Amazon MTurk
Vous allez probablement nettoyer votre ensemble de données, par exemple en fonction des éléments de réponse instruits (très bons), des éléments faux (également bons) et / ou des temps de réponse (équitables, envisagez d’utiliser TIME_RSI).
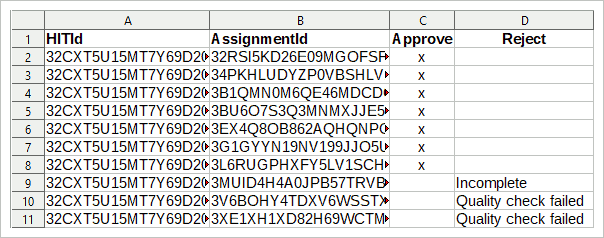
Vous avez les ID de travail de tous les enregistrements restants qui sont conformes à vos critères de qualité. Bien sûr, vous pouvez vérifier toutes les affectations dans MTurk manuellement, mais cela prend beaucoup de temps. Mieux vaut travailler avec un fichier CSV.
Pour le fichier CSV, vous avez besoin de l’ID d’accès et de l’ID d’affectation. Si vous avez suivi le manuel ci-dessus, vous aurez ces données disponibles. Ensuite, créez une table (avec R, SPSS, LibreOffice Calc, Excel, Excel) avec trois colonnes à partir de vos données: La première colonne contient l’ID de HIT, la deuxième colonne contient l’ID d’affectation et la troisième colonne doit contenir un « x » pour chaque entrée.
La première ligne de la table est l’en-tête, les noms de variables. Assurez-vous que les noms de variables sont les suivants (sensibles à la casse):
-
HITId
-
Assignentid
-
Approuver
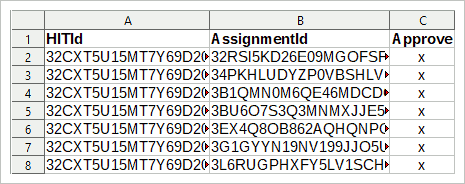
, stockez ensuite la table en tant que fichier CSV et dans MTurk → Gérer → Examiner les résultats, cliquez sur le bouton Télécharger CSV. Sélectionnez le CSV nouvellement enregistré et confirmez. MTurk vous demandera alors d’accepter ou non ces missions.
Lorsque vous avez terminé, il ne restera que les affectations qui ne correspondent pas à vos critères de qualité. Rejetez-les en expliquant pourquoi.
Sinon, ne supprimez pas les enregistrements immédiatement pendant le nettoyage des données, mais marquez-les. Vous pouvez ensuite télécharger un fichier CSV avec quatre colonnes, la quatrième nommée « Rejeter » et avec une explication du rejet dans la colonne. Cela garantira que vous ne rejetez personne dont l’identité s’est perdue.