




Crawl Errors: The Next Generation
maandag 12 maart 2012
Crawl errors is een van de meest populaire functies in Webmaster Tools, en vandaag zijn we het uitrollen van een aantal zeer belangrijke verbeteringen die het nog nuttiger zullen maken.
we detecteren en rapporteren nu veel nieuwe soorten fouten. Om de nieuwe gegevens zinvol te maken, hebben we de fouten in twee delen opgesplitst: sitefouten en URL-fouten.
Sitefouten
Sitefouten zijn fouten die niet specifiek zijn voor een bepaalde URL—ze beïnvloeden uw hele site. Deze omvatten DNS-resolutiefouten, verbindingsproblemen met uw webserver en problemen met het ophalen van uw robots.txt-bestand. Vroeger rapporteerden we deze fouten per URL, maar dat was niet erg logisch omdat ze niet specifiek zijn voor individuele URL ‘ s—in feite voorkomen ze dat Googlebot zelfs een URL aanvraagt! In plaats daarvan houden we nu de foutpercentages bij voor elk type site-brede fout. We zullen ook proberen om u waarschuwingen te sturen wanneer deze fouten worden frequent genoeg dat ze aandacht verdienen.
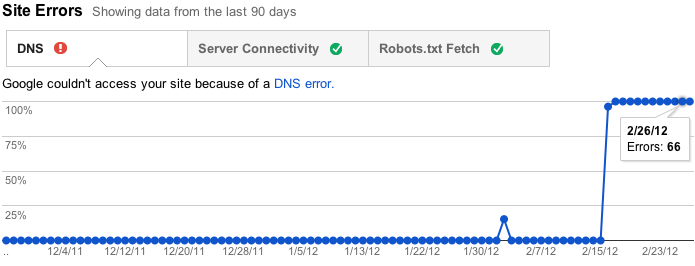
bovendien, als u geen problemen heeft (en onlangs nog niet hebt gehad) op deze gebieden, zoals het geval is voor veel sites, zullen we u niet lastig vallen met deze sectie. In plaats daarvan laten we je wat vriendelijke vinkjes zien om je te laten weten dat alles goed is.

URL fouten
URL fouten zijn fouten die specifiek zijn voor een bepaalde pagina. Dit betekent dat wanneer Googlebot probeerde de URL te crawlen, het in staat was om je DNS op te lossen, verbinding te maken met je server, je robots te halen en te lezen.txt-bestand, en vraag dan deze URL, maar er ging iets mis na dat. We splitsen de URL fouten in verschillende categorieën op basis van wat de fout veroorzaakt. Als uw site Google News-of mobiele (HTML/XHTML) – gegevens serveert, tonen we afzonderlijke categorieën voor deze fouten.

minder is meer
we hebben gebruikt om u maximaal 100.000 fouten van elk type te tonen. Proberen om al deze informatie te consumeren was als het drinken van een brandslang, en je had geen manier om te weten welke van die fouten waren belangrijk (uw homepage is naar beneden) of minder belangrijk (iemands persoonlijke site maakte een typefout in een link naar uw site). Er was geen realistische manier om alle 100.000 fouten te bekijken—geen manier om uw voortgang te sorteren, te zoeken of te markeren. In de nieuwe versie van deze functie, we hebben gericht op het proberen om u alleen de belangrijkste fouten vooraf. Voor elke categorie geven we je wat we denken dat de 1000 belangrijkste en uitvoerbare fouten zijn. U kunt sorteren en filteren deze top 1000 fouten, laat het ons weten als je denkt dat je ze hebt opgelost, en bekijk details over hen.
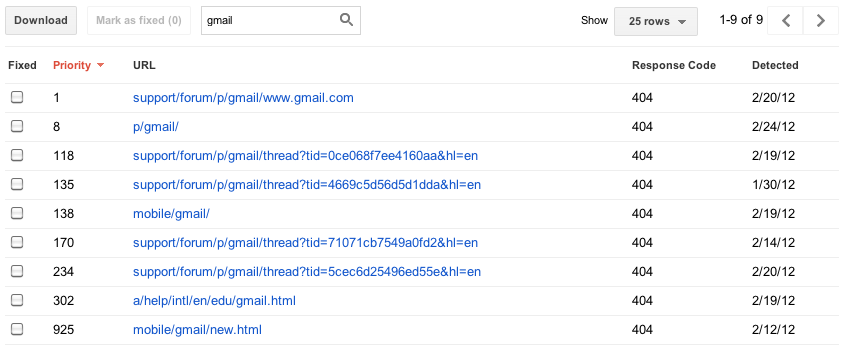
sommige sites hebben meer dan 1000 fouten van een bepaald type, dus u kunt nog steeds het totale aantal fouten van elk type zien, evenals een grafiek met historische gegevens die 90 dagen terug gaan. Voor degenen die zich zorgen maken dat 1000 foutdetails plus een totaal totaalaantal niet genoeg zal zijn, overwegen we het toevoegen van programmatic access (een API) zodat u elke laatste fout die u hebt kunt downloaden, dus geef ons feedback als u meer nodig hebt.
we hebben ook de lijst verwijderd van pagina ‘ s die geblokkeerd zijn door robots.txt, want hoewel deze soms nuttig kunnen zijn voor het diagnosticeren van een probleem met uw robots.txt-bestand, Ze zijn vaak pagina ‘ s die u opzettelijk geblokkeerd. We wilden ons echt richten op fouten, dus zoek naar informatie over geroboteerde URL ‘ s om snel te verschijnen in de functie “Crawler access” onder “Site configuration”.
duik in de details
Als u op een individuele fout-URL uit de hoofdlijst klikt, verschijnt er een detailvenster met aanvullende informatie, inclusief wanneer we de URL voor het laatst probeerden te crawlen, wanneer we voor het eerst een probleem merkten, en een korte uitleg van de fout.

in het detailvenster kunt u klikken op de link voor de URL die de fout veroorzaakte om zelf te zien wat er gebeurt wanneer u probeert om het te bezoeken. U kunt de fout ook markeren als “vast” (meer daarover later!), bekijk help-inhoud voor het type fout, lijst Sitemaps die de URL bevatten, zie andere pagina ‘ s die verwijzen naar deze URL, en zelfs Googlebot halen de URL nu, hetzij voor meer informatie of om te controleren of uw oplossing werkte.

Onderneem actie!
een ding waar we erg enthousiast over zijn in deze nieuwe versie van de Crawl errors functie is dat je je echt kunt concentreren op het oplossen van wat eerst het belangrijkste is. We hebben de fouten gerangschikt, zodat die bovenaan de prioriteitenlijst degenen zijn waar er iets is wat je kunt doen, of dat nu de vaststelling van gebroken links op uw eigen site, de vaststelling van bugs in uw server software, het bijwerken van uw sitemaps om dode URL ‘ s snoeien, of het toevoegen van een 301 redirect om gebruikers naar de “echte” pagina. We bepalen dit op basis van een veelheid aan factoren, waaronder het al dan niet opnemen van de URL in een Sitemap, hoeveel plaatsen Het is gekoppeld vanaf (en als een van deze zijn ook op uw site), en of de URL heeft gekregen enig verkeer onlangs van search.
zodra u denkt dat u het probleem hebt opgelost (u kunt uw oplossing testen door de URL op te halen als Googlebot), kunt u ons dit laten weten door de fout als “opgelost” te markeren als u een gebruiker bent met volledige toegangsrechten. Dit zal de fout uit uw lijst verwijderen. In de toekomst zullen de fouten die je hebt gemarkeerd als opgelost niet worden opgenomen in de lijst met topfouten, tenzij we dezelfde fout hebben ondervonden bij het opnieuw crawlen van een URL.
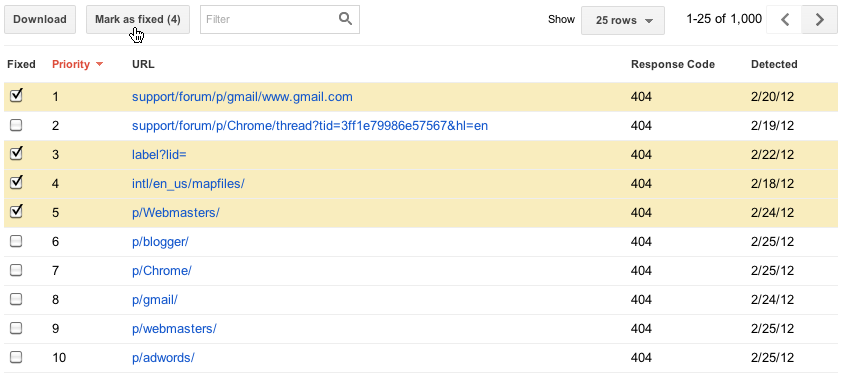
we hebben veel werk gestoken in de nieuwe Crawl errors functie, dus we hopen dat het zeer nuttig voor u zal zijn. Laat ons weten wat je denkt en als je suggesties hebt, bezoek dan ons forum!
geschreven door Kurt Dresner, Webmaster Tools team