




Guía de diseño de Infraestructura de centro de datos de Cisco 2.5
Diseños de clúster de servidores con Ethernet
En el Capítulo 1 «Descripción general de la arquitectura del centro de datos» se proporciona una descripción general de alto nivel de los servidores y componentes de red utilizados en el modelo de clúster de servidores.»Este capítulo describe con mayor detalle el propósito y la función de cada capa del modelo de clúster de servidores. Se incluyen las siguientes secciones:
•![]() Objetivos Técnicos
Objetivos Técnicos
•![]() Reenvío Distribuido y Latencia
Reenvío Distribuido y Latencia
•![]() Enrutamiento de Múltiples Rutas de Igual Costo
Enrutamiento de Múltiples Rutas de Igual Costo
•![]() Diseño de Clúster de Servidores: Modelo de Dos Niveles
Diseño de Clúster de Servidores: Modelo de Dos Niveles
•![]() Diseño de Clúster de Servidores: Modelo de Tres Niveles
Diseño de Clúster de Servidores: Modelo de Tres Niveles
•![]() Hardware y módulos recomendados
Hardware y módulos recomendados

Nota ![]() Los modelos de diseño cubiertos en este capítulo no se han verificado completamente en las pruebas de laboratorio de Cisco debido al tamaño y el alcance de las pruebas que se requerirían. Los modelos de dos niveles cubiertos son diseños similares que se han implementado en redes de producción de clientes.
Los modelos de diseño cubiertos en este capítulo no se han verificado completamente en las pruebas de laboratorio de Cisco debido al tamaño y el alcance de las pruebas que se requerirían. Los modelos de dos niveles cubiertos son diseños similares que se han implementado en redes de producción de clientes.
Objetivos técnicos
Al diseñar una gran red de clústeres empresariales, es fundamental tener en cuenta objetivos específicos. No hay dos clústeres exactamente iguales; cada uno tiene sus propios requisitos específicos y debe examinarse desde la perspectiva de la aplicación para determinar los requisitos de diseño particulares. Tenga en cuenta las siguientes consideraciones técnicas:
•![]() Latencia: En el transporte de red, la latencia puede afectar negativamente al rendimiento general del clúster. El uso de plataformas de conmutación que emplean una arquitectura de conmutación de baja latencia ayuda a garantizar un rendimiento óptimo. La principal fuente de latencia es la pila de protocolos y la implementación de hardware de NIC que se utiliza en el servidor. Las técnicas de optimización de controladores y descarga de CPU, como el Motor de descarga TCP (TOE) y el Acceso Remoto Directo a la Memoria (RDMA), pueden ayudar a disminuir la latencia y reducir la sobrecarga de procesamiento en el servidor.
Latencia: En el transporte de red, la latencia puede afectar negativamente al rendimiento general del clúster. El uso de plataformas de conmutación que emplean una arquitectura de conmutación de baja latencia ayuda a garantizar un rendimiento óptimo. La principal fuente de latencia es la pila de protocolos y la implementación de hardware de NIC que se utiliza en el servidor. Las técnicas de optimización de controladores y descarga de CPU, como el Motor de descarga TCP (TOE) y el Acceso Remoto Directo a la Memoria (RDMA), pueden ayudar a disminuir la latencia y reducir la sobrecarga de procesamiento en el servidor.
La latencia puede no ser siempre un factor crítico en el diseño del clúster. Por ejemplo, algunos clústeres pueden requerir un gran ancho de banda entre servidores debido a una gran cantidad de transferencia de archivos en masa, pero es posible que no dependan en gran medida de la mensajería de Comunicación entre Procesos (IPC) de servidor a servidor, que puede verse afectada por una alta latencia.
•![]() Conectividad de malla / malla parcial: Los diseños de clúster de servidores generalmente requieren una malla o tejido de malla parcial para permitir la comunicación entre todos los nodos del clúster. Esta estructura de malla se utiliza para compartir estado, datos y otra información entre servidores maestro a procesamiento y de cómputo a cómputo en el clúster. La conectividad de malla o malla parcial también depende de la aplicación.
Conectividad de malla / malla parcial: Los diseños de clúster de servidores generalmente requieren una malla o tejido de malla parcial para permitir la comunicación entre todos los nodos del clúster. Esta estructura de malla se utiliza para compartir estado, datos y otra información entre servidores maestro a procesamiento y de cómputo a cómputo en el clúster. La conectividad de malla o malla parcial también depende de la aplicación.
•![]() Alto rendimiento: la capacidad de enviar un archivo grande en un período de tiempo específico puede ser fundamental para el funcionamiento y el rendimiento del clúster. Los clústeres de servidores suelen requerir una cantidad mínima de ancho de banda sin bloqueo disponible, lo que se traduce en un modelo de baja sobreescritura entre las capas de acceso y núcleo.
Alto rendimiento: la capacidad de enviar un archivo grande en un período de tiempo específico puede ser fundamental para el funcionamiento y el rendimiento del clúster. Los clústeres de servidores suelen requerir una cantidad mínima de ancho de banda sin bloqueo disponible, lo que se traduce en un modelo de baja sobreescritura entre las capas de acceso y núcleo.
•![]() Relación de sobresubscripción: la relación de sobresubscripción se debe examinar en varios puntos de agregación en el diseño, incluida la tarjeta de línea para cambiar el ancho de banda de tejido y la entrada de tejido de conmutación al ancho de banda de enlace ascendente.
Relación de sobresubscripción: la relación de sobresubscripción se debe examinar en varios puntos de agregación en el diseño, incluida la tarjeta de línea para cambiar el ancho de banda de tejido y la entrada de tejido de conmutación al ancho de banda de enlace ascendente.
•![]() Compatibilidad con marcos jumbo: Aunque es posible que no se utilicen marcos jumbo en la implementación inicial de un clúster de servidores, es una característica muy importante que es necesaria para una flexibilidad adicional o para posibles requisitos futuros. La construcción de paquetes TCP/IP coloca una sobrecarga adicional en la CPU del servidor. El uso de marcos jumbo puede reducir el número de paquetes, reduciendo así esta sobrecarga.
Compatibilidad con marcos jumbo: Aunque es posible que no se utilicen marcos jumbo en la implementación inicial de un clúster de servidores, es una característica muy importante que es necesaria para una flexibilidad adicional o para posibles requisitos futuros. La construcción de paquetes TCP/IP coloca una sobrecarga adicional en la CPU del servidor. El uso de marcos jumbo puede reducir el número de paquetes, reduciendo así esta sobrecarga.
•![]() Densidad de puertos: es posible que los clústeres de servidores necesiten escalar a decenas de miles de puertos. Como tales, requieren plataformas con un alto nivel de rendimiento de conmutación de paquetes, una gran cantidad de ancho de banda de tejido de conmutadores y un alto nivel de densidad de puertos.
Densidad de puertos: es posible que los clústeres de servidores necesiten escalar a decenas de miles de puertos. Como tales, requieren plataformas con un alto nivel de rendimiento de conmutación de paquetes, una gran cantidad de ancho de banda de tejido de conmutadores y un alto nivel de densidad de puertos.
Reenvío distribuido y latencia
El switch Cisco Catalyst Serie 6500 tiene la capacidad única de admitir un reenvío de paquetes central o una arquitectura de reenvío distribuido opcional, mientras que el Cisco Catalyst 4948-10GE es un diseño ASIC central único con rendimiento de reenvío de velocidad de línea fija. Los módulos de tarjeta de línea Cisco 6700 admiten un módulo de tarjeta hija opcional llamado Tarjeta de reenvío distribuido (DFC). El DFC permite que se tomen decisiones de enrutamiento local en cada tarjeta de línea mediante la implementación de una Base de Información de Reenvío local (FIB). La mesa de FIB del Sup720 PFC mantiene la sincronización con cada mesa de FIB DFC en las tarjetas de línea para garantizar la integridad del enrutamiento en todo el sistema.
Cuando la tarjeta DFC opcional no está presente, se envía una búsqueda compacta de encabezado al PFC3 en el Sup720 para determinar en qué parte de la estructura del conmutador se debe reenviar cada paquete. Cuando un DFC está presente, la tarjeta de línea puede cambiar un paquete directamente a través de la tela del interruptor a la tarjeta de línea de destino sin consultar el Sup720. La diferencia en el rendimiento puede ser de 30 Mpps en todo el sistema sin DFCs a 48 Mpps por ranura con DFCs. El switch Catalyst 4948-10GE de configuración fija tiene una arquitectura de velocidad de cable sin bloqueo que admite un rendimiento de hasta 101,18 Mpps, lo que proporciona un rendimiento de capa de acceso superior para los diseños de la parte superior del bastidor.
El rendimiento de latencia puede variar significativamente al comparar los modelos de reenvío distribuido y central. La tabla 3-1 proporciona un ejemplo de latencias medidas en una tarjeta de línea 6704 con y sin DFCs.
| 6704 con DFC (Puerto-a-Puerto en cuestión de Microsegundos a través de un Conmutador de Tela) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
tamaño del Paquete (B) |
||||||||||
|
Latencia (ms) |
||||||||||
| 6704 sin DFC (Puerto-a-Puerto en cuestión de Microsegundos a través de un Conmutador de Tela) | ||||||||||
|
tamaño del Paquete (B) |
||||||||||
|
Latencia (ms) |
||||||||||
La diferencia en la latencia entre un DFC-habilitado y es posible que la tarjeta de línea no habilitada para DFC no parezca significativa. Sin embargo, en una arquitectura de reenvío central 6500, la latencia puede aumentar a medida que aumentan las tasas de tráfico debido a la contención de la búsqueda compartida en el bus central. Con un DFC, la ruta de búsqueda se dedica a cada tarjeta de línea y la latencia es constante.
Ancho de banda del sistema Catalyst 6500
El ancho de banda del sistema disponible no cambia cuando se utilizan DFCs. Los DFC mejoran el procesamiento de paquetes por segundo (pps) del sistema en general. La tabla 3-2 resume el rendimiento y el ancho de banda de los módulos compatibles con DFCs, además de los módulos de bus clásicos y CEF256 más antiguos.
| Configuración del sistema con Sup720 | Rendimiento en Mpps | Ancho de banda en Gbps |
|
Módulos de la serie clásica |
Hasta 15 Mpps (por sistema) |
16 G autobús compartido (autobús clásico) |
|
Módulos de la serie CEF256 |
Hasta 30 Mpps (por sistema) |
1x 8 G (dedicado por ranura) |
|
Mezcla de módulos clásicos con la serie CEF256 o CEF720 |
Hasta 15 Mpps (por sistema) |
Dependiente de la tarjeta |
|
Módulos de la serie CEF720(6748, 6704, 6724) |
Hasta 30 Mpps (por sistema) |
2x 20 G (dedicado por ranura) |
|
Módulos de la serie CEF720 con DFC3 (6704 con DFC3, 6708 con DFC3, 6748 con DFC3 6724 + DFC3) |
Sustain hasta 48 Mpps (por ranura) |
2x 20 G (dedicado por ranura) |
Aunque el 6513 podría ser una solución válida para la capa de acceso del modelo de clúster grande, tenga en cuenta que hay una mezcla de ranuras de canal único y doble en este chasis. Las ranuras del 1 al 8 son de un solo canal y las ranuras del 9 al 13 son de dos canales, como se muestra en la Figura 3-1.
Figura 3-1 Canales de tejido Catalyst 6500 por chasis y Ranura (6513 Focus
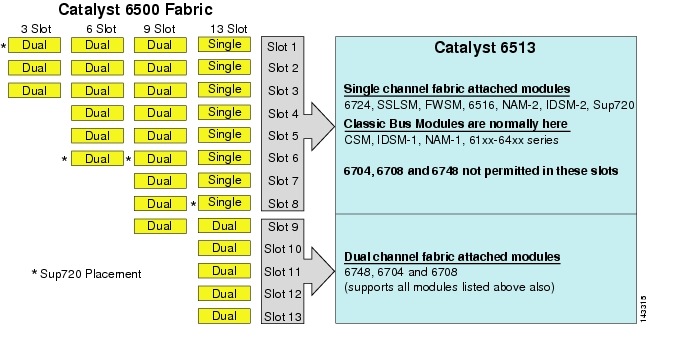
Cuando se utiliza un Cisco Catalyst 6513, las tarjetas de doble canal, como las tarjetas de línea SFP/cobre de 6704-4 puertos 10GigE, 6708-8 puertos 10GigE y 6748-48 puertos, solo se pueden colocar en las ranuras 9 a 13. Las tarjetas de línea de un solo canal, como las tarjetas de línea SFP/cobre de 6724-24 puertos, se pueden usar en las ranuras 1 a 8. El Sup720 utiliza ranuras 7 y 8, que son de tela de 20 G de un solo canal unidas. A diferencia del 6513, el 6509 tiene menos ranuras disponibles, pero puede admitir módulos de doble canal en todas las ranuras porque cada ranura tiene canales duales para la estructura del interruptor.
Nota ![]() Debido a que el entorno de clúster de servidores generalmente requiere un gran ancho de banda con características de baja latencia, recomendamos usar DFCs en este tipo de diseños.
Debido a que el entorno de clúster de servidores generalmente requiere un gran ancho de banda con características de baja latencia, recomendamos usar DFCs en este tipo de diseños.
Enrutamiento de múltiples rutas de igual costo
Enrutamiento de múltiples rutas de igual costo (ECMP) es una tecnología de equilibrio de carga que optimiza los flujos a través de múltiples rutas IP entre dos subredes cualesquiera en un entorno habilitado para reenvío Cisco Express. ECMP aplica equilibrio de carga para paquetes TCP y UDP por flujo. Los paquetes que no son TCP/UDP, como ICMP, se distribuyen paquete por paquete. ECMP se basa en el RFC 2991 y se aprovecha en otras plataformas de Cisco, como los productos PIX y Cisco Content Services Switch (CSS). ECMP es compatible con las plataformas 6500 y 4948-10GE recomendadas en el diseño del clúster de servidores.
Los cambios drásticos resultantes de los ASIC de hardware de conmutación de capa 3 y los algoritmos de hash de reenvío rápido de Cisco ayudan a distinguir ECMP de sus tecnologías predecesoras. El principal beneficio de un diseño ECMP para implementaciones de clústeres de servidores es el algoritmo de hash combinado con poca o ninguna sobrecarga de CPU en la conmutación de capa 3. El algoritmo de hash de reenvío Cisco Express es capaz de distribuir flujos granulares a través de varias tarjetas de línea a velocidad de línea en hardware. La configuración predeterminada del algoritmo de hash es flujos de hash basados en direcciones IP de origen y destino de la capa 3 y, opcionalmente, agregar números de puerto de la Capa 4 para una capa adicional de diferenciación. El número máximo de rutas ECMP permitidas es de ocho.
La figura 3-2 ilustra un diseño de clúster de servidores ECMP de 8 direcciones. Para simplificar la ilustración, solo se muestran dos conmutadores de capa de acceso, pero se pueden admitir hasta 32 (64 10GigEs por nodo central).
Figura 3-2 Diseño de clúster de servidores ECMP de 8 direcciones
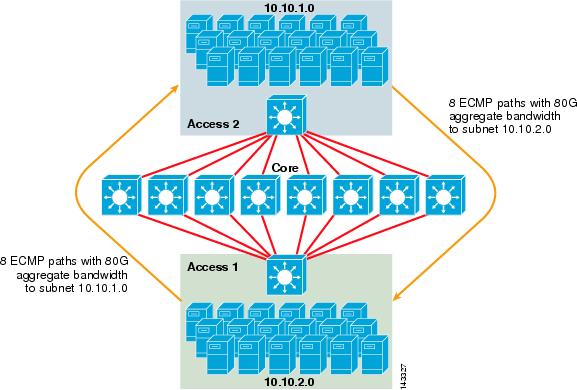
En la Figura 3-2, cada conmutador de capa de acceso puede admitir una o más subredes de servidores conectados. Cada interruptor tiene una sola conexión de 10 Gige a cada uno de los ocho interruptores de núcleo utilizando dos tarjetas de línea 6704. Esta configuración proporciona ocho rutas de 10GigE para un total de 80 G de ancho de banda habilitado para reenvío Cisco Express a cualquier otra subred del tejido de clúster de servidores. Una consulta de ruta de ip a otra subred en otro conmutador muestra ocho entradas de igual costo.
El núcleo se rellena con tarjetas de línea 10GigE con DFCs para permitir una estructura de conmutación de alta velocidad totalmente distribuida con una latencia de puerto a puerto muy baja. Una consulta de ruta de muestra ip a un conmutador de capa de acceso muestra una sola entrada de ruta en cada uno de los ocho conmutadores principales.
Nota ![]() Aunque no se ha probado para esta guía, hay un nuevo módulo Ethernet de 8 puertos y 10 Gigabits (WS-X6708-10G-3C) que se ha introducido recientemente para el switch de la serie Catalyst 6500. Esta tarjeta de línea se probará para su inclusión en esta guía en una fecha posterior. Para preguntas sobre la tarjeta 10GigE de 8 puertos, consulte la hoja de datos del producto.
Aunque no se ha probado para esta guía, hay un nuevo módulo Ethernet de 8 puertos y 10 Gigabits (WS-X6708-10G-3C) que se ha introducido recientemente para el switch de la serie Catalyst 6500. Esta tarjeta de línea se probará para su inclusión en esta guía en una fecha posterior. Para preguntas sobre la tarjeta 10GigE de 8 puertos, consulte la hoja de datos del producto.
Redundancia en el diseño del clúster de servidores
El diseño del clúster de servidores normalmente no se implementa con CPU redundantes o procesadores de estructura de conmutadores. La resiliencia se logra típicamente inherentemente en el diseño y por el método que el clúster funciona como un todo. Como se describe en el capítulo 1, «Descripción general de la arquitectura del centro de datos», los nodos de cómputo del clúster son administrados por nodos maestros que son responsables de asignar trabajos específicos a cada nodo de cómputo y supervisar su rendimiento. Si un nodo de cómputo se retira del clúster, se reasignará a un nodo disponible y seguirá funcionando, aunque con menos potencia de procesamiento, hasta que el nodo esté disponible. Aunque es importante diversificar las conexiones de nodo maestro en el clúster a través de diferentes conmutadores de acceso, no es crítico para los nodos de cómputo.
Aunque las CPU redundantes son sin duda opcionales, es importante considerar la densidad de puertos, particularmente con respecto a los puertos 10GE, donde hay una ranura adicional disponible en lugar de un módulo Sup720 redundante.
Nota ![]() Los ejemplos de este capítulo utilizan diseños de CPU no redundantes, que permiten un máximo de 64 puertos 10GE por nodo de núcleo 6509 disponibles para conexiones de enlace ascendente de nodo de acceso basadas en el uso de una tarjeta de línea 6708 de 8 puertos 10GigE.
Los ejemplos de este capítulo utilizan diseños de CPU no redundantes, que permiten un máximo de 64 puertos 10GE por nodo de núcleo 6509 disponibles para conexiones de enlace ascendente de nodo de acceso basadas en el uso de una tarjeta de línea 6708 de 8 puertos 10GigE.
Diseño de clúster de servidor: Modelo de dos niveles
Esta sección describe los diversos enfoques de un diseño de clúster de servidor que aprovecha ECMP y CEF distribuido. Cada diseño demuestra cómo las diferentes configuraciones pueden alcanzar varios niveles de sobresuscripción y pueden escalarse de manera flexible, comenzando con unos pocos nodos y creciendo hasta muchos que admiten miles de servidores.
El diseño del clúster de servidores suele seguir un modelo de dos niveles que consta de capas de núcleo y de acceso. Debido a que los objetivos de diseño requieren el uso de ECMP de capa 3 y reenvío distribuido para lograr un ancho de banda y latencia altamente deterministas por servidor, un modelo de tres niveles que introduzca otro punto de sobresuscripción generalmente no es deseable. Las ventajas de un modelo de tres niveles se describen en Diseño de clúster de servidores: Modelo de tres niveles.
Los tres cálculos principales a tener en cuenta al diseñar una solución de clúster de servidores son las conexiones máximas de servidor, el ancho de banda por servidor y la proporción de suscripciones excesivas. Los diseñadores de clústeres pueden determinar estos valores en función del rendimiento de la aplicación, el hardware del servidor y otros factores, incluidos los siguientes:
•![]() Número máximo de conexiones GigE de servidor a escala: los diseñadores de clústeres suelen tener una idea de la escala máxima requerida en el concepto inicial. Una ventaja de la forma en que funcionan los diseños ECMP es que pueden comenzar con un número mínimo de conmutadores y servidores que cumplan con un requisito particular de ancho de banda, latencia y sobre suscripciones, y crecer de manera flexible de una manera baja/no disruptiva a la máxima escala, manteniendo el mismo ancho de banda, latencia y valores de sobre suscripciones.
Número máximo de conexiones GigE de servidor a escala: los diseñadores de clústeres suelen tener una idea de la escala máxima requerida en el concepto inicial. Una ventaja de la forma en que funcionan los diseños ECMP es que pueden comenzar con un número mínimo de conmutadores y servidores que cumplan con un requisito particular de ancho de banda, latencia y sobre suscripciones, y crecer de manera flexible de una manera baja/no disruptiva a la máxima escala, manteniendo el mismo ancho de banda, latencia y valores de sobre suscripciones.
•![]() Ancho de banda aproximado por servidor: Este valor se puede determinar simplemente dividiendo el ancho de banda total agregado del enlace ascendente por el total de conexiones GigE del servidor en el conmutador de capa de acceso. Por ejemplo, una capa de acceso Cisco 6509 con cuatro enlaces ascendentes ECMP de 10GigE con 336 puertos de acceso al servidor se puede calcular de la siguiente manera:
Ancho de banda aproximado por servidor: Este valor se puede determinar simplemente dividiendo el ancho de banda total agregado del enlace ascendente por el total de conexiones GigE del servidor en el conmutador de capa de acceso. Por ejemplo, una capa de acceso Cisco 6509 con cuatro enlaces ascendentes ECMP de 10GigE con 336 puertos de acceso al servidor se puede calcular de la siguiente manera:
Enlaces ascendentes 4x10GigE con 336 servidores = 120 Mbps por servidor
Ajustando cualquiera de los lados de la ecuación disminuye o aumenta la cantidad de ancho de banda por servidor.
Nota ![]() Este es solo un valor aproximado y sirve solo como guía. Varios factores influyen en la cantidad real de ancho de banda que cada servidor tiene disponible. El algoritmo hash de distribución de carga ECMP divide la carga en función de los valores de la capa 3 y la capa 4 y varía en función de los patrones de tráfico. Además, los parámetros de configuración, como los valores de limitación de velocidad, colas y QoS, pueden influir en el ancho de banda real alcanzado por servidor.
Este es solo un valor aproximado y sirve solo como guía. Varios factores influyen en la cantidad real de ancho de banda que cada servidor tiene disponible. El algoritmo hash de distribución de carga ECMP divide la carga en función de los valores de la capa 3 y la capa 4 y varía en función de los patrones de tráfico. Además, los parámetros de configuración, como los valores de limitación de velocidad, colas y QoS, pueden influir en el ancho de banda real alcanzado por servidor.
•![]() Relación de sobre suscripciones por servidor: Este valor se puede determinar simplemente dividiendo el número total de conexiones GigE de servidor por el ancho de banda total agregado del enlace ascendente en el conmutador de capa de acceso. Por ejemplo, una capa de acceso 6509 con cuatro enlaces ascendentes ECMP de 10giges con 336 puertos de acceso al servidor se puede calcular de la siguiente manera:
Relación de sobre suscripciones por servidor: Este valor se puede determinar simplemente dividiendo el número total de conexiones GigE de servidor por el ancho de banda total agregado del enlace ascendente en el conmutador de capa de acceso. Por ejemplo, una capa de acceso 6509 con cuatro enlaces ascendentes ECMP de 10giges con 336 puertos de acceso al servidor se puede calcular de la siguiente manera:
Conexiones de servidor de 336 Giges con ancho de banda de enlace ascendente de 40G = relación de sobresuscripción de 8,4:1
Las siguientes secciones demuestran cómo varían estos valores, en función de diferentes configuraciones de hardware e interconexión, y sirven como guía al diseñar configuraciones de clúster grandes.
Nota ![]() Para fines de cálculo, se asume que no hay una tarjeta de línea para cambiar la suscripción excesiva de tela en el interruptor de la serie Catalyst 6500. La ranura de doble canal proporciona un ancho de banda máximo de 40 G a la estructura del interruptor. Una tarjeta 10GigE de 4 puertos con todos los puertos a velocidad de línea utilizando paquetes de tamaño máximo se considera la mejor condición posible con poca o ninguna suscripción excesiva. La cantidad real de ancho de banda de tela de conmutación disponible varía, según el tamaño promedio de los paquetes. Estos cálculos tendrían que volver a calcularse si utilizaras la tarjeta WS-X6708 de 8 puertos y 10GigE, que está sobreescrita en 2:1.
Para fines de cálculo, se asume que no hay una tarjeta de línea para cambiar la suscripción excesiva de tela en el interruptor de la serie Catalyst 6500. La ranura de doble canal proporciona un ancho de banda máximo de 40 G a la estructura del interruptor. Una tarjeta 10GigE de 4 puertos con todos los puertos a velocidad de línea utilizando paquetes de tamaño máximo se considera la mejor condición posible con poca o ninguna suscripción excesiva. La cantidad real de ancho de banda de tela de conmutación disponible varía, según el tamaño promedio de los paquetes. Estos cálculos tendrían que volver a calcularse si utilizaras la tarjeta WS-X6708 de 8 puertos y 10GigE, que está sobreescrita en 2:1.
Diseños ECMP de 4 y 8 vías con Acceso modular
Los siguientes cuatro ejemplos de diseño demuestran varios métodos para crear y escalar el modelo de clúster de servidores de dos niveles utilizando ECMP de 4 y 8 vías. Los principales problemas a considerar son el número de nodos principales y el número máximo de enlaces ascendentes, ya que estos influyen directamente en la escala máxima, el ancho de banda por servidor y los valores de suscripción excesiva.
Nota ![]() Aunque no se ha probado para esta guía, hay un nuevo módulo Ethernet de 8 puertos y 10 Gigabits (WS-X6708-10G-3C) que se ha introducido recientemente para el switch de la serie Catalyst 6500. Esta tarjeta de línea se probará para su inclusión en la guía en una fecha posterior. Para preguntas sobre la tarjeta 10GigE de 8 puertos, consulte la hoja de datos del producto.
Aunque no se ha probado para esta guía, hay un nuevo módulo Ethernet de 8 puertos y 10 Gigabits (WS-X6708-10G-3C) que se ha introducido recientemente para el switch de la serie Catalyst 6500. Esta tarjeta de línea se probará para su inclusión en la guía en una fecha posterior. Para preguntas sobre la tarjeta 10GigE de 8 puertos, consulte la hoja de datos del producto.
Nota ![]() Los enlaces necesarios para conectar el clúster de servidores a un campus externo o a una red de metro no se muestran en estos ejemplos de diseño, pero deben tenerse en cuenta.
Los enlaces necesarios para conectar el clúster de servidores a un campus externo o a una red de metro no se muestran en estos ejemplos de diseño, pero deben tenerse en cuenta.
La figura 3-3 proporciona un ejemplo en el que se utilizan dos nodos principales para proporcionar una solución ECMP de 4 vías.
Figura 3-3 ECMP de 4 vías utilizando dos nodos principales
Una ventaja de este enfoque es que un número menor de conmutadores principales puede admitir un gran número de servidores. La posible desventaja es una alta sobre suscripción, un ancho de banda bajo por valor de servidor y una gran exposición a un error de nodo central. Tenga en cuenta que los enlaces ascendentes son enlaces ascendentes L3 individuales y no son EtherChannels.
La figura 3-4 muestra cómo la adición de dos nodos principales al diseño anterior puede aumentar drásticamente la escala máxima mientras se mantienen los mismos valores de sobresuscripción y ancho de banda por servidor.
Figura 3-4 ECMP de 4 vías usando Cuatro nodos principales
La Figura 3-5 muestra un diseño ECMP de 8 vías usando dos nodos principales.
Figura 3-5 ECMP de 8 vías utilizando dos nodos principales
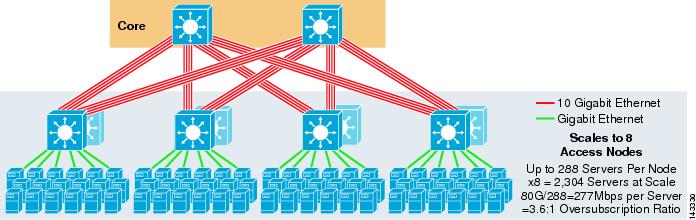
Como se esperaba, el ancho de banda adicional del enlace ascendente aumenta drásticamente el ancho de banda por servidor y reduce la relación de sobre suscripciones por servidor. Observe cómo las ranuras adicionales tomadas en cada conmutador de capa de acceso para admitir los enlaces ascendentes de 8 vías reducen la escala máxima a medida que el número de servidores por conmutador se reduce a 288. Tenga en cuenta que los enlaces ascendentes son enlaces ascendentes L3 individuales y no son EtherChannels.
La figura 3-6 muestra un diseño ECMP de 8 direcciones con ocho nodos principales.
Figura 3-6 ECMP de 8 direcciones usando ocho nodos principales
Esto demuestra cómo agregar cuatro nodos principales al mismo diseño anterior puede aumentar drásticamente la escala máxima mientras se mantienen los mismos valores de sobresuscripción y ancho de banda por servidor.
Diseño ECMP de 2 vías con acceso 1RU
En muchos entornos de clúster, se desea o se requiere la conmutación de servidores basada en rack mediante pequeños conmutadores en la parte superior de cada rack de servidores debido a problemas de cableado, administrativos, de bienes raíces o para cumplir con objetivos particulares del modelo de implementación.
La figura 3-7 muestra un ejemplo en el que se utilizan dos nodos principales para proporcionar una solución ECMP de 2 vías con conmutadores de acceso 1RU 4948-10GE.
Figura 3-7 ECMP de 2 vías utilizando dos Nodos Principales y Acceso 1RU
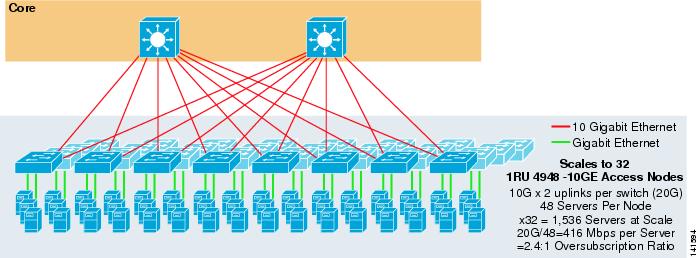
La escala máxima está limitada a 1536 servidores, pero proporciona más de 400 Mbps de ancho de banda con una baja relación de sobre suscripciones. Debido a que el 4948 solo tiene dos enlaces ascendentes de 10GigE, este diseño no puede escalar más allá de estos valores.
Nota ![]() En el Capítulo 3 «Diseños de clúster de servidores con Ethernet se proporciona más información sobre la conmutación de servidores basados en rack.»
En el Capítulo 3 «Diseños de clúster de servidores con Ethernet se proporciona más información sobre la conmutación de servidores basados en rack.»
Diseño de clúster de servidores: Modelo de tres niveles
Aunque un modelo de dos niveles es más común en diseños de clúster grandes, también se puede usar un modelo de tres niveles. El modelo de tres niveles se utiliza normalmente para admitir implementaciones de grandes clústeres de servidores mediante conmutadores de capa de acceso modular o 1RU.
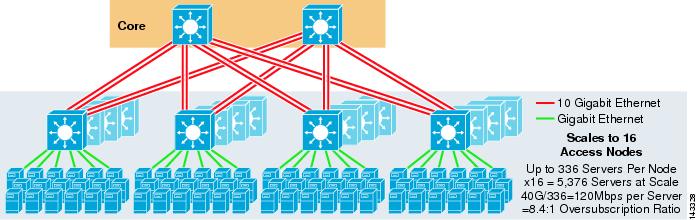
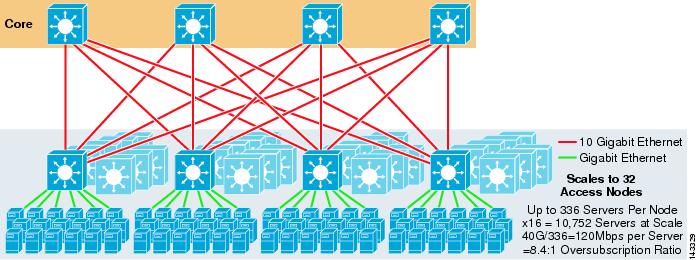
La figura 3-8 muestra un ejemplo a gran escala que aprovecha ECMP de 8 vías con conmutadores de núcleo y agregación 6500 y conmutadores de capa de acceso 1RU 4948 – 10GE.
Figura 3-8 Modelo de tres niveles con ECMP de 8 direcciones
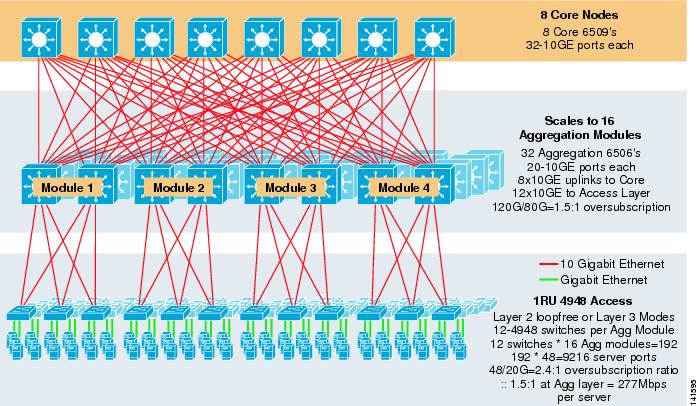
La escala máxima es de más de 9200 servidores con 277 Mbps de ancho de banda con una baja relación de sobre suscripciones. Los beneficios del enfoque de tres niveles que utiliza conmutadores de acceso 1RU incluyen los siguientes:
•![]() Modelos de implementación de 1RU: Como se mencionó anteriormente, muchas implementaciones de modelos de clúster de gran tamaño requieren un enfoque de 1RU para simplificar la instalación. Por ejemplo, un ASP despliega racks de servidores a la vez a medida que escalan aplicaciones de clúster grandes. El rack de servidores está premontado y preparado fuera del sitio para que se pueda instalar y agregar rápidamente al clúster en ejecución. Esto generalmente involucra a un tercero que construye los racks, pre-configura los servidores y los precablea con alimentación y Ethernet a un switch 1RU. El rack entra en el centro de datos y simplemente se conecta y se agrega al clúster después de conectar los enlaces ascendentes.
Modelos de implementación de 1RU: Como se mencionó anteriormente, muchas implementaciones de modelos de clúster de gran tamaño requieren un enfoque de 1RU para simplificar la instalación. Por ejemplo, un ASP despliega racks de servidores a la vez a medida que escalan aplicaciones de clúster grandes. El rack de servidores está premontado y preparado fuera del sitio para que se pueda instalar y agregar rápidamente al clúster en ejecución. Esto generalmente involucra a un tercero que construye los racks, pre-configura los servidores y los precablea con alimentación y Ethernet a un switch 1RU. El rack entra en el centro de datos y simplemente se conecta y se agrega al clúster después de conectar los enlaces ascendentes.
Sin una capa de agregación, el tamaño máximo del modelo de acceso 1RU está limitado a poco más de 1500 servidores. La adición de una capa de agregación permite que el modelo de acceso 1RU se pueda escalar a un tamaño mucho más grande y, al mismo tiempo, aprovechar el modelo ECMP.
•![]() Centralización de switches de núcleo y agregación: Con los switches 1RU implementados en los racks, es posible centralizar los switches modulares de núcleo y agregación más grandes. Esto puede simplificar la infraestructura de energía y cableado y mejorar el uso de los racks en el sector inmobiliario.
Centralización de switches de núcleo y agregación: Con los switches 1RU implementados en los racks, es posible centralizar los switches modulares de núcleo y agregación más grandes. Esto puede simplificar la infraestructura de energía y cableado y mejorar el uso de los racks en el sector inmobiliario.
•![]() Permite topología sin bucles de capa 2: Una gran red de clústeres que utiliza acceso ECMP de capa 3 puede usar mucho espacio de direcciones en los enlaces ascendentes y puede agregar complejidad al diseño. Esto es particularmente importante si se utiliza espacio de megafonía. El enfoque de modelo de tres niveles se presta bien a una topología de acceso sin bucle de capa 2 que reduce el número de subredes necesarias.
Permite topología sin bucles de capa 2: Una gran red de clústeres que utiliza acceso ECMP de capa 3 puede usar mucho espacio de direcciones en los enlaces ascendentes y puede agregar complejidad al diseño. Esto es particularmente importante si se utiliza espacio de megafonía. El enfoque de modelo de tres niveles se presta bien a una topología de acceso sin bucle de capa 2 que reduce el número de subredes necesarias.
Cuando se utiliza un modelo sin bucles de capa 2, es importante utilizar un protocolo de puerta de enlace redundante predeterminado, como HSRP o GLBP, para eliminar un único punto de error si falla un nodo de agregación. En este diseño, los módulos de agregación no están interconectados, lo que permite un diseño de capa 2 sin bucles que puede aprovechar GLBP para el equilibrio de carga automático de puerta de enlace predeterminada del servidor. GLBP distribuye automáticamente la asignación de puerta de enlace predeterminada de los servidores entre los dos nodos del módulo de agregación. Después de que un paquete llega a la capa de agregación, se equilibra a través del núcleo utilizando el tejido ECMP de 8 vías. Aunque GLBP no proporciona un hash de distribución de carga de Capa 3/Capa 4 similar a CEF, es una alternativa que se puede usar con una topología de acceso de Capa 2.
Cálculo de la suscripción excesiva
El modelo de tres niveles introduce dos puntos de suscripción excesiva en las capas de acceso y agregación, en comparación con el modelo de dos niveles que solo tiene un punto de suscripción excesiva en la capa de acceso. Para calcular correctamente el ancho de banda aproximado por servidor y la relación de sobre suscripciones, realice los dos pasos siguientes, que usan la Figura 3-8 como ejemplo:
Paso 1 ![]() Calcule la relación de sobre suscripciones y el ancho de banda por servidor para las capas de agregación y acceso de forma independiente.
Calcule la relación de sobre suscripciones y el ancho de banda por servidor para las capas de agregación y acceso de forma independiente.
•![]() Capa de acceso
Capa de acceso
–![]() Sobresuscripción-Servidores conectados 48GE / enlaces ascendentes de 20G a agregación = 2.4:1
Sobresuscripción-Servidores conectados 48GE / enlaces ascendentes de 20G a agregación = 2.4:1
–![]() Ancho de banda por servidor: enlaces ascendentes de 20G a servidores agregados / conectados de 48GigE = 416 Mbps
Ancho de banda por servidor: enlaces ascendentes de 20G a servidores agregados / conectados de 48GigE = 416 Mbps
•![]() Capa de agregación
Capa de agregación
–![]() Suscripción excesiva-Enlaces descendentes de 120 G para acceder / enlaces ascendentes de 80 G al núcleo = 1.5:1
Suscripción excesiva-Enlaces descendentes de 120 G para acceder / enlaces ascendentes de 80 G al núcleo = 1.5:1
Paso 2 ![]() Calcule la proporción combinada de suscripciones excesivas y el ancho de banda por servidor.
Calcule la proporción combinada de suscripciones excesivas y el ancho de banda por servidor.
La relación real de sobresuscripción es la suma de los dos puntos de sobresuscripción en las capas de acceso y agregación.
1.5*2.4 = 3.6:1
Para determinar el verdadero valor de ancho de banda por servidor, utilice la fórmula algebraica para proporciones:
a: b = c: d
Se ha determinado que el ancho de banda por servidor en la capa de acceso es de 416 Mbps por servidor. Debido a que la proporción de sobresuscripción de la capa de agregación es de 1.5:1, puede aplicar la fórmula anterior de la siguiente manera:
416:1 = x: 1.5
x=~264 Mbps por servidor
Hardware y módulos recomendados
Las plataformas recomendadas para el diseño del modelo de clúster de servidores consisten en la familia Cisco Catalyst 6500 con el módulo de procesador Sup720 y el switch Catalyst 4948-10GE 1RU. La alta velocidad de conmutación, la gran estructura del conmutador, la baja latencia, el reenvío distribuido y la densidad de 10 Gig hacen que el conmutador de la serie Catalyst 6500 sea ideal para todas las capas de este modelo. El factor de forma 1RU combinado con el reenvío de velocidad de cable, los enlaces ascendentes 10GE y la latencia constante muy baja hacen del 4948-10GE una excelente solución superior de rack para la capa de acceso.
Se recomienda lo siguiente:
•![]() Sup720-El Sup720 puede consistir en tarjetas hija de tipo PFC3A (por defecto) o de tipo PFC3B más reciente.
Sup720-El Sup720 puede consistir en tarjetas hija de tipo PFC3A (por defecto) o de tipo PFC3B más reciente.
•![]() Tarjetas de línea – Todas las tarjetas de línea deben ser de la serie 6700 y todas deben estar habilitadas para el reenvío distribuido con las tarjetas hijas DFC3A o DFC3B.
Tarjetas de línea – Todas las tarjetas de línea deben ser de la serie 6700 y todas deben estar habilitadas para el reenvío distribuido con las tarjetas hijas DFC3A o DFC3B.
Nota ![]() Al utilizar todos los módulos de la serie CEF720 conectados a tela, el modo de conmutación global es compacto, lo que permite que el sistema funcione al más alto nivel de rendimiento. El Catalyst 6509 puede admitir módulos de 10 GigE en todas las posiciones porque cada ranura admite canales duales a la estructura del conmutador (el Cisco Catalyst 6513 no admite esto).
Al utilizar todos los módulos de la serie CEF720 conectados a tela, el modo de conmutación global es compacto, lo que permite que el sistema funcione al más alto nivel de rendimiento. El Catalyst 6509 puede admitir módulos de 10 GigE en todas las posiciones porque cada ranura admite canales duales a la estructura del conmutador (el Cisco Catalyst 6513 no admite esto).
•![]() Cisco Catalyst 4948-10GE: El 4948—10GE proporciona una solución de capa de acceso de alto rendimiento que puede aprovechar los enlaces ascendentes ECMP y 10GigE. No se requieren requisitos especiales. El 4948 – 10GE puede utilizar una imagen Cisco IOS de capa 2 o una imagen Cisco IOS de capa 2/3, lo que permite un ajuste óptimo en cualquier entorno.
Cisco Catalyst 4948-10GE: El 4948—10GE proporciona una solución de capa de acceso de alto rendimiento que puede aprovechar los enlaces ascendentes ECMP y 10GigE. No se requieren requisitos especiales. El 4948 – 10GE puede utilizar una imagen Cisco IOS de capa 2 o una imagen Cisco IOS de capa 2/3, lo que permite un ajuste óptimo en cualquier entorno.