




SQL Serverの大規模なデータボリュームの更新クエリの最適化
非常に大きなテーブルの更新には時間がかか これに加えて、ブロックの問題も発生する可能性があります。
ここでは、SQL Serverが大規模なデータボリュームで更新を最適化するためのヒントをいくつか紹介します。
- 更新する列のインデックスを削除します。
- 小さなバッチで更新を実行します。
- 削除トリガーを無効にします。
- Updateステートメントを一括挿入操作に置き換えます。
そうは言っても、上記の点を適用して更新クエリを最適化しましょう。
以下のコードは、200,000行と必要なインデックスを持つダミーテーブルを作成します。
CREATE TABLE tblverylargetable ( sno INT IDENTITY, col1 CHAR(800), col2 CHAR(800), col3 CHAR(800) ) GO DECLARE @i INT=0 WHILE( @i < 200000 ) BEGIN INSERT INTO tblverylargetable VALUES ('Dummy', Replicate('Dummy', 160), Replicate('Dummy', 160)) SET @i=@i + 1 ENDGOCREATE INDEX ix_col1 ON tblverylargetable(col1) GO CREATE INDEX ix_col2_col3 ON tblverylargetable(col2) INCLUDE(col3)
最適化される次の更新クエリを考えてみましょう。 単一の列を更新するのは非常に簡単なクエリです。
UPDATE tblverylargetable SET col1 = 'D'WHERE col1 = 'Dummy'
クエリの実行には2:19分かかります。
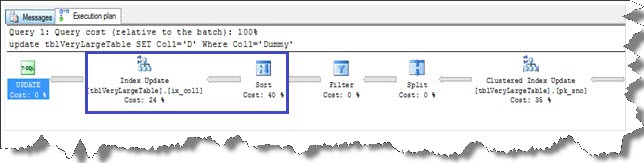
以下に示すクエリの実行計画を見てみましょう。 クラスタ化インデックスの更新に加えて、インデックスix_col1も更新されます。 インデックスの更新操作と並べ替え操作は、実行コストの64%を要します。
1. 更新する列のインデックスの削除
col1にインデックスがない場合、同じクエリには14-18秒かかります。 したがって、更新する列がインデックスキー列でない場合、更新クエリはより高速に実行されます。 更新が完了すると、インデックスは常に作成できます。
2. より小さなバッチでの更新の実行
クエリをより小さなバッチで実行することで、クエリをさらに最適化することができます。 これは一般的に高速です。 以下のコードは、20000のバッチでレコードを更新します。
DECLARE @i INT=1 WHILE( @i <= 10 ) BEGIN UPDATE TOP(20000) tblverylargetable SET col1 = 'D' WHERE col1 = 'Dummy' SET @i=@i + 1 END
上記のクエリの実行には6-8秒かかります。 バッチで更新する場合、更新が失敗した場合や停止する必要がある場合でも、現在のバッチの行のみがロールバックされます。
3. カーソルを使用して削除トリガー
トリガーを無効にすると、削除クエリのパフォーマンスが非常に低下する可能性があります。 After deleteトリガーを無効にすると、クエリのパフォーマンスが大幅に向上します。
4. Updateステートメントを一括挿入操作に置き換える
updateステートメントは完全にログに記録された操作であるため、何百万行もの行を更新する場合は、確かにかなりの時間がかかります。更新クエリを高速化する最速の方法は、一括挿入操作に置き換えることです。 これは、単純な一括ログ復旧モデルでの最小限のログ操作です。 これは、新しいテーブルでbulk-insertを実行してから、テーブルの名前を元のテーブルに変更することで簡単に行うことができます。 必要な索引と制約は、必要に応じて新しい表に作成できます。
以下のコードは、更新を一括挿入操作に変換する方法を示しています。 実行には4秒かかります。
SELECT sno, CASE col1 WHEN 'Dummy' THEN 'D' ELSE col1 END AS col1, col2, col3 INTO tblverylargetabletemp FROM tblverylargetable
その後、bulk-insertをさらに最適化してパフォーマンスを向上させることができます。
これが助けてくれることを願っています!!!
FaceBookで私たちのように|Twitterで私たちに従ってください|FaceBookで最も急速に成長しているSQL Serverグループに参加