




SQLShack
w tym artykule pokażemy, jak utworzyć dokument typu danych XML z tabeli relacyjnej przy użyciu różnych sposobów T-SQL. Na przykład w przypadku migracji danych informacje z bazy danych SQL Server mogą być eksportowane i importowane przy użyciu XML w innym frameworku. XML jest standardowym sposobem wyodrębniania, przechowywania i manipulowania danymi. Jednym z aspektów pracy z typem danych XML jest wytworzenie XML z informacji relacyjnych, co odbywa się za pomocą przepisu FOR XML w SQL serwerze:

typ danych XML może być wykorzystywany w alternatywny sposób w SQL Server. Ten artykuł wyjaśni kilka podstawowych zastosowań XML. Słowo kluczowe dla XML to przepis, który można dodać za pomocą instrukcji SELECT query, aby przygotować dokument XML w wymaganych formularzach w wyniku zapytania. Rezultatem jest ciąg znaków Unicode zawierający komponenty i właściwości kontrolowane przez różne tryby określone w przepisie z FOR XML.
cztery tryby to:
- RAW
- AUTO
- EXPLICIT
- ścieżka
poniższa tabela przedstawia przykładowe dane do dalszego wyjaśnienia różnych metod:
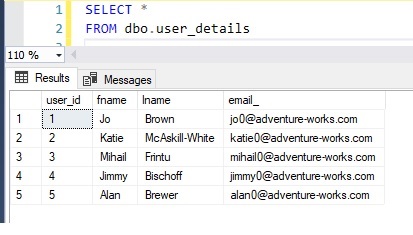
tryb automatyczny
tryb automatyczny jest jednym z podejść do konwersji elementów XML z wierszy tabeli. Nazwy elementów dokumentu XML odpowiadające aliasowi kolumny lub nazwie kolumny zapytania SELECT.
na przykład wynik zapytania został wygenerowany za pomocą jednego dokumentu XML dla powyższych przykładowych danych. Wynik zapytania miał 5 wierszy w zestawie wyników, który jest zmieniany na pojedynczy zestaw wyników komórki. Metodologia ta jest wykorzystywana w funkcji jednowartościowej do zwracania wielu wierszy w pojedynczej zmiennej zwrotnej.
|
1
2
3
|
SELECT user_id, fname, lname, email_
FROM user_details
FOR XML AUTO;
|
tutaj automatycznie tworzy nazwy nagłówków z wykorzystaniem nazw tabel.
tryb jawny
aby uzyskać większą kontrolę nad stylizacją kolejnego XML, Programiści SQL mogą używać trybu jawnego. W trybie jawnym wynik zapytania zostanie zmieniony na pojedynczy dokument typu danych XML z niestandardowymi etykietami i wartościami XML. Tryb jawny spowoduje ustawienie innej etykiety dla każdego wiersza w rekordzie. Tryb jawny umożliwia również zaprojektowanie formatu XML tak, jak użytkownik chce ustawić pozycję elementów w formacie typu danych XML w zapytaniu SQL.
Poniżej znajduje się przykład użycia trybu jawnego:
zapytanie SQL:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
wybierz 1 jako tag,
NULL jako rodzic,
user_id jako ,
NULL jako ,
NULL jako,
NULL jako
FROM user_details
UNION ALL
SELECT 3 as tag,
1 as parent,
user_id as ,
fname AS ,
lname AS ,
email_ AS
from user_details
UNION ALL
select 2 as tag,
1 as parent,
user_id as ,
fname as ,
lname as ,
email_ as
from user_details
order by 3, 1
for XML explicit;
|
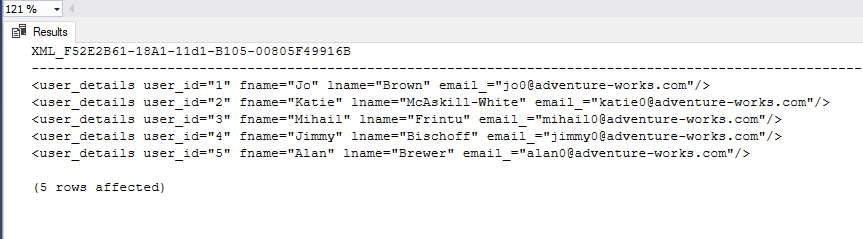
jawny wynik trybu:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
<użytkownik>
<fname fname= „Jo” />
<lname lname= „brązowy” />
</użytkownik>
<użytkownik>
<fname fname= „Katie” />
< lname lname = „McAskill-White” />
</użytkownik>
<użytkownik>
<fname fname= „Mihail” />
<lname lname= „Frintu” />
</użytkownik>
<użytkownik>
<fname fname= „Jimmy” />
<lname lname= „Bischoff” />
</użytkownik>
<użytkownik>
<fname fname= „Alan” />
<lname lname= „Brewer” />
</użytkownik>
|
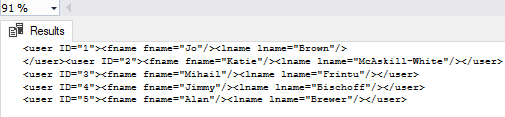
tryb RAW
najpopularniejszym i najczęściej używanym trybem przez programistów do tworzenia XML w FOR XML jest tryb RAW. Zasadniczo tryb RAW wyświetla element o nazwie ” row ” z wyniku ustawionego dla każdego wiersza w artykulacji SELECT, a wartość komórki wiersza zostanie ograniczona jako atrybut elementu. W trybie RAW każda kolumna będzie traktowana jako jeden element w XML, a kolumny tych linii będą przypisane do tego samego elementu. Tryb RAW służy do zmiany każdego wiersza w wyniku ustawionym na komponent XML.
dla trybu wiersza, różne modele zapytań z różnymi wyjściami wyjaśnione w poniższych przykładach:
przykład 1
|
1
2
3
4
5
6
7
8
9
|
SELECT user_id, fname, lname, email_
FROM user_details
FOR XML RAW
< row user_id=”1″ fname=”Jo” lname=”Brown” email_=”[email protected]” />
<row user_id= ” 2 „fname =” Katie „lname =” McAskill-White”email_= „[email protected]” />
< row user_id= ” 3 „fname =” Mihail „lname = „Frintu”email_= „[email protected]” />
< row user_id= ” 4 „fname =” Jimmy „lname = „Bischoff”email_= „[email protected]” />
< row user_id= ” 5 „fname =” Alan „lname =” Brewer „email_ =” [email protected]” />
|
w trybie RAW nagłówek każdego elementu jest definiowany jako element wiersza w wyniku XML, a kolumny każdego wiersza są przypisywane wewnątrz elementu wiersza w wyniku typu danych XML.
przykład 2
|
1
2
3
4
5
6
7
8
9
10
11
|
wybierz user_id, fname, lname, email_
z user_details
dla XML RAW (’użytkownik’), ROOT
< root>
<user user_id=”1″ fname=”Jo” lname = „Brown” email_ = ” [email protected]” />
<user user_id= ” 2 „fname =” Katie „lname =” McAskill-White”email_= „[email protected]” />
< user user_id= ” 3 „fname =” Mihail „lname = „Frintu”email_= „[email protected]” />
< user user_id= ” 4 „fname =” Jimmy „lname = „Bischoff”email_= „[email protected]” />
< user user_id= ” 5 „fname=” Alan „lname =” Brewer „email_ =” [email protected]” />
</korzeń>
|
jeśli użytkownik chce uwzględnić wszystkie elementy w jednym znaczniku, wtedy można użyć opcji ROOT z trybem RAW i nazwa nagłówka każdego elementu może być zdefiniowana przez użytkownika poprzez dodanie nazwy z RAW () w wyniku typu danych XML.
przykład 3
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT user_id, fname, lname, email_
FROM user_details
FOR XML RAW(’user’), ROOT (’UserDetails’)
<UserDetails>
<user user_id=”1″ fname=”Jo” lname = „Brown” email_ = ” [email protected]” />
<user user_id= ” 2 „fname =” Katie „lname =” McAskill-White”email_= „[email protected]” />
< user user_id= ” 3 „fname =” Mihail „lname = „Frintu”email_= „[email protected]” />
< user user_id= ” 4 „fname =” Jimmy „lname = „Bischoff”email_= „[email protected]” />
< user user_id= ” 5 „fname=” Alan „lname =” Brewer „email_ =” [email protected]” />
</UserDetails>
|
w surowym korzeniu XML nagłówek może być zaprojektowany z nazwą zdefiniowaną przez Użytkownika za pomocą ROOT (). Jak widać w przykładzie, element <root> jest zastępowany przez<UserDetails>
przykład 4
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
SELECT user_id, fname, lname, email_
FROM user_details
FOR XML RAW, ELEMENTS
<row>
<user_id> 1 < / user_id>
<fname> Jo < / fname>
<lname> Brown < / lname>
<email_>[email protected]< / email_>
</wiersz>
<wiersz>
<user_id>2< /user_id>
<fname>Katie< / fname>
<lname> McAskill-White< / lname>
<email_> [email protected]< / email_>
</wiersz>
|
używając dyrektywy ELEMENT z trybem RAW, użytkownik może tworzyć XML oparty na strukturze wiersza. Każda komórka wiersza jest wyodrębniana z elementami XML wewnątrz elementu nadrzędnego wiersza jako<wiersz >. Zasadniczo użyliśmy słowa kluczowego ELEMENTS w powyższym zapytaniu, aby wyświetlić kolumny jako elementy w wyjściowym XML.
tryb ścieżki
najlepszym trybem do tworzenia XML z większą kontrolą nad formatem jest tryb ścieżki. Korzystając ze ścieżki, użytkownik może skomponować prostsze Select i dostarczyć przeguby XPATH dla kolumny, aby przypisać łańcuch poleceń. Użyj ścieżki XML z zapytaniami podrzędnymi, aby uzyskać właściwy dokument typu danych XML z łańcuchem elementu-atrybutu:
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT user_id, fname, lname, email_
FROM user_details
WHERE email_ = „[email protected]”
dla ścieżki XML;
<wiersz>
<user_id> 3</user_id>
<fname>Mihail< / fname>
<lname> Frintu< / lname>
<email_>[email protected]< / email_>
</wiersz>
|
wniosek
używanie wyniku zapytania serwera w celu uzyskania innego formatu XML jest proste. Wynik zapytania zostanie rozpakowany w XML przez dodanie hasła FOR XML na końcu instrukcji SELECT. Jak omówiono, mamy wiele alternatyw do struktury lub uporządkowania wyniku za pomocą kolumn do atrybutów lub węzłów XML z typem danych XML.
- Autor
- Ostatnie posty

Zobacz wszystkie posty, których autorem jest Jignesh Raiyani
- oczekiwana długość życia strony (PLE) w SQL Server-lipiec 17, 2020
- jak zautomatyzować partycjonowanie tabel w SQL Server-lipiec 7, 2020
- Konfigurowanie SQL Server Always On Availability Groups na AWS EC2-lipiec 6, 2020