyst 4948-10GE are o rată de sârmă, arhitectură care nu blochează performanța de până la 101,18 Mpps, oferind performanțe superioare ale stratului de acces pentru partea superioară a modelelor rack.
performanța latenței poate varia semnificativ atunci când se compară modelele distribuite și cele de redirecționare centrală. Tabelul 3-1 oferă un exemplu de latențe măsurate pe un card de linie 6704 cu și fără DFC.
| 6704 cu DFC (Port-to-Port în microsecunde prin țesătură de comutare) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
dimensiunea pachetului (B) |
||||||||||
|
latență (ms) |
||||||||||
| 6704 fără DFC (Port-to-Port în microsecunde prin țesătură de comutare) | ||||||||||
|
dimensiunea pachetului (B) |
||||||||||
|
latență (ms) |
||||||||||
diferența de latență între un DFC activat și este posibil ca cardul de linie care nu este activat DFC să nu pară semnificativ. Cu toate acestea, într-o arhitectură de redirecționare centrală 6500, latența poate crește pe măsură ce ratele de trafic cresc din cauza disputei pentru căutarea partajată pe magistrala centrală. Cu un DFC, calea de căutare este dedicată fiecărei cărți de linie, iar latența este constantă.
Catalyst 6500 lățimea de bandă a sistemului
lățimea de bandă disponibilă a sistemului nu se modifică atunci când sunt utilizate DFC-uri. DFC-urile îmbunătățesc procesarea pachetelor pe secundă (pps) a sistemului general. Tabelul 3-2 rezumă performanța de transfer și lățime de bandă pentru modulele care acceptă DFC-uri, pe lângă modulele mai vechi cef256 și Classic bus.
| configurarea sistemului cu Sup720 | debit în Mpps | lățime de bandă în Gbps |
|
module de serie clasice |
până la 15 Mpps (pe sistem) |
16 g autobuz comun (autobuz clasic) |
|
Module din seria CEF256 |
până la 30 Mpps (pe sistem) |
1x 8 G (dedicat pe slot) |
|
Mix clasic cu module din seria Cef256 sau Cef720 |
până la 15 Mpps (pe sistem) |
dependent de Card |
|
Module din seria CEF720(6748, 6704, 6724) |
până la 30 Mpps (pe sistem) |
2x 20 G (dedicat pe slot) |
|
Module din seria CEF720 cu DFC3 (6704 cu DFC3, 6708 cu DFC3, 6748 cu DFC3 6724 + DFC3) |
susține până la 48 Mpps (pe slot) |
2x 20 G(dedicat pe slot) |
deși 6513 ar putea fi o soluție validă pentru stratul de acces al modelului cluster mare, rețineți că există un amestec de sloturi cu un singur canal și dual în acest șasiu. Sloturi 1 la 8 sunt un singur canal și sloturi 9 la 13 sunt dual channel, așa cum se arată în figura 3-1.
figura 3-1 Catalyst 6500 canale Tesatura de șasiu și Slot (6513 Focus
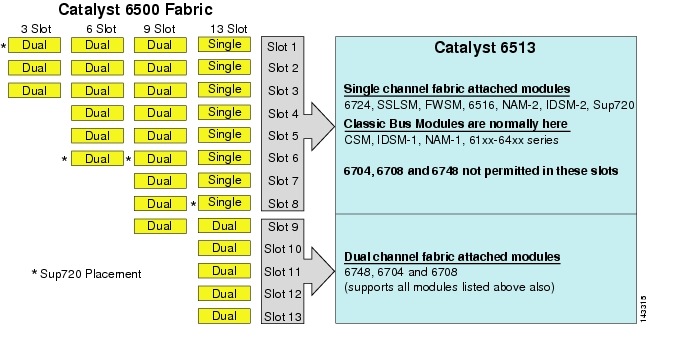
atunci când se utilizează un Cisco Catalyst 6513, carduri dual channel, cum ar fi 6704-4 port 10GigE, 6708 – 8 port 10GigE, și 6748-48 port SFP/carduri de linie de cupru pot fi plasate numai în sloturi 9 la 13. Carduri de linie singur canal, cum ar fi 6724-24 port SFP/cupru linie carduri pot fi utilizate în sloturi 1 la 8. Sup720 utilizează sloturi 7 și 8, care sunt un singur canal 20g Tesatura atașat. Spre deosebire de 6513, 6509 are mai puține sloturi disponibile, dar poate suporta module cu două canale în toate sloturile, deoarece fiecare slot are canale duale către țesătura comutatorului.
notă ![]() deoarece mediul de cluster server necesită de obicei lățime de bandă mare cu caracteristici de latență scăzută, vă recomandăm să utilizați DFC-uri în aceste tipuri de modele.
deoarece mediul de cluster server necesită de obicei lățime de bandă mare cu caracteristici de latență scăzută, vă recomandăm să utilizați DFC-uri în aceste tipuri de modele.
Equal Cost Multi-Path Routing
equal cost multi-path (ECMP) routing este o tehnologie de echilibrare a sarcinii care optimizează fluxurile pe mai multe căi IP între oricare două subrețele într-un mediu activat Cisco Express Forwarding. ECMP aplică echilibrarea sarcinii pentru pachetele TCP și UDP pe bază de flux. Pachetele non-TCP / UDP, cum ar fi ICMP, sunt distribuite pe bază de pachet cu pachet. ECMP se bazează pe RFC 2991 și este utilizat pe alte platforme Cisco, cum ar fi produsele PIX și Cisco Content Services Switch (CSS). ECMP este acceptat atât pe platformele 6500, cât și pe cele 4948-10GE recomandate în proiectarea clusterului de servere.
schimbările dramatice rezultate din ASIC-urile hardware de comutare Layer 3 și algoritmii de hashing Cisco Express Forwarding ajută la distingerea ECMP de tehnologiile sale predecesoare. Principalul beneficiu într-un design ECMP pentru implementările de cluster de servere este algoritmul de hashing combinat cu puțin sau deloc CPU deasupra capului în comutarea stratului 3. Algoritmul de hashing Cisco Express Forwarding este capabil să distribuie fluxuri granulare pe mai multe carduri de linie la rata de linie în hardware. Setarea implicită a algoritmului de hashing este de a hash fluxurile bazate pe adresele IP sursă-destinație Layer 3 și, opțional, adăugarea numerelor de port layer 4 pentru un strat suplimentar de diferențiere. Numărul maxim de căi ECMP permise este de opt.
figura 3-2 ilustrează un design de cluster de server ECMP cu 8 căi. Pentru a simplifica ilustrația, sunt afișate doar două comutatoare de strat de acces, dar pot fi acceptate până la 32 (64 10GigEs pe nod de bază).
figura 3-2 8-Way Ecmp server Cluster Design
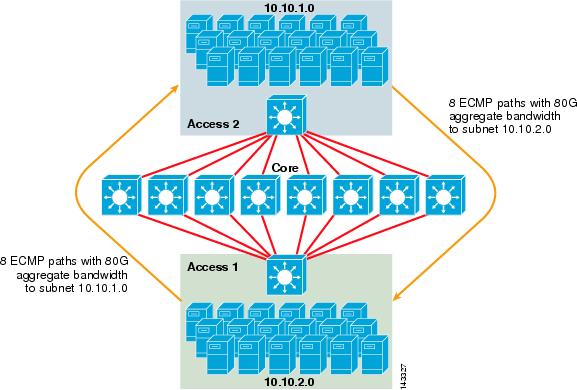
în figura 3-2, fiecare comutator strat de acces poate suporta una sau mai multe subrețele de servere atașate. Fiecare comutator are o singură conexiune 10gige la fiecare dintre cele opt switch-uri de bază folosind două 6704 carduri de linie. Această configurație oferă opt căi de 10gige pentru un total de 80 g de lățime de bandă Cisco Express Forwarding activat la orice altă subrețea din tesatura cluster server. O interogare de afișare a rutei ip către o altă subrețea de pe un alt comutator arată opt intrări cu costuri egale.
miezul este populat cu carduri de linie 10gige cu DFC-uri pentru a permite o țesătură de comutare de mare viteză complet distribuită, cu latență port-port foarte mică. O interogare afișare traseu ip la un comutator strat de acces arată o singură intrare traseu pe fiecare dintre cele opt switch-uri de bază.
notă ![]() deși nu a fost testat pentru acest ghid, există un nou modul 8-port 10 Gigabit Ethernet (WS-X6708-10g-3c), care a fost recent introdus pentru comutatorul Catalyst 6500 Series. Acest card de linie va fi testat pentru includerea în acest ghid la o dată ulterioară. Pentru întrebări despre cardul 10gige cu 8 porturi, consultați fișa tehnică a produsului.
deși nu a fost testat pentru acest ghid, există un nou modul 8-port 10 Gigabit Ethernet (WS-X6708-10g-3c), care a fost recent introdus pentru comutatorul Catalyst 6500 Series. Acest card de linie va fi testat pentru includerea în acest ghid la o dată ulterioară. Pentru întrebări despre cardul 10gige cu 8 porturi, consultați fișa tehnică a produsului.
redundanță în proiectarea clusterului serverului
designul clusterului serverului nu este de obicei implementat cu procesoare redundante CPU sau switch fabric. Reziliența este de obicei realizată în mod inerent în proiectare și prin metoda clusterului funcționează ca un întreg. Așa cum este descris în Capitolul 1 „Prezentare generală a arhitecturii centrelor de date”, nodurile de calcul din cluster sunt gestionate de noduri master care sunt responsabile pentru atribuirea de joburi specifice fiecărui nod de calcul și monitorizarea performanței acestora. Dacă un nod de calcul iese din cluster, acesta se reatribuie la un nod disponibil și continuă să funcționeze, deși cu o putere de procesare mai mică, până când nodul este disponibil. Deși este important să diversificați conexiunile nodului principal din cluster pe diferite comutatoare de acces, nu este esențial pentru nodurile de calcul.
deși procesoarele redundante sunt cu siguranță opționale, este important să se ia în considerare densitatea porturilor, în special în ceea ce privește porturile 10GE, unde un slot suplimentar este disponibil în locul unui modul Sup720 redundant.
notă ![]() exemplele din acest capitol utilizează modele de procesoare non-redundante, care permit un maxim de 64 de porturi 10GE pe 6509 nod de bază disponibil pentru conexiunile de legătură în sus a nodului de acces bazate pe utilizarea unui card de linie 6708 cu 8 porturi 10gige.
exemplele din acest capitol utilizează modele de procesoare non-redundante, care permit un maxim de 64 de porturi 10GE pe 6509 nod de bază disponibil pentru conexiunile de legătură în sus a nodului de acces bazate pe utilizarea unui card de linie 6708 cu 8 porturi 10gige.
Design Cluster Server—model pe două niveluri
această secțiune descrie diferitele abordări ale unui design cluster server care utilizează ECMP și CEF distribuit. Fiecare design demonstrează modul în care diferite configurații pot atinge diferite niveluri de suprasubscriere și pot scala într-o manieră flexibilă, începând cu câteva noduri și crescând la multe care acceptă mii de servere.
designul clusterului de server urmează de obicei un model pe două niveluri format din straturi de bază și de acces. Deoarece obiectivele de proiectare necesită utilizarea stratului 3 ECMP și redirecționarea distribuită pentru a obține o lățime de bandă și o latență extrem de deterministe pe server, un model pe trei niveluri care introduce un alt punct de suprasubscriere nu este de obicei de dorit. Avantajele cu un model pe trei niveluri sunt descrise în Server Cluster Design—model pe trei niveluri.
cele trei calcule principale de luat în considerare la proiectarea unei soluții de cluster server sunt conexiunile maxime ale serverului, lățimea de bandă pe server și raportul de suprasubscriere. Proiectanții de Cluster pot determina aceste valori pe baza performanței aplicației, a hardware-ului serverului și a altor factori, inclusiv următorii:
•![]() numărul maxim de conexiuni GigE de server la scară—proiectanții de Cluster au de obicei o idee despre scara maximă necesară la conceptul inițial. Un beneficiu al modului în care funcționează proiectele ECMP este că pot începe cu un număr minim de comutatoare și servere care îndeplinesc o anumită cerință de lățime de bandă, latență și suprasubscriere și cresc flexibil într-o manieră scăzută/non-perturbatoare la scară maximă, menținând în același timp aceleași valori de lățime de bandă, latență și suprasubscriere.
numărul maxim de conexiuni GigE de server la scară—proiectanții de Cluster au de obicei o idee despre scara maximă necesară la conceptul inițial. Un beneficiu al modului în care funcționează proiectele ECMP este că pot începe cu un număr minim de comutatoare și servere care îndeplinesc o anumită cerință de lățime de bandă, latență și suprasubscriere și cresc flexibil într-o manieră scăzută/non-perturbatoare la scară maximă, menținând în același timp aceleași valori de lățime de bandă, latență și suprasubscriere.
•![]() lățime de bandă aproximativă pe server—această valoare poate fi determinată prin simpla împărțire a lățimii de bandă uplink totală agregată la conexiunile GigE totale ale serverului de pe comutatorul stratului de acces. De exemplu, un strat de acces Cisco 6509 cu patru uplink-uri 10GIGE ECMP cu 336 porturi de acces server poate fi calculată după cum urmează:
lățime de bandă aproximativă pe server—această valoare poate fi determinată prin simpla împărțire a lățimii de bandă uplink totală agregată la conexiunile GigE totale ale serverului de pe comutatorul stratului de acces. De exemplu, un strat de acces Cisco 6509 cu patru uplink-uri 10GIGE ECMP cu 336 porturi de acces server poate fi calculată după cum urmează:
4x10gige uplink-uri cu 336 servere = 120 Mbps pe server
ajustarea fiecare parte a ecuației scade sau crește cantitatea de lățime de bandă pe server.
notă ![]() aceasta este doar o valoare aproximativă și servește doar ca orientare. Diferiți factori influențează cantitatea reală de lățime de bandă pe care fiecare server o are disponibilă. Algoritmul ecmp load-distribution hash împarte sarcina pe baza valorilor Layer 3 plus Layer 4 și variază în funcție de modelele de trafic. De asemenea, parametrii de configurare, cum ar fi limitarea ratei, coada și valorile QoS, pot influența lățimea de bandă reală realizată pe server.
aceasta este doar o valoare aproximativă și servește doar ca orientare. Diferiți factori influențează cantitatea reală de lățime de bandă pe care fiecare server o are disponibilă. Algoritmul ecmp load-distribution hash împarte sarcina pe baza valorilor Layer 3 plus Layer 4 și variază în funcție de modelele de trafic. De asemenea, parametrii de configurare, cum ar fi limitarea ratei, coada și valorile QoS, pot influența lățimea de bandă reală realizată pe server.
•![]() raportul de suprasubscriere pe server—această valoare poate fi determinată prin simpla împărțire a numărului total de conexiuni GigE server la lățimea de bandă uplink totală agregată pe comutatorul stratului de acces. De exemplu, un nivel de acces 6509 cu patru uplink-uri ECMP 10GIGE cu 336 porturi de acces la server poate fi calculat după cum urmează:
raportul de suprasubscriere pe server—această valoare poate fi determinată prin simpla împărțire a numărului total de conexiuni GigE server la lățimea de bandă uplink totală agregată pe comutatorul stratului de acces. De exemplu, un nivel de acces 6509 cu patru uplink-uri ECMP 10GIGE cu 336 porturi de acces la server poate fi calculat după cum urmează:
conexiuni de server 336 GigE cu lățime de bandă uplink 40G = 8.4:1 raport suprasubscriere
următoarele secțiuni demonstrează modul în care aceste valori variază, pe baza diferitelor configurații hardware și de interconectare, și servesc drept îndrumare la proiectarea configurațiilor de cluster mari.
notă ![]() în scopuri de calcul, se presupune că nu există nici o carte de linie pentru a comuta suprasubscriere Tesatura pe comutatorul Catalyst 6500 Series. Slotul cu două canale oferă o lățime de bandă maximă de 40g pentru țesătura comutatorului. Un card de 4 porturi 10GigE cu toate porturile la rata de linie folosind pachete de dimensiuni maxime este considerată cea mai bună condiție posibilă, cu puțin sau deloc suprasubscriere. Cantitatea reală de lățime de bandă a țesăturii de comutare disponibilă variază, în funcție de dimensiunile medii ale pachetelor. Aceste calcule ar trebui să fie recalculate dacă ar fi să utilizați cardul WS-X6708 8-port 10gige, care este suprasubscris la 2:1.
în scopuri de calcul, se presupune că nu există nici o carte de linie pentru a comuta suprasubscriere Tesatura pe comutatorul Catalyst 6500 Series. Slotul cu două canale oferă o lățime de bandă maximă de 40g pentru țesătura comutatorului. Un card de 4 porturi 10GigE cu toate porturile la rata de linie folosind pachete de dimensiuni maxime este considerată cea mai bună condiție posibilă, cu puțin sau deloc suprasubscriere. Cantitatea reală de lățime de bandă a țesăturii de comutare disponibilă variază, în funcție de dimensiunile medii ale pachetelor. Aceste calcule ar trebui să fie recalculate dacă ar fi să utilizați cardul WS-X6708 8-port 10gige, care este suprasubscris la 2:1.
modele ECMP cu 4 și 8 căi cu acces Modular
următoarele patru exemple de proiectare demonstrează diferite metode de construire și scalare a modelului de cluster de server pe două niveluri folosind ECMP cu 4 căi și 8 căi. Principalele probleme de luat în considerare sunt numărul de noduri de bază și numărul maxim de uplink-uri, deoarece acestea influențează direct scara maximă, lățimea de bandă pe server și valorile suprasubscrierii.
notă ![]() deși nu a fost testat pentru acest ghid, există un nou modul 8-port 10 Gigabit Ethernet (WS-X6708-10g-3c), care a fost recent introdus pentru comutatorul Catalyst 6500 Series. Acest card de linie va fi testat pentru includerea în ghid la o dată ulterioară. Pentru întrebări despre cardul 10gige cu 8 porturi, consultați fișa tehnică a produsului.
deși nu a fost testat pentru acest ghid, există un nou modul 8-port 10 Gigabit Ethernet (WS-X6708-10g-3c), care a fost recent introdus pentru comutatorul Catalyst 6500 Series. Acest card de linie va fi testat pentru includerea în ghid la o dată ulterioară. Pentru întrebări despre cardul 10gige cu 8 porturi, consultați fișa tehnică a produsului.
notă ![]() legăturile necesare pentru conectarea clusterului de server la o rețea de campus sau metrou din afara nu sunt prezentate în aceste exemple de proiectare, dar ar trebui luate în considerare.
legăturile necesare pentru conectarea clusterului de server la o rețea de campus sau metrou din afara nu sunt prezentate în aceste exemple de proiectare, dar ar trebui luate în considerare.
figura 3-3 oferă un exemplu în care două noduri de bază sunt utilizate pentru a furniza o soluție ECMP cu 4 căi.
figura 3-3 4-Way ECMP folosind două noduri de bază
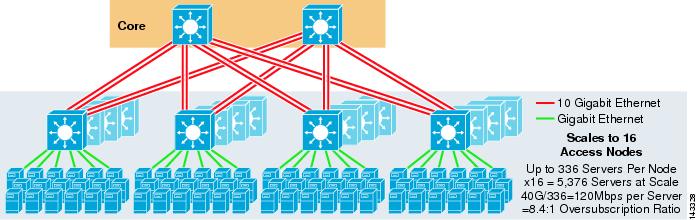
un avantaj al acestei abordări este că un număr mai mic de switch-uri de bază poate sprijini un număr mare de servere. Dezavantajul posibil este o suprasubscriere ridicată-lățime de bandă redusă pe valoare de server și expunere mare la o defecțiune a nodului de bază. Rețineți că uplink-urile sunt uplink-uri individuale L3 și nu sunt EtherChannels.
figura 3-4 demonstrează modul în care adăugarea a două noduri de bază la designul anterior poate crește dramatic scara maximă, menținând în același timp aceleași valori de suprasubscriere și lățime de bandă pe server.
figura 3-4 ECMP cu 4 căi folosind patru noduri de bază
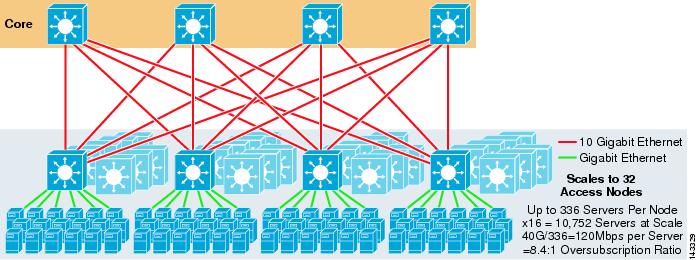
figura 3-5 prezintă un design ECMP cu 8 căi folosind două noduri de bază.
figura 3-5 ECMP cu 8 căi folosind două noduri de bază
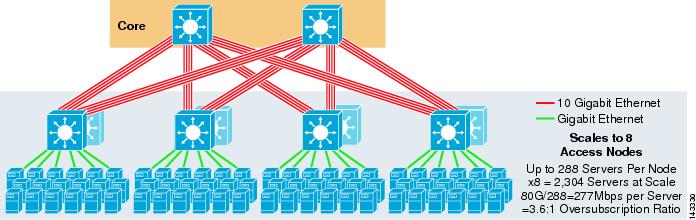
așa cum era de așteptat, lățimea de bandă suplimentară uplink crește dramatic lățimea de bandă pe server și reduce raportul suprasubscriere pe server. Rețineți modul în care sloturile suplimentare luate în fiecare comutator strat de acces pentru a sprijini uplink 8-way reduce scara maximă ca numărul de servere pe-comutator este redus la 288. Rețineți că uplink-urile sunt uplink-uri individuale L3 și nu sunt EtherChannels.
figura 3-6 prezintă un design ECMP cu 8 căi cu opt noduri de bază.
figura 3-6 ECMP cu 8 căi folosind opt noduri de bază
acest lucru demonstrează modul în care adăugarea a patru noduri de bază la același design anterior poate crește dramatic scara maximă, menținând în același timp aceleași valori de suprasubscriere și lățime de bandă pe server.
proiectare ECMP cu 2 căi cu acces 1RU
în multe medii de cluster, comutarea serverului pe bază de rack folosind comutatoare mici în partea de sus a fiecărui rack de server este dorită sau necesară din cauza cablării, a problemelor administrative, imobiliare sau pentru a îndeplini anumite obiective ale modelului de implementare.
figura 3-7 prezintă un exemplu în care două noduri de bază sunt utilizate pentru a furniza o soluție ECMP cu 2 căi cu comutatoare de acces 1RU 4948-10GE.
figura 3-7 ECMP cu 2 căi folosind două noduri de bază și acces 1RU
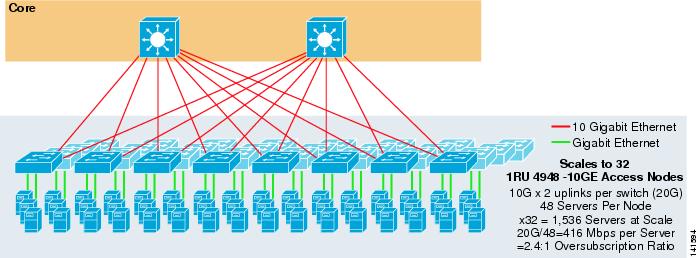
scara maximă este limitată la 1536 servere, dar oferă peste 400 Mbps de lățime de bandă cu un raport redus de suprasubscriere. Deoarece 4948 are doar două uplink-uri 10GigE, acest design nu poate scala dincolo de aceste valori.
notă ![]() mai multe informații despre comutarea serverului pe bază de rack sunt furnizate în Capitolul 3 „proiecte de Cluster de servere cu Ethernet.”
mai multe informații despre comutarea serverului pe bază de rack sunt furnizate în Capitolul 3 „proiecte de Cluster de servere cu Ethernet.”
Design Cluster Server—model pe trei niveluri
deși un model pe două niveluri este cel mai frecvent în proiectele de cluster mari, poate fi utilizat și un model pe trei niveluri. Modelul pe trei niveluri este de obicei utilizat pentru a suporta implementări mari de cluster de servere folosind 1RU sau comutatoare modulare de strat de acces.
figura 3-8 prezintă un exemplu la scară largă care utilizează ECMP cu 8 căi cu 6500 comutatoare de bază și agregare și 1RU 4948-10GE comutatoare de strat de acces.
figura 3-8 model pe trei niveluri cu 8 căi ECMP
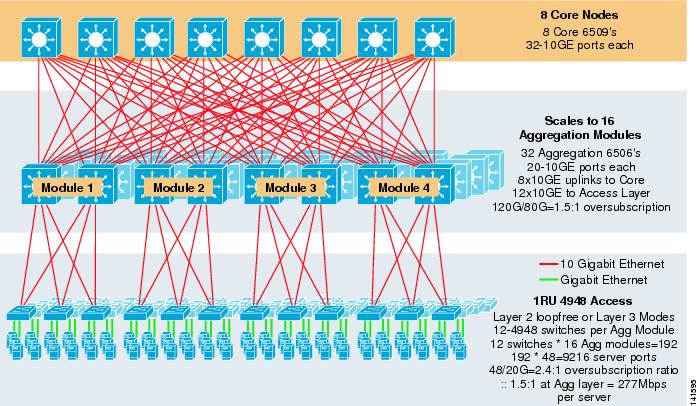
scara maximă este de peste 9200 de servere cu 277 Mbps de lățime de bandă cu un raport redus de suprasubscriere. Beneficiile abordării pe trei niveluri folosind comutatoarele de acces 1RU includ următoarele:
•![]() modele de implementare 1RU – așa cum am menționat anterior, multe implementări de modele mari de cluster necesită o abordare 1RU pentru instalarea simplificată. De exemplu, un ASP rulează rafturi de servere la un moment dat, pe măsură ce scalează aplicații mari de cluster. Rack-ul serverului este pre-asamblat și pus în scenă în afara amplasamentului, astfel încât să poată fi instalat rapid și adăugat la clusterul care rulează. Aceasta implică, de obicei, o terță parte care construiește rafturile, pre-configurează serverele și le pre-cablează cu power și Ethernet la un comutator 1RU. Rack-ul se rulează în centrul de date și este pur și simplu conectat și adăugat la cluster după conectarea uplink-urilor.
modele de implementare 1RU – așa cum am menționat anterior, multe implementări de modele mari de cluster necesită o abordare 1RU pentru instalarea simplificată. De exemplu, un ASP rulează rafturi de servere la un moment dat, pe măsură ce scalează aplicații mari de cluster. Rack-ul serverului este pre-asamblat și pus în scenă în afara amplasamentului, astfel încât să poată fi instalat rapid și adăugat la clusterul care rulează. Aceasta implică, de obicei, o terță parte care construiește rafturile, pre-configurează serverele și le pre-cablează cu power și Ethernet la un comutator 1RU. Rack-ul se rulează în centrul de date și este pur și simplu conectat și adăugat la cluster după conectarea uplink-urilor.
fără un strat de agregare, dimensiunea maximă a modelului de acces 1RU este limitată la puțin peste 1500 de servere. Adăugarea unui strat de agregare permite modelului de acces 1RU să se scaleze la o dimensiune mult mai mare, în timp ce încă utilizează modelul ECMP.
•![]() centralizarea comutatoarelor de bază și de agregare—cu comutatoarele 1RU desfășurate în rafturi, este posibilă centralizarea comutatoarelor modulare de bază și agregare mai mari. Acest lucru poate simplifica infrastructura de alimentare și cablare și poate îmbunătăți utilizarea imobiliară a rafturilor.
centralizarea comutatoarelor de bază și de agregare—cu comutatoarele 1RU desfășurate în rafturi, este posibilă centralizarea comutatoarelor modulare de bază și agregare mai mari. Acest lucru poate simplifica infrastructura de alimentare și cablare și poate îmbunătăți utilizarea imobiliară a rafturilor.
•![]() permite topologia fără buclă Layer 2—o rețea de cluster mare care utilizează accesul Ecmp Layer 3 poate utiliza mult spațiu de adrese pe uplink-uri și poate adăuga complexitate designului. Acest lucru este deosebit de important dacă se utilizează spațiul de adrese publice. Abordarea modelului pe trei niveluri se pretează bine unei topologii de acces fără buclă Layer 2 care reduce numărul de subrețele necesare.
permite topologia fără buclă Layer 2—o rețea de cluster mare care utilizează accesul Ecmp Layer 3 poate utiliza mult spațiu de adrese pe uplink-uri și poate adăuga complexitate designului. Acest lucru este deosebit de important dacă se utilizează spațiul de adrese publice. Abordarea modelului pe trei niveluri se pretează bine unei topologii de acces fără buclă Layer 2 care reduce numărul de subrețele necesare.
când se utilizează un model fără buclă Layer 2, este important să se utilizeze un protocol gateway implicit redundant, cum ar fi HSRP sau GLBP, pentru a elimina un singur punct de eșec dacă un nod de agregare eșuează. În acest design, modulele de agregare nu sunt interconectate, permițând un design layer 2 fără buclă care poate utiliza GLBP pentru echilibrarea automată a încărcării gateway-ului implicit al serverului. GLBP distribuie automat atribuirea implicită a gateway-ului serverelor între cele două noduri din modulul de agregare. După ce un pachet ajunge la stratul de agregare, acesta este echilibrat pe miez folosind țesătura ECMP cu 8 căi. Deși GLBP nu oferă un hash de distribuție a sarcinii Layer 3/Layer 4 similar cu CEF, este o alternativă care poate fi utilizată cu o topologie de acces Layer 2.
calculul Suprasubscrierii
modelul pe trei niveluri introduce două puncte de suprasubscriere la straturile de acces și agregare, în comparație cu modelul pe două niveluri care are doar un singur punct de suprasubscriere la nivelul de acces. Pentru a calcula corect lățimea de bandă aproximativă pe server și raportul suprasubscriere, efectuați următorii doi pași, care folosesc figura 3-8 ca exemplu:
Pasul 1 ![]() calculați raportul suprasubscriere și lățimea de bandă pe server atât pentru straturile de agregare, cât și pentru cele de acces în mod independent.
calculați raportul suprasubscriere și lățimea de bandă pe server atât pentru straturile de agregare, cât și pentru cele de acces în mod independent.
•![]() stratul de acces
stratul de acces
–![]() suprasubscriere-48ge servere atașate / 20g uplink-uri la agregare = 2.4:1
suprasubscriere-48ge servere atașate / 20g uplink-uri la agregare = 2.4:1
–![]() lățime de bandă pe server-20g uplink la agregare / 48gige servere atașate = 416Mbps
lățime de bandă pe server-20g uplink la agregare / 48gige servere atașate = 416Mbps
•![]() stratul de agregare
stratul de agregare
–![]() suprasubscriere—120g downlinks pentru a accesa / 80g uplink-uri la bază = 1.5:1
suprasubscriere—120g downlinks pentru a accesa / 80g uplink-uri la bază = 1.5:1
Pasul 2 ![]() calculați raportul combinat de suprasubscriere și lățimea de bandă pe server.
calculați raportul combinat de suprasubscriere și lățimea de bandă pe server.
raportul real de suprasubscriere este suma celor două puncte de suprasubscriere la straturile de acces și agregare.
1.5*2.4 = 3.6:1
pentru a determina adevărata lățime de bandă pe server valoare, utilizați formula algebrică pentru proporții:
a:b = C:d
lățimea de bandă pe server la stratul de acces a fost determinată a fi 416 Mbps pe server. Deoarece raportul de suprasubscriere a stratului de agregare este de 1,5: 1, puteți aplica formula de mai sus după cum urmează:
416:1 = x: 1.5
x=~264 Mbps per server
Hardware și module recomandate
platformele recomandate pentru proiectarea modelului de cluster server constau din familia Cisco Catalyst 6500 cu modulul de procesor Sup720 și comutatorul Catalyst 4948-10GE 1RU. Rata mare de comutare, Tesatura comutator mare, latență scăzută, redirecționare distribuite, și densitatea 10gige face Catalyst 6500 Seria comutator ideal pentru toate straturile acestui model. Factorul de formă 1RU combinat cu redirecționarea ratei de sârmă, uplink-urile 10GE și latența constantă foarte scăzută fac din 4948-10GE un top excelent al soluției rack pentru stratul de acces.
se recomandă următoarele:
•![]() Sup720-Sup720 poate consta din ambele PFC3A (implicit) sau mai noi PFC3B carduri de tip fiică.
Sup720-Sup720 poate consta din ambele PFC3A (implicit) sau mai noi PFC3B carduri de tip fiică.
•![]() carduri de linie—toate cardurile de linie ar trebui să fie seria 6700 și ar trebui să fie activate pentru redirecționarea distribuită cu cardurile dfc3a sau dfc3b daughter.
carduri de linie—toate cardurile de linie ar trebui să fie seria 6700 și ar trebui să fie activate pentru redirecționarea distribuită cu cardurile dfc3a sau dfc3b daughter.
notă ![]() prin utilizarea tuturor modulelor din seria cef720 atașate la țesătură, modul de comutare globală este compact, ceea ce permite sistemului să funcționeze la cel mai înalt nivel de performanță. Catalyst 6509 poate suporta 10 module GigE în toate pozițiile, deoarece fiecare slot suportă canale duale la Tesatura comutator (Cisco Catalyst 6513 nu acceptă acest lucru).
prin utilizarea tuturor modulelor din seria cef720 atașate la țesătură, modul de comutare globală este compact, ceea ce permite sistemului să funcționeze la cel mai înalt nivel de performanță. Catalyst 6509 poate suporta 10 module GigE în toate pozițiile, deoarece fiecare slot suportă canale duale la Tesatura comutator (Cisco Catalyst 6513 nu acceptă acest lucru).
•![]() Cisco Catalyst 4948-10GE-4948-10GE oferă o soluție de înaltă performanță strat de acces, care poate pârghie ecmp și 10gige uplink-uri. Nu sunt necesare cerințe speciale. 4948 – 10GE poate utiliza o imagine Cisco IOS Layer 2 sau o imagine Cisco IOS layer 2/3, permițând o potrivire optimă în ambele medii.
Cisco Catalyst 4948-10GE-4948-10GE oferă o soluție de înaltă performanță strat de acces, care poate pârghie ecmp și 10gige uplink-uri. Nu sunt necesare cerințe speciale. 4948 – 10GE poate utiliza o imagine Cisco IOS Layer 2 sau o imagine Cisco IOS layer 2/3, permițând o potrivire optimă în ambele medii.