Amazon MTurk
指示された応答項目(非常に良い)、偽の項目(良い)、および/または応答時間(公正、TIME_RSIの使用を検討してください)に基づいて、データセットをクリー
残りのすべてのレコードから、品質基準に準拠した作業者Idがあります。 もちろん、MTurkのすべての割り当てを手動で確認することもできますが、それには多くの時間がかかります。 CSVファイルでの作業を改善します。
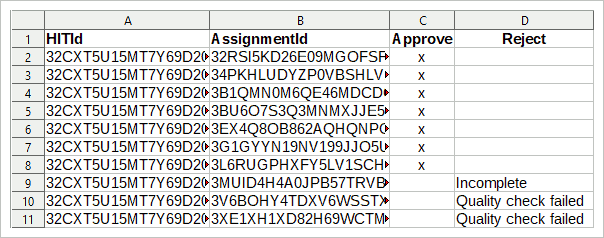
CSVファイルには、ヒットIDと割り当てIDが必要です。 上記のマニュアルに従った場合、これらのデータが利用可能になります。 次に、データから3つの列を持つテーブル(R、SPSS、LibreOffice Calc、Excel、…)を作成します:最初の列にはヒットIDが含まれ、2番目の列には割り当てIDが含まれ、3番目の列にはすべて
テーブルの最初の行はヘッダー、変数名です。 変数名が次のようになっていることを確認してください(大文字と小文字が区別されます):
-
ヒティッド
-
AssignmentId
-
承認
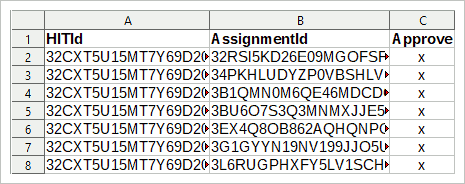
次に、テーブルをCSVファイルとして保存し、MTurk→管理→結果の確認で、Csvのアップロードボタンをクリックします。 新しく保存したCSVを選択して確認します。 MTurkは、これらの割り当てを受け入れるかどうかを尋ねます。
完了すると、品質基準に一致しなかった課題のみが残ります。 理由を説明して、それらを拒否します。
または、データクリーニング中にレコードをすぐに削除しないで、マークしてください。 その後、4つの列、「拒否」という名前の4つの列と、その列に拒否の説明が記載されたCSVファイルをアップロードできます。 これにより、IDが失われた人を拒否しないようにします。