




Guide de conception de l’Infrastructure de centre de données Cisco 2.5
Conceptions de grappes de serveurs avec Ethernet
Une vue d’ensemble de haut niveau des serveurs et des composants réseau utilisés dans le modèle de grappe de serveurs est fournie dans le chapitre 1 » Vue d’ensemble de l’architecture du centre de données. » Ce chapitre décrit plus en détail le but et la fonction de chaque couche du modèle de cluster de serveurs. Les sections suivantes sont incluses:
•![]() Objectifs Techniques
Objectifs Techniques
•![]() Transfert distribué et Latence
Transfert distribué et Latence
•![]() Routage Multi-Chemins À Coût Égal
Routage Multi-Chemins À Coût Égal
•![]() Conception de Cluster de Serveurs – Modèle à Deux niveaux
Conception de Cluster de Serveurs – Modèle à Deux niveaux
•![]() Conception de Cluster de Serveurs – Modèle à Trois niveaux
Conception de Cluster de Serveurs – Modèle à Trois niveaux
•![]() Matériel et modules recommandés
Matériel et modules recommandés

Note ![]() Les modèles de conception couverts dans ce chapitre n’ont pas été entièrement vérifiés dans les tests de laboratoire Cisco en raison de la taille et de la portée des tests qui seraient nécessaires. Les modèles à deux niveaux couverts sont des conceptions similaires qui ont été mises en œuvre dans les réseaux de production des clients.
Les modèles de conception couverts dans ce chapitre n’ont pas été entièrement vérifiés dans les tests de laboratoire Cisco en raison de la taille et de la portée des tests qui seraient nécessaires. Les modèles à deux niveaux couverts sont des conceptions similaires qui ont été mises en œuvre dans les réseaux de production des clients.
Objectifs techniques
Lors de la conception d’un grand réseau de clusters d’entreprise, il est essentiel de prendre en compte des objectifs spécifiques. Il n’y a pas deux groupes qui se ressemblent exactement; chacun a ses propres exigences spécifiques et doit être examiné du point de vue de l’application pour déterminer les exigences de conception particulières. Tenir compte des considérations techniques suivantes:
•![]() Latence – Dans le transport réseau, la latence peut nuire aux performances globales du cluster. L’utilisation de plates-formes de commutation qui utilisent une architecture de commutation à faible latence permet d’assurer des performances optimales. La principale source de latence est la pile de protocoles et l’implémentation matérielle de la carte réseau utilisée sur le serveur. Les techniques d’optimisation des pilotes et de déchargement du processeur, telles que le moteur de déchargement TCP (TOE) et l’accès direct à la mémoire à distance (RDMA), peuvent aider à réduire la latence et la surcharge de traitement sur le serveur.
Latence – Dans le transport réseau, la latence peut nuire aux performances globales du cluster. L’utilisation de plates-formes de commutation qui utilisent une architecture de commutation à faible latence permet d’assurer des performances optimales. La principale source de latence est la pile de protocoles et l’implémentation matérielle de la carte réseau utilisée sur le serveur. Les techniques d’optimisation des pilotes et de déchargement du processeur, telles que le moteur de déchargement TCP (TOE) et l’accès direct à la mémoire à distance (RDMA), peuvent aider à réduire la latence et la surcharge de traitement sur le serveur.
La latence peut ne pas toujours être un facteur critique dans la conception du cluster. Par exemple, certains clusters peuvent nécessiter une bande passante élevée entre les serveurs en raison d’une grande quantité de transfert de fichiers en masse, mais peuvent ne pas dépendre fortement de la messagerie de communication inter-processus (IPC) de serveur à serveur, qui peut être affectée par une latence élevée.
•![]() Connectivité maillée/maillée partielle – Les conceptions de cluster de serveurs nécessitent généralement un maillage ou une structure maillée partielle pour permettre la communication entre tous les nœuds du cluster. Cette structure de maillage est utilisée pour partager l’état, les données et d’autres informations entre les serveurs maître-calcul et calcul-à-calcul du cluster. La connectivité maillée ou maillée partielle dépend également de l’application.
Connectivité maillée/maillée partielle – Les conceptions de cluster de serveurs nécessitent généralement un maillage ou une structure maillée partielle pour permettre la communication entre tous les nœuds du cluster. Cette structure de maillage est utilisée pour partager l’état, les données et d’autres informations entre les serveurs maître-calcul et calcul-à-calcul du cluster. La connectivité maillée ou maillée partielle dépend également de l’application.
•![]() Débit élevé – La possibilité d’envoyer un fichier volumineux dans un laps de temps spécifique peut être essentielle au fonctionnement et aux performances du cluster. Les clusters de serveurs nécessitent généralement une quantité minimale de bande passante non bloquante disponible, ce qui se traduit par un modèle de sursouscription faible entre les couches access et core.
Débit élevé – La possibilité d’envoyer un fichier volumineux dans un laps de temps spécifique peut être essentielle au fonctionnement et aux performances du cluster. Les clusters de serveurs nécessitent généralement une quantité minimale de bande passante non bloquante disponible, ce qui se traduit par un modèle de sursouscription faible entre les couches access et core.
•![]() Rapport de sursouscription — Le rapport de sursouscription doit être examiné à plusieurs points d’agrégation dans la conception, y compris le linecard pour commuter la bande passante de la matrice et l’entrée de la matrice de commutation sur la bande passante de liaison montante.
Rapport de sursouscription — Le rapport de sursouscription doit être examiné à plusieurs points d’agrégation dans la conception, y compris le linecard pour commuter la bande passante de la matrice et l’entrée de la matrice de commutation sur la bande passante de liaison montante.
•![]() Prise en charge des trames Jumbo — Bien que les trames jumbo puissent ne pas être utilisées dans la mise en œuvre initiale d’un cluster de serveurs, il s’agit d’une fonctionnalité très importante qui est nécessaire pour une flexibilité supplémentaire ou pour d’éventuelles exigences futures. La construction de paquets TCP/ IP place une surcharge supplémentaire sur le processeur du serveur. L’utilisation de trames jumbo peut réduire le nombre de paquets, réduisant ainsi cette surcharge.
Prise en charge des trames Jumbo — Bien que les trames jumbo puissent ne pas être utilisées dans la mise en œuvre initiale d’un cluster de serveurs, il s’agit d’une fonctionnalité très importante qui est nécessaire pour une flexibilité supplémentaire ou pour d’éventuelles exigences futures. La construction de paquets TCP/ IP place une surcharge supplémentaire sur le processeur du serveur. L’utilisation de trames jumbo peut réduire le nombre de paquets, réduisant ainsi cette surcharge.
•![]() Densité de ports – Les clusters de serveurs peuvent avoir besoin d’évoluer vers des dizaines de milliers de ports. En tant que tels, ils nécessitent des plates-formes avec un niveau élevé de performances de commutation de paquets, une grande quantité de bande passante de la matrice de commutation et un niveau élevé de densité de ports.
Densité de ports – Les clusters de serveurs peuvent avoir besoin d’évoluer vers des dizaines de milliers de ports. En tant que tels, ils nécessitent des plates-formes avec un niveau élevé de performances de commutation de paquets, une grande quantité de bande passante de la matrice de commutation et un niveau élevé de densité de ports.
Transfert distribué et latence
Le commutateur de la série Cisco Catalyst 6500 a la capacité unique de prendre en charge un transfert de paquets central ou une architecture de transfert distribuée en option, tandis que le Cisco Catalyst 4948-10GE est une conception ASIC centrale unique avec des performances de transfert de débit de ligne fixe. Les modules de carte de ligne Cisco 6700 prennent en charge un module de carte fille en option appelé carte de transfert distribuée (DFC). Le DFC permet de prendre des décisions de routage local sur chaque carte de ligne en mettant en œuvre une base d’informations de transfert local (FIB). La table FIB du PFC Sup720 maintient la synchronisation avec chaque table FIB DFC sur les linecards pour assurer l’intégrité du routage à travers le système.
Quand la carte facultative de DFC n’est pas présente, une recherche compacte d’en-tête est envoyée au PFC3 sur le Sup720 pour déterminer où sur la matrice de commutateur pour expédier chaque paquet. Lorsqu’un DFC est présent, le linecard peut commuter un paquet directement à travers la matrice de commutation vers le linecard de destination sans consulter le Sup720. La différence de performance peut aller de 30 MPPS à l’échelle du système sans DFC à 48 Mpps par emplacement avec DFC. Le commutateur Catalyst 4948-10GE à configuration fixe a un débit de fil, une architecture non bloquante prenant en charge des performances allant jusqu’à 101,18 Mpps, offrant des performances de couche d’accès supérieures pour les conceptions de rack supérieures.
Les performances de latence peuvent varier considérablement lorsque l’on compare les modèles de transfert distribué et central. Le tableau 3-1 fournit un exemple de latences mesurées sur une carte de ligne 6704 avec et sans DFC.
| 6704 avec DFC (Port à port en Microsecondes via la matrice de commutation) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Taille du paquet (B) |
||||||||||
|
Latence (ms) |
||||||||||
| 6704 sans DFC (Port à port en Microsecondes via la matrice de commutation) | ||||||||||
|
Taille du paquet (B) |
||||||||||
|
Latence (ms) |
||||||||||
La différence de latence entre un DFC activé et la carte de ligne non activée par DFC peut ne pas sembler significative. Cependant, dans une architecture de transfert central 6500, la latence peut augmenter à mesure que les taux de trafic augmentent en raison du conflit pour la recherche partagée sur le bus central. Avec un DFC, le chemin de recherche est dédié à chaque linecard et la latence est constante.
Bande passante système Catalyst 6500
La bande passante système disponible ne change pas lorsque des DFC sont utilisés. Les DFC améliorent le traitement des paquets par seconde (pps) de l’ensemble du système. Le tableau 3-2 résume les performances de débit et de bande passante pour les modules prenant en charge les DFC, en plus des anciens modules de bus CEF256 et classiques.
| Configuration du système avec Sup720 | Débit en Mpps | Bande passante en Gbps |
|
Modules de la série classique |
Jusqu’à 15 Mpps (par système) |
16 G bus partagé (bus classique) |
|
Modules de la série CEF256 |
Jusqu’à 30 Mpps (par système) |
1x 8 G (dédié par emplacement) |
|
Mélange de modules classiques avec les séries CEF256 ou CEF720 |
Jusqu’à 15 Mpps (par système) |
Dépendant de la carte |
|
Modules de la série CEF720 (6748, 6704, 6724) |
Jusqu’à 30 Mpps (par système) |
2x 20 G (dédié par emplacement) |
|
Modules de la série CEF720 avec DFC3 (6704 avec DFC3, 6708 avec DFC3, 6748 avec DFC3 6724 + DFC3) |
Soutenir jusqu’à 48 mpps (par emplacement) |
2×20 G (dédié par emplacement) |
Bien que le 6513 puisse être une solution valable pour la couche d’accès du modèle de grand cluster, notez qu’il existe un mélange d’emplacements à canal unique et double dans ce châssis. Les fentes 1 à 8 sont à canal unique et les fentes 9 à 13 sont à canal double, comme le montre la figure 3-1.
Figure 3-1 Canaux de matrice Catalyst 6500 par châssis et fente (Focus 6513
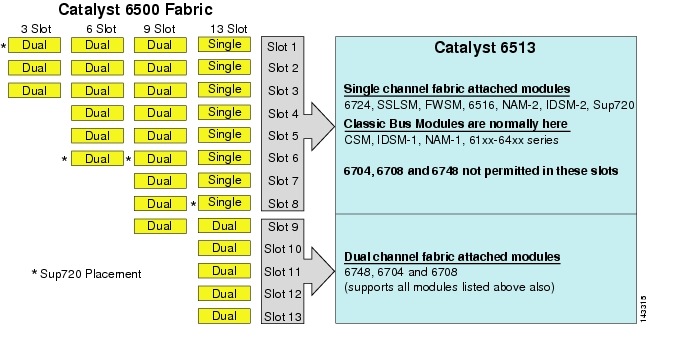
Lorsqu’un Cisco Catalyst 6513 est utilisé, les cartes à double canal, telles que le port 6704-4 10GigE, le port 6708-8 10GigE et les cartes de ligne SFP / cuivre 6748-48 peuvent être placées uniquement dans les emplacements 9 à 13. Les cartes de lignes à canal unique telles que les cartes de lignes SFP / cuivre 6724-24 ports peuvent être utilisées dans les emplacements 1 à 8. Le Sup720 utilise des fentes 7 et 8, qui sont attachées en tissu 20G à canal unique. Contrairement au 6513, le 6509 a moins d’emplacements disponibles mais peut prendre en charge des modules à deux canaux dans tous les emplacements car chaque emplacement a deux canaux vers la matrice de commutation.
Note ![]() Étant donné que l’environnement de cluster de serveurs nécessite généralement une bande passante élevée avec des caractéristiques de faible latence, nous recommandons d’utiliser des DFC dans ces types de conceptions.
Étant donné que l’environnement de cluster de serveurs nécessite généralement une bande passante élevée avec des caractéristiques de faible latence, nous recommandons d’utiliser des DFC dans ces types de conceptions.
Routage multi-chemins à coût égal
Le routage multi-chemins à coût égal (ECMP) est une technologie d’équilibrage de charge qui optimise les flux sur plusieurs chemins IP entre deux sous-réseaux quelconques dans un environnement compatible Cisco Express Forwarding. ECMP applique l’équilibrage de charge pour les paquets TCP et UDP par flux. Les paquets non TCP/UDP, tels que ICMP, sont distribués paquet par paquet. ECMP est basé sur la RFC 2991 et est utilisé sur d’autres plates-formes Cisco, telles que les produits PIX et Cisco Content Services Switch (CSS). ECMP est pris en charge sur les plates-formes 6500 et 4948-10GE recommandées dans la conception du cluster de serveurs.
Les changements spectaculaires résultant des algorithmes de hachage ASIC de matériel de commutation de couche 3 et de Cisco Express Forwarding aident à distinguer l’ECMP de ses technologies prédécesseurs. Le principal avantage d’une conception ECMP pour les implémentations de cluster de serveurs est l’algorithme de hachage combiné avec peu ou pas de surcharge CPU dans la commutation de couche 3. L’algorithme de hachage Cisco Express Forwarding est capable de distribuer des flux granulaires sur plusieurs cartes de lignes au débit de ligne dans le matériel. Le paramètre par défaut de l’algorithme de hachage consiste à hacher les flux en fonction des adresses IP source-destination de la couche 3 et à ajouter éventuellement des numéros de port de la couche 4 pour une couche supplémentaire de différenciation. Le nombre maximum de chemins ECMP autorisés est de huit.
La figure 3-2 illustre une conception de cluster de serveurs ECMP à 8 voies. Pour simplifier l’illustration, seuls deux commutateurs de couche d’accès sont affichés, mais jusqu’à 32 peuvent être pris en charge (64 10GigEs par nœud principal).
Figure 3-2 Conception de cluster de serveurs ECMP 8 voies
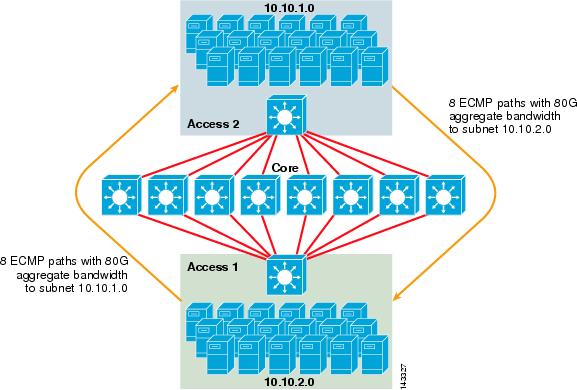
Dans la figure 3-2, chaque commutateur de couche d’accès peut prendre en charge un ou plusieurs sous-réseaux de serveurs attachés. Chaque commutateur a une seule connexion 10GigE à chacun des huit commutateurs principaux à l’aide de deux cartes de lignes 6704. Cette configuration fournit huit chemins de 10GigE pour un total de 80 G de bande passante compatible Cisco Express Forwarding vers tout autre sous-réseau de la matrice de cluster de serveurs. Une requête show ip route vers un autre sous-réseau sur un autre commutateur affiche huit entrées à coût égal.
Le noyau est rempli de cartes de lignes 10GigE avec DFC pour permettre une matrice de commutation haute vitesse entièrement distribuée avec une latence de port à port très faible. Une requête show ip route vers un commutateur de couche d’accès affiche une seule entrée de route sur chacun des huit commutateurs principaux.
Note ![]() Bien qu’il n’ait pas été testé pour ce guide, un nouveau module Ethernet 10 Gigabits à 8 ports (WS-X6708-10G-3C) a récemment été introduit pour le commutateur de la série Catalyst 6500. Cette carte de ligne sera testée pour être incluse dans ce guide à une date ultérieure. Pour des questions sur la carte 10GigE à 8 ports, reportez-vous à la fiche technique du produit.
Bien qu’il n’ait pas été testé pour ce guide, un nouveau module Ethernet 10 Gigabits à 8 ports (WS-X6708-10G-3C) a récemment été introduit pour le commutateur de la série Catalyst 6500. Cette carte de ligne sera testée pour être incluse dans ce guide à une date ultérieure. Pour des questions sur la carte 10GigE à 8 ports, reportez-vous à la fiche technique du produit.
Redondance dans la conception du cluster de serveurs
La conception du cluster de serveurs n’est généralement pas implémentée avec des processeurs CPU redondants ou des processeurs de matrice de commutation. La résilience est généralement obtenue de manière inhérente dans la conception et par la méthode le cluster fonctionne dans son ensemble. Comme décrit au chapitre 1 » Vue d’ensemble de l’architecture du centre de données « , les nœuds de calcul du cluster sont gérés par des nœuds maîtres chargés d’attribuer des tâches spécifiques à chaque nœud de calcul et de surveiller leurs performances. Si un nœud de calcul quitte le cluster, il est réaffecté à un nœud disponible et continue de fonctionner, bien qu’avec moins de puissance de traitement, jusqu’à ce que le nœud soit disponible. Bien qu’il soit important de diversifier les connexions de nœuds maîtres dans le cluster entre différents commutateurs d’accès, cela n’est pas critique pour les nœuds de calcul.
Bien que les PROCESSEURS redondants soient certainement optionnels, il est important de considérer la densité de ports, en particulier en ce qui concerne les ports 10GE, où un slot supplémentaire est disponible à la place d’un module Sup720 redondant.
Note ![]() Les exemples de ce chapitre utilisent des conceptions CPU non redondantes, qui permettent un maximum de 64 ports 10GE par nœud central 6509 disponibles pour les connexions de liaison montante du nœud d’accès basées sur l’utilisation d’une carte de ligne 10GigE 6708 à 8 ports.
Les exemples de ce chapitre utilisent des conceptions CPU non redondantes, qui permettent un maximum de 64 ports 10GE par nœud central 6509 disponibles pour les connexions de liaison montante du nœud d’accès basées sur l’utilisation d’une carte de ligne 10GigE 6708 à 8 ports.
Conception de cluster de serveurs – Modèle à deux niveaux
Cette section décrit les différentes approches d’une conception de cluster de serveurs qui exploite ECMP et CEF distribué. Chaque conception montre comment différentes configurations peuvent atteindre différents niveaux de sursouscription et peuvent évoluer de manière flexible, en commençant par quelques nœuds et en augmentant jusqu’à plusieurs qui prennent en charge des milliers de serveurs.
La conception du cluster de serveurs suit généralement un modèle à deux niveaux composé de couches core et access. Étant donné que les objectifs de conception nécessitent l’utilisation de l’ECMP de couche 3 et du transfert distribué pour obtenir une bande passante et une latence hautement déterministes par serveur, un modèle à trois niveaux qui introduit un autre point de sursouscription n’est généralement pas souhaitable. Les avantages d’un modèle à trois niveaux sont décrits dans Conception de cluster de serveurs – Modèle à trois niveaux.
Les trois calculs principaux à prendre en compte lors de la conception d’une solution de cluster de serveurs sont les connexions de serveur maximales, la bande passante par serveur et le ratio de surabonnement. Les concepteurs de cluster peuvent déterminer ces valeurs en fonction des performances de l’application, du matériel du serveur et d’autres facteurs, notamment les suivants:
•![]() Nombre maximal de connexions GigE de serveur à l’échelle – Les concepteurs de clusters ont généralement une idée de l’échelle maximale requise lors du concept initial. Un avantage de la façon dont les conceptions ECMP fonctionnent est qu’elles peuvent commencer avec un nombre minimum de commutateurs et de serveurs qui répondent à une exigence particulière de bande passante, de latence et de sursouscription, et croître de manière flexible de manière faible / non perturbatrice jusqu’à une échelle maximale tout en conservant les mêmes valeurs de bande passante, de latence et de sursouscription.
Nombre maximal de connexions GigE de serveur à l’échelle – Les concepteurs de clusters ont généralement une idée de l’échelle maximale requise lors du concept initial. Un avantage de la façon dont les conceptions ECMP fonctionnent est qu’elles peuvent commencer avec un nombre minimum de commutateurs et de serveurs qui répondent à une exigence particulière de bande passante, de latence et de sursouscription, et croître de manière flexible de manière faible / non perturbatrice jusqu’à une échelle maximale tout en conservant les mêmes valeurs de bande passante, de latence et de sursouscription.
•![]() Bande passante approximative par serveur — Cette valeur peut être déterminée en divisant simplement la bande passante totale agrégée de liaison montante par les connexions GigE totales du serveur sur le commutateur de couche d’accès. Par exemple, une couche d’accès Cisco 6509 avec quatre liaisons montantes ECMP 10GigE avec 336 ports d’accès au serveur peut être calculée comme suit :
Bande passante approximative par serveur — Cette valeur peut être déterminée en divisant simplement la bande passante totale agrégée de liaison montante par les connexions GigE totales du serveur sur le commutateur de couche d’accès. Par exemple, une couche d’accès Cisco 6509 avec quatre liaisons montantes ECMP 10GigE avec 336 ports d’accès au serveur peut être calculée comme suit :
Liaisons montantes 4x10GigE avec 336 serveurs = 120 Mbps par serveur
L’ajustement de chaque côté de l’équation diminue ou augmente la quantité de bande passante par serveur.
Note ![]() Ceci n’est qu’une valeur approximative et ne sert qu’à titre indicatif. Divers facteurs influencent la quantité réelle de bande passante disponible pour chaque serveur. L’algorithme de hachage de distribution de charge ECMP divise la charge en fonction des valeurs de la couche 3 et de la couche 4 et varie en fonction des modèles de trafic. En outre, des paramètres de configuration tels que la limitation de débit, la mise en file d’attente et les valeurs de QoS peuvent influencer la bande passante réelle obtenue par serveur.
Ceci n’est qu’une valeur approximative et ne sert qu’à titre indicatif. Divers facteurs influencent la quantité réelle de bande passante disponible pour chaque serveur. L’algorithme de hachage de distribution de charge ECMP divise la charge en fonction des valeurs de la couche 3 et de la couche 4 et varie en fonction des modèles de trafic. En outre, des paramètres de configuration tels que la limitation de débit, la mise en file d’attente et les valeurs de QoS peuvent influencer la bande passante réelle obtenue par serveur.
•![]() Rapport de surabonnement par serveur — Cette valeur peut être déterminée en divisant simplement le nombre total de connexions GigE de serveur par la bande passante totale agrégée de liaison montante sur le commutateur de couche d’accès. Par exemple, une couche d’accès 6509 avec quatre liaisons montantes ECMP 10GigE avec 336 ports d’accès au serveur peut être calculée comme suit :
Rapport de surabonnement par serveur — Cette valeur peut être déterminée en divisant simplement le nombre total de connexions GigE de serveur par la bande passante totale agrégée de liaison montante sur le commutateur de couche d’accès. Par exemple, une couche d’accès 6509 avec quatre liaisons montantes ECMP 10GigE avec 336 ports d’accès au serveur peut être calculée comme suit :
336 connexions de serveur GigE avec une bande passante de liaison montante 40G = 8,4:1 rapport de surabonnement
Les sections suivantes montrent comment ces valeurs varient, en fonction de différentes configurations matérielles et d’interconnexion, et servent de ligne directrice lors de la conception de configurations de cluster de grande taille.
Note ![]() À des fins de calcul, on suppose qu’il n’y a pas de carte de ligne pour commuter la sursouscription de la matrice sur le commutateur de la série Catalyst 6500. L’emplacement à double canal fournit une bande passante maximale de 40 G à la matrice de commutation. Une carte 10GigE à 4 ports avec tous les ports au débit ligne en utilisant des paquets de taille maximale est considérée comme la meilleure condition possible avec peu ou pas de sursouscription. La quantité réelle de bande passante de la matrice de commutation disponible varie, en fonction de la taille moyenne des paquets. Ces calculs devraient être recalculés si vous deviez utiliser la carte 10GigE 8 ports WS-X6708 qui est sursouscrite à 2:1.
À des fins de calcul, on suppose qu’il n’y a pas de carte de ligne pour commuter la sursouscription de la matrice sur le commutateur de la série Catalyst 6500. L’emplacement à double canal fournit une bande passante maximale de 40 G à la matrice de commutation. Une carte 10GigE à 4 ports avec tous les ports au débit ligne en utilisant des paquets de taille maximale est considérée comme la meilleure condition possible avec peu ou pas de sursouscription. La quantité réelle de bande passante de la matrice de commutation disponible varie, en fonction de la taille moyenne des paquets. Ces calculs devraient être recalculés si vous deviez utiliser la carte 10GigE 8 ports WS-X6708 qui est sursouscrite à 2:1.
Conceptions ECMP à 4 et 8 voies avec accès modulaire
Les quatre exemples de conception suivants illustrent diverses méthodes de création et de mise à l’échelle du modèle de cluster de serveurs à deux niveaux à l’aide d’ECMP à 4 et 8 voies. Les principaux problèmes à considérer sont le nombre de nœuds principaux et le nombre maximal de liaisons montantes, car ceux-ci influencent directement l’échelle maximale, la bande passante par serveur et les valeurs de sursouscription.
Note ![]() Bien qu’il n’ait pas été testé pour ce guide, un nouveau module Ethernet 10 Gigabit à 8 ports (WS-X6708-10G-3C) a récemment été introduit pour le commutateur de la série Catalyst 6500. Cette carte de ligne sera testée pour être incluse dans le guide à une date ultérieure. Pour des questions sur la carte 10GigE à 8 ports, reportez-vous à la fiche technique du produit.
Bien qu’il n’ait pas été testé pour ce guide, un nouveau module Ethernet 10 Gigabit à 8 ports (WS-X6708-10G-3C) a récemment été introduit pour le commutateur de la série Catalyst 6500. Cette carte de ligne sera testée pour être incluse dans le guide à une date ultérieure. Pour des questions sur la carte 10GigE à 8 ports, reportez-vous à la fiche technique du produit.
Note ![]() Les liens nécessaires pour connecter le cluster de serveurs à un réseau de campus ou de métro extérieur ne sont pas indiqués dans ces exemples de conception, mais doivent être pris en compte.
Les liens nécessaires pour connecter le cluster de serveurs à un réseau de campus ou de métro extérieur ne sont pas indiqués dans ces exemples de conception, mais doivent être pris en compte.
La figure 3-3 fournit un exemple dans lequel deux nœuds principaux sont utilisés pour fournir une solution ECMP à 4 voies.
Figure 3-3 ECMP à 4 voies utilisant deux nœuds principaux
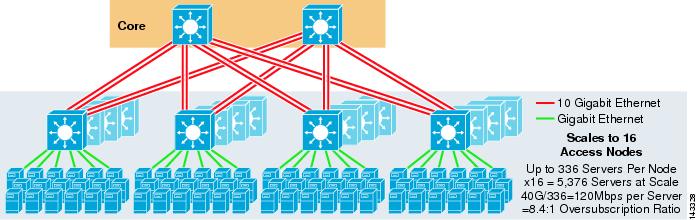
Un avantage de cette approche est qu’un plus petit nombre de commutateurs principaux peut prendre en charge un grand nombre de serveurs. L’inconvénient possible est une sursouscription élevée – une faible bande passante par valeur de serveur et une exposition importante à une défaillance d’un nœud central. Notez que les liaisons montantes sont des liaisons montantes L3 individuelles et ne sont pas des EtherChannels.
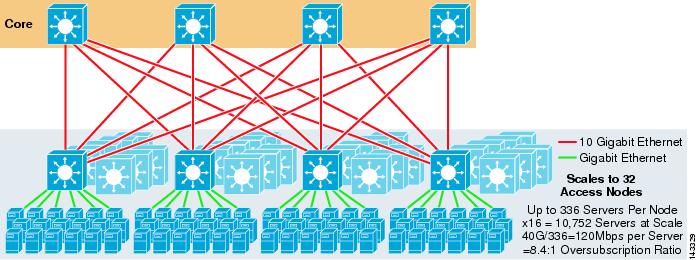
La figure 3-4 montre comment l’ajout de deux nœuds principaux à la conception précédente peut augmenter considérablement l’échelle maximale tout en conservant les mêmes valeurs de sursouscription et de bande passante par serveur.
Figure 3-4 ECMP à 4 voies utilisant quatre nœuds principaux
La figure 3-5 montre une conception ECMP à 8 voies utilisant deux nœuds principaux.
Figure 3-5 ECMP 8 voies utilisant deux nœuds principaux
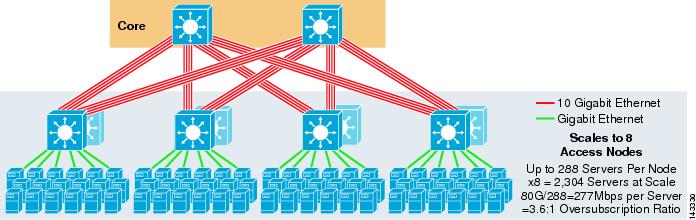
Comme prévu, la bande passante de liaison montante supplémentaire augmente considérablement la bande passante par serveur et réduit le ratio de sursouscription par serveur. Notez comment les emplacements supplémentaires pris dans chaque commutateur de couche d’accès pour prendre en charge les liaisons montantes à 8 voies réduisent l’échelle maximale car le nombre de serveurs par commutateur est réduit à 288. Notez que les liaisons montantes sont des liaisons montantes L3 individuelles et ne sont pas des EtherChannels.
La figure 3-6 montre une conception ECMP à 8 voies avec huit nœuds principaux.
Figure 3-6 ECMP 8 voies utilisant huit nœuds principaux
Cela montre comment l’ajout de quatre nœuds principaux à la même conception précédente peut augmenter considérablement l’échelle maximale tout en conservant les mêmes valeurs de sursouscription et de bande passante par serveur.
Conception ECMP 2 voies avec accès 1RU
Dans de nombreux environnements de cluster, la commutation de serveur en rack à l’aide de petits commutateurs en haut de chaque rack de serveur est souhaitée ou requise en raison de problèmes de câblage, d’administration, d’immobilier ou pour répondre à des objectifs particuliers de modèle de déploiement.
La figure 3-7 montre un exemple dans lequel deux nœuds principaux sont utilisés pour fournir une solution ECMP à 2 voies avec des commutateurs d’accès 1RU 4948-10GE.
Figure 3-7 ECMP 2 voies utilisant deux nœuds principaux et un accès 1RU
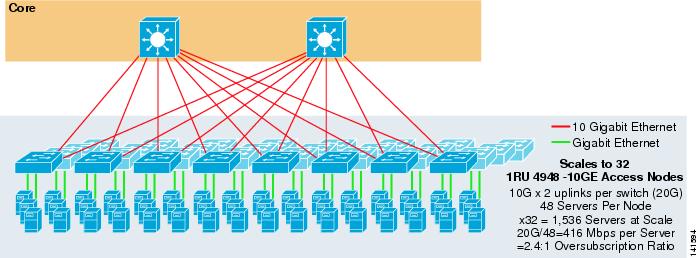
L’échelle maximale est limitée à 1536 serveurs mais fournit plus de 400 Mbps de bande passante avec un faible taux de sursouscription. Comme le 4948 n’a que deux liaisons montantes 10GigE, cette conception ne peut pas évoluer au-delà de ces valeurs.
Note ![]() Plus d’informations sur la commutation de serveur en rack sont fournies dans le chapitre 3 » Conceptions de cluster de serveurs avec Ethernet. »
Plus d’informations sur la commutation de serveur en rack sont fournies dans le chapitre 3 » Conceptions de cluster de serveurs avec Ethernet. »
Conception de cluster de serveurs – Modèle à trois niveaux
Bien qu’un modèle à deux niveaux soit le plus courant dans les conceptions de grands clusters, un modèle à trois niveaux peut également être utilisé. Le modèle à trois niveaux est généralement utilisé pour prendre en charge les implémentations de grappes de serveurs de grande taille à l’aide de commutateurs 1RU ou de couches d’accès modulaires.
La figure 3-8 montre un exemple à grande échelle exploitant l’ECMP à 8 voies avec 6500 commutateurs de base et d’agrégation et des commutateurs de couche d’accès 1RU 4948-10GE.
Figure 3-8 Modèle à trois niveaux avec ECMP à 8 voies
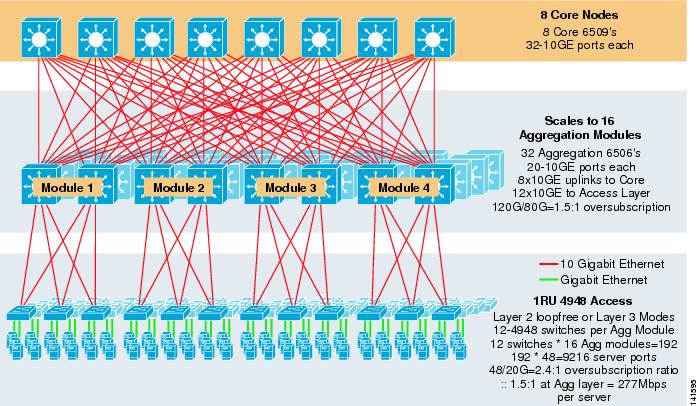
L’échelle maximale est supérieure à 9200 serveurs avec une bande passante de 277 Mbps avec un faible taux de sursouscription. Les avantages de l’approche à trois niveaux utilisant des commutateurs d’accès 1RU sont les suivants:
•![]() Modèles de déploiement 1RU – Comme mentionné précédemment, de nombreux déploiements de modèles de cluster de grande taille nécessitent une approche 1RU pour une installation simplifiée. Par exemple, un ASP déploie des racks de serveurs à la fois lorsqu’il met à l’échelle de grandes applications de cluster. Le rack de serveur est pré-assemblé et mis en scène hors site de sorte qu’il puisse être rapidement installé et ajouté au cluster en cours d’exécution. Cela implique généralement un tiers qui construit les racks, pré-configure les serveurs et les pré-câble avec alimentation et Ethernet à un commutateur 1RU. Le rack roule dans le centre de données et est simplement branché et ajouté au cluster après la connexion des liaisons montantes.
Modèles de déploiement 1RU – Comme mentionné précédemment, de nombreux déploiements de modèles de cluster de grande taille nécessitent une approche 1RU pour une installation simplifiée. Par exemple, un ASP déploie des racks de serveurs à la fois lorsqu’il met à l’échelle de grandes applications de cluster. Le rack de serveur est pré-assemblé et mis en scène hors site de sorte qu’il puisse être rapidement installé et ajouté au cluster en cours d’exécution. Cela implique généralement un tiers qui construit les racks, pré-configure les serveurs et les pré-câble avec alimentation et Ethernet à un commutateur 1RU. Le rack roule dans le centre de données et est simplement branché et ajouté au cluster après la connexion des liaisons montantes.
Sans couche d’agrégation, la taille maximale du modèle d’accès 1RU est limitée à un peu plus de 1500 serveurs. L’ajout d’une couche d’agrégation permet au modèle d’accès 1RU de prendre une taille beaucoup plus grande tout en tirant parti du modèle ECMP.
•![]() Centralisation des commutateurs de base et d’agrégation – Avec les commutateurs 1RU déployés dans les racks, il est possible de centraliser les commutateurs modulaires de base et d’agrégation plus grands. Cela peut simplifier l’infrastructure d’alimentation et de câblage et améliorer l’utilisation de l’immobilier en rack.
Centralisation des commutateurs de base et d’agrégation – Avec les commutateurs 1RU déployés dans les racks, il est possible de centraliser les commutateurs modulaires de base et d’agrégation plus grands. Cela peut simplifier l’infrastructure d’alimentation et de câblage et améliorer l’utilisation de l’immobilier en rack.
•![]() Permet une topologie sans boucle de couche 2 – Un grand réseau de cluster utilisant un accès ECMP de couche 3 peut utiliser beaucoup d’espace d’adressage sur les liaisons montantes et peut ajouter de la complexité à la conception. Ceci est particulièrement important si l’espace public est utilisé. L’approche du modèle à trois niveaux se prête bien à une topologie d’accès sans boucle de couche 2 qui réduit le nombre de sous-réseaux requis.
Permet une topologie sans boucle de couche 2 – Un grand réseau de cluster utilisant un accès ECMP de couche 3 peut utiliser beaucoup d’espace d’adressage sur les liaisons montantes et peut ajouter de la complexité à la conception. Ceci est particulièrement important si l’espace public est utilisé. L’approche du modèle à trois niveaux se prête bien à une topologie d’accès sans boucle de couche 2 qui réduit le nombre de sous-réseaux requis.
Lorsqu’un modèle sans boucle de couche 2 est utilisé, il est important d’utiliser un protocole de passerelle par défaut redondant tel que HSRP ou GLBP pour éliminer un point de défaillance unique en cas de défaillance d’un nœud d’agrégation. Dans cette conception, les modules d’agrégation ne sont pas interconnectés, ce qui permet une conception de couche 2 sans boucle pouvant tirer parti du GLBP pour l’équilibrage de charge automatique de la passerelle par défaut du serveur. GLBP distribue automatiquement l’affectation de passerelle par défaut des serveurs entre les deux nœuds du module d’agrégation. Une fois qu’un paquet arrive à la couche d’agrégation, il est équilibré dans le cœur à l’aide de la matrice ECMP à 8 voies. Bien que GLBP ne fournisse pas de hachage de distribution de charge de couche 3 / couche 4 similaire à CEF, c’est une alternative qui peut être utilisée avec une topologie d’accès de couche 2.
Calcul de la sursouscription
Le modèle à trois niveaux introduit deux points de sursouscription aux couches d’accès et d’agrégation, par rapport au modèle à deux niveaux qui n’a qu’un seul point de sursouscription à la couche d’accès. Pour calculer correctement la bande passante approximative par serveur et le rapport de sursouscription, effectuez les deux étapes suivantes, qui utilisent la figure 3-8 à titre d’exemple :
Étape 1 ![]() Calculez indépendamment le rapport de sursouscription et la bande passante par serveur pour les couches d’agrégation et d’accès.
Calculez indépendamment le rapport de sursouscription et la bande passante par serveur pour les couches d’agrégation et d’accès.
•![]() Couche d’accès
Couche d’accès
–![]() Oversubscription – Serveurs attachés 48GE / liaisons montantes 20G vers l’agrégation = 2.4:1
Oversubscription – Serveurs attachés 48GE / liaisons montantes 20G vers l’agrégation = 2.4:1
–![]() Bande passante par serveur – 20G de liaisons montantes vers l’agrégation / 48GIGE serveurs attachés = 416Mbps
Bande passante par serveur – 20G de liaisons montantes vers l’agrégation / 48GIGE serveurs attachés = 416Mbps
•![]() Couche d’agrégation
Couche d’agrégation
–![]() Oversubscription – 120G de liaisons descendantes pour accéder / 80G de liaisons montantes vers le cœur = 1.5:1
Oversubscription – 120G de liaisons descendantes pour accéder / 80G de liaisons montantes vers le cœur = 1.5:1
Étape 2 ![]() Calculez le rapport de sursouscription combiné et la bande passante par serveur.
Calculez le rapport de sursouscription combiné et la bande passante par serveur.
Le rapport de sursouscription réel est la somme des deux points de sursouscription aux couches d’accès et d’agrégation.
1.5*2.4 = 3.6:1
Pour déterminer la bande passante réelle par valeur de serveur, utilisez la formule algébrique pour les proportions :
a:b = c: d
La bande passante par serveur au niveau de la couche d’accès a été déterminée comme étant de 416 Mbps par serveur. Étant donné que le rapport de sursouscription de la couche d’agrégation est de 1,5:1, vous pouvez appliquer la formule ci-dessus comme suit:
416:1 = x: 1.5
x = ~ 264 Mbps par serveur
Matériel et modules recommandés
Les plates-formes recommandées pour la conception du modèle de cluster de serveurs sont constituées de la famille Cisco Catalyst 6500 avec le module de processeur Sup720 et le commutateur Catalyst 4948-10GE 1RU. Le taux de commutation élevé, la grande structure de commutation, la faible latence, le transfert distribué et la densité de 10 GigE font du commutateur de la série Catalyst 6500 l’idéal pour toutes les couches de ce modèle. Le facteur de forme 1RU combiné au transfert de débit de fil, aux liaisons montantes 10GE et à une latence constante très faible fait du 4948-10GE une excellente solution de haut de gamme pour la couche d’accès.
Les éléments suivants sont recommandés:
•![]() Sup720 – Le Sup720 peut être constitué à la fois de cartes filles de type PFC3A (par défaut) ou de cartes filles de type PFC3B plus récentes.
Sup720 – Le Sup720 peut être constitué à la fois de cartes filles de type PFC3A (par défaut) ou de cartes filles de type PFC3B plus récentes.
•![]() Linecards – Tous les linecards doivent être de la série 6700 et doivent tous être activés pour le transfert distribué avec les cartes filles DFC3A ou DFC3B.
Linecards – Tous les linecards doivent être de la série 6700 et doivent tous être activés pour le transfert distribué avec les cartes filles DFC3A ou DFC3B.
Note ![]() En utilisant tous les modules de la série CEF720 connectés en tissu, le mode de commutation global est compact, ce qui permet au système de fonctionner à son niveau de performance le plus élevé. Le Catalyst 6509 peut prendre en charge 10 modules GigE dans toutes les positions car chaque emplacement prend en charge deux canaux vers la matrice de commutation (le Cisco Catalyst 6513 ne prend pas en charge cela).
En utilisant tous les modules de la série CEF720 connectés en tissu, le mode de commutation global est compact, ce qui permet au système de fonctionner à son niveau de performance le plus élevé. Le Catalyst 6509 peut prendre en charge 10 modules GigE dans toutes les positions car chaque emplacement prend en charge deux canaux vers la matrice de commutation (le Cisco Catalyst 6513 ne prend pas en charge cela).
•![]() Cisco Catalyst 4948-10GE — Le 4948-10GE fournit une solution de couche d’accès haute performance qui peut tirer parti des liaisons ascendantes ECMP et 10GigE. Aucune exigence particulière n’est nécessaire. Le 4948-10GE peut utiliser une image Cisco IOS de couche 2 ou une image Cisco IOS de couche 2/3, permettant un ajustement optimal dans l’un ou l’autre environnement.
Cisco Catalyst 4948-10GE — Le 4948-10GE fournit une solution de couche d’accès haute performance qui peut tirer parti des liaisons ascendantes ECMP et 10GigE. Aucune exigence particulière n’est nécessaire. Le 4948-10GE peut utiliser une image Cisco IOS de couche 2 ou une image Cisco IOS de couche 2/3, permettant un ajustement optimal dans l’un ou l’autre environnement.