




Cisco Data Center Infrastructure 2.5 Design Guide
Server Cluster Designs with Ethernet
a kiszolgálófürtmodellben használt kiszolgálók és hálózati összetevők magas szintű áttekintése az 1.fejezetben található “adatközpont architektúra áttekintése.”Ez a fejezet részletesebben ismerteti a kiszolgálófürtmodell egyes rétegeinek célját és működését. A következő szakaszok szerepelnek:
•![]() technikai célkitűzések
technikai célkitűzések
•![]() elosztott Továbbítás és késleltetés
elosztott Továbbítás és késleltetés
•![]() egyenlő költségű többutas útválasztás
egyenlő költségű többutas útválasztás
•![]() szerver klaszter tervezés-kétszintű modell
szerver klaszter tervezés-kétszintű modell
•![]() szerver klaszter tervezés-háromszintű modell
szerver klaszter tervezés-háromszintű modell
•![]() ajánlott hardverek és modulok
ajánlott hardverek és modulok

Megjegyzés ![]() az ebben a fejezetben tárgyalt tervezési modelleket a szükséges tesztelés mérete és terjedelme miatt nem ellenőrizték teljes mértékben a Cisco laboratóriumi tesztelése során. A lefedett kétszintű modellek hasonló tervek, amelyeket az ügyfélgyártási hálózatokban valósítottak meg.
az ebben a fejezetben tárgyalt tervezési modelleket a szükséges tesztelés mérete és terjedelme miatt nem ellenőrizték teljes mértékben a Cisco laboratóriumi tesztelése során. A lefedett kétszintű modellek hasonló tervek, amelyeket az ügyfélgyártási hálózatokban valósítottak meg.
műszaki célok
nagyvállalati klaszterhálózat tervezésekor kritikus fontosságú figyelembe venni a konkrét célokat. Nincs két pontosan egyforma klaszter; mindegyiknek megvannak a maga sajátos követelményei, amelyeket alkalmazási szempontból meg kell vizsgálni az adott tervezési követelmények meghatározásához. Vegye figyelembe a következő műszaki megfontolásokat:
•![]() késleltetés-a hálózati átvitel során a késleltetés hátrányosan befolyásolhatja a fürt teljes teljesítményét. Az alacsony késleltetésű kapcsolási architektúrát alkalmazó kapcsolási platformok használata segít az optimális teljesítmény biztosításában. A késleltetés fő forrása a kiszolgálón használt protokoll stack és NIC hardver implementáció. Az illesztőprogram-optimalizálási és CPU-tehermentesítési technikák, mint például a TCP-tehermentesítő Motor (TOE) és a távoli közvetlen memória-hozzáférés (RDMA), csökkenthetik a késleltetést és csökkenthetik a kiszolgálón a feldolgozási költségeket.
késleltetés-a hálózati átvitel során a késleltetés hátrányosan befolyásolhatja a fürt teljes teljesítményét. Az alacsony késleltetésű kapcsolási architektúrát alkalmazó kapcsolási platformok használata segít az optimális teljesítmény biztosításában. A késleltetés fő forrása a kiszolgálón használt protokoll stack és NIC hardver implementáció. Az illesztőprogram-optimalizálási és CPU-tehermentesítési technikák, mint például a TCP-tehermentesítő Motor (TOE) és a távoli közvetlen memória-hozzáférés (RDMA), csökkenthetik a késleltetést és csökkenthetik a kiszolgálón a feldolgozási költségeket.
a késleltetés nem mindig kritikus tényező a klaszter kialakításában. Például egyes klaszterek nagy sávszélességet igényelhetnek a kiszolgálók között a nagy mennyiségű tömeges fájlátvitel miatt, de előfordulhat, hogy nem támaszkodnak erősen a kiszolgálók közötti folyamatok közötti kommunikációra (IPC), amelyre hatással lehet a magas késleltetés.
•![]() háló / részleges háló kapcsolat-a kiszolgálófürt-tervek általában hálót vagy részleges hálószövetet igényelnek, hogy lehetővé tegyék a kommunikációt a fürt összes csomópontja között. Ez a hálószövet az állapot, adatok és egyéb információk megosztására szolgál a fürtben lévő master-to-compute és compute-to-compute kiszolgálók között. A hálós vagy részleges hálós kapcsolat szintén alkalmazásfüggő.
háló / részleges háló kapcsolat-a kiszolgálófürt-tervek általában hálót vagy részleges hálószövetet igényelnek, hogy lehetővé tegyék a kommunikációt a fürt összes csomópontja között. Ez a hálószövet az állapot, adatok és egyéb információk megosztására szolgál a fürtben lévő master-to-compute és compute-to-compute kiszolgálók között. A hálós vagy részleges hálós kapcsolat szintén alkalmazásfüggő.
•![]() nagy áteresztőképesség—az a képesség, hogy egy nagy fájlt egy adott idő alatt küldjön, kritikus lehet A klaszter működése és teljesítménye szempontjából. A kiszolgálófürtök általában minimális mennyiségű rendelkezésre álló nem blokkoló sávszélességet igényelnek, ami az access és a core rétegek közötti alacsony túlfizetési modellt eredményez.
nagy áteresztőképesség—az a képesség, hogy egy nagy fájlt egy adott idő alatt küldjön, kritikus lehet A klaszter működése és teljesítménye szempontjából. A kiszolgálófürtök általában minimális mennyiségű rendelkezésre álló nem blokkoló sávszélességet igényelnek, ami az access és a core rétegek közötti alacsony túlfizetési modellt eredményez.
•![]() Oversubscription ratio-a oversubscription ratio-t a tervezés több aggregációs pontján kell megvizsgálni, beleértve a vonalkártyát a szövet sávszélességének átkapcsolására, a szövet bemenetét pedig a felfelé irányuló sávszélességre.
Oversubscription ratio-a oversubscription ratio-t a tervezés több aggregációs pontján kell megvizsgálni, beleértve a vonalkártyát a szövet sávszélességének átkapcsolására, a szövet bemenetét pedig a felfelé irányuló sávszélességre.
•![]() Jumbo keret támogatás-bár a Jumbo keretek nem használhatók a kiszolgálófürt kezdeti megvalósításában, ez egy nagyon fontos jellemző, amely a további rugalmassághoz vagy a lehetséges jövőbeli követelményekhez szükséges. A TCP / IP csomag felépítése további költségeket helyez el a szerver CPU-ján. A jumbo keretek használata csökkentheti a csomagok számát, ezáltal csökkentve ezt a rezsit.
Jumbo keret támogatás-bár a Jumbo keretek nem használhatók a kiszolgálófürt kezdeti megvalósításában, ez egy nagyon fontos jellemző, amely a további rugalmassághoz vagy a lehetséges jövőbeli követelményekhez szükséges. A TCP / IP csomag felépítése további költségeket helyez el a szerver CPU-ján. A jumbo keretek használata csökkentheti a csomagok számát, ezáltal csökkentve ezt a rezsit.
•![]() portsűrűség-előfordulhat, hogy a Kiszolgálófürtöknek több tízezer portra kell méretezniük. Mint ilyenek, magas szintű csomagkapcsolási teljesítményű platformokra, nagy mennyiségű kapcsolószövet sávszélességre és nagy portsűrűségre van szükségük.
portsűrűség-előfordulhat, hogy a Kiszolgálófürtöknek több tízezer portra kell méretezniük. Mint ilyenek, magas szintű csomagkapcsolási teljesítményű platformokra, nagy mennyiségű kapcsolószövet sávszélességre és nagy portsűrűségre van szükségük.
elosztott Továbbítás és késleltetés
a Cisco Catalyst 6500 sorozatú kapcsoló egyedülálló képességgel rendelkezik a központi csomag továbbítás vagy az opcionális elosztott továbbítási architektúra támogatására, míg a Cisco Catalyst 4948-10GE egyetlen központi ASIC kialakítás, Vezetékes sebességű továbbítási teljesítménnyel. A Cisco 6700 vonali kártyamodulok támogatják az opcionális leánykártya-modult, az úgynevezett elosztott továbbítási kártyát (DFC). A DFC lehetővé teszi a helyi útválasztási döntések meghozatalát az egyes vonali kártyákon egy helyi továbbítási információs bázis (FIB) megvalósításával. A Sup720 PFC FIB táblája fenntartja a szinkronizálást a vonalkártyák minden DFC FIB táblájával, hogy biztosítsa az Útválasztás integritását a rendszeren keresztül.
ha az opcionális DFC-kártya nincs jelen, egy kompakt fejléc-keresést küld a Pfc3-nak a Sup720-On annak meghatározására, hogy a kapcsolószövet hol továbbítsa az egyes csomagokat. Ha DFC van jelen, a vonalkártya a csomagot közvetlenül a kapcsolószöveten át tudja váltani a célvonal kártyára A Sup720 megkérdezése nélkül. A teljesítménykülönbség lehet 30 Mpps rendszerszintű nélkül DFC-K 48 Mpps per slot DFC-k. A rögzített konfigurációjú Catalyst 4948-10GE kapcsoló vezetéksebességgel, nem blokkoló architektúrával rendelkezik, amely akár 101,18 Mpps teljesítményt is támogat, kiváló hozzáférési réteg teljesítményt nyújt a rack-minták tetején.
a késleltetési teljesítmény jelentősen eltérhet az elosztott és a központi továbbítási modellek összehasonlításakor. A 3-1. táblázat példát mutat a 6704-es vonali kártyán mért késésekre DFC-kkel vagy anélkül.
| 6704 DFC-vel (Port-to-Port Mikroszekundumban a Kapcsolószöveten keresztül) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
csomag mérete (B) |
||||||||||
|
késleltetés (ms) |
||||||||||
| 6704 DFC nélkül (Port-to-Port Mikroszekundumban a Kapcsolószöveten keresztül) | ||||||||||
|
csomag mérete (B) |
||||||||||
|
késleltetés (ms) |
||||||||||
a késleltetés különbsége a DFC-kompatibilis és előfordulhat, hogy a nem DFC-kompatibilis vonalkártya nem jelenik meg jelentősnek. A 6500-as központi továbbítási architektúrában azonban a késés növekedhet a forgalmi sebesség növekedésével, mivel a központi buszon megosztott keresés áll. DFC esetén a keresési útvonal az egyes vonalkártyákhoz van rendelve, a késleltetés pedig állandó.
Catalyst 6500 rendszer sávszélessége
a rendelkezésre álló rendszer sávszélessége nem változik DFC-k használata esetén. A DFC-k javítják a teljes rendszer PPS (packets per second) feldolgozását. A 3-2.táblázat a régebbi CEF256 és klasszikus buszmodulok mellett összefoglalja a DFC-ket támogató modulok áteresztőképességét és sávszélességét.
| Rendszerkonfiguráció Sup720 | átviteli sebesség Mpps-ben | sávszélesség Gbps-ben |
|
klasszikus sorozatú modulok |
akár 15 MPP (rendszerenként) |
16 G megosztott busz (klasszikus busz) |
|
CEF256 sorozatú modulok |
akár 30 MPP (rendszerenként) |
1x 8 G (dedikált résenként) |
|
klasszikus keverék CEF256 vagy CEF720 sorozatú modulokkal |
akár 15 MPP (rendszerenként) |
kártya függő |
|
CEF720 sorozatú modulok (6748, 6704, 6724) |
akár 30 MPP (rendszerenként) |
2x 20 G (dedikált résenként) |
|
CEF720 sorozatú modulok DFC3-mal (6704 DFC3-mal, 6708 DFC3-mal, 6748 dfc3-mal 6724 + DFC3) |
Sustain akár 48 MPP (résenként) |
2x 20 G (dedikált résenként) |
bár a 6513 érvényes megoldás lehet A large cluster modell hozzáférési rétegére, vegye figyelembe, hogy ebben az alvázban egy-és kétcsatornás rések vannak. Az 1-8 rések egycsatornásak, a 9-13 rések pedig kétcsatornásak, amint azt a 3-1.ábra mutatja.
ábra 3-1 Catalyst 6500 Szövet csatornák alváz és Slot (6513 Focus
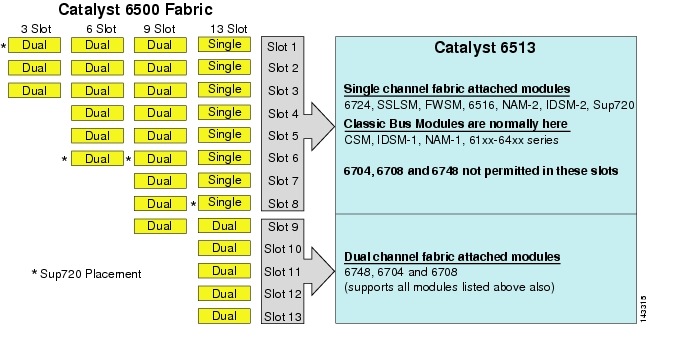
amikor egy Cisco Catalyst 6513 használják, a kétcsatornás kártyák, mint például a 6704-4 port 10gige, a 6708 – 8 port 10gige, és a 6748-48 port SFP/réz vonal kártyákat lehet helyezni csak rések 9 hogy 13. Az egycsatornás vonal kártyák, mint például a 6724-24 port SFP / réz vonal kártyákat lehet használni rések 1 hogy 8. A Sup720 7 és 8 nyílásokat használ, amelyek egycsatornás 20g szövethez vannak csatlakoztatva. A 6513-mal ellentétben a 6509-nek kevesebb rendelkezésre álló nyílása van, de minden nyílásban támogathatja a kétcsatornás modulokat, mivel minden nyílásnak kettős csatornája van a kapcsolószövethez.
Megjegyzés ![]() mivel a kiszolgálófürt környezet általában nagy sávszélességet igényel, alacsony késleltetési jellemzőkkel, javasoljuk a DFC-k használatát az ilyen típusú tervekben.
mivel a kiszolgálófürt környezet általában nagy sávszélességet igényel, alacsony késleltetési jellemzőkkel, javasoljuk a DFC-k használatát az ilyen típusú tervekben.
Equal Cost Multi-Path Routing
az Equal cost multi-path (Ecmp) routing egy terheléselosztási technológia, amely optimalizálja a Cisco Express Forwarding-kompatibilis környezetben a két alhálózat közötti több IP-útvonalon történő áramlást. Az ECMP terheléselosztást alkalmaz a TCP és UDP csomagokra áramlásonként. A nem TCP / UDP csomagok, mint például az ICMP, csomagonként vannak elosztva. Az ECMP az RFC 2991 szabványon alapul, és más Cisco platformokon, például a PIX és a Cisco Content Services Switch (CSS) termékeken alapul. Az ECMP mind a 6500, mind a 4948-10GE platformokon támogatott a kiszolgálófürt tervezésében.
a Layer 3 kapcsoló hardver ASIC és a Cisco Express Forwarding hashing algoritmusok által okozott drámai változások segítenek megkülönböztetni az ECMP-t az elődjétől. A kiszolgálófürt-megvalósítások ECMP-tervezésének fő előnye a hash algoritmus, kevés vagy egyáltalán nem CPU-rezsi a 3. réteg kapcsolásában. A Cisco Express Forwarding hash algoritmus képes a szemcsés áramlások elosztására több vonali kártyán, hardveres vonali sebességgel. A hash algoritmus alapértelmezett beállítása a hash folyamatok alapján 3. réteg forrás-cél IP-címek, opcionálisan hozzáadva a 4. réteg portszámait egy további differenciálási réteghez. Az ECMP útvonalak maximális száma nyolc.
a 3-2.ábra egy 8-utas ECMP kiszolgálófürt kialakítását szemlélteti. Az illusztráció egyszerűsítése érdekében csak két hozzáférési réteg kapcsoló jelenik meg, de legfeljebb 32 támogatható (64 10giges magcsomópontonként).
3-2. ábra 8-utas ECMP szerver klaszter tervezés
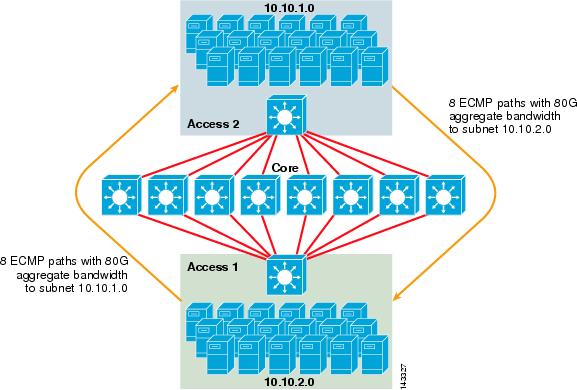
a 3-2.ábrán minden hozzáférési réteg kapcsoló támogathatja a csatolt szerverek egy vagy több alhálózatát. Minden kapcsoló egyetlen 10gige kapcsolat mind a nyolc mag kapcsolók két 6704 vonal kártyák. Ez a konfiguráció nyolc utak 10GigE összesen 80 G Cisco Express Forwarding-kompatibilis sávszélesség bármely más alhálózaton a szerver klaszter Szövet. A show ip útvonal lekérdezés egy másik alhálózatra egy másik kapcsolón nyolc egyenlő költségű bejegyzést mutat.
a magot 10gige vonalkártyák töltik be DFC-kkel, hogy lehetővé tegyék a teljesen elosztott nagysebességű kapcsolószövetet, nagyon alacsony port-port késéssel. Az IP-útvonal megjelenítése lekérdezés egy hozzáférési réteg kapcsolóhoz egyetlen útvonalbejegyzést jelenít meg mind a nyolc magkapcsolón.
Megjegyzés ![]() bár ezt az útmutatót még nem tesztelték, van egy új 8 portos 10 Gigabites Ethernet modul (WS-X6708-10g-3C), amelyet nemrégiben vezettek be a Catalyst 6500 sorozatú kapcsolóhoz. Ezt a vonalkártyát egy későbbi időpontban tesztelik az útmutatóba való felvétel céljából. Ha kérdése van a 8 portos 10gige kártyával kapcsolatban, olvassa el a termék adatlapját.
bár ezt az útmutatót még nem tesztelték, van egy új 8 portos 10 Gigabites Ethernet modul (WS-X6708-10g-3C), amelyet nemrégiben vezettek be a Catalyst 6500 sorozatú kapcsolóhoz. Ezt a vonalkártyát egy későbbi időpontban tesztelik az útmutatóba való felvétel céljából. Ha kérdése van a 8 portos 10gige kártyával kapcsolatban, olvassa el a termék adatlapját.
redundancia a kiszolgálófürt tervezésében
a kiszolgálófürt tervezését általában nem redundáns CPU vagy switch fabric processzorokkal hajtják végre. A rugalmasság jellemzően a tervezés során és a klaszter egészének működésével érhető el. Az “adatközpont-architektúra áttekintése” című 1.fejezetben leírtak szerint a fürt számítási csomópontjait olyan főcsomópontok kezelik, amelyek felelősek az egyes számítási csomópontokhoz adott feladatok hozzárendeléséért és teljesítményük figyeléséért. Ha egy számítási csomópont kiesik a fürtből, akkor újra hozzárendel egy rendelkezésre álló csomóponthoz, és továbbra is működik, bár kevesebb feldolgozási teljesítmény mellett, amíg a csomópont rendelkezésre nem áll. Bár fontos a fürtben lévő fő csomópont-kapcsolatok diverzifikálása a különböző hozzáférési kapcsolók között, ez nem kritikus a számítási csomópontok szempontjából.
bár a redundáns CPU-k minden bizonnyal opcionálisak, fontos figyelembe venni a port sűrűségét, különös tekintettel a 10GE portokra, ahol egy extra nyílás áll rendelkezésre a redundáns Sup720 modul helyett.
Megjegyzés ![]() az ebben a fejezetben szereplő példák nem redundáns CPU-terveket használnak, amelyek legfeljebb 64 10GE portot tesznek lehetővé 6509 magcsomópontonként a hozzáférési csomópont felfelé irányuló kapcsolataihoz 6708 8 portos 10gige vonalkártya használatával.
az ebben a fejezetben szereplő példák nem redundáns CPU-terveket használnak, amelyek legfeljebb 64 10GE portot tesznek lehetővé 6509 magcsomópontonként a hozzáférési csomópont felfelé irányuló kapcsolataihoz 6708 8 portos 10gige vonalkártya használatával.
kiszolgálófürt—tervezés-kétszintű modell
ez a szakasz az ECMP-t és az elosztott CEF-t kihasználó kiszolgálófürt-tervezés különböző megközelítéseit ismerteti. Minden terv bemutatja, hogy a különböző konfigurációk hogyan érhetnek el különböző túljelentkezési szinteket, és rugalmasan skálázhatók, kezdve néhány csomóponttal, és egyre több kiszolgálót támogatva.
a kiszolgálófürt kialakítása jellemzően kétszintű modellt követ, amely mag-és hozzáférési rétegekből áll. Mivel a tervezési célok megkövetelik a 3. réteg ECMP használatát és az elosztott továbbítást, hogy szerverenként erősen determinisztikus sávszélességet és késleltetést érjenek el, általában nem kívánatos egy háromszintű modell, amely újabb túljelentkezési pontot vezet be. A háromszintű modell előnyeit a kiszolgálófürt tervezése—háromszintű modell ismerteti.
a kiszolgálófürtmegoldás tervezésekor figyelembe veendő három fő számítás a maximális Kiszolgálókapcsolat, a kiszolgálónkénti sávszélesség és a túljelentkezés aránya. A fürttervezők ezeket az értékeket az alkalmazás teljesítménye, a kiszolgálói hardver és egyéb tényezők alapján határozhatják meg, beleértve a következőket:
•![]() a szerver GigE-kapcsolatok maximális száma méretarányban-a Klasztertervezők általában elképzelik a kezdeti koncepcióhoz szükséges maximális skálát. Az ECMP tervezési funkciójának előnye, hogy minimális számú kapcsolóval és kiszolgálóval indulhat, amelyek megfelelnek egy adott sávszélesség -, késleltetési és túlfizetési követelménynek, és rugalmasan növekedhetnek alacsony/nem zavaró módon a maximális méretarányig, miközben ugyanazt a sávszélességet, késleltetést és túlfizetési értékeket tartják fenn.
a szerver GigE-kapcsolatok maximális száma méretarányban-a Klasztertervezők általában elképzelik a kezdeti koncepcióhoz szükséges maximális skálát. Az ECMP tervezési funkciójának előnye, hogy minimális számú kapcsolóval és kiszolgálóval indulhat, amelyek megfelelnek egy adott sávszélesség -, késleltetési és túlfizetési követelménynek, és rugalmasan növekedhetnek alacsony/nem zavaró módon a maximális méretarányig, miközben ugyanazt a sávszélességet, késleltetést és túlfizetési értékeket tartják fenn.
•![]() hozzávetőleges sávszélesség kiszolgálónként—ez az érték úgy határozható meg, hogy egyszerűen elosztjuk a teljes összesített felfelé irányuló sávszélességet a hozzáférési réteg kapcsolóján lévő összes szerver GigE-kapcsolattal. Például, egy hozzáférési réteg Cisco 6509 négy 10GigE ECMP uplinks a 336 szerver hozzáférési portok lehet kiszámítani a következőképpen:
hozzávetőleges sávszélesség kiszolgálónként—ez az érték úgy határozható meg, hogy egyszerűen elosztjuk a teljes összesített felfelé irányuló sávszélességet a hozzáférési réteg kapcsolóján lévő összes szerver GigE-kapcsolattal. Például, egy hozzáférési réteg Cisco 6509 négy 10GigE ECMP uplinks a 336 szerver hozzáférési portok lehet kiszámítani a következőképpen:
4x10GigE Uplinks a 336 szerverek = 120 Mbps per szerver
beállítása mindkét oldalán az egyenlet csökkenti vagy növeli a sávszélesség per szerver.
Megjegyzés ![]() ez csak hozzávetőleges érték, és csak iránymutatásként szolgál. Különböző tényezők befolyásolják az egyes kiszolgálók tényleges sávszélességét. Az ECMP terheléselosztási hash algoritmus a 3. réteg plusz 4. réteg értékei alapján osztja fel a terhelést, és a forgalmi minták alapján változik. A konfigurációs paraméterek, mint például a sebességkorlátozás, a sorban állás és a QoS értékek befolyásolhatják a kiszolgálónkénti tényleges sávszélességet.
ez csak hozzávetőleges érték, és csak iránymutatásként szolgál. Különböző tényezők befolyásolják az egyes kiszolgálók tényleges sávszélességét. Az ECMP terheléselosztási hash algoritmus a 3. réteg plusz 4. réteg értékei alapján osztja fel a terhelést, és a forgalmi minták alapján változik. A konfigurációs paraméterek, mint például a sebességkorlátozás, a sorban állás és a QoS értékek befolyásolhatják a kiszolgálónkénti tényleges sávszélességet.
•![]() túljelentkezés aránya szerverenként—ez az érték úgy határozható meg, hogy egyszerűen elosztjuk a szerver GigE-kapcsolatok teljes számát A hozzáférési réteg kapcsolójának teljes összesített felfelé irányuló sávszélességével. Például egy 6509-es hozzáférési réteg négy 10gige ECMP uplinkkel, 336 szerver hozzáférési porttal a következőképpen számítható ki:
túljelentkezés aránya szerverenként—ez az érték úgy határozható meg, hogy egyszerűen elosztjuk a szerver GigE-kapcsolatok teljes számát A hozzáférési réteg kapcsolójának teljes összesített felfelé irányuló sávszélességével. Például egy 6509-es hozzáférési réteg négy 10gige ECMP uplinkkel, 336 szerver hozzáférési porttal a következőképpen számítható ki:
336 GigE szerver kapcsolat 40G uplink sávszélességgel = 8,4: 1 túljelentkezési arány
a következő szakaszok bemutatják, hogy ezek az értékek hogyan változnak a különböző hardver-és összekapcsolási konfigurációk alapján, és iránymutatásként szolgálnak nagy fürtkonfigurációk tervezésekor.
Megjegyzés ![]() számítási célokra feltételezzük, hogy a Catalyst 6500 sorozatú kapcsolón nincs vonalkártya a szövet túlfizetésének váltására. A kétcsatornás nyílás 40G maximális sávszélességet biztosít a kapcsolószövet számára. A 4-portos 10gige kártya minden port line rate segítségével maximális méretű csomagokat tartják a lehető legjobb állapotban alig vagy egyáltalán nem túljelentkezés. A rendelkezésre álló switch fabric sávszélesség tényleges mennyisége az átlagos csomagméretek alapján változik. Ezeket a számításokat újra kell számolni, ha a WS-X6708 8-portos 10gige kártyát használná, amely 2:1 arányban túl van írva.
számítási célokra feltételezzük, hogy a Catalyst 6500 sorozatú kapcsolón nincs vonalkártya a szövet túlfizetésének váltására. A kétcsatornás nyílás 40G maximális sávszélességet biztosít a kapcsolószövet számára. A 4-portos 10gige kártya minden port line rate segítségével maximális méretű csomagokat tartják a lehető legjobb állapotban alig vagy egyáltalán nem túljelentkezés. A rendelkezésre álló switch fabric sávszélesség tényleges mennyisége az átlagos csomagméretek alapján változik. Ezeket a számításokat újra kell számolni, ha a WS-X6708 8-portos 10gige kártyát használná, amely 2:1 arányban túl van írva.
4-és 8-utas ECMP tervek moduláris hozzáféréssel
az alábbi négy tervezési példa bemutatja a kétszintű kiszolgálófürtmodell felépítésének és méretezésének különböző módszereit 4-utas és 8-utas ECMP használatával. A legfontosabb megfontolandó kérdések a magcsomópontok száma és az uplinkek maximális száma, mivel ezek közvetlenül befolyásolják a maximális skálát, a kiszolgálónkénti sávszélességet és a túljelentkezés értékeit.
Megjegyzés ![]() bár ezt az útmutatót még nem tesztelték, van egy új 8 portos 10 Gigabites Ethernet modul (WS-X6708-10g-3C), amelyet nemrégiben vezettek be a Catalyst 6500 sorozatú kapcsolóhoz. Ezt a vonalkártyát egy későbbi időpontban tesztelik az útmutatóba való felvétel céljából. Ha kérdése van a 8 portos 10gige kártyával kapcsolatban, olvassa el a termék adatlapját.
bár ezt az útmutatót még nem tesztelték, van egy új 8 portos 10 Gigabites Ethernet modul (WS-X6708-10g-3C), amelyet nemrégiben vezettek be a Catalyst 6500 sorozatú kapcsolóhoz. Ezt a vonalkártyát egy későbbi időpontban tesztelik az útmutatóba való felvétel céljából. Ha kérdése van a 8 portos 10gige kártyával kapcsolatban, olvassa el a termék adatlapját.
Megjegyzés ![]() a kiszolgálófürt külső campus-vagy metróhálózathoz való csatlakoztatásához szükséges linkek nem szerepelnek ezekben a tervezési példákban, de figyelembe kell venni.
a kiszolgálófürt külső campus-vagy metróhálózathoz való csatlakoztatásához szükséges linkek nem szerepelnek ezekben a tervezési példákban, de figyelembe kell venni.
a 3-3. ábra egy olyan példát mutat be, amelyben két magcsomópontot használnak egy 4-utas ECMP megoldás biztosítására.
3-3. ábra 4-utas ECMP két Magcsomópont használatával
ennek a megközelítésnek az az előnye, hogy kisebb számú magkapcsoló képes nagyszámú szervert támogatni. A lehetséges hátrány a magas túljelentkezés-kiszolgálónkénti alacsony sávszélesség és a magcsomópont meghibásodásának nagy kitettsége. Vegye figyelembe, hogy az uplinkek egyedi L3 uplinkek, és nem Étercsatornák.
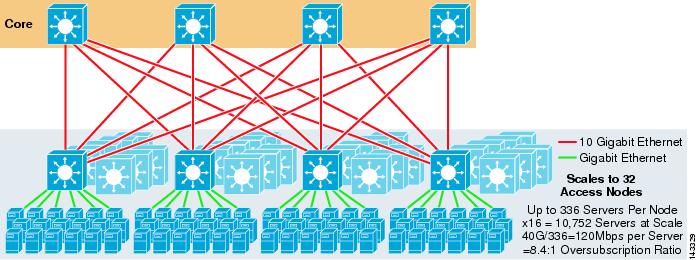
a 3-4. ábra bemutatja, hogy két magcsomópont hozzáadása az előző tervhez drámaian megnövelheti a maximális skálát, miközben ugyanazt a túljelentkezést és sávszélességet tartja fenn szerverenként.
3-4. ábra 4-utas ECMP négy Magcsomópont használatával
a 3-5.ábra egy 8-utas ECMP kialakítást mutat két magcsomópont használatával.
3-5. ábra 8-utas ECMP két Magcsomópont használatával
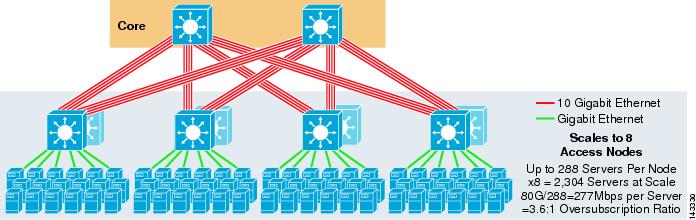
a várakozásoknak megfelelően a további felfelé irányuló sávszélesség drámai módon növeli a kiszolgálónkénti sávszélességet és csökkenti a kiszolgálónkénti túljelentkezés arányát. Vegye figyelembe, hogy az egyes hozzáférési rétegkapcsolókban a 8-utas felfelé mutató linkek támogatására szolgáló további rések hogyan csökkentik a maximális skálát, mivel a kapcsolónkénti szerverek száma 288-ra csökken. Vegye figyelembe, hogy az uplinkek egyedi L3 uplinkek, és nem Étercsatornák.
a 3-6.ábra egy 8-utas ECMP kialakítást mutat nyolc magcsomóponttal.
3-6. ábra 8-utas ECMP nyolc Magcsomópont használatával
ez azt mutatja, hogy négy magcsomópont hozzáadása ugyanahhoz az előző tervhez drámai módon növelheti a maximális skálát, miközben ugyanazt a túljelentkezést és sávszélességet tartja fenn szerverenként.
2-utas ECMP tervezés 1RU hozzáféréssel
sok fürtkörnyezetben a rack-alapú kiszolgálóváltás az egyes kiszolgálóállványok tetején lévő kis kapcsolókkal kívánatos vagy szükséges kábelezés, adminisztratív, ingatlanproblémák vagy bizonyos telepítési modell célok elérése érdekében.
a 3-7.ábra egy példát mutat be, amelyben két magcsomópontot használnak 2-utas ECMP megoldás biztosítására 1RU 4948-10GE hozzáférési kapcsolókkal.
3-7. ábra 2-utas ECMP két központi csomópont és 1RU hozzáférés
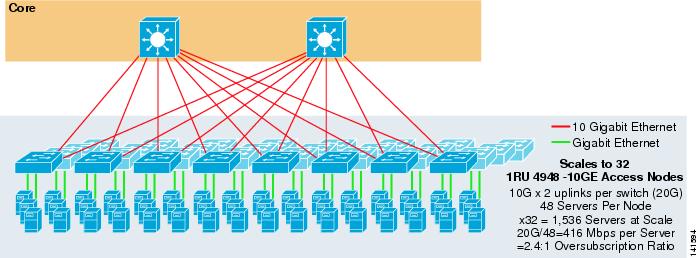
a maximális skála 1536 szerverre korlátozódik, de több mint 400 Mbps sávszélességet biztosít alacsony túlfizetési arány mellett. Mivel a 4948-nak csak két 10gige felfelé mutató linkje van, ez a kialakítás nem haladhatja meg ezeket az értékeket.
Megjegyzés ![]() a rack-alapú kiszolgálóváltással kapcsolatos további információk a 3.fejezetben találhatók “Kiszolgálófürtök tervezése Ethernettel.”
a rack-alapú kiszolgálóváltással kapcsolatos további információk a 3.fejezetben találhatók “Kiszolgálófürtök tervezése Ethernettel.”
kiszolgálófürt kialakítása—háromszintű modell
bár a kétszintű modell a leggyakoribb a nagy klasztertervekben, háromszintű modell is használható. A háromszintű modellt általában nagy kiszolgálófürt-megvalósítások támogatására használják 1RU vagy moduláris hozzáférési réteg kapcsolók.
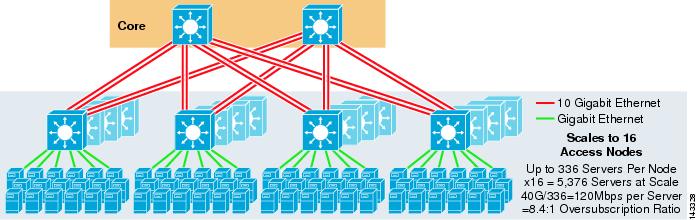
a 3-8.ábra egy nagyszabású példát mutat be a 8-utas ECMP kihasználására 6500 mag-és aggregációs kapcsolókkal és 1RU 4948-10GE hozzáférési réteg kapcsolókkal.
3-8. ábra háromszintű Modell 8 utas ECMP-vel
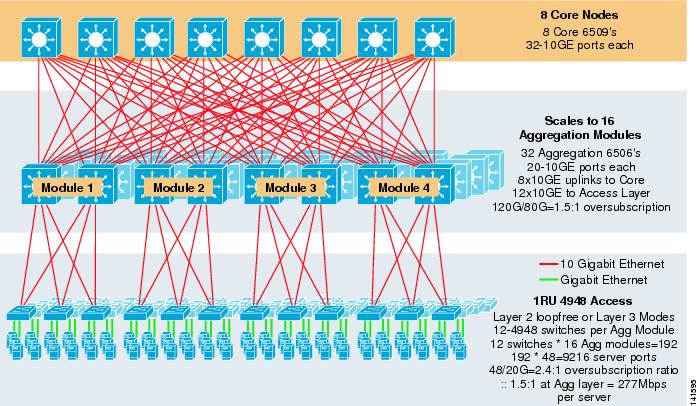
a maximális skála több mint 9200 szerver 277 Mbps sávszélességgel, alacsony túlfizetési arány mellett. Az 1RU hozzáférési kapcsolókat használó háromszintű megközelítés előnyei a következők:
•![]() 1RU telepítési modellek—mint korábban említettük, sok nagy fürt modell telepítése 1RU megközelítést igényel az egyszerűsített telepítéshez. Például egy ASP egyszerre gördít ki kiszolgálók állványait, amikor nagy fürtalkalmazásokat méreteznek. A szerver rack előre összeszerelt és szakaszos kihelyezett oly módon, hogy gyorsan telepíthető és hozzáadható a futó fürt. Ez általában magában foglal egy harmadik felet, aki felépíti a rackeket, előre konfigurálja a szervereket, és előzetesen kábelezi őket tápellátással és Ethernettel egy 1RU kapcsolóhoz. A rack az adatközpontba gördül, és az uplinkek csatlakoztatása után egyszerűen csatlakozik és hozzáadódik a fürthöz.
1RU telepítési modellek—mint korábban említettük, sok nagy fürt modell telepítése 1RU megközelítést igényel az egyszerűsített telepítéshez. Például egy ASP egyszerre gördít ki kiszolgálók állványait, amikor nagy fürtalkalmazásokat méreteznek. A szerver rack előre összeszerelt és szakaszos kihelyezett oly módon, hogy gyorsan telepíthető és hozzáadható a futó fürt. Ez általában magában foglal egy harmadik felet, aki felépíti a rackeket, előre konfigurálja a szervereket, és előzetesen kábelezi őket tápellátással és Ethernettel egy 1RU kapcsolóhoz. A rack az adatközpontba gördül, és az uplinkek csatlakoztatása után egyszerűen csatlakozik és hozzáadódik a fürthöz.
aggregációs réteg nélkül az 1RU hozzáférési modell maximális mérete alig több mint 1500 szerverre korlátozódik. Az aggregációs réteg hozzáadása lehetővé teszi az 1RU hozzáférési modell sokkal nagyobb méretre méretezését, miközben továbbra is kihasználja az ECMP modellt.
•![]() mag-és aggregációs kapcsolók központosítása—az 1RU kapcsolókkal a rackekben lehetőség van a nagyobb mag-és aggregációs moduláris kapcsolók központosítására. Ez egyszerűsítheti az áram-és kábelezési infrastruktúrát, és javíthatja a rack ingatlanok használatát.
mag-és aggregációs kapcsolók központosítása—az 1RU kapcsolókkal a rackekben lehetőség van a nagyobb mag-és aggregációs moduláris kapcsolók központosítására. Ez egyszerűsítheti az áram-és kábelezési infrastruktúrát, és javíthatja a rack ingatlanok használatát.
•![]() lehetővé teszi a 2. réteg hurokmentes topológiáját—a 3. réteg ECMP-hozzáférését használó nagy fürthálózat sok címteret használhat a felfelé mutató linkeken, és bonyolultabbá teheti a tervezést. Ez különösen fontos, ha nyilvános címtartományt használnak. A háromszintű modell megközelítés jól alkalmazható egy 2. rétegű hurokmentes hozzáférési topológiára, amely csökkenti a szükséges alhálózatok számát.
lehetővé teszi a 2. réteg hurokmentes topológiáját—a 3. réteg ECMP-hozzáférését használó nagy fürthálózat sok címteret használhat a felfelé mutató linkeken, és bonyolultabbá teheti a tervezést. Ez különösen fontos, ha nyilvános címtartományt használnak. A háromszintű modell megközelítés jól alkalmazható egy 2. rétegű hurokmentes hozzáférési topológiára, amely csökkenti a szükséges alhálózatok számát.
ha 2. rétegű hurokmentes modellt használunk, fontos, hogy redundáns alapértelmezett átjáró protokollt, például HSRP vagy GLBP használjunk az egyetlen hibapont kiküszöbölésére, ha egy aggregációs csomópont meghibásodik. Ebben a kialakításban az aggregációs modulok nincsenek összekapcsolva, lehetővé téve a hurokmentes 2. réteg kialakítását, amely kihasználhatja a GLBP-t az automatikus szerver alapértelmezett átjáró terheléselosztásához. A GLBP automatikusan elosztja a kiszolgálók alapértelmezett átjáró-hozzárendelését az összesítő modul két csomópontja között. Miután egy csomag megérkezett az aggregációs réteghez, a 8-utas ECMP szövet segítségével egyensúlyba kerül a magon. Bár a GLBP nem nyújt a CEF-hez hasonló 3.réteg/4. réteg terheléselosztási hash-ot, ez egy alternatíva, amely a 2. réteg hozzáférési topológiájával használható.
túljegyzés kiszámítása
a háromszintű modell két túljegyzési pontot vezet be az access és az aggregation rétegeken, szemben a kétszintű modellel, amelynek csak egyetlen túljegyzési pontja van az access rétegen. A kiszolgálónkénti hozzávetőleges sávszélesség és a túljelentkezés arány megfelelő kiszámításához hajtsa végre a következő két lépést, amelyek példaként a 3-8.ábrát használják:
1. lépés ![]() Számítsa ki a túljelentkezés arányát és a kiszolgálónkénti sávszélességet mind az összesítési, mind az access rétegek esetében függetlenül.
Számítsa ki a túljelentkezés arányát és a kiszolgálónkénti sávszélességet mind az összesítési, mind az access rétegek esetében függetlenül.
•![]() hozzáférési réteg
hozzáférési réteg
–![]() túljelentkezés—48ge csatolt szerverek/20g uplinkek az aggregációhoz = 2.4:1
túljelentkezés—48ge csatolt szerverek/20g uplinkek az aggregációhoz = 2.4:1
–![]() sávszélesség kiszolgálónként—20g felfelé mutató linkek az összesítéshez / 48gige csatolt szerverek = 416Mbps
sávszélesség kiszolgálónként—20g felfelé mutató linkek az összesítéshez / 48gige csatolt szerverek = 416Mbps
•![]() aggregációs réteg
aggregációs réteg
–![]() túljelentkezés—120g lefelé mutató linkek a hozzáféréshez / 80G felfelé mutató linkek a maghoz = 1.5:1
túljelentkezés—120g lefelé mutató linkek a hozzáféréshez / 80G felfelé mutató linkek a maghoz = 1.5:1
2. lépés ![]() Számítsa ki a kombinált túlfizetési arányt és a sávszélességet szerverenként.
Számítsa ki a kombinált túlfizetési arányt és a sávszélességet szerverenként.
a tényleges túljegyzési arány a túljegyzés két pontjának összege az access és az aggregation rétegeknél.
1.5*2.4 = 3.6:1
a kiszolgálónkénti valós sávszélesség meghatározásához használja az algebrai képletet az arányokhoz:
a:b = c: d
a hozzáférési réteg kiszolgálónkénti sávszélessége kiszolgálónként 416 Mbps. Mivel az aggregációs réteg túljelentkezési aránya 1,5: 1, a fenti képletet a következőképpen alkalmazhatja:
416:1 = x: 1.5
x = ~264 Mbps / szerver
ajánlott hardver és modulok
a kiszolgálófürt modelltervezéséhez ajánlott platformok a Cisco Catalyst 6500 családból állnak, a Sup720 processzormodullal és a Catalyst 4948-10GE 1RU kapcsolóval. A magas kapcsolási sebesség, a nagy kapcsolószövet, az alacsony késleltetés, az elosztott továbbítás és a 10GigE sűrűség miatt a Catalyst 6500 sorozatú kapcsoló ideális a modell minden rétegéhez. Az 1RU forma tényező a huzalsebesség-továbbítással, az 10GE felfelé irányuló kapcsolatokkal és a nagyon alacsony állandó késleltetéssel kombinálva a 4948-10GE kiváló rack-megoldást kínál a hozzáférési réteg számára.
a következőket ajánljuk:
•![]() Sup720-a Sup720 állhat mind a pfc3a (alapértelmezett), mind az újabb pfc3b típusú leánykártyákból.
Sup720-a Sup720 állhat mind a pfc3a (alapértelmezett), mind az újabb pfc3b típusú leánykártyákból.
•![]() Vonalkártyák-minden vonalkártyának 6700-as sorozatnak kell lennie, és engedélyezni kell az elosztott továbbítást a DFC3A vagy DFC3B leánykártyákkal.
Vonalkártyák-minden vonalkártyának 6700-as sorozatnak kell lennie, és engedélyezni kell az elosztott továbbítást a DFC3A vagy DFC3B leánykártyákkal.
Megjegyzés ![]() az összes szövetre szerelt CEF720 sorozatú modul használatával a globális kapcsolási mód kompakt, amely lehetővé teszi a rendszer legmagasabb szintű működését. A Catalyst 6509 támogatja 10 GigE modulok minden helyzetben, mert minden slot támogatja a kétcsatornás a kapcsoló szövet (A Cisco Catalyst 6513 nem támogatja ezt).
az összes szövetre szerelt CEF720 sorozatú modul használatával a globális kapcsolási mód kompakt, amely lehetővé teszi a rendszer legmagasabb szintű működését. A Catalyst 6509 támogatja 10 GigE modulok minden helyzetben, mert minden slot támogatja a kétcsatornás a kapcsoló szövet (A Cisco Catalyst 6513 nem támogatja ezt).
•![]() Cisco Catalyst 4948-10GE—a 4948-10GE nagy teljesítményű hozzáférési réteg megoldást kínál, amely kihasználhatja az ECMP és a 10GIGE uplinkeket. Nincs szükség különleges követelményekre. A 4948 – 10GE használhat egy réteg 2 Cisco IOS képet vagy egy réteg 2/3 Cisco IOS képet, amely lehetővé teszi az optimális illeszkedést mindkét környezetben.
Cisco Catalyst 4948-10GE—a 4948-10GE nagy teljesítményű hozzáférési réteg megoldást kínál, amely kihasználhatja az ECMP és a 10GIGE uplinkeket. Nincs szükség különleges követelményekre. A 4948 – 10GE használhat egy réteg 2 Cisco IOS képet vagy egy réteg 2/3 Cisco IOS képet, amely lehetővé teszi az optimális illeszkedést mindkét környezetben.