




Cisco Data Center de Infra-estrutura 2.5 Guia de Design
Cluster de Servidor com Projetos de Ethernet
Uma visão geral de alto nível dos servidores e componentes de rede utilizados no modelo de cluster de servidor é fornecida no Capítulo 1 “Centro de Dados Visão geral da Arquitetura.”Este capítulo descreve a finalidade e a função de cada camada do modelo de cluster do servidor em maior detalhe. As seguintes seções estão incluídas:
•![]() Objectivos Técnicos
Objectivos Técnicos
•![]() Encaminhamento Distribuído e Latência
Encaminhamento Distribuído e Latência
•![]() Custo Igual Multi-Caminho de Roteamento
Custo Igual Multi-Caminho de Roteamento
•![]() Cluster de Servidor de Projeto—Modelo de Duas Camadas
Cluster de Servidor de Projeto—Modelo de Duas Camadas
•![]() Cluster de Servidor de Projeto—Modelo de Três Camadas
Cluster de Servidor de Projeto—Modelo de Três Camadas
•![]() Recomendados de Hardware e Módulos
Recomendados de Hardware e Módulos

Nota ![]() O design de modelos abordados neste capítulo não foi totalmente comprovada em Cisco testes de laboratório, devido ao tamanho e o escopo dos testes que seriam necessários. Os modelos de duas camadas que são cobertos são projetos semelhantes que foram implementados em redes de produção de clientes.
O design de modelos abordados neste capítulo não foi totalmente comprovada em Cisco testes de laboratório, devido ao tamanho e o escopo dos testes que seriam necessários. Os modelos de duas camadas que são cobertos são projetos semelhantes que foram implementados em redes de produção de clientes.
objetivos técnicos
ao projetar uma rede de cluster de grandes empresas, é fundamental considerar objetivos específicos. Não há dois clusters exatamente iguais; cada um tem seus próprios requisitos específicos e deve ser examinado a partir de uma perspectiva de aplicação para determinar os requisitos de projeto específicos. Leve em consideração as seguintes considerações técnicas:
•![]() latência – no transporte de rede, a latência pode afetar negativamente o desempenho geral do cluster. O uso de plataformas de comutação que empregam uma arquitetura de comutação de baixa latência ajuda a garantir um desempenho ideal. A principal fonte de latência é a pilha de protocolo e a implementação de hardware NIC usada no servidor. A otimização do Driver e as técnicas de descarregamento da CPU, como o TCP Offload Engine (TOE) e o Remote Direct Memory Access (RDMA), podem ajudar a diminuir a latência e reduzir a sobrecarga de processamento no servidor. A latência pode nem sempre ser um fator crítico no design do cluster. Por exemplo, alguns clusters podem exigir alta largura de banda entre servidores por causa de uma grande quantidade de transferência de arquivos em massa, mas podem não depender muito de mensagens de comunicação entre processos de servidor para servidor (IPC), que podem ser impactadas por alta latência.
latência – no transporte de rede, a latência pode afetar negativamente o desempenho geral do cluster. O uso de plataformas de comutação que empregam uma arquitetura de comutação de baixa latência ajuda a garantir um desempenho ideal. A principal fonte de latência é a pilha de protocolo e a implementação de hardware NIC usada no servidor. A otimização do Driver e as técnicas de descarregamento da CPU, como o TCP Offload Engine (TOE) e o Remote Direct Memory Access (RDMA), podem ajudar a diminuir a latência e reduzir a sobrecarga de processamento no servidor. A latência pode nem sempre ser um fator crítico no design do cluster. Por exemplo, alguns clusters podem exigir alta largura de banda entre servidores por causa de uma grande quantidade de transferência de arquivos em massa, mas podem não depender muito de mensagens de comunicação entre processos de servidor para servidor (IPC), que podem ser impactadas por alta latência.
•![]() conectividade de malha / malha parcial—os projetos de cluster do servidor geralmente exigem uma malha ou tecido de malha parcial para permitir a comunicação entre todos os nós do cluster. Esse tecido de malha é usado para compartilhar estado, dados e outras informações entre servidores mestre para computação e computação para computação no cluster. A conectividade de malha ou malha parcial também depende do aplicativo.
conectividade de malha / malha parcial—os projetos de cluster do servidor geralmente exigem uma malha ou tecido de malha parcial para permitir a comunicação entre todos os nós do cluster. Esse tecido de malha é usado para compartilhar estado, dados e outras informações entre servidores mestre para computação e computação para computação no cluster. A conectividade de malha ou malha parcial também depende do aplicativo.
•![]() alta taxa de transferência—a capacidade de enviar um arquivo grande em um período específico de tempo pode ser fundamental para a operação e o desempenho do cluster. Os clusters de servidor normalmente exigem uma quantidade mínima de largura de banda disponível sem bloqueio, o que se traduz em um modelo de oversubscription baixo entre as camadas de acesso e núcleo.
alta taxa de transferência—a capacidade de enviar um arquivo grande em um período específico de tempo pode ser fundamental para a operação e o desempenho do cluster. Os clusters de servidor normalmente exigem uma quantidade mínima de largura de banda disponível sem bloqueio, o que se traduz em um modelo de oversubscription baixo entre as camadas de acesso e núcleo.
•![]() relação de inscrição excessiva – a relação de inscrição excessiva deve ser examinada em vários pontos de agregação no design, incluindo a placa de linha para alternar a largura de banda do tecido e a entrada do tecido do interruptor para uplink a largura de banda.
relação de inscrição excessiva – a relação de inscrição excessiva deve ser examinada em vários pontos de agregação no design, incluindo a placa de linha para alternar a largura de banda do tecido e a entrada do tecido do interruptor para uplink a largura de banda.
•![]() suporte a quadros Jumbo – embora os quadros jumbo possam não ser usados na implementação inicial de um cluster de servidor, é um recurso muito importante que é necessário para flexibilidade adicional ou para possíveis requisitos futuros. A construção de pacotes TCP/IP coloca sobrecarga adicional na CPU do servidor. O uso de quadros jumbo pode reduzir o número de pacotes, reduzindo assim essa sobrecarga.
suporte a quadros Jumbo – embora os quadros jumbo possam não ser usados na implementação inicial de um cluster de servidor, é um recurso muito importante que é necessário para flexibilidade adicional ou para possíveis requisitos futuros. A construção de pacotes TCP/IP coloca sobrecarga adicional na CPU do servidor. O uso de quadros jumbo pode reduzir o número de pacotes, reduzindo assim essa sobrecarga.
•![]() densidade de Portas-os clusters de servidor podem precisar ser dimensionados para dezenas de milhares de portas. Como tal, eles exigem plataformas com um alto nível de desempenho de comutação de Pacotes, uma grande quantidade de largura de banda do switch fabric e um alto nível de densidade de porta.
densidade de Portas-os clusters de servidor podem precisar ser dimensionados para dezenas de milhares de portas. Como tal, eles exigem plataformas com um alto nível de desempenho de comutação de Pacotes, uma grande quantidade de largura de banda do switch fabric e um alto nível de densidade de porta.
encaminhamento distribuído e latência
o switch Cisco Catalyst 6500 Series tem a capacidade exclusiva de suportar um encaminhamento de pacote central ou arquitetura de encaminhamento distribuído opcional, enquanto o Cisco Catalyst 4948-10GE é um único projeto ASIC central com desempenho de encaminhamento de taxa de linha fixa. Os módulos de Placa de linha Cisco 6700 suportam um módulo de placa filha opcional chamado de cartão de encaminhamento distribuído (DFC). O DFC permite que as decisões de roteamento local ocorram em cada placa de linha implementando uma base de informações de encaminhamento local (FIB). A tabela FIB no Sup720 PFC mantém a sincronização com cada tabela FIB DFC nas placas de linha para garantir a integridade de roteamento em todo o sistema.
quando o cartão DFC opcional não está presente, uma pesquisa de cabeçalho compacta é enviada para o PFC3 no Sup720 para determinar onde no tecido do switch encaminhar cada pacote. Quando um DFC está presente, a placa de linha pode mudar um pacote diretamente através da tela do interruptor para a placa de linha de destino sem consultar o Sup720. A diferença no desempenho pode ser de 30 Mpps em todo o sistema sem DFCs a 48 Mpps por slot com DFCs. O interruptor fixo do catalizador 4948-10GE da configuração tem uma taxa do fio, arquitetura não-obstruindo suportando até o desempenho 101.18 Mpps, fornecendo o desempenho superior da camada do acesso para a parte superior de projetos da cremalheira.
o desempenho de latência pode variar significativamente ao comparar os modelos de encaminhamento distribuído e central. A tabela 3-1 fornece um exemplo de latências medidas em uma placa de linha 6704 com e sem DFCs.
| 6704 com DFC (Porta-a-Porta em Microssegundos através do Interruptor de Tecido) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
tamanho do Pacote B) |
||||||||||
|
Latência (ms) |
||||||||||
| 6704 sem DFC (Porta-a-Porta em Microssegundos através do Interruptor de Tecido) | ||||||||||
|
tamanho do Pacote B) |
||||||||||
|
Latência (ms) |
||||||||||
A diferença de latência entre a DFC habilitado e a placa de linha não habilitada para DFC pode não parecer significativa. No entanto, em uma arquitetura de encaminhamento central 6500, a latência pode aumentar à medida que as taxas de tráfego aumentam devido à disputa pela pesquisa compartilhada no barramento central. Com um DFC, o caminho de pesquisa é dedicado a cada placa de linha e a latência é constante.
Catalyst 6500 largura de banda do sistema
a largura de banda do sistema disponível não muda quando os DFCs são usados. Os DFCs melhoram o processamento de pacotes por segundo (pps) do sistema geral. A tabela 3-2 resume a taxa de transferência e o desempenho da largura de banda para módulos que suportam DFCs, além dos módulos CEF256 e classic bus mais antigos.
| Configuração do Sistema com o Sup720 | taxa de transferência em Mpps | Gbps de largura de Banda |
|
Clássica série de módulos de |
Até 15 Mpps (por sistema) |
16 G barramento compartilhado (clássico de ônibus) |
|
CEF256 módulos da Série |
Até 30 Mpps (por sistema) |
1x de 8 G (dedicado por slot) |
|
Mistura de clássico com CEF256 ou CEF720 Série de módulos de |
Até 15 Mpps (por sistema) |
Cartão de dependentes |
|
CEF720 Série de módulos de (6748, 6704, 6724) |
Até 30 Mpps (por sistema) |
2x de 20 G (dedicado por slot) |
|
CEF720 Série de módulos com DFC3 (6704 com DFC3, 6708 com DFC3, 6748 com DFC3 6724+DFC3) |
Sustentar até 48 Mpps (por slot) |
2x de 20 G (dedicado por slot) |
Embora o 6513 pode ser uma solução válida para a camada de acesso do grande modelo de cluster, observe que há uma mistura de canal único ou duplo slots neste chassis. Os Slots 1 a 8 são de canal único e os slots 9 a 13 são de canal duplo, conforme mostrado na figura 3-1.
Figura 3-1 Catalyst 6500 Tecido Canais por Chassi e o Slot (6513 Foco
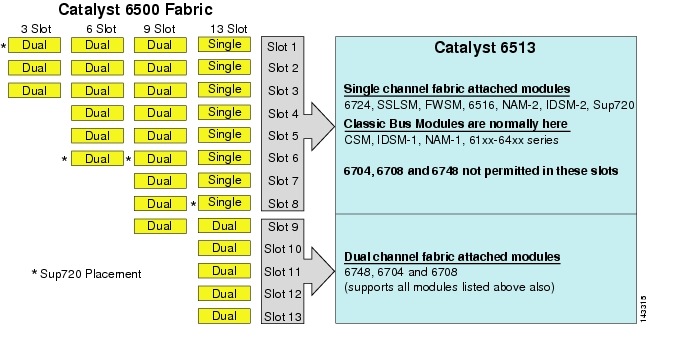
Quando um Cisco Catalyst 6513 é usado, o dual channel cartões, tais como o 6704-4 porta 10GigE, o 6708 – 8 porta 10GigE, e o 6748-48 porta SFP/cobre linha de cartões só podem ser colocados nos slots de 9 para 13. As placas de linha de canal único, como as placas de linha SFP/cobre de porta 6724-24, podem ser usadas nos slots 1 a 8. O Sup720 usa entalhes 7 e 8, que são tela do único canal 20g Unida. Em contraste com o 6513, o 6509 tem menos slots disponíveis, mas pode suportar módulos de canal duplo em todos os slots porque cada slot tem canais duplos para o tecido do switch.
Nota ![]() como o ambiente de cluster do servidor geralmente requer alta largura de banda com características de baixa latência, recomendamos o uso de DFCs nesses tipos de designs.
como o ambiente de cluster do servidor geralmente requer alta largura de banda com características de baixa latência, recomendamos o uso de DFCs nesses tipos de designs.
custo igual roteamento multi-caminho
custo igual o roteamento multi-caminho (ECMP) é uma tecnologia de balanceamento de carga que otimiza fluxos em vários caminhos IP entre duas sub-redes em um ambiente habilitado para Cisco Express Forwarding. O ECMP aplica balanceamento de carga para pacotes TCP e UDP em uma base por fluxo. Pacotes não TCP / UDP, como ICMP, são distribuídos em uma base de pacote por pacote. O ECMP é baseado no RFC 2991 e é aproveitado em outras plataformas Cisco, como os produtos Pix e Cisco Content Services Switch (CSS). O ECMP é suportado nas plataformas 6500 e 4948-10GE recomendadas no design do cluster do servidor.
as mudanças dramáticas resultantes de Hardware de comutação Da Camada 3 ASICS e Cisco Express Forwarding hashing algorithms ajudam a distinguir o ECMP de suas tecnologias predecessoras. O principal benefício em um projeto ECMP para implementações de cluster de servidor é o algoritmo de hash combinado com pouca ou nenhuma sobrecarga de CPU na comutação Da Camada 3. O algoritmo hashing Cisco Express Forwarding é capaz de distribuir fluxos granulares em várias placas de linha à taxa de linha no hardware. A configuração padrão do algoritmo de hash é para fluxos de hash com base nos endereços IP de destino de origem da camada 3 e, opcionalmente, adicionar números de porta da camada 4 para uma camada adicional de diferenciação. O número máximo de caminhos ECMP permitidos é oito.
a figura 3-2 ilustra um design de cluster de servidor ECMP de 8 vias. Para simplificar a ilustração, apenas dois switches de camada de acesso são mostrados, mas até 32 podem ser suportados (64 10 gig por nó principal).
figura 3-2 8-Way ECMP Server Cluster Design
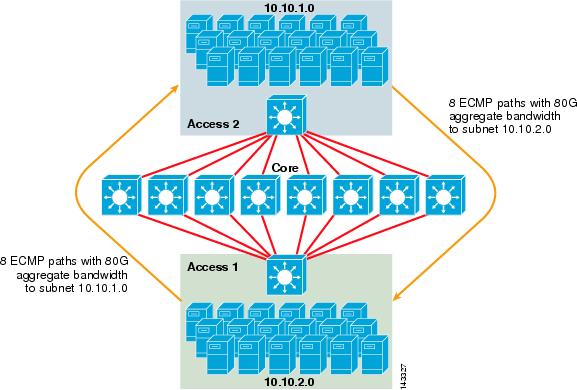
na figura 3-2, cada switch de camada de acesso pode suportar uma ou mais sub-redes de servidores anexados. Cada interruptor tem uma única conexão 10GigE a cada um dos oito interruptores do núcleo usando duas placas de linha 6704. Essa configuração fornece oito caminhos de 10GigE para um total de 80 g de largura de banda habilitada para Cisco Express Forwarding para qualquer outra sub-rede no tecido do cluster do servidor. Uma consulta show ip route para outra sub-rede em outro switch mostra oito entradas de custo igual.
o núcleo é preenchido com placas de linha 10GigE com DFCs para permitir um tecido de comutação de alta velocidade totalmente distribuído com latência porta a porta muito baixa. Uma consulta show ip route para um switch de camada de acesso mostra uma única entrada de rota em cada um dos oito switches principais.
Nota ![]() Embora não tenha sido testado para este guia, há um novo 8-portas 10 Gigabit Ethernet (módulo WS-X6708-10G-3C), que foi recentemente introduzido para o Catalyst 6500 Series switch. Esta placa de linha será testada para inclusão neste guia em uma data posterior. Para perguntas sobre o cartão 10GigE de 8 portas, consulte a folha de dados do produto.
Embora não tenha sido testado para este guia, há um novo 8-portas 10 Gigabit Ethernet (módulo WS-X6708-10G-3C), que foi recentemente introduzido para o Catalyst 6500 Series switch. Esta placa de linha será testada para inclusão neste guia em uma data posterior. Para perguntas sobre o cartão 10GigE de 8 portas, consulte a folha de dados do produto.
redundância no design do Cluster do servidor
o design do cluster do servidor normalmente não é implementado com processadores redundantes de CPU ou switch fabric. A resiliência é tipicamente alcançada inerentemente no design e pelo método o cluster funciona como um todo. Conforme descrito no Capítulo 1 “Visão Geral da arquitetura de Data Center”, os nós de computação no cluster são gerenciados por nós mestres responsáveis por atribuir tarefas específicas a cada nó de computação e monitorar seu desempenho. Se um nó de computação sair do cluster, ele será reatribuído a um nó disponível e continuará a operar, embora com menos poder de processamento, até que o nó esteja disponível. Embora seja importante diversificar as conexões de nó mestre no cluster em diferentes switches de acesso, não é crítico para os nós de computação.
embora as CPUs redundantes sejam certamente opcionais, é importante considerar a densidade da porta, particularmente em relação às portas 10GE, onde um slot extra está disponível no lugar de um módulo Sup720 redundante.
Nota ![]() os exemplos neste capítulo usam projetos de CPU não redundantes, que permitem um máximo de 64 portas 10GE por nó de núcleo 6509 disponível para conexões de uplink de nó de acesso com base no uso de uma placa de linha 10GigE de 8 portas 6708.
os exemplos neste capítulo usam projetos de CPU não redundantes, que permitem um máximo de 64 portas 10GE por nó de núcleo 6509 disponível para conexões de uplink de nó de acesso com base no uso de uma placa de linha 10GigE de 8 portas 6708.
Server Cluster Design—modelo de duas camadas
esta seção descreve as várias abordagens de um design de cluster de servidor que aproveita o ECMP e o CEF distribuído. Cada design demonstra como diferentes configurações podem atingir vários níveis de oversubscription e podem escalar de maneira flexível, começando com alguns nós e crescendo para muitos que suportam milhares de servidores.
o design do cluster do servidor normalmente segue um modelo de duas camadas que consiste em camadas de núcleo e acesso. Como os objetivos do projeto exigem o uso de ECMP de Camada 3 e encaminhamento distribuído para obter uma largura de banda e latência altamente determinísticas por servidor, um modelo de três camadas que introduz outro ponto de inscrição excessiva geralmente não é desejável. As vantagens com um modelo de três camadas são descritas no design de Cluster de servidor—modelo de três camadas.
os três principais cálculos a serem considerados ao projetar uma solução de cluster de servidor são conexões máximas do servidor, largura de banda por servidor e taxa de inscrição excessiva. Os designers de Cluster podem determinar esses valores com base no desempenho do aplicativo, no hardware do servidor e em outros fatores, incluindo o seguinte:
•![]() Número máximo de conexões GigE de servidor em escala-os designers de Cluster normalmente têm uma ideia da escala máxima necessária no conceito inicial. Um benefício do caminho ECMP projetos de função é que eles podem começar com um número mínimo de switches e servidores que atendem a uma determinada largura de banda, latência e excesso de demanda requisito, de forma flexível e crescer em uma baixa/sem interrupções, de forma a escala máxima, mantendo a mesma largura de banda, latência, e o excesso de propostas de valores.
Número máximo de conexões GigE de servidor em escala-os designers de Cluster normalmente têm uma ideia da escala máxima necessária no conceito inicial. Um benefício do caminho ECMP projetos de função é que eles podem começar com um número mínimo de switches e servidores que atendem a uma determinada largura de banda, latência e excesso de demanda requisito, de forma flexível e crescer em uma baixa/sem interrupções, de forma a escala máxima, mantendo a mesma largura de banda, latência, e o excesso de propostas de valores.
•![]() largura de banda aproximada por Servidor—Esse valor pode ser determinado simplesmente dividindo a largura de banda total agregada de uplink pelas conexões GigE totais do servidor no switch de camada de acesso. Por exemplo, uma camada de acesso Cisco 6509 com quatro 10GigE ECMP uplinks com 336 servidor portas de acesso pode ser calculado da seguinte forma:
largura de banda aproximada por Servidor—Esse valor pode ser determinado simplesmente dividindo a largura de banda total agregada de uplink pelas conexões GigE totais do servidor no switch de camada de acesso. Por exemplo, uma camada de acesso Cisco 6509 com quatro 10GigE ECMP uplinks com 336 servidor portas de acesso pode ser calculado da seguinte forma:
4x10GigE Uplinks com 336 servidores = 120 Mbps por servidor
Ajustar ambos os lados da equação diminui ou aumenta a quantidade de largura de banda por servidor.
Nota ![]() este é apenas um valor aproximado e serve apenas como uma diretriz. Vários fatores influenciam a quantidade real de largura de banda que cada servidor tem disponível. O algoritmo de hash de distribuição de carga ECMP divide a carga com base nos valores da camada 3 mais a camada 4 e varia com base nos padrões de tráfego. Além disso, parâmetros de configuração como limitação de taxa, enfileiramento e valores de QoS podem influenciar a largura de banda real alcançada por servidor.
este é apenas um valor aproximado e serve apenas como uma diretriz. Vários fatores influenciam a quantidade real de largura de banda que cada servidor tem disponível. O algoritmo de hash de distribuição de carga ECMP divide a carga com base nos valores da camada 3 mais a camada 4 e varia com base nos padrões de tráfego. Além disso, parâmetros de configuração como limitação de taxa, enfileiramento e valores de QoS podem influenciar a largura de banda real alcançada por servidor.
•![]() taxa de inscrição excessiva por Servidor-Esse valor pode ser determinado simplesmente dividindo o número total de conexões GigE do servidor pela largura de banda total agregada do uplink no switch da camada de acesso. Por exemplo, uma camada de acesso 6509 com quatro uplinks 10GigE ECMP com 336 portas de acesso de servidor pode ser calculada da seguinte forma:
taxa de inscrição excessiva por Servidor-Esse valor pode ser determinado simplesmente dividindo o número total de conexões GigE do servidor pela largura de banda total agregada do uplink no switch da camada de acesso. Por exemplo, uma camada de acesso 6509 com quatro uplinks 10GigE ECMP com 336 portas de acesso de servidor pode ser calculada da seguinte forma:
336 conexões de servidor GigE com 40G uplink bandwidth = 8.4: 1 oversubscription ratio
as seções a seguir demonstram como esses valores variam, com base em diferentes configurações de hardware e interconexão, e servem como uma diretriz ao projetar grandes configurações de cluster.
Nota ![]() para fins de cálculo, presume-se que não haja placa de linha para alternar a inscrição excessiva do tecido no switch Catalyst 6500 Series. O slot de canal duplo fornece largura de banda máxima de 40G para o tecido do switch. Um cartão 10GigE de 4 portas com todas as portas na taxa de linha usando pacotes de tamanho máximo é considerado a melhor condição possível com pouca ou nenhuma inscrição excessiva. A quantidade real de largura de banda do switch fabric disponível varia, com base nos tamanhos médios de pacotes. Esses cálculos precisariam ser recomputados se você usasse o cartão 10GigE de 8 portas WS-X6708, que é supersubscrito em 2: 1.
para fins de cálculo, presume-se que não haja placa de linha para alternar a inscrição excessiva do tecido no switch Catalyst 6500 Series. O slot de canal duplo fornece largura de banda máxima de 40G para o tecido do switch. Um cartão 10GigE de 4 portas com todas as portas na taxa de linha usando pacotes de tamanho máximo é considerado a melhor condição possível com pouca ou nenhuma inscrição excessiva. A quantidade real de largura de banda do switch fabric disponível varia, com base nos tamanhos médios de pacotes. Esses cálculos precisariam ser recomputados se você usasse o cartão 10GigE de 8 portas WS-X6708, que é supersubscrito em 2: 1.
projetos ECMP de 4 e 8 vias com acesso Modular
os quatro exemplos de design a seguir demonstram vários métodos de construção e dimensionamento do modelo de cluster de servidor de duas camadas usando ECMP de 4 e 8 vias. Os principais problemas a serem considerados são o número de nós principais e o número máximo de uplinks, porque eles influenciam diretamente a escala máxima, a largura de banda por servidor e os valores de oversubscription.
Nota ![]() Embora não tenha sido testado para este guia, há um novo 8-portas 10 Gigabit Ethernet (Módulo WS-X6708-10G-3C), que foi recentemente introduzido para o Catalyst 6500 Series switch. Esta placa de linha será testada para inclusão no Guia em uma data posterior. Para perguntas sobre o cartão 10GigE de 8 portas, consulte a folha de dados do produto.
Embora não tenha sido testado para este guia, há um novo 8-portas 10 Gigabit Ethernet (Módulo WS-X6708-10G-3C), que foi recentemente introduzido para o Catalyst 6500 Series switch. Esta placa de linha será testada para inclusão no Guia em uma data posterior. Para perguntas sobre o cartão 10GigE de 8 portas, consulte a folha de dados do produto.
Nota ![]() os links necessários para conectar o cluster do servidor a um campus externo ou rede de metrô não são mostrados nesses exemplos de design, mas devem ser considerados.
os links necessários para conectar o cluster do servidor a um campus externo ou rede de metrô não são mostrados nesses exemplos de design, mas devem ser considerados.
a figura 3-3 fornece um exemplo no qual dois nós principais são usados para fornecer uma solução ECMP de 4 vias.
figura 3-3 ECMP de 4 vias usando dois nós principais
uma vantagem dessa abordagem é que um número menor de switches Principais pode suportar um grande número de servidores. A possível desvantagem é uma alta oversubscription-baixa largura de banda por valor de servidor e grande exposição a uma falha de nó central. Observe que os uplinks são uplinks L3 individuais e não são EtherChannels.
a figura 3-4 demonstra como a adição de dois nós principais ao design anterior pode aumentar drasticamente a escala máxima, mantendo os mesmos valores de oversubscription e largura de banda por servidor.
a figura 3-4 ECMP de 4 vias usando quatro nós principais
a figura 3-5 mostra um design ECMP de 8 vias usando dois nós principais.
figura 3-5 ECMP de 8 vias usando dois nós principais
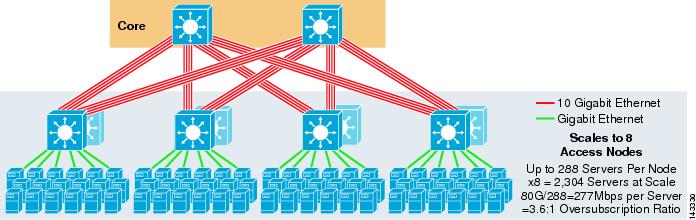
como esperado, a largura de banda de uplink adicional aumenta drasticamente a largura de banda por servidor e reduz a taxa de inscrição excessiva por servidor. Observe como os slots adicionais tomados em cada switch de camada de Acesso para suportar os uplinks de 8 vias reduzem a escala máxima à medida que o número de servidores por switch é reduzido para 288. Observe que os uplinks são uplinks L3 individuais e não são EtherChannels.
a figura 3-6 mostra um design ECMP de 8 vias com oito nós principais.
figura 3-6 ECMP de 8 vias usando oito nós principais
isso demonstra como adicionar quatro nós principais ao mesmo design anterior pode aumentar drasticamente a escala máxima, mantendo a mesma inscrição excessiva e largura de banda por valores de servidor.
design ECMP de 2 vias com acesso 1RU
em muitos ambientes de cluster, a troca de servidor baseada em rack usando pequenos switches na parte superior de cada rack de servidor é desejada ou necessária por causa de cabeamento, questões administrativas, imobiliárias ou para atender a objetivos específicos do modelo de implantação.
a figura 3-7 mostra um exemplo no qual dois nós principais são usados para fornecer uma solução ECMP de 2 vias com switches de acesso 1RU 4948-10GE.
Figura 3-7 2-Forma ECMP usando Dois núcleos de Nós e 1RU Acesso
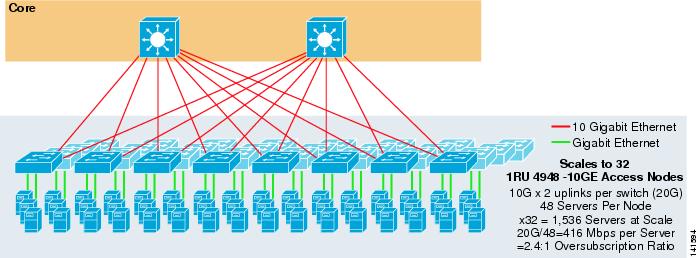
A escala máxima é limitada a 1536 servidores, mas fornece mais de 400 Mbps de largura de banda com uma baixa proporção de excesso de propostas. Como o 4948 tem apenas dois uplinks 10GigE, esse design não pode escalar além desses valores.
Nota ![]() mais informações sobre a troca de servidor baseada em rack são fornecidas no Capítulo 3 “projetos de Cluster de servidor com Ethernet.”
mais informações sobre a troca de servidor baseada em rack são fornecidas no Capítulo 3 “projetos de Cluster de servidor com Ethernet.”
Server Cluster Design – modelo de três camadas
embora um modelo de duas camadas seja mais comum em grandes designs de cluster, um modelo de três camadas também pode ser usado. O modelo de três camadas é normalmente usado para suportar grandes implementações de cluster de servidor usando switches de camada de acesso 1RU ou modular.
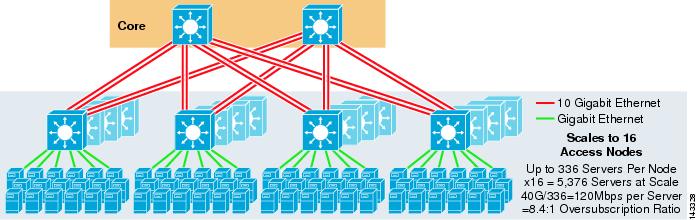
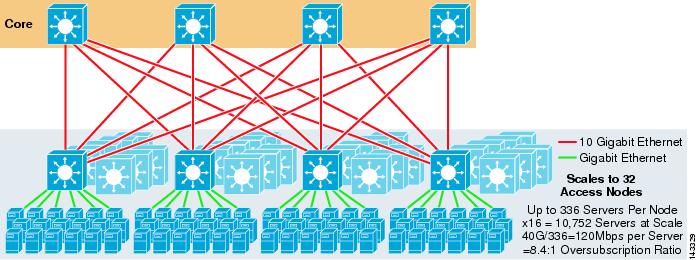
a figura 3-8 mostra um exemplo em grande escala aproveitando o ECMP de 8 vias com switches de núcleo e agregação 6500 e switches de camada de acesso 1RU 4948-10GE.
Figura 3-8 Modelo de Três Camadas com 8 Vias ECMP
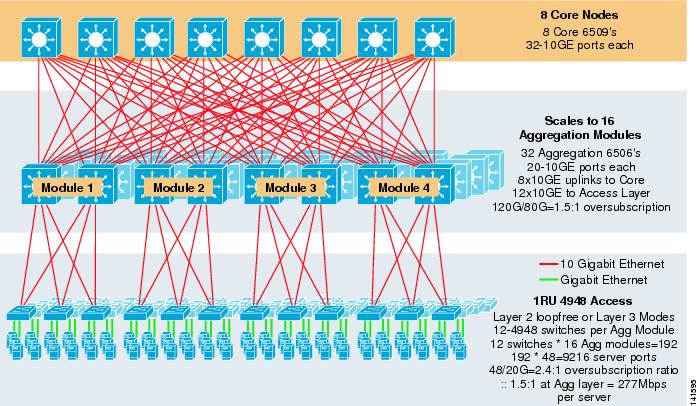
A escala máxima é de mais de 9200 servidores com 277 Mbps de largura de banda com uma baixa proporção de excesso de propostas. Os benefícios da abordagem de três níveis usando switches de acesso 1RU incluem o seguinte:
•![]() 1RU deployment models – como mencionado anteriormente, muitas implantações de modelos de cluster grandes exigem uma abordagem 1RU para instalação simplificada. Por exemplo, um ASP lança racks de servidores de cada vez à medida que escalam aplicativos de cluster de grande porte. O rack do servidor é pré-montado e encenado fora do local, de modo que pode ser instalado e adicionado rapidamente ao cluster em execução. Isso geralmente envolve um terceiro que constrói os racks, pré-configura os servidores e Pré-os cabos com energia e Ethernet para um switch 1RU. O rack rola para o data center e é simplesmente conectado e adicionado ao cluster após conectar os uplinks.
1RU deployment models – como mencionado anteriormente, muitas implantações de modelos de cluster grandes exigem uma abordagem 1RU para instalação simplificada. Por exemplo, um ASP lança racks de servidores de cada vez à medida que escalam aplicativos de cluster de grande porte. O rack do servidor é pré-montado e encenado fora do local, de modo que pode ser instalado e adicionado rapidamente ao cluster em execução. Isso geralmente envolve um terceiro que constrói os racks, pré-configura os servidores e Pré-os cabos com energia e Ethernet para um switch 1RU. O rack rola para o data center e é simplesmente conectado e adicionado ao cluster após conectar os uplinks.
sem uma camada de agregação, o tamanho máximo do modelo de acesso 1RU é limitado a pouco mais de 1500 servidores. Adicionar uma camada de agregação permite que o modelo de acesso 1RU seja dimensionado para um tamanho muito maior, enquanto ainda aproveita o modelo ECMP.
•![]() centralização de switches de núcleo e agregação—com switches 1RU implantados nos racks, é possível centralizar os switches modulares de núcleo e agregação maiores. Isso pode simplificar a infraestrutura De Energia e cabeamento e melhorar o uso de imóveis em rack.
centralização de switches de núcleo e agregação—com switches 1RU implantados nos racks, é possível centralizar os switches modulares de núcleo e agregação maiores. Isso pode simplificar a infraestrutura De Energia e cabeamento e melhorar o uso de imóveis em rack.
•![]() permite a topologia sem loop da camada 2 – uma grande rede de cluster usando o acesso ECMP da camada 3 pode usar muito espaço de endereço nos uplinks e pode adicionar complexidade ao design. Isso é particularmente importante se o espaço de endereço público for usado. A abordagem de modelo de três camadas se presta bem a uma topologia de acesso sem loop da camada 2 que reduz o número de sub-redes necessárias.
permite a topologia sem loop da camada 2 – uma grande rede de cluster usando o acesso ECMP da camada 3 pode usar muito espaço de endereço nos uplinks e pode adicionar complexidade ao design. Isso é particularmente importante se o espaço de endereço público for usado. A abordagem de modelo de três camadas se presta bem a uma topologia de acesso sem loop da camada 2 que reduz o número de sub-redes necessárias.
quando um modelo sem loop de Camada 2 é usado, é importante usar um protocolo de gateway padrão redundante, como HSRP ou GLBP, para eliminar um único ponto de falha se um nó de agregação falhar. Neste projeto, os módulos de agregação não estão interconectados, permitindo um design de camada 2 sem loop que pode aproveitar o GLBP para balanceamento de carga de gateway padrão do servidor automático. O GLBP distribui automaticamente a atribuição de gateway padrão dos servidores entre os dois nós no módulo de agregação. Depois que um pacote chega à camada de agregação, ele é balanceado em todo o núcleo usando o tecido ECMP de 8 vias. Embora o GLBP não forneça um hash de distribuição de carga da camada 3/Camada 4 semelhante ao CEF, é uma alternativa que pode ser usada com uma topologia de acesso da camada 2.
Cálculo de excesso de demanda
O modelo de três camadas apresenta dois pontos de excesso de demanda no acesso e agregação de camadas, em comparação com o modelo de duas camadas, que tem apenas um único ponto de excesso de demanda na camada de acesso. Para calcular corretamente a largura de banda aproximada por servidor e a taxa de inscrição excessiva, execute as duas etapas a seguir, que usam a figura 3-8 como exemplo:
Etapa 1 ![]() Calcule a taxa de inscrição excessiva e a largura de banda por servidor para as camadas de agregação e acesso de forma independente.
Calcule a taxa de inscrição excessiva e a largura de banda por servidor para as camadas de agregação e acesso de forma independente.
•![]() camada de Acesso
camada de Acesso
–![]() excesso de demanda—48GE servidores ligados/20G uplinks para agregação = 2.4:1
excesso de demanda—48GE servidores ligados/20G uplinks para agregação = 2.4:1
–![]() largura de Banda por servidor—20G uplinks para agregação/48GigE servidores ligados = 416Mbps
largura de Banda por servidor—20G uplinks para agregação/48GigE servidores ligados = 416Mbps
•![]() camada de Agregação
camada de Agregação
–![]() excesso de demanda—120G receptores localizados para acesso/80G de uplinks para o core = 1.5:1
excesso de demanda—120G receptores localizados para acesso/80G de uplinks para o core = 1.5:1
Passo 2 ![]() Calcular o combinado proporção de excesso de propostas e de largura de banda por servidor.
Calcular o combinado proporção de excesso de propostas e de largura de banda por servidor.
a taxa de inscrição excessiva real é a soma dos dois pontos de inscrição excessiva nas camadas de acesso e agregação.
1.5*2.4 = 3.6:1
Para determinar a largura de banda de servidor por valor, use a fórmula algébrica para proporções:
a:b = c:d
largura de banda por servidor na camada de acesso foi determinado para ser 416 Mbps por servidor. Como a taxa de inscrição excessiva da camada de agregação é de 1,5:1, você pode aplicar a fórmula acima da seguinte maneira:
416:1 = x: 1.5
x=~264 Mbps por servidor
> Recomendado de Hardware e Módulos
As plataformas recomendadas para o modelo de cluster de servidor de projeto consistem Cisco Catalyst 6500 família com o Sup720 módulo do processador e o Catalyst 4948-10GE switch 1RU. A taxa de comutação alta, a grande tela do interruptor, a baixa latência, a transmissão distribuída, e a densidade 10GigE fazem o ideal do interruptor da série do catalizador 6500 para todas as camadas deste modelo. O Fator de formulário 1RU combinado com a transmissão da taxa do fio, os uplinks 10GE, e a latência constante muito baixa fazem ao 4948-10GE uma parte superior excelente da solução da cremalheira para a camada do acesso.
os seguintes são recomendados:
•![]() Sup720-o Sup720 pode consistir em ambos PFC3A (padrão) ou o mais recente PFC3B tipo filha cartões.
Sup720-o Sup720 pode consistir em ambos PFC3A (padrão) ou o mais recente PFC3B tipo filha cartões.
•![]() cartões de linha-todas as placas de linha devem ser 6700 Séries e devem Todas ser permitidas para a transmissão distribuída com os cartões da filha de DFC3A ou de DFC3B.
cartões de linha-todas as placas de linha devem ser 6700 Séries e devem Todas ser permitidas para a transmissão distribuída com os cartões da filha de DFC3A ou de DFC3B.
Nota ![]() ao usar todos os módulos da série CEF720 acoplados a tecido, o modo de comutação global é compacto, o que permite que o sistema opere em seu mais alto nível de desempenho. O Catalyst 6509 pode suportar 10 módulos GigE em todas as posições porque cada slot suporta canais duplos para o switch fabric (o Cisco Catalyst 6513 não suporta isso).
ao usar todos os módulos da série CEF720 acoplados a tecido, o modo de comutação global é compacto, o que permite que o sistema opere em seu mais alto nível de desempenho. O Catalyst 6509 pode suportar 10 módulos GigE em todas as posições porque cada slot suporta canais duplos para o switch fabric (o Cisco Catalyst 6513 não suporta isso).
•![]() Cisco Catalyst 4948-10GE—o 4948-10GE fornece uma solução de camada de acesso de alto desempenho que pode alavancar uplinks ECMP e 10GigE. Não são necessários requisitos especiais. O 4948-10GE pode usar uma imagem do Cisco IOS Da Camada 2 ou uma imagem do Cisco IOS Da camada 2/3, permitindo um ajuste ótimo em um ou outro ambiente.
Cisco Catalyst 4948-10GE—o 4948-10GE fornece uma solução de camada de acesso de alto desempenho que pode alavancar uplinks ECMP e 10GigE. Não são necessários requisitos especiais. O 4948-10GE pode usar uma imagem do Cisco IOS Da Camada 2 ou uma imagem do Cisco IOS Da camada 2/3, permitindo um ajuste ótimo em um ou outro ambiente.