




SQL Server Optymalizacja zapytań aktualizacyjnych dla dużych wolumenów danych
Aktualizacja bardzo dużych tabel może być zadaniem czasochłonnym, a czasami może zająć wiele godzin. Oprócz tego może również powodować problemy z blokowaniem.
oto kilka wskazówek, jak SQL Server optymalizuje aktualizacje dużych ilości danych.
- usuwanie indeksu w kolumnie, która ma zostać zaktualizowana.
- wykonywanie aktualizacji w mniejszych partiach.
- wyłączanie wyzwalaczy Delete.
- zastąpienie instrukcji aktualizacji operacją wstawiania zbiorczego.
Mając to na uwadze, zastosujmy powyższe punkty, aby zoptymalizować Zapytanie o aktualizację.
poniższy kod tworzy obojętną tabelę z 200 000 wierszy i wymaganymi indeksami.
CREATE TABLE tblverylargetable ( sno INT IDENTITY, col1 CHAR(800), col2 CHAR(800), col3 CHAR(800) ) GO DECLARE @i INT=0 WHILE( @i < 200000 ) BEGIN INSERT INTO tblverylargetable VALUES ('Dummy', Replicate('Dummy', 160), Replicate('Dummy', 160)) SET @i=@i + 1 ENDGOCREATE INDEX ix_col1 ON tblverylargetable(col1) GO CREATE INDEX ix_col2_col3 ON tblverylargetable(col2) INCLUDE(col3)
rozważ następujące zapytanie aktualizacyjne, które ma zostać zoptymalizowane. Jest to bardzo proste zapytanie do aktualizacji pojedynczej kolumny.
UPDATE tblverylargetable SET col1 = 'D'WHERE col1 = 'Dummy'
wykonanie zapytania zajmuje 2:19 minut.
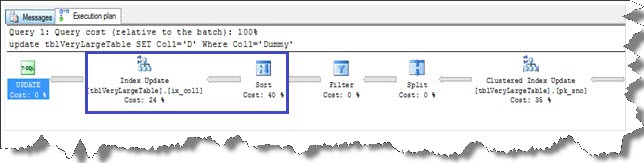
spójrzmy na plan wykonania zapytania pokazany poniżej. Oprócz klastrowej aktualizacji indeksu, indeks ix_col1 jest również aktualizowany. Operacja aktualizacji indeksu i sortowania razem zajmują 64% kosztów wykonania.
1. Usuwanie indeksu w kolumnie, która ma zostać zaktualizowana
to samo zapytanie trwa 14-18 sekund, gdy nie ma żadnego indeksu na col1. W ten sposób zapytanie aktualizacyjne działa szybciej, jeśli kolumna, która ma być zaktualizowana, nie jest kolumną klucza indeksowego. Indeks można zawsze utworzyć po zakończeniu aktualizacji.
2. Wykonywanie aktualizacji w mniejszych partiach
zapytanie można dodatkowo zoptymalizować, wykonując je w mniejszych partiach. Zazwyczaj jest to szybsze. Poniższy kod aktualizuje zapisy w partiach 20000.
DECLARE @i INT=1 WHILE( @i <= 10 ) BEGIN UPDATE TOP(20000) tblverylargetable SET col1 = 'D' WHERE col1 = 'Dummy' SET @i=@i + 1 END
wykonanie powyższego zapytania zajmuje 6-8 sekund. Podczas aktualizacji w partiach, nawet jeśli aktualizacja nie powiedzie się lub musi zostać zatrzymana, tylko wiersze z bieżącej partii są wycofywane.
3. Wyłączenie wyzwalaczy Delete
z kursorami może znacznie spowolnić działanie zapytania delete. Wyłączenie wyzwalaczy po usunięciu znacznie zwiększy wydajność zapytania.
4. Zastąpienie instrukcji aktualizacji operacją wstawiania zbiorczego
Instrukcja aktualizacji jest operacją w pełni zarejestrowaną, a zatem z pewnością zajmie sporo czasu, jeśli miliony wierszy mają zostać zaktualizowane.Najszybszym sposobem na przyspieszenie zapytania aktualizacji jest zastąpienie go operacją wstawiania zbiorczego. Jest to operacja minimalnie rejestrowana w prostym i masowo rejestrowanym modelu odzyskiwania. Można to łatwo zrobić, wykonując wstawianie zbiorcze w nowej tabeli, a następnie zmienić nazwę tabeli na oryginalną. Wymagane indeksy i ograniczenia mogą być tworzone w nowej tabeli zgodnie z wymaganiami.
poniższy kod pokazuje, w jaki sposób można przekonwertować aktualizację na operację wstawiania zbiorczego. Wykonanie zajmuje 4 sekundy.
SELECT sno, CASE col1 WHEN 'Dummy' THEN 'D' ELSE col1 END AS col1, col2, col3 INTO tblverylargetabletemp FROM tblverylargetable
wkład zbiorczy można następnie zoptymalizować, aby uzyskać dodatkowe zwiększenie wydajności.
mam nadzieję, że to pomoże!!!Facebook / Obserwuj nas na Twitterze / Dołącz do najszybciej rozwijającej się grupy SQL Server na Facebooku