




SQL Server-optimalisatie van Updatequery’ s voor grote datavolumes
het bijwerken van zeer grote tabellen kan een tijdrovende taak zijn en soms kan het uren duren om te voltooien. Naast deze, het kan ook leiden tot blokkerende problemen.
hier zijn enkele tips om SQL Server te optimaliseren van de updates op grote data volumes.
- verwijdert de index op de bij te werken kolom.
- de update uitvoeren in kleinere batches.
- Verwijder triggers uitschakelen.
- Update statement vervangen door een Bulk-Insert-bewerking.
laten we de bovenstaande punten toepassen om een update query te optimaliseren.
de onderstaande code maakt een dummy tabel met 200.000 rijen en vereiste indexen.
CREATE TABLE tblverylargetable ( sno INT IDENTITY, col1 CHAR(800), col2 CHAR(800), col3 CHAR(800) ) GO DECLARE @i INT=0 WHILE( @i < 200000 ) BEGIN INSERT INTO tblverylargetable VALUES ('Dummy', Replicate('Dummy', 160), Replicate('Dummy', 160)) SET @i=@i + 1 ENDGOCREATE INDEX ix_col1 ON tblverylargetable(col1) GO CREATE INDEX ix_col2_col3 ON tblverylargetable(col2) INCLUDE(col3)
overweeg de volgende update query die moet worden geoptimaliseerd. Het is een zeer eenvoudige vraag om een enkele kolom bij te werken.
UPDATE tblverylargetable SET col1 = 'D'WHERE col1 = 'Dummy'
de query duurt 2:19 minuten om uit te voeren.
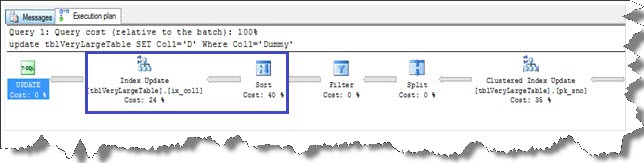
laten we eens kijken naar het uitvoeringsplan van de onderstaande query. Naast de geclusterde indexupdate wordt ook de index ix_col1 bijgewerkt. De index update en sorteer operatie samen nemen 64% van de uitvoeringskosten.
1. Het verwijderen van index op de kolom die moet worden bijgewerkt
dezelfde query duurt 14-18 seconden als er geen index op col1. Dus, een update query draait sneller als de kolom te worden bijgewerkt is niet een index sleutel kolom. De index kan altijd worden gemaakt zodra de update is voltooid.
2. Het uitvoeren van de update in kleinere batches
de query kan verder worden geoptimaliseerd door het uitvoeren in kleinere batches. Dit is over het algemeen sneller. De code hieronder werkt de records bij in batches van 20000.
DECLARE @i INT=1 WHILE( @i <= 10 ) BEGIN UPDATE TOP(20000) tblverylargetable SET col1 = 'D' WHERE col1 = 'Dummy' SET @i=@i + 1 END
de bovenstaande query duurt 6-8 seconden om uit te voeren. Bij het bijwerken in batches, zelfs als de update mislukt of moet worden gestopt, worden alleen rijen van de huidige batch teruggerold.
3. Het uitschakelen van Delete triggers
Triggers met cursors kan de prestaties van een delete query extreem vertragen. Uitschakelen na verwijderen triggers zal aanzienlijk verhogen van de query prestaties.
4. Het vervangen van een Update statement door een Bulk-Insert operatie
een update statement is een volledig gelogde operatie en dus zal het zeker veel tijd in beslag nemen als miljoenen rijen moeten worden bijgewerkt.De snelste manier om de update query te versnellen is om het te vervangen door een bulk-insert operatie. Het is een minimaal gelogde werking in eenvoudige en Bulk-gelogde herstelmodel. Dit kan gemakkelijk worden gedaan door het doen van een bulk-invoegen in een nieuwe tabel en vervolgens de naam van de tabel naar de originele. De vereiste indexen en beperking kunnen worden gemaakt op een nieuwe tabel zoals vereist.
onderstaande code laat zien hoe de update kan worden geconverteerd naar een bulk-insert-bewerking. Het duurt 4 seconden om uit te voeren.
SELECT sno, CASE col1 WHEN 'Dummy' THEN 'D' ELSE col1 END AS col1, col2, col3 INTO tblverylargetabletemp FROM tblverylargetable
de bulk-insert kan dan verder worden geoptimaliseerd om extra prestatieverbetering te krijgen.
hoop dat dit helpt!!!
Vind ons leuk op FaceBook / Volg ons op Twitter / Word lid van de snelst groeiende SQL Server-groep op FaceBook