




Cisco Data Center Infrastructure 2.5 Design Guide
Server-Cluster-Designs mit Ethernet
Eine allgemeine Übersicht über die im Serverclustermodell verwendeten Server und Netzwerkkomponenten finden Sie in Kapitel 1 „Übersicht über die Architektur des Rechenzentrums.“ Dieses Kapitel beschreibt den Zweck und die Funktion jeder Schicht des Serverclustermodells genauer. Die folgenden Abschnitte sind enthalten:
•![]() Technische Ziele
Technische Ziele
•![]() Verteilte Weiterleitung und Latenz
Verteilte Weiterleitung und Latenz
•![]() Mehrpfad-Routing mit gleichen Kosten
Mehrpfad-Routing mit gleichen Kosten
•![]() Servercluster-Design – zweistufiges Modell
Servercluster-Design – zweistufiges Modell
•![]() Servercluster-Design – Dreistufiges Modell
Servercluster-Design – Dreistufiges Modell
•![]() Empfohlene Hardware und Module
Empfohlene Hardware und Module

Hinweis ![]() Die in diesem Kapitel behandelten Entwurfsmodelle wurden in Cisco-Labortests aufgrund der Größe und des Umfangs der erforderlichen Tests nicht vollständig verifiziert. Bei den abgedeckten zweistufigen Modellen handelt es sich um ähnliche Designs, die in Produktionsnetzwerken von Kunden implementiert wurden.
Die in diesem Kapitel behandelten Entwurfsmodelle wurden in Cisco-Labortests aufgrund der Größe und des Umfangs der erforderlichen Tests nicht vollständig verifiziert. Bei den abgedeckten zweistufigen Modellen handelt es sich um ähnliche Designs, die in Produktionsnetzwerken von Kunden implementiert wurden.
Technische Ziele
Beim Entwurf eines großen Unternehmensclusternetzwerks ist es wichtig, spezifische Ziele zu berücksichtigen. Keine zwei Cluster sind genau gleich; jeder hat seine eigenen spezifischen Anforderungen und muss aus einer Anwendungsperspektive untersucht werden, um die besonderen Designanforderungen zu bestimmen. Berücksichtigen Sie die folgenden technischen Überlegungen:
•![]() Latenz – Beim Netzwerktransport kann sich die Latenz negativ auf die Gesamtleistung des Clusters auswirken. Die Verwendung von Switching-Plattformen, die eine Switching-Architektur mit niedriger Latenzzeit verwenden, trägt zur Gewährleistung einer optimalen Leistung bei. Die Hauptquelle der Latenz ist der Protokollstapel und die NIC-Hardwareimplementierung, die auf dem Server verwendet werden. Treiberoptimierung und CPU-Offload-Techniken wie TCP Offload Engine (TOE) und Remote Direct Memory Access (RDMA) können dazu beitragen, die Latenz zu verringern und den Verarbeitungsaufwand auf dem Server zu reduzieren.
Latenz – Beim Netzwerktransport kann sich die Latenz negativ auf die Gesamtleistung des Clusters auswirken. Die Verwendung von Switching-Plattformen, die eine Switching-Architektur mit niedriger Latenzzeit verwenden, trägt zur Gewährleistung einer optimalen Leistung bei. Die Hauptquelle der Latenz ist der Protokollstapel und die NIC-Hardwareimplementierung, die auf dem Server verwendet werden. Treiberoptimierung und CPU-Offload-Techniken wie TCP Offload Engine (TOE) und Remote Direct Memory Access (RDMA) können dazu beitragen, die Latenz zu verringern und den Verarbeitungsaufwand auf dem Server zu reduzieren.
Die Latenz ist möglicherweise nicht immer ein kritischer Faktor beim Clusterdesign. Beispielsweise erfordern einige Cluster aufgrund einer großen Menge an Massendateitransfers möglicherweise eine hohe Bandbreite zwischen Servern, sind jedoch möglicherweise nicht stark auf IPC-Nachrichten (Server-zu-Server-Interprozesskommunikation) angewiesen, die durch hohe Latenzzeiten beeinträchtigt werden können.
•![]() Mesh / Partial Mesh-Konnektivität – Servercluster-Designs erfordern normalerweise ein Mesh- oder Partial Mesh-Fabric, um die Kommunikation zwischen allen Knoten im Cluster zu ermöglichen. Dieses Mesh Fabric wird verwendet, um Status, Daten und andere Informationen zwischen Master-zu-Compute- und Compute-zu-Compute-Servern im Cluster gemeinsam zu nutzen. Mesh- oder partielle Mesh-Konnektivität ist auch anwendungsabhängig.
Mesh / Partial Mesh-Konnektivität – Servercluster-Designs erfordern normalerweise ein Mesh- oder Partial Mesh-Fabric, um die Kommunikation zwischen allen Knoten im Cluster zu ermöglichen. Dieses Mesh Fabric wird verwendet, um Status, Daten und andere Informationen zwischen Master-zu-Compute- und Compute-zu-Compute-Servern im Cluster gemeinsam zu nutzen. Mesh- oder partielle Mesh-Konnektivität ist auch anwendungsabhängig.
•![]() Hoher Durchsatz — Die Möglichkeit, eine große Datei in einem bestimmten Zeitraum zu senden, kann für den Clusterbetrieb und die Leistung von entscheidender Bedeutung sein. Servercluster benötigen in der Regel eine minimale verfügbare nicht blockierende Bandbreite, was sich in einem Modell mit geringer Überzeichnung zwischen den Zugriffs- und Kernschichten niederschlägt.
Hoher Durchsatz — Die Möglichkeit, eine große Datei in einem bestimmten Zeitraum zu senden, kann für den Clusterbetrieb und die Leistung von entscheidender Bedeutung sein. Servercluster benötigen in der Regel eine minimale verfügbare nicht blockierende Bandbreite, was sich in einem Modell mit geringer Überzeichnung zwischen den Zugriffs- und Kernschichten niederschlägt.
•![]() Überzeichnungsverhältnis – Das Überzeichnungsverhältnis muss an mehreren Aggregationspunkten im Entwurf untersucht werden, einschließlich der Leitungskarte für die Switch-Fabric-Bandbreite und des Switch-Fabric-Eingangs für die Uplink-Bandbreite.
Überzeichnungsverhältnis – Das Überzeichnungsverhältnis muss an mehreren Aggregationspunkten im Entwurf untersucht werden, einschließlich der Leitungskarte für die Switch-Fabric-Bandbreite und des Switch-Fabric-Eingangs für die Uplink-Bandbreite.
•![]() Jumbo-Frame-Unterstützung – Obwohl Jumbo-Frames bei der ersten Implementierung eines Serverclusters möglicherweise nicht verwendet werden, ist dies eine sehr wichtige Funktion, die für zusätzliche Flexibilität oder mögliche zukünftige Anforderungen erforderlich ist. Die TCP / IP-Paketkonstruktion verursacht zusätzlichen Overhead für die Server-CPU. Die Verwendung von Jumbo-Frames kann die Anzahl der Pakete reduzieren, wodurch dieser Overhead reduziert wird.
Jumbo-Frame-Unterstützung – Obwohl Jumbo-Frames bei der ersten Implementierung eines Serverclusters möglicherweise nicht verwendet werden, ist dies eine sehr wichtige Funktion, die für zusätzliche Flexibilität oder mögliche zukünftige Anforderungen erforderlich ist. Die TCP / IP-Paketkonstruktion verursacht zusätzlichen Overhead für die Server-CPU. Die Verwendung von Jumbo-Frames kann die Anzahl der Pakete reduzieren, wodurch dieser Overhead reduziert wird.
•![]() Portdichte – Servercluster müssen möglicherweise auf Zehntausende von Ports skaliert werden. Daher benötigen sie Plattformen mit einer hohen Paketvermittlungsleistung, einer großen Switch-Fabric-Bandbreite und einer hohen Portdichte.
Portdichte – Servercluster müssen möglicherweise auf Zehntausende von Ports skaliert werden. Daher benötigen sie Plattformen mit einer hohen Paketvermittlungsleistung, einer großen Switch-Fabric-Bandbreite und einer hohen Portdichte.
Verteilte Weiterleitung und Latenz
Der Switch der Cisco Catalyst 6500-Serie verfügt über die einzigartige Fähigkeit, eine zentrale Paketweiterleitung oder eine optionale verteilte Weiterleitungsarchitektur zu unterstützen, während der Cisco Catalyst 4948-10GE ein einzelnes zentrales ASIC-Design mit Festnetz-Weiterleitungsleistung ist. Die Cisco 6700 Line Card Module unterstützen ein optionales Tochterkartenmodul, das als Distributed Forwarding Card (DFC) bezeichnet wird. Der DFC ermöglicht lokale Routingentscheidungen auf jeder Leitungskarte durch Implementierung einer lokalen Weiterleitungsinformationsbasis (FIB). Die FIB-Tabelle auf dem Sup720 PFC hält die Synchronisation mit jeder DFC-FIB-Tabelle auf den Linienkarten aufrecht, um die Routing-Integrität im gesamten System sicherzustellen.
Wenn die optionale DFC-Karte nicht vorhanden ist, wird eine kompakte Header-Suche an den PFC3 auf dem Sup720 gesendet, um zu bestimmen, wohin auf der Switch-Fabric jedes Paket weitergeleitet werden soll. Wenn ein DFC vorhanden ist, kann die Leitungskarte ein Paket direkt über die Switch-Fabric zur Zielleitungskarte wechseln, ohne den Sup720 zu konsultieren. Der Leistungsunterschied kann zwischen 30 Mpps systemweit ohne DFCs und 48 Mpps pro Steckplatz mit DFCs liegen. Der Catalyst 4948-10GE Switch mit fester Konfiguration verfügt über eine drahtgebundene, nicht blockierende Architektur, die eine Leistung von bis zu 101,18 Mpps unterstützt und eine überlegene Zugriffsschichtleistung für Top-of-Rack-Designs bietet.
Die Latenzleistung kann beim Vergleich der verteilten und zentralen Weiterleitungsmodelle erheblich variieren. Tabelle 3-1 enthält ein Beispiel für Latenzen, die über eine 6704 Line Card mit und ohne DFCs gemessen wurden.
| 6704 mit DFC (Port-zu-Port in Mikrosekunden durch Switch Fabric) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Paketgröße (B) |
||||||||||
|
Latenz (ms) |
||||||||||
| 6704 ohne DFC (Port-zu-Port in Mikrosekunden durch Switch Fabric) | ||||||||||
|
Paketgröße (B) |
||||||||||
|
Latenz (ms) |
||||||||||
Der Unterschied in der Latenz zwischen einem DFC-fähigen und nicht DFC-fähige Leitungskarten erscheinen möglicherweise nicht signifikant. In einer zentralen 6500-Weiterleitungsarchitektur kann sich die Latenz jedoch erhöhen, wenn die Datenverkehrsraten aufgrund des Konflikts um die gemeinsame Suche auf dem zentralen Bus steigen. Bei einem DFC ist der Nachschlagepfad für jede Leitungskarte reserviert und die Latenz ist konstant.
Die verfügbare Systembandbreite ändert sich nicht, wenn DFCs verwendet werden. Die DFCs verbessern die Pakete pro Sekunde (pps) Verarbeitung des Gesamtsystems. Tabelle 3-2 fasst den Durchsatz und die Bandbreitenleistung für Module zusammen, die zusätzlich zu den älteren CEF256- und Classic-Busmodulen DFCs unterstützen.
| Systemkonfiguration mit Sup720 | Durchsatz in Mpps | Bandbreite in Gbps |
|
Module der Classic-Serie |
Bis zu 15 Mpps (pro System) |
16 G geteilter Bus (klassischer Bus) |
|
CEF256 Serie module |
Bis zu 30 Mpps (pro System) |
1x 8 G (dediziert pro Steckplatz) |
|
Mix aus Classic mit Modulen der Serien CEF256 oder CEF720 |
Bis zu 15 Mpps (pro System) |
Karte abhängig |
|
Module der Serie CEF720 (6748, 6704, 6724) |
Bis zu 30 Mpps (pro System) |
2x20g (gewidmet pro slot) |
|
CEF720 Serie module mit DFC3 (6704 mit DFC3, 6708 mit DFC3, 6748 mit DFC3 6724 + DFC3) |
Sustain bis zu 48 Mpps (pro Steckplatz) |
2x 20 G (dediziert pro Steckplatz) |
Obwohl die 6513 könnte eine gültige Lösung für die Zugriffsschicht des großen Cluster-Modells sein, beachten Sie, dass es eine Mischung aus Einzel- und Zweikanal-Slots in diesem Chassis. Die Steckplätze 1 bis 8 sind einkanalig und die Steckplätze 9 bis 13 sind zweikanalig, wie in Abbildung 3-1 gezeigt.
Abbildung 3-1 Catalyst 6500 Fabric-Kanäle nach Chassis und Steckplatz (6513)
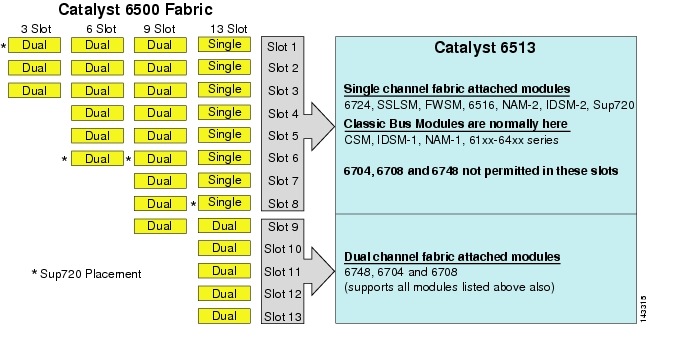
Wenn ein Cisco Catalyst 6513 verwendet wird, können die Zweikanalkarten, z. B. der 6704-4-Port 10GigE, der 6708-8-Port 10GigE und der 6748-48-Port SFP / copper Line Cards, nur in den Steckplätzen 9 bis 13 platziert werden. Die einzelnen kanal line cards wie die 6724-24 port SFP/kupfer linie karten können verwendet werden in slots 1 zu 8. Die Sup720 verwendet slots 7 und 8, die sind einzigen kanal 20G stoff befestigt. Im Gegensatz zum 6513 verfügt der 6509 über weniger verfügbare Steckplätze, kann jedoch Zweikanalmodule in allen Steckplätzen unterstützen, da jeder Steckplatz zwei Kanäle zur Switch-Fabric hat.
Hinweis ![]() Da die Serverclusterumgebung normalerweise eine hohe Bandbreite mit niedrigen Latenzeigenschaften erfordert, empfehlen wir die Verwendung von DFCs in diesen Arten von Designs.
Da die Serverclusterumgebung normalerweise eine hohe Bandbreite mit niedrigen Latenzeigenschaften erfordert, empfehlen wir die Verwendung von DFCs in diesen Arten von Designs.
Equal Cost Multi-Path Routing
Equal Cost Multi-Path (ECMP) Routing ist eine Load-Balancing-Technologie, die den Datenfluss über mehrere IP-Pfade zwischen zwei beliebigen Subnetzen in einer Cisco Express Forwarding-fähigen Umgebung optimiert. ECMP wendet den Lastenausgleich für TCP- und UDP-Pakete pro Flow an. Nicht-TCP / UDP-Pakete wie ICMP werden paketweise verteilt. ECMP basiert auf RFC 2991 und wird auf anderen Cisco-Plattformen wie den Produkten PIX und Cisco Content Services Switch (CSS) eingesetzt. ECMP wird sowohl auf den 6500- als auch auf den 4948-10GE-Plattformen unterstützt, die im Servercluster-Design empfohlen werden.
Die dramatischen Änderungen, die sich aus Layer-3-Switching-Hardware-ASICs und Cisco Express Forwarding-Hashing-Algorithmen ergeben, helfen, ECMP von seinen Vorgängertechnologien zu unterscheiden. Der Hauptvorteil eines ECMP-Designs für Servercluster-Implementierungen ist der Hashing-Algorithmus in Kombination mit wenig bis gar keinem CPU-Overhead beim Layer-3-Switching. Der Cisco Express Forwarding Hashing-Algorithmus ist in der Lage, granulare Flüsse über mehrere Leitungskarten mit Leitungsrate in Hardware zu verteilen. Die Standardeinstellung des Hash-Algorithmus besteht darin, Flows basierend auf Quell-Ziel-IP-Adressen der Ebene 3 zu hashen und optional Portnummern der Ebene 4 für eine zusätzliche Differenzierungsebene hinzuzufügen. Die maximal zulässige Anzahl von ECMP-Pfaden beträgt acht.
Abbildung 3-2 veranschaulicht ein 8-Wege-ECMP-Servercluster-Design. Zur Vereinfachung der Darstellung sind nur zwei Access Layer Switches dargestellt, es können jedoch bis zu 32 unterstützt werden (64 10GigEs pro Core Node).
Abbildung 3-2 8-Wege-ECMP-Servercluster-Design
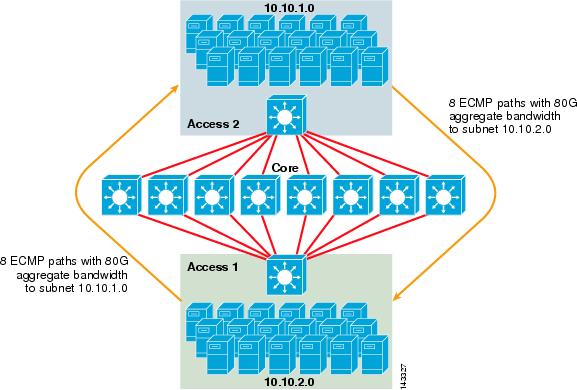
In Abbildung 3-2 kann jeder Access Layer Switch ein oder mehrere Subnetze angeschlossener Server unterstützen. Jeder Switch verfügt über eine einzelne 10GigE-Verbindung zu jedem der acht Core-Switches unter Verwendung von zwei 6704-Leitungskarten. Diese Konfiguration bietet acht Pfade von 10GigE für insgesamt 80 G Cisco Express-weiterleitungsfähige Bandbreite zu jedem anderen Subnetz in der Serverclusterstruktur. Eine show ip Route-Abfrage zu einem anderen Subnetz auf einem anderen Switch zeigt acht Einträge zu gleichen Kosten.
Der Kern ist mit 10GigE-Leitungskarten mit DFCs bestückt, um eine vollständig verteilte Hochgeschwindigkeits-Switching-Fabric mit sehr geringer Port-zu-Port-Latenz zu ermöglichen. Eine show ip Route-Abfrage an einen Access Layer-Switch zeigt einen einzelnen Routeneintrag auf jedem der acht Core-Switches.
Hinweis ![]() Obwohl es nicht für dieses Handbuch getestet wurde, gibt es ein neues 8-Port-10-Gigabit-Ethernet-Modul (WS-X6708-10G-3C), das kürzlich für den Switch der Catalyst 6500-Serie eingeführt wurde. Diese Linienkarte wird zu einem späteren Zeitpunkt für die Aufnahme in dieses Handbuch getestet. Fragen zur 8-Port 10GigE-Karte finden Sie im Produktdatenblatt.
Obwohl es nicht für dieses Handbuch getestet wurde, gibt es ein neues 8-Port-10-Gigabit-Ethernet-Modul (WS-X6708-10G-3C), das kürzlich für den Switch der Catalyst 6500-Serie eingeführt wurde. Diese Linienkarte wird zu einem späteren Zeitpunkt für die Aufnahme in dieses Handbuch getestet. Fragen zur 8-Port 10GigE-Karte finden Sie im Produktdatenblatt.
Redundanz im Servercluster-Design
Das Servercluster-Design wird normalerweise nicht mit redundanten CPU- oder Switch-Fabric-Prozessoren implementiert. Die Ausfallsicherheit wird typischerweise inhärent im Design und durch die Methode erreicht, mit der der Cluster als Ganzes funktioniert. Wie in Kapitel 1 „Übersicht über die Rechenzentrumsarchitektur“ beschrieben, werden die Rechenknoten im Cluster von Masterknoten verwaltet, die für die Zuweisung bestimmter Aufträge an jeden Rechenknoten und die Überwachung ihrer Leistung verantwortlich sind. Wenn ein Compute-Knoten den Cluster verlässt, wird er einem verfügbaren Knoten neu zugewiesen und arbeitet weiter, obwohl mit weniger Rechenleistung, bis der Knoten verfügbar ist. Obwohl es wichtig ist, Masterknotenverbindungen im Cluster über verschiedene Zugriffsschalter hinweg zu diversifizieren, ist dies für die Rechenknoten nicht kritisch.
Obwohl redundante CPUs sicherlich optional sind, ist es wichtig, die Portdichte zu berücksichtigen, insbesondere in Bezug auf 10GE-Ports, bei denen anstelle eines redundanten Sup720-Moduls ein zusätzlicher Steckplatz verfügbar ist.
Hinweis ![]() Die Beispiele in diesem Kapitel verwenden nicht redundante CPU-Designs, die maximal 64 10GE-Ports pro 6509-Kernknoten für Access Node-Uplink-Verbindungen basierend auf der Verwendung einer 6708 8-Port 10GigE-Leitungskarte ermöglichen.
Die Beispiele in diesem Kapitel verwenden nicht redundante CPU-Designs, die maximal 64 10GE-Ports pro 6509-Kernknoten für Access Node-Uplink-Verbindungen basierend auf der Verwendung einer 6708 8-Port 10GigE-Leitungskarte ermöglichen.
Serverclusterdesign — Zweistufiges Modell
In diesem Abschnitt werden die verschiedenen Ansätze eines Serverclusterdesigns beschrieben, das ECMP und verteiltes CEF nutzt. Jedes Design zeigt, wie verschiedene Konfigurationen verschiedene Überzeichnungsstufen erreichen und flexibel skalieren können, angefangen bei einigen Knoten bis hin zu vielen, die Tausende von Servern unterstützen.
Das Servercluster-Design folgt in der Regel einem zweistufigen Modell, das aus Kern- und Zugriffsschichten besteht. Da die Entwurfsziele die Verwendung von Layer-3-ECMP und verteilter Weiterleitung erfordern, um eine hochdeterministische Bandbreite und Latenz pro Server zu erreichen, ist ein dreistufiges Modell, das einen weiteren Punkt der Überzeichnung einführt, normalerweise nicht wünschenswert. Die Vorteile eines dreistufigen Modells werden in Serverclusterdesign —Dreistufiges Modell beschrieben.
Die drei wichtigsten Berechnungen, die beim Entwurf einer Serverclusterlösung zu berücksichtigen sind, sind maximale Serververbindungen, Bandbreite pro Server und Überzeichnungsverhältnis. Clusterdesigner können diese Werte basierend auf der Anwendungsleistung, der Serverhardware und anderen Faktoren ermitteln, einschließlich der folgenden:
•![]() Maximale Anzahl von Server-GigE-Verbindungen im Maßstab – Cluster-Designer haben in der Regel eine Vorstellung von der maximalen Skalierung, die beim ersten Konzept erforderlich ist. Ein Vorteil der Funktionsweise von ECMP-Designs besteht darin, dass sie mit einer minimalen Anzahl von Switches und Servern beginnen können, die eine bestimmte Bandbreiten-, Latenz- und Überzeichnungsanforderung erfüllen, und flexibel auf niedrige / unterbrechungsfreie Weise bis zur maximalen Skalierung wachsen können, während die gleichen Bandbreiten-, Latenz- und Überzeichnungswerte beibehalten werden.
Maximale Anzahl von Server-GigE-Verbindungen im Maßstab – Cluster-Designer haben in der Regel eine Vorstellung von der maximalen Skalierung, die beim ersten Konzept erforderlich ist. Ein Vorteil der Funktionsweise von ECMP-Designs besteht darin, dass sie mit einer minimalen Anzahl von Switches und Servern beginnen können, die eine bestimmte Bandbreiten-, Latenz- und Überzeichnungsanforderung erfüllen, und flexibel auf niedrige / unterbrechungsfreie Weise bis zur maximalen Skalierung wachsen können, während die gleichen Bandbreiten-, Latenz- und Überzeichnungswerte beibehalten werden.
•![]() Ungefähre Bandbreite pro Server – Dieser Wert kann bestimmt werden, indem einfach die gesamte aggregierte Uplink-Bandbreite durch die gesamten Server-GigE-Verbindungen auf dem Access Layer Switch dividiert wird. Zum Beispiel kann eine Zugriffsschicht Cisco 6509 mit vier 10GigE ECMP-Uplinks mit 336 Serverzugriffsports wie folgt berechnet werden:
Ungefähre Bandbreite pro Server – Dieser Wert kann bestimmt werden, indem einfach die gesamte aggregierte Uplink-Bandbreite durch die gesamten Server-GigE-Verbindungen auf dem Access Layer Switch dividiert wird. Zum Beispiel kann eine Zugriffsschicht Cisco 6509 mit vier 10GigE ECMP-Uplinks mit 336 Serverzugriffsports wie folgt berechnet werden:
4x10GigE Uplinks mit 336 Servern = 120 Mbps pro Server
Eine Anpassung auf beiden Seiten der Gleichung verringert oder erhöht die Bandbreite pro Server.
Hinweis ![]() Dies ist nur ein ungefährer Wert und dient nur als Richtlinie. Verschiedene Faktoren beeinflussen die tatsächliche Bandbreite, die jedem Server zur Verfügung steht. Der ECMP-Lastverteilungs-Hash-Algorithmus teilt die Last basierend auf Layer-3- plus-Layer-4-Werten und variiert basierend auf Verkehrsmustern. Auch Konfigurationsparameter wie Ratenbegrenzung, Queuing und QoS-Werte können die tatsächlich erreichte Bandbreite pro Server beeinflussen.
Dies ist nur ein ungefährer Wert und dient nur als Richtlinie. Verschiedene Faktoren beeinflussen die tatsächliche Bandbreite, die jedem Server zur Verfügung steht. Der ECMP-Lastverteilungs-Hash-Algorithmus teilt die Last basierend auf Layer-3- plus-Layer-4-Werten und variiert basierend auf Verkehrsmustern. Auch Konfigurationsparameter wie Ratenbegrenzung, Queuing und QoS-Werte können die tatsächlich erreichte Bandbreite pro Server beeinflussen.
•![]() Überzeichnungsverhältnis pro Server – Dieser Wert kann bestimmt werden, indem einfach die Gesamtzahl der Server-GigE-Verbindungen durch die gesamte aggregierte Uplink-Bandbreite auf dem Access Layer Switch dividiert wird. Beispielsweise kann eine Zugriffsschicht 6509 mit vier 10GigE-ECMP-Uplinks mit 336 Serverzugriffsports wie folgt berechnet werden:
Überzeichnungsverhältnis pro Server – Dieser Wert kann bestimmt werden, indem einfach die Gesamtzahl der Server-GigE-Verbindungen durch die gesamte aggregierte Uplink-Bandbreite auf dem Access Layer Switch dividiert wird. Beispielsweise kann eine Zugriffsschicht 6509 mit vier 10GigE-ECMP-Uplinks mit 336 Serverzugriffsports wie folgt berechnet werden:
336 GigE-Serververbindungen mit 40G-Uplink-Bandbreite = 8,4:1-Überzeichnungsverhältnis
Die folgenden Abschnitte zeigen, wie diese Werte variieren, basierend auf unterschiedlichen Hardware- und Verbindungskonfigurationen, und dienen als Richtlinie beim Entwerfen großer Clusterkonfigurationen.
Hinweis ![]() Zu Berechnungszwecken wird davon ausgegangen, dass keine Leitungskarte zum Umschalten der Fabric-Überzeichnung auf dem Switch der Catalyst 6500-Serie vorhanden ist. Der Dual-Channel-Steckplatz bietet dem Switch Fabric eine maximale Bandbreite von 40 G. Eine 4-Port-10GigE-Karte mit allen Ports mit Leitungsrate unter Verwendung von Paketen maximaler Größe wird als der bestmögliche Zustand mit geringer oder keiner Überzeichnung angesehen. Die tatsächlich verfügbare Switch-Fabric-Bandbreite variiert je nach durchschnittlicher Paketgröße. Diese Berechnungen müssten neu berechnet werden, wenn Sie die WS-X6708 8-Port 10GigE-Karte verwenden würden, die bei 2: 1 überzeichnet ist.
Zu Berechnungszwecken wird davon ausgegangen, dass keine Leitungskarte zum Umschalten der Fabric-Überzeichnung auf dem Switch der Catalyst 6500-Serie vorhanden ist. Der Dual-Channel-Steckplatz bietet dem Switch Fabric eine maximale Bandbreite von 40 G. Eine 4-Port-10GigE-Karte mit allen Ports mit Leitungsrate unter Verwendung von Paketen maximaler Größe wird als der bestmögliche Zustand mit geringer oder keiner Überzeichnung angesehen. Die tatsächlich verfügbare Switch-Fabric-Bandbreite variiert je nach durchschnittlicher Paketgröße. Diese Berechnungen müssten neu berechnet werden, wenn Sie die WS-X6708 8-Port 10GigE-Karte verwenden würden, die bei 2: 1 überzeichnet ist.
4- und 8-Wege-ECMP-Designs mit modularem Zugriff
Die folgenden vier Designbeispiele zeigen verschiedene Methoden zum Erstellen und Skalieren des zweistufigen Serverclustermodells mit 4-Wege- und 8-Wege-ECMP. Die wichtigsten zu berücksichtigenden Punkte sind die Anzahl der Kernknoten und die maximale Anzahl der Uplinks, da diese direkt die maximale Skalierung, die Bandbreite pro Server und die Überzeichnungswerte beeinflussen.
Hinweis ![]() Obwohl es nicht für dieses Handbuch getestet wurde, gibt es ein neues 8-Port-10-Gigabit-Ethernet-Modul (WS-X6708-10G-3C), das kürzlich für den Switch der Catalyst 6500-Serie eingeführt wurde. Diese Linienkarte wird zu einem späteren Zeitpunkt für die Aufnahme in den Leitfaden getestet. Fragen zur 8-Port 10GigE-Karte finden Sie im Produktdatenblatt.
Obwohl es nicht für dieses Handbuch getestet wurde, gibt es ein neues 8-Port-10-Gigabit-Ethernet-Modul (WS-X6708-10G-3C), das kürzlich für den Switch der Catalyst 6500-Serie eingeführt wurde. Diese Linienkarte wird zu einem späteren Zeitpunkt für die Aufnahme in den Leitfaden getestet. Fragen zur 8-Port 10GigE-Karte finden Sie im Produktdatenblatt.
Hinweis ![]() Die Verbindungen, die erforderlich sind, um den Servercluster mit einem externen Campus- oder U-Bahn-Netzwerk zu verbinden, sind in diesen Konstruktionsbeispielen nicht dargestellt, sollten jedoch berücksichtigt werden.
Die Verbindungen, die erforderlich sind, um den Servercluster mit einem externen Campus- oder U-Bahn-Netzwerk zu verbinden, sind in diesen Konstruktionsbeispielen nicht dargestellt, sollten jedoch berücksichtigt werden.
Abbildung 3-3 zeigt ein Beispiel, in dem zwei Kernknoten verwendet werden, um eine 4-Wege-ECMP-Lösung bereitzustellen.
Abbildung 3-3 4-Wege-ECMP mit zwei Core-Knoten
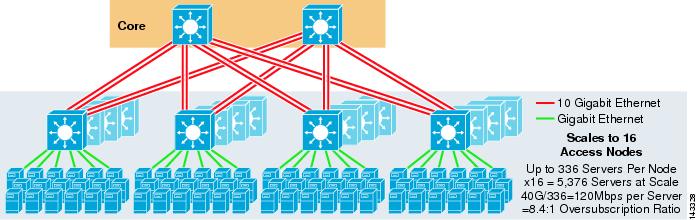
Ein Vorteil dieses Ansatzes besteht darin, dass eine kleinere Anzahl von Core-Switches eine große Anzahl von Servern unterstützen kann. Der mögliche Nachteil ist eine hohe Überzeichnung – geringe Bandbreite pro Serverwert und großes Risiko für einen Ausfall des Kernknotens. Beachten Sie, dass es sich bei den Uplinks um einzelne L3-Uplinks und nicht um EtherChannels handelt.
Abbildung 3-4 zeigt, wie das Hinzufügen von zwei Kernknoten zum vorherigen Design die maximale Skalierung drastisch erhöhen kann, während die gleichen Werte für Überzeichnung und Bandbreite pro Server beibehalten werden.
Abbildung 3-4 4-Wege-ECMP mit vier Kernknoten
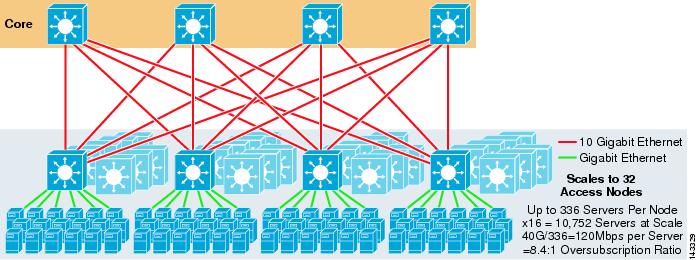
Abbildung 3-5 zeigt ein 8-Wege-ECMP-Design mit zwei Kernknoten.
Abbildung 3-5 8-Wege-ECMP mit zwei Kernknoten
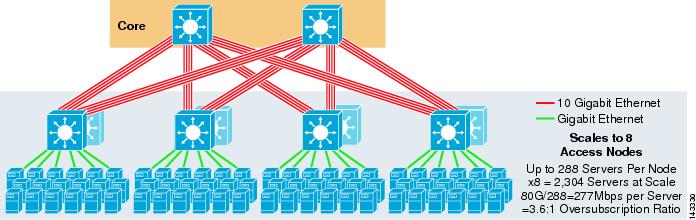
Wie erwartet erhöht die zusätzliche Uplink-Bandbreite die Bandbreite pro Server erheblich und verringert das Überzeichnungsverhältnis pro Server. Beachten Sie, dass die zusätzlichen Steckplätze, die in jedem Access Layer-Switch zur Unterstützung der 8-Wege-Uplinks belegt werden, die maximale Skalierung verringern, da die Anzahl der Server pro Switch auf 288 reduziert wird. Beachten Sie, dass es sich bei den Uplinks um einzelne L3-Uplinks und nicht um EtherChannels handelt.
Abbildung 3-6 zeigt ein 8-Wege-ECMP-Design mit acht Kernknoten.
Abbildung 3-6 8-Wege-ECMP mit acht Kernknoten
Dies zeigt, wie das Hinzufügen von vier Kernknoten zu demselben vorherigen Design die maximale Skalierung drastisch erhöhen kann, während die gleichen Werte für Überzeichnung und Bandbreite pro Server beibehalten werden.
2-Wege-ECMP-Design mit 1-HE-Zugriff
In vielen Clusterumgebungen ist ein Rack-basiertes Server-Switching mit kleinen Switches an der Oberseite jedes Server-Racks aufgrund von Verkabelungs-, Verwaltungs-, Immobilienproblemen oder zur Erfüllung bestimmter Ziele des Bereitstellungsmodells erwünscht oder erforderlich.
Abbildung 3-7 zeigt ein Beispiel, in dem zwei Kernknoten verwendet werden, um eine 2-Wege-ECMP-Lösung mit 1HE 4948-10GE Access Switches bereitzustellen.
Abbildung 3-7 2-Wege-ECMP mit zwei Kernknoten und 1-HE-Zugriff
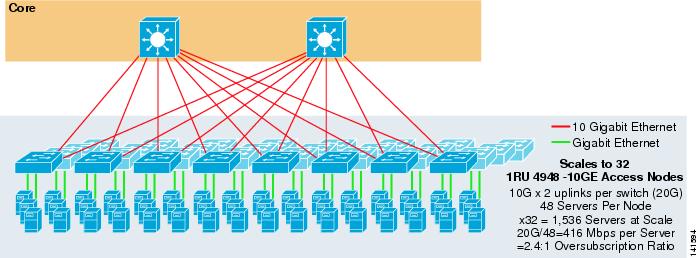
Die maximale Skalierung ist auf 1536 Server beschränkt, bietet jedoch eine Bandbreite von über 400 Mbit / s bei einem niedrigen Überzeichnungsverhältnis. Da der 4948 nur über zwei 10GigE-Uplinks verfügt, kann dieses Design nicht über diese Werte hinaus skaliert werden.
Hinweis ![]() Weitere Informationen zum Rack-basierten Server-Switching finden Sie im Kapitel 3 „Server-Cluster-Designs mit Ethernet.“
Weitere Informationen zum Rack-basierten Server-Switching finden Sie im Kapitel 3 „Server-Cluster-Designs mit Ethernet.“
Serverclusterdesign – Dreistufiges Modell
Obwohl ein zweistufiges Modell am häufigsten in großen Clusterdesigns verwendet wird, kann auch ein dreistufiges Modell verwendet werden. Das dreistufige Modell wird normalerweise verwendet, um große Serverclusterimplementierungen mit 1HE- oder modularen Zugriffsschichtschaltern zu unterstützen.
Abbildung 3-8 zeigt ein groß angelegtes Beispiel für die Nutzung von 8-Wege-ECMP mit 6500 Kern- und Aggregationsschaltern und 1HE 4948-10GE Access Layer Switches.
Abbildung 3-8 Dreistufiges Modell mit 8-Wege-ECMP
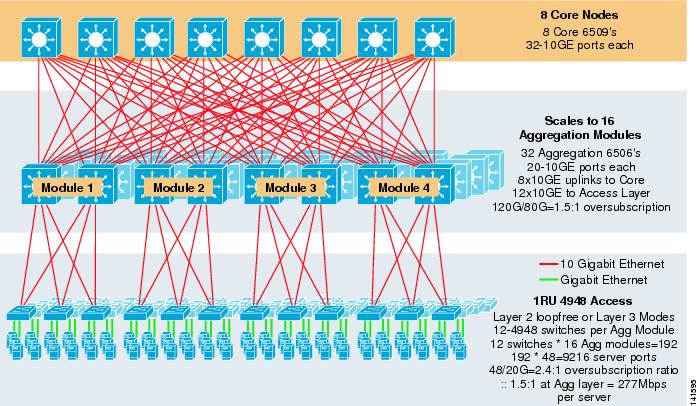
Die maximale Skalierung liegt bei über 9200 Servern mit 277 Mbit/s Bandbreite und einem niedrigen Überzeichnungsverhältnis. Zu den Vorteilen des dreistufigen Ansatzes mit 1RU-Zugriffsschaltern gehören:
•![]() 1RU-Bereitstellungsmodelle – Wie bereits erwähnt, erfordern viele große Cluster-Modellbereitstellungen einen 1RU-Ansatz für eine vereinfachte Installation. Zum Beispiel rollt ein ASP Racks von Servern gleichzeitig aus, wenn sie große Clusteranwendungen skalieren. Das Server-Rack wird vormontiert und extern bereitgestellt, sodass es schnell installiert und dem laufenden Cluster hinzugefügt werden kann. In der Regel handelt es sich dabei um einen Drittanbieter, der die Racks baut, die Server vorkonfiguriert und sie mit Strom und Ethernet an einen 1-HE-Switch vorverkabelt. Das Rack rollt in das Rechenzentrum und wird nach dem Anschließen der Uplinks einfach eingesteckt und dem Cluster hinzugefügt.
1RU-Bereitstellungsmodelle – Wie bereits erwähnt, erfordern viele große Cluster-Modellbereitstellungen einen 1RU-Ansatz für eine vereinfachte Installation. Zum Beispiel rollt ein ASP Racks von Servern gleichzeitig aus, wenn sie große Clusteranwendungen skalieren. Das Server-Rack wird vormontiert und extern bereitgestellt, sodass es schnell installiert und dem laufenden Cluster hinzugefügt werden kann. In der Regel handelt es sich dabei um einen Drittanbieter, der die Racks baut, die Server vorkonfiguriert und sie mit Strom und Ethernet an einen 1-HE-Switch vorverkabelt. Das Rack rollt in das Rechenzentrum und wird nach dem Anschließen der Uplinks einfach eingesteckt und dem Cluster hinzugefügt.
Ohne Aggregationsschicht ist die maximale Größe des 1-HE-Zugriffsmodells auf etwas mehr als 1500 Server begrenzt. Durch das Hinzufügen einer Aggregationsschicht kann das 1RU-Zugriffsmodell auf eine viel größere Größe skaliert werden, während das ECMP-Modell weiterhin genutzt wird.
•![]() Zentralisierung von Kern- und Aggregationsschaltern – Mit 1HE-Switches in den Racks ist es möglich, die größeren modularen Kern- und Aggregationsschalter zu zentralisieren. Dies kann die Strom- und Verkabelungsinfrastruktur vereinfachen und die Nutzung von Rack-Immobilien verbessern.
Zentralisierung von Kern- und Aggregationsschaltern – Mit 1HE-Switches in den Racks ist es möglich, die größeren modularen Kern- und Aggregationsschalter zu zentralisieren. Dies kann die Strom- und Verkabelungsinfrastruktur vereinfachen und die Nutzung von Rack-Immobilien verbessern.
•![]() Ermöglicht eine schleifenfreie Topologie der Schicht 2 — Ein großes Clusternetzwerk, das den ECMP-Zugriff der Schicht 3 verwendet, kann viel Adressraum auf den Uplinks beanspruchen und das Design komplexer machen. Dies ist besonders wichtig, wenn der öffentliche Beschallungsraum genutzt wird. Der dreistufige Modellansatz eignet sich gut für eine schleifenfreie Layer-2-Zugriffstopologie, die die Anzahl der erforderlichen Subnetze reduziert.
Ermöglicht eine schleifenfreie Topologie der Schicht 2 — Ein großes Clusternetzwerk, das den ECMP-Zugriff der Schicht 3 verwendet, kann viel Adressraum auf den Uplinks beanspruchen und das Design komplexer machen. Dies ist besonders wichtig, wenn der öffentliche Beschallungsraum genutzt wird. Der dreistufige Modellansatz eignet sich gut für eine schleifenfreie Layer-2-Zugriffstopologie, die die Anzahl der erforderlichen Subnetze reduziert.
Wenn ein schleifenfreies Layer-2-Modell verwendet wird, ist es wichtig, ein redundantes Standard-Gateway-Protokoll wie HSRP oder GLBP zu verwenden, um einen Single Point of Failure zu eliminieren, wenn ein Aggregationsknoten ausfällt. In diesem Design sind die Aggregationsmodule nicht miteinander verbunden, was ein schleifenfreies Layer-2-Design ermöglicht, das GLBP für den automatischen Server- und Gateway-Lastenausgleich nutzen kann. GLBP verteilt die Standard-Gateway-Zuweisung des Servers automatisch auf die beiden Knoten im Aggregationsmodul. Nachdem ein Paket die Aggregationsschicht erreicht hat, wird es mithilfe der 8-Wege-ECMP-Struktur über den Kern ausgeglichen. Obwohl GLBP keinen Layer 3 / Layer 4-Lastverteilungshash ähnlich wie CEF bereitstellt, ist es eine Alternative, die mit einer Layer 2-Zugriffstopologie verwendet werden kann.
Berechnung der Überzeichnung
Das dreistufige Modell führt zwei Überzeichnungspunkte auf den Zugriffs- und Aggregationsebenen ein, verglichen mit dem zweistufigen Modell, das nur einen einzigen Überzeichnungspunkt auf der Zugriffsebene aufweist. Um die ungefähre Bandbreite pro Server und das Überzeichnungsverhältnis ordnungsgemäß zu berechnen, führen Sie die folgenden zwei Schritte aus, die Abbildung 3-8 als Beispiel verwenden:
Schritt 1 ![]() Berechnen Sie das Überzeichnungsverhältnis und die Bandbreite pro Server sowohl für die Aggregations- als auch für die Zugriffsebene unabhängig voneinander.
Berechnen Sie das Überzeichnungsverhältnis und die Bandbreite pro Server sowohl für die Aggregations- als auch für die Zugriffsebene unabhängig voneinander.
•![]() Zugriffsebene
Zugriffsebene
–![]() Überzeichnung-48GE angeschlossene Server / 20G Uplinks zur Aggregation = 2.4:1
Überzeichnung-48GE angeschlossene Server / 20G Uplinks zur Aggregation = 2.4:1
–![]() Bandbreite pro Server- 20G Uplinks zu Aggregation / 48GigE angeschlossenen Servern = 416Mbps
Bandbreite pro Server- 20G Uplinks zu Aggregation / 48GigE angeschlossenen Servern = 416Mbps
•![]() Aggregationsschicht
Aggregationsschicht
–![]() Überzeichnung – 120G Downlinks zum Zugang / 80G Uplinks zum Kern = 1.5:1
Überzeichnung – 120G Downlinks zum Zugang / 80G Uplinks zum Kern = 1.5:1
Schritt 2 ![]() Berechnen Sie das kombinierte Überzeichnungsverhältnis und die Bandbreite pro Server.
Berechnen Sie das kombinierte Überzeichnungsverhältnis und die Bandbreite pro Server.
Das tatsächliche Überzeichnungsverhältnis ist die Summe der beiden Überzeichnungspunkte auf den Zugangs- und Aggregationsebenen.
1.5*2.4 = 3.6:1
Um den Wert für die wahre Bandbreite pro Server zu bestimmen, verwenden Sie die algebraische Formel für Proportionen:
a:b = c:d
Die Bandbreite pro Server auf der Zugriffsschicht wurde mit 416 Mbit / s pro Server bestimmt. Da das Überzeichnungsverhältnis der Aggregationsschicht 1,5: 1 beträgt, können Sie die obige Formel wie folgt anwenden:
416:1 = x:1.5
x= ~264 Mbit / s pro Server
Empfohlene Hardware und Module
Die empfohlenen Plattformen für das Design des Serverclustermodells bestehen aus der Cisco Catalyst 6500-Familie mit dem Sup720-Prozessormodul und dem Catalyst 4948-10GE 1RU-Switch. Die hohe Schaltrate, die große Switch-Fabric, die geringe Latenz, die verteilte Weiterleitung und die 10GigE-Dichte machen den Switch der Catalyst 6500-Serie ideal für alle Schichten dieses Modells. Der 1HE-Formfaktor in Kombination mit Wire Rate Forwarding, 10GE-Uplinks und sehr geringer konstanter Latenz macht den 4948-10GE zu einer hervorragenden Top-of-Rack-Lösung für die Zugangsschicht.
Folgendes wird empfohlen:
•![]() Sup720-Der Sup720 kann sowohl aus PFC3A (Standard) als auch aus den neueren Tochterkarten vom Typ PFC3B bestehen.
Sup720-Der Sup720 kann sowohl aus PFC3A (Standard) als auch aus den neueren Tochterkarten vom Typ PFC3B bestehen.
•![]() Line Cards – Alle Line Cards sollten der Serie 6700 angehören und alle für die verteilte Weiterleitung mit den DFC3A- oder DFC3B-Tochterkarten aktiviert sein.
Line Cards – Alle Line Cards sollten der Serie 6700 angehören und alle für die verteilte Weiterleitung mit den DFC3A- oder DFC3B-Tochterkarten aktiviert sein.
Hinweis ![]() Durch die Verwendung aller Fabric-Attached Module der CEF720-Serie ist der globale Schaltmodus kompakt, sodass das System auf höchstem Leistungsniveau betrieben werden kann. Der Catalyst 6509 kann 10 GigE-Module in allen Positionen unterstützen, da jeder Steckplatz zwei Kanäle zur Switch-Fabric unterstützt (der Cisco Catalyst 6513 unterstützt dies nicht).
Durch die Verwendung aller Fabric-Attached Module der CEF720-Serie ist der globale Schaltmodus kompakt, sodass das System auf höchstem Leistungsniveau betrieben werden kann. Der Catalyst 6509 kann 10 GigE-Module in allen Positionen unterstützen, da jeder Steckplatz zwei Kanäle zur Switch-Fabric unterstützt (der Cisco Catalyst 6513 unterstützt dies nicht).
•![]() Cisco Catalyst 4948-10GE-Der 4948-10GE bietet eine Hochleistungs-Access-Layer-Lösung, die ECMP- und 10GigE-Uplinks nutzen kann. Es sind keine besonderen Anforderungen erforderlich. Das 4948-10GE kann ein Cisco IOS-Bild der Schicht 2 oder ein Cisco IOS-Bild der Schicht 2/3 verwenden und eine optimale Passform in jeder Umwelt erlauben.
Cisco Catalyst 4948-10GE-Der 4948-10GE bietet eine Hochleistungs-Access-Layer-Lösung, die ECMP- und 10GigE-Uplinks nutzen kann. Es sind keine besonderen Anforderungen erforderlich. Das 4948-10GE kann ein Cisco IOS-Bild der Schicht 2 oder ein Cisco IOS-Bild der Schicht 2/3 verwenden und eine optimale Passform in jeder Umwelt erlauben.