




Cisco datacenterinfrastruktur 2.5 designguide
Serverklyngedesign med Ethernet
en oversigt på højt niveau over de servere og netværkskomponenter, der bruges i serverklyngemodellen, findes i kapitel 1 “Oversigt over Datacenterarkitektur.”Dette kapitel beskriver formålet og funktionen af hvert lag af serverklyngemodellen mere detaljeret. Følgende afsnit er inkluderet:
•![]() tekniske mål
tekniske mål
•![]() distribueret videresendelse og latenstid
distribueret videresendelse og latenstid
•![]() lige omkostninger multi-Path Routing
lige omkostninger multi-Path Routing
•![]() Server Cluster Design—to-lags Model
Server Cluster Design—to-lags Model
•![]() Server Cluster Design-tre-Tier Model
Server Cluster Design-tre-Tier Model
•![]() anbefalet udstyr og moduler
anbefalet udstyr og moduler

Bemærk ![]() de designmodeller, der er omfattet af dette kapitel, er ikke fuldt verificeret i Cisco lab-test på grund af størrelsen og omfanget af test, der ville være påkrævet. De to-lags modeller, der er dækket, er lignende designs, der er implementeret i kundeproduktionsnetværk.
de designmodeller, der er omfattet af dette kapitel, er ikke fuldt verificeret i Cisco lab-test på grund af størrelsen og omfanget af test, der ville være påkrævet. De to-lags modeller, der er dækket, er lignende designs, der er implementeret i kundeproduktionsnetværk.
tekniske mål
når man designer et stort virksomhedsklyngenetværk, er det vigtigt at overveje specifikke mål. Ikke to klynger er nøjagtigt ens; hver har sine egne specifikke krav og skal undersøges ud fra et applikationsperspektiv for at bestemme de særlige designkrav. Tage hensyn til følgende tekniske overvejelser:
•![]() Latency-i netværkstransporten kan latency påvirke den samlede klyngepræstation negativt. Brug af skifteplatforme, der anvender en skiftearkitektur med lav latenstid, hjælper med at sikre optimal ydelse. Den vigtigste kilde til latenstid er protokolstakken og implementeringen af Nic-udstyr, der bruges på serveren. Driveroptimering og CPU-offload-teknikker, såsom TCP Offload Engine (TOE) og Remote Direct Memory Access (RDMA), kan hjælpe med at reducere latenstid og reducere behandlingsomkostninger på serveren.
Latency-i netværkstransporten kan latency påvirke den samlede klyngepræstation negativt. Brug af skifteplatforme, der anvender en skiftearkitektur med lav latenstid, hjælper med at sikre optimal ydelse. Den vigtigste kilde til latenstid er protokolstakken og implementeringen af Nic-udstyr, der bruges på serveren. Driveroptimering og CPU-offload-teknikker, såsom TCP Offload Engine (TOE) og Remote Direct Memory Access (RDMA), kan hjælpe med at reducere latenstid og reducere behandlingsomkostninger på serveren.
Latency er måske ikke altid en kritisk faktor i klyngedesignet. For eksempel kan nogle klynger kræve høj båndbredde mellem servere på grund af en stor mængde bulkfiloverførsel, men er muligvis ikke stærkt afhængige af server-til-server Inter-Process Communication (IPC) – meddelelser, som kan påvirkes af høj latenstid.
•![]() Mesh / delvis mesh-forbindelse-Serverklyngedesign kræver normalt et mesh eller delvis mesh-stof for at muliggøre kommunikation mellem alle noder i klyngen. Dette mesh-stof bruges til at dele tilstand, data og anden information mellem master-to-compute og compute-to-compute-servere i klyngen. Mesh eller delvis mesh-forbindelse er også applikationsafhængig.
Mesh / delvis mesh-forbindelse-Serverklyngedesign kræver normalt et mesh eller delvis mesh-stof for at muliggøre kommunikation mellem alle noder i klyngen. Dette mesh-stof bruges til at dele tilstand, data og anden information mellem master-to-compute og compute-to-compute-servere i klyngen. Mesh eller delvis mesh-forbindelse er også applikationsafhængig.
•![]() høj gennemstrømning-evnen til at sende en stor fil i en bestemt mængde tid kan være afgørende for klynge drift og ydeevne. Serverklynger kræver typisk et minimum af tilgængelig ikke-blokerende båndbredde, hvilket oversættes til en lav overtegningsmodel mellem adgangs-og kernelagene.
høj gennemstrømning-evnen til at sende en stor fil i en bestemt mængde tid kan være afgørende for klynge drift og ydeevne. Serverklynger kræver typisk et minimum af tilgængelig ikke-blokerende båndbredde, hvilket oversættes til en lav overtegningsmodel mellem adgangs-og kernelagene.
•![]() Overtegningsforhold—overtegningsforholdet skal undersøges ved flere aggregeringspunkter i designet, inklusive linjekortet for at skifte stofbåndbredde og skifte stofindgang til uplink båndbredde.
Overtegningsforhold—overtegningsforholdet skal undersøges ved flere aggregeringspunkter i designet, inklusive linjekortet for at skifte stofbåndbredde og skifte stofindgang til uplink båndbredde.
•![]() jumbo frame support – selvom jumbo frames muligvis ikke bruges i den indledende implementering af en serverklynge, er det en meget vigtig funktion, der er nødvendig for yderligere fleksibilitet eller for mulige fremtidige krav. TCP / IP-pakkekonstruktionen placerer yderligere overhead på serverens CPU. Brugen af jumbo rammer kan reducere antallet af pakker og derved reducere denne overhead.
jumbo frame support – selvom jumbo frames muligvis ikke bruges i den indledende implementering af en serverklynge, er det en meget vigtig funktion, der er nødvendig for yderligere fleksibilitet eller for mulige fremtidige krav. TCP / IP-pakkekonstruktionen placerer yderligere overhead på serverens CPU. Brugen af jumbo rammer kan reducere antallet af pakker og derved reducere denne overhead.
•![]() porttæthed-serverklynger skal muligvis skaleres til titusinder af porte. Som sådan kræver de platforme med et højt niveau af pakkeomskiftningsydelse, en stor mængde båndbåndbredde og et højt niveau af porttæthed.
porttæthed-serverklynger skal muligvis skaleres til titusinder af porte. Som sådan kræver de platforme med et højt niveau af pakkeomskiftningsydelse, en stor mængde båndbåndbredde og et højt niveau af porttæthed.
distribueret videresendelse og latenstid
Cisco Catalyst 6500-Seriekontakten har den unikke evne til at understøtte en central pakke videresendelse eller valgfri distribueret videresendelsesarkitektur, mens Cisco Catalyst 4948-10GE er et enkelt centralt ASIC-design med fastlinjehastighed videresendelse ydeevne. Cisco 6700 line card-modulerne understøtter et valgfrit datterkortmodul kaldet et distribueret Videresendelseskort (DFC). DFC tillader lokale routingbeslutninger at forekomme på hvert linjekort ved at implementere en lokal Videresendelsesinformationsbase (FIB). FIB-bordet på Sup720 PFC opretholder synkronisering med hvert DFC FIB-bord på linjekortene for at sikre ruteintegritet på tværs af systemet.
når det valgfri DFC-kort ikke er til stede, sendes et kompakt headeropslag til PFC3 på Sup720 for at bestemme, hvor på omskifterstoffet der skal videresendes hver pakke. Når en DFC er til stede, kan linjekortet skifte en pakke direkte over omskifterstoffet til destinationslinjekortet uden at konsultere Sup720. Forskellen i ydeevne kan være fra 30 MPP ‘er hele systemet uden DFC’ er til 48 MPP ‘ er pr. Den faste konfiguration Catalyst 4948 – 10GE kontakt har en trådhastighed, ikke-blokerende arkitektur understøtter op til 101.18 Mpps ydeevne, giver overlegen adgang lag ydeevne for toppen af rack design.
Latency ydeevne kan variere betydeligt, når man sammenligner de distribuerede og centrale videresendelsesmodeller. Tabel 3-1 giver et eksempel på forsinkelser målt på tværs af et 6704 linjekort med og uden DFC ‘ er.
| 6704 med DFC (Port-til-Port i mikrosekunder gennem Skift Stof) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Pakkestørrelse (B) |
||||||||||
|
Latency (ms) |
||||||||||
| 6704 uden DFC (Port-til-Port i mikrosekunder gennem Skift Stof) | ||||||||||
|
Pakkestørrelse (B) |
||||||||||
|
Latency (ms) |
||||||||||
forskellen i latenstid mellem en DFC-aktiveret og ikke-DFC-aktiveret linjekort vises muligvis ikke signifikant. I en 6500 central videresendelsesarkitektur kan latenstiden dog stige, når trafikraterne stiger på grund af påstanden om det delte opslag på den centrale bus. Med en DFC er opslagsstien dedikeret til hvert linjekort, og latenstiden er konstant.
Catalyst 6500 Systembåndbredde
den tilgængelige systembåndbredde ændres ikke, når DFC ‘ er anvendes. DFC ‘ erne forbedrer PPS-behandlingen (PPS) af det samlede system. Tabel 3-2 opsummerer gennemstrømnings-og båndbreddeydelsen for moduler, der understøtter DFC ‘ er, ud over de ældre cef256-og classic bus-moduler.
| systemkonfiguration med Sup720 | gennemstrømning i MPP ‘er | båndbredde i Gbps |
|
klassiske serie moduler |
op til 15 MPP’ er (pr. system) |
16 g delt bus (klassisk bus) |
|
cef256 serie moduler |
op til 30 MPP ‘ er (pr. system) |
1 gang 8 G (dedikeret pr slot) |
|
blanding af classic med cef256 eller cef720 serie moduler |
op til 15 MPP ‘er (pr. system) |
kort afhængig |
|
cef720 serie moduler (6748, 6704, 6724) |
op til 30 MPP’ er (pr. system) |
2 gange 20 G (dedikeret pr. slot) |
|
cef720 serie moduler med DFC3 (6704 med DFC3, 6708 med DFC3, 6748 med DFC3 6724 + DFC3) |
Sustain op til 48 MPP ‘ er (pr. slot) |
2 gange 20 G (dedikeret pr. slot) |
selvom 6513 kan være en gyldig løsning til adgangslaget i den store klyngemodel, skal du bemærke, at der er en blanding af enkelt-og dobbeltkanalsspor i dette chassis. Slots 1 til 8 er enkelt kanal og slots 9 til 13 er dobbelt kanal, som vist i figur 3-1.
figur 3-1 Catalyst 6500 Stof kanaler ved Chassis og Slot (6513 Focus
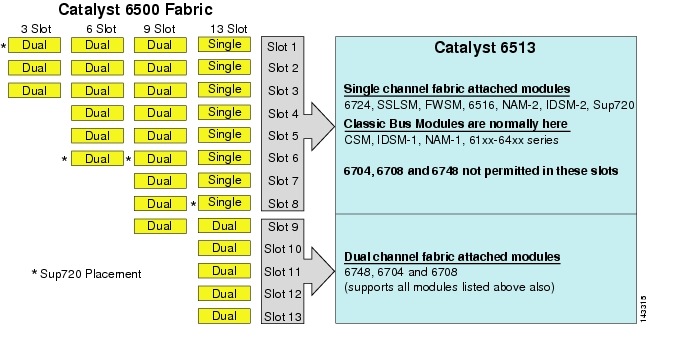
når en Cisco Catalyst 6513 anvendes, de dobbelte kanal kort, såsom 6704-4 port 10gige, den 6708 – 8 port 10gige, og 6748-48 port SFP/kobber linje kort kan kun placeres i slots 9 til 13. De enkeltkanallinjekort såsom 6724-24 port SFP / kobberlinjekort kan bruges i slots 1 til 8. Sup720 bruger slots 7 og 8, som er enkelt kanal 20g stof fastgjort. I modsætning til 6513 har 6509 færre tilgængelige slots, men kan understøtte dobbeltkanalmoduler i alle slots, fordi hver slot har dobbeltkanaler til omskifterstoffet.
Bemærk ![]() da serverklyngemiljøet normalt kræver høj båndbredde med lav latenstidsegenskaber, anbefaler vi at bruge DFC ‘ er i disse typer design.
da serverklyngemiljøet normalt kræver høj båndbredde med lav latenstidsegenskaber, anbefaler vi at bruge DFC ‘ er i disse typer design.
lige omkostninger multi-Path Routing
lige omkostninger multi-path (ECMP) routing er en belastningsbalanceringsteknologi, der optimerer strømme på tværs af flere IP-stier mellem to undernet i et Cisco-Ekspresvideresendelsesaktiveret miljø. ECMP anvender belastningsbalancering for TCP-og UDP-pakker pr. Ikke-TCP/UDP-pakker, såsom ICMP, distribueres på pakke-for-pakke-basis. ECMP er baseret på RFC 2991 og er gearet på andre Cisco platforme, som f.eks. ECMP understøttes på både 6500-og 4948-10GE-platformene, der anbefales i serverklyngedesignet.
de dramatiske ændringer som følge af lag 3 skifte udstyr ASICs og Cisco hurtig videresendelse hashing algoritmer hjælper med at skelne ECMP fra sin forgænger teknologier. Den største fordel ved et ECMP-design til implementering af serverklynger er hashingalgoritmen kombineret med lidt eller ingen CPU-overhead i lag 3-Skift. Cisco hurtig videresendelse hashing algoritme er i stand til at distribuere granulære strømme på tværs af flere linjekort på linje sats i udstyr. Hashing algoritme standardindstillingen er at hash strømme baseret på lag 3 kilde-destination IP-adresser, og eventuelt tilføje lag 4 portnumre for et yderligere lag af differentiering. Det maksimale antal ECMP-stier, der er tilladt, er otte.
figur 3-2 illustrerer et 8-vejs ECMP-serverklyngedesign. For at forenkle illustrationen vises kun to adgangslagskontakter, men op til 32 kan understøttes (64 10giges pr.
figur 3-2 8-vejs ECMP Server Cluster Design
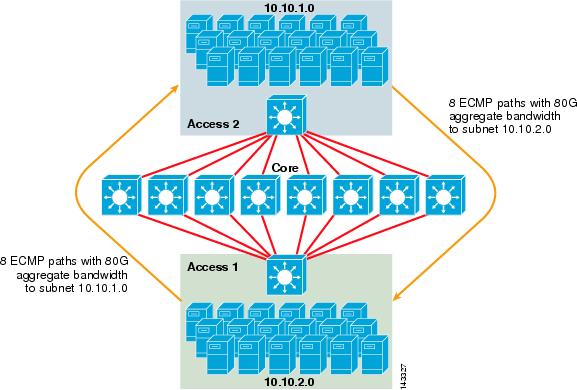
i figur 3-2 kan hver adgangslagskontakt understøtte et eller flere undernet af vedhæftede servere. Hver kontakt har en enkelt 10gige forbindelse til hver af de otte centrale kontakter ved hjælp af to 6704 line kort. Denne konfiguration giver otte stier af 10gige for i alt 80 G Cisco Ekspres videresendelse-aktiveret båndbredde til enhver anden subnet i serveren klynge stof. En vis ip-ruteforespørgsel til et andet undernet på en anden kontakt viser otte poster med samme omkostninger.
kernen er befolket med 10gige linjekort med DFC ‘ er for at muliggøre et fuldt distribueret højhastighedsskiftestof med meget lav port-til-port-latenstid. En vis ip-ruteforespørgsel til en access layer-kontakt viser en enkelt ruteindgang på hver af de otte kernekontakter.
Bemærk ![]() selvom det ikke er testet for denne vejledning, er der et nyt 8-port 10 Gigabit Ethernet-modul (6708-10g-3c), der for nylig er blevet introduceret til Catalyst 6500-Seriekontakten. Dette linjekort testes for optagelse i denne vejledning på et senere tidspunkt. For spørgsmål om 8-port 10gige kortet, henvises til produktdatabladet.
selvom det ikke er testet for denne vejledning, er der et nyt 8-port 10 Gigabit Ethernet-modul (6708-10g-3c), der for nylig er blevet introduceret til Catalyst 6500-Seriekontakten. Dette linjekort testes for optagelse i denne vejledning på et senere tidspunkt. For spørgsmål om 8-port 10gige kortet, henvises til produktdatabladet.
redundans i Serverklyngedesignet
serverklyngedesignet implementeres typisk ikke med overflødige CPU-eller skiftstofprocessorer. Elasticitet opnås typisk iboende i designet, og ved metoden fungerer klyngen som en helhed. Som beskrevet i kapitel 1″ Oversigt over Datacenterarkitektur ” styres computernoderne i klyngen af masternoder, der er ansvarlige for at tildele specifikke job til hver computernode og overvåge deres ydeevne. Hvis en computernode falder ud af klyngen, tildeles den igen til en tilgængelig node og fortsætter med at fungere, dog med mindre processorkraft, indtil noden er tilgængelig. Selvom det er vigtigt at diversificere masterknudeforbindelser i klyngen på tværs af forskellige adgangsafbrydere, er det ikke kritisk for computernoderne.
selvom overflødige CPU ‘ er bestemt er valgfri, er det vigtigt at overveje porttæthed, især med hensyn til 10GE-porte, hvor en ekstra slot er tilgængelig i stedet for et overflødigt Sup720-modul.
Bemærk ![]() eksemplerne i dette kapitel bruger ikke-redundante CPU-design, som tillader maksimalt 64 10GE-porte pr.6509-kerneknude tilgængelig for adgangsknude uplink-forbindelser baseret på brug af et 6708 8-port 10gige linjekort.
eksemplerne i dette kapitel bruger ikke-redundante CPU-design, som tillader maksimalt 64 10GE-porte pr.6509-kerneknude tilgængelig for adgangsknude uplink-forbindelser baseret på brug af et 6708 8-port 10gige linjekort.
Serverklyngedesign—to-lags Model
dette afsnit beskriver de forskellige tilgange til et serverklyngedesign, der udnytter ECMP og distribueret CEF. Hvert design demonstrerer, hvordan forskellige konfigurationer kan opnå forskellige overtegningsniveauer og kan skaleres på en fleksibel måde, startende med et par noder og vokser til mange, der understøtter tusinder af servere.
serverklyngedesignet følger typisk en todelt model bestående af kerne-og adgangslag. Da designmålene kræver brug af Layer 3 ECMP og distribueret videresendelse for at opnå en meget deterministisk båndbredde og latenstid pr.server, er en tre-lags model, der introducerer et andet overtegningspunkt, normalt ikke ønskelig. Fordelene med en tre-tier model er beskrevet i Server Cluster Design—tre-Tier Model.
de tre vigtigste beregninger, der skal overvejes, når man designer en serverklyngeløsning, er maksimale serverforbindelser, båndbredde pr. Klyngedesignere kan bestemme disse værdier baseret på applikationsydelse, serverudstyr og andre faktorer, herunder følgende:
•![]() maksimalt antal server GigE-forbindelser i skala-Klyngedesignere har typisk en ide om den maksimale skala, der kræves ved indledende koncept. En fordel ved ECMP-designfunktionen er, at de kan starte med et minimum antal kontakter og servere, der opfylder en bestemt båndbredde, latenstid og overtegningskrav og fleksibelt vokse på en lav/ikke-forstyrrende måde til maksimal skala, samtidig med at de samme båndbredde -, latenstids-og overtegningsværdier opretholdes.
maksimalt antal server GigE-forbindelser i skala-Klyngedesignere har typisk en ide om den maksimale skala, der kræves ved indledende koncept. En fordel ved ECMP-designfunktionen er, at de kan starte med et minimum antal kontakter og servere, der opfylder en bestemt båndbredde, latenstid og overtegningskrav og fleksibelt vokse på en lav/ikke-forstyrrende måde til maksimal skala, samtidig med at de samme båndbredde -, latenstids-og overtegningsværdier opretholdes.
•![]() Server-denne værdi kan bestemmes ved blot at dividere den samlede aggregerede uplink-båndbredde med de samlede server GigE-forbindelser på access layer-kontakten. For eksempel kan et adgangslag Cisco 6509 med fire 10GIGE ECMP uplinks med 336 serveradgangsporte beregnes som følger:
Server-denne værdi kan bestemmes ved blot at dividere den samlede aggregerede uplink-båndbredde med de samlede server GigE-forbindelser på access layer-kontakten. For eksempel kan et adgangslag Cisco 6509 med fire 10GIGE ECMP uplinks med 336 serveradgangsporte beregnes som følger:
4h10gige Uplinks med 336 servere = 120 Mbps pr.server
justering af begge sider af ligningen reducerer eller Øger mængden af båndbredde pr. server.
Bemærk ![]() dette er kun en omtrentlig værdi og tjener kun som retningslinje. Forskellige faktorer påvirker den faktiske mængde båndbredde, som hver server har til rådighed. ECMP load-distribution hash algoritme opdeler belastning baseret på Lag 3 plus Lag 4 værdier og varierer baseret på trafikmønstre. Konfigurationsparametre som hastighedsbegrænsende, kø-og Kvalitetsstyringsværdier kan også påvirke den faktiske opnåede båndbredde pr.server.
dette er kun en omtrentlig værdi og tjener kun som retningslinje. Forskellige faktorer påvirker den faktiske mængde båndbredde, som hver server har til rådighed. ECMP load-distribution hash algoritme opdeler belastning baseret på Lag 3 plus Lag 4 værdier og varierer baseret på trafikmønstre. Konfigurationsparametre som hastighedsbegrænsende, kø-og Kvalitetsstyringsværdier kan også påvirke den faktiske opnåede båndbredde pr.server.
•![]() Server-denne værdi kan bestemmes ved blot at dividere det samlede antal server GigE-forbindelser med den samlede aggregerede uplink-båndbredde på access layer-kontakten. For eksempel kan et access layer 6509 med fire 10GIGE ECMP uplinks med 336 serveradgangsporte beregnes som følger:
Server-denne værdi kan bestemmes ved blot at dividere det samlede antal server GigE-forbindelser med den samlede aggregerede uplink-båndbredde på access layer-kontakten. For eksempel kan et access layer 6509 med fire 10GIGE ECMP uplinks med 336 serveradgangsporte beregnes som følger:
336 GigE serverforbindelser med 40g uplink båndbredde = 8.4:1 overtegningsforhold
de følgende afsnit viser, hvordan disse værdier varierer, baseret på forskellige udstyrs-og samtrafikkonfigurationer, og tjener som retningslinje ved design af store klyngekonfigurationer.
Bemærk ![]() til beregningsformål antages det, at der ikke er noget linjekort til at skifte stofovertegning på Catalyst 6500-seriekontakten. Den dobbelte kanal slot giver 40G maksimal båndbredde til kontakten stof. En 4-port 10gige kort med alle porte på linje sats ved hjælp af maksimal størrelse pakker betragtes som den bedst mulige tilstand med ringe eller ingen overtegning. Den faktiske mængde tilgængelig båndbredde varierer, baseret på gennemsnitlige pakkestørrelser. Disse beregninger skal beregnes igen, hvis du skulle bruge kortet VS6708 8-port 10gige, som er overtegnet til 2:1.
til beregningsformål antages det, at der ikke er noget linjekort til at skifte stofovertegning på Catalyst 6500-seriekontakten. Den dobbelte kanal slot giver 40G maksimal båndbredde til kontakten stof. En 4-port 10gige kort med alle porte på linje sats ved hjælp af maksimal størrelse pakker betragtes som den bedst mulige tilstand med ringe eller ingen overtegning. Den faktiske mængde tilgængelig båndbredde varierer, baseret på gennemsnitlige pakkestørrelser. Disse beregninger skal beregnes igen, hvis du skulle bruge kortet VS6708 8-port 10gige, som er overtegnet til 2:1.
4 – og 8-vejs ECMP-design med modulær adgang
de følgende fire designeksempler demonstrerer forskellige metoder til opbygning og skalering af to-lags serverklyngemodel ved hjælp af 4-vejs og 8-vejs ECMP. De vigtigste problemer, der skal overvejes, er antallet af kernenoder og det maksimale antal uplinks, fordi disse direkte påvirker den maksimale skala, båndbredde pr.
Bemærk ![]() selvom det ikke er testet for denne vejledning, er der et nyt 8-port 10 Gigabit Ethernet-modul (6708-10g-3c), der for nylig er blevet introduceret til Catalyst 6500-Seriekontakten. Dette linjekort testes for optagelse i guiden på et senere tidspunkt. For spørgsmål om 8-port 10gige kortet, henvises til produktdatabladet.
selvom det ikke er testet for denne vejledning, er der et nyt 8-port 10 Gigabit Ethernet-modul (6708-10g-3c), der for nylig er blevet introduceret til Catalyst 6500-Seriekontakten. Dette linjekort testes for optagelse i guiden på et senere tidspunkt. For spørgsmål om 8-port 10gige kortet, henvises til produktdatabladet.
Bemærk ![]() de links, der er nødvendige for at forbinde serverklyngen til et eksternt campus-eller metronetværk, vises ikke i disse designeksempler, men bør overvejes.
de links, der er nødvendige for at forbinde serverklyngen til et eksternt campus-eller metronetværk, vises ikke i disse designeksempler, men bør overvejes.
figur 3-3 giver et eksempel, hvor to kerneknuder bruges til at tilvejebringe en 4-vejs ECMP-opløsning.
figur 3-3 4-vejs ECMP ved hjælp af to Kerneknuder
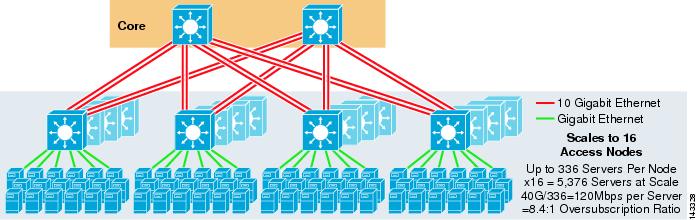
en fordel ved denne tilgang er, at et mindre antal kernekontakter kan understøtte et stort antal servere. Den mulige ulempe er en høj overtegning-lav båndbredde pr. Bemærk, at uplinks er individuelle L3 uplinks og ikke EtherChannels.
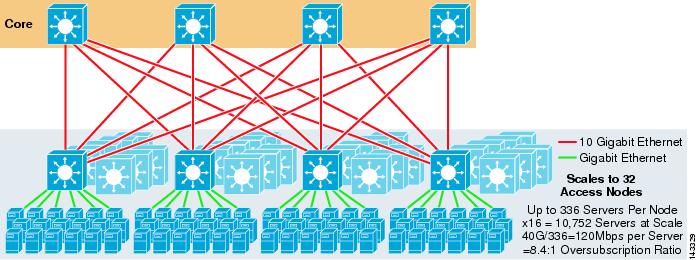
figur 3-4 viser, hvordan tilføjelse af to kernenoder til det forrige design dramatisk kan øge den maksimale skala, samtidig med at den samme overtegning og båndbredde pr.
figur 3-4 4-vejs ECMP ved hjælp af fire Kernenoder
figur 3-5 viser et 8-vejs ECMP-design ved hjælp af to kernenoder.
figur 3-5 8-vejs ECMP ved hjælp af to Kernenoder
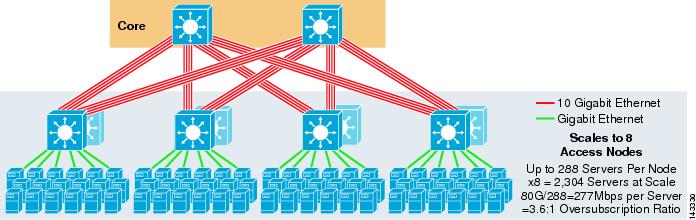
som forventet øger den ekstra uplink-båndbredde dramatisk båndbredden pr. Bemærk, hvordan de ekstra slots, der tages i hvert adgangslag, der understøtter 8-vejs uplinks, reducerer den maksimale skala, da antallet af servere pr. Bemærk, at uplinks er individuelle L3 uplinks og ikke EtherChannels.
figur 3-6 viser et 8-vejs ECMP-design med otte kerneknuder.
figur 3-6 8-vejs ECMP ved hjælp af otte Kernenoder
dette viser, hvordan tilføjelse af fire kernenoder til det samme tidligere design dramatisk kan øge den maksimale skala, samtidig med at den samme overtegning og båndbredde pr.
2-vejs ECMP-Design med 1RU-adgang
i mange klyngemiljøer ønskes eller kræves rackbaseret serverskift ved hjælp af små kontakter øverst på hvert serverstativ på grund af kabling, administrative problemer, ejendomsproblemer eller for at opfylde bestemte implementeringsmodelmål.
figur 3-7 viser et eksempel, hvor to kerneknuder bruges til at tilvejebringe en 2-vejs ECMP-opløsning med 1RU 4948-10GE adgangsafbrydere.
figur 3-7 2-vejs ECMP ved hjælp af to Kernenoder og 1RU-adgang
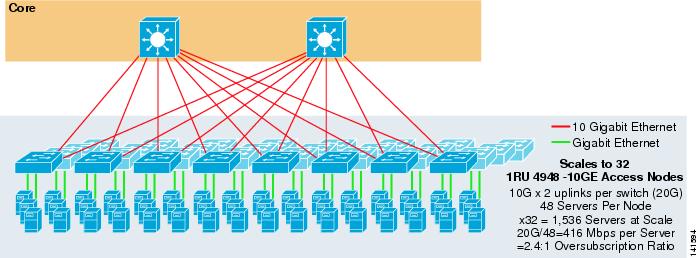
den maksimale skala er begrænset til 1536 servere, men giver over 400 Mbps båndbredde med et lavt overtegningsforhold. Fordi 4948 har kun to 10gige uplinks, kan dette design ikke skalere ud over disse værdier.
Bemærk ![]() flere oplysninger om rackbaseret serverskift findes i kapitel 3 “Serverklyngedesign med Ethernet.”
flere oplysninger om rackbaseret serverskift findes i kapitel 3 “Serverklyngedesign med Ethernet.”
Serverklyngedesign—tre-lags Model
selvom en to-lags model er mest almindelig i store klyngedesign, kan en tre-lags model også bruges. Den tre-lags model bruges typisk til at understøtte store serverklyngeimplementeringer ved hjælp af 1RU eller modulære adgangslagskontakter.
figur 3-8 viser et eksempel i stor skala, der udnytter 8-vejs ECMP med 6500 kerne-og aggregeringsafbrydere og 1RU 4948-10GE adgangslagsafbrydere.
figur 3-8 tre-Tier Model med 8-vejs ECMP
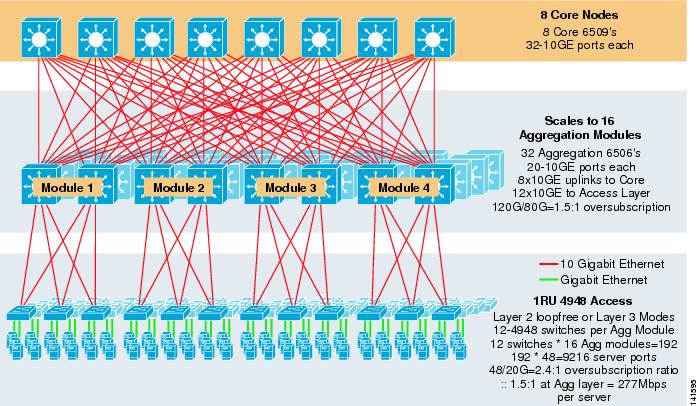
den maksimale skala er over 9200 servere med 277 Mbps båndbredde med et lavt overtegningsforhold. Fordelene ved den tre-lags tilgang ved hjælp af 1RU-adgangsafbrydere inkluderer følgende:
•![]() 1RU-implementeringsmodeller-som tidligere nævnt kræver mange store klyngemodelinstallationer en 1RU-tilgang til forenklet installation. For eksempel ruller en ASP ud racks af servere ad gangen, da de skalerer store klyngeapplikationer. Serverstativet er formonteret og iscenesat offsite, så det hurtigt kan installeres og tilføjes til den løbende klynge. Dette involverer normalt en tredjepart, der bygger stativerne, forudkonfigurerer serverne og forkabler dem med strøm og Ethernet til en 1RU-kontakt. Racket ruller ind i datacentret og er simpelthen tilsluttet og tilføjet til klyngen efter tilslutning af uplinks.
1RU-implementeringsmodeller-som tidligere nævnt kræver mange store klyngemodelinstallationer en 1RU-tilgang til forenklet installation. For eksempel ruller en ASP ud racks af servere ad gangen, da de skalerer store klyngeapplikationer. Serverstativet er formonteret og iscenesat offsite, så det hurtigt kan installeres og tilføjes til den løbende klynge. Dette involverer normalt en tredjepart, der bygger stativerne, forudkonfigurerer serverne og forkabler dem med strøm og Ethernet til en 1RU-kontakt. Racket ruller ind i datacentret og er simpelthen tilsluttet og tilføjet til klyngen efter tilslutning af uplinks.
uden et aggregeringslag er den maksimale størrelse af 1RU-adgangsmodellen begrænset til lidt over 1500 servere. Tilføjelse af et aggregeringslag gør det muligt for 1RU-adgangsmodellen at skalere til en meget større størrelse, mens den stadig udnytter ECMP-modellen.
•![]() centralisering af kerne—og aggregeringsafbrydere-med 1RU-afbrydere indsat i stativerne er det muligt at centralisere de større kerne-og aggregeringsmodulære afbrydere. Dette kan forenkle strøm-og kabelinfrastrukturen og forbedre brugen af fast ejendom.
centralisering af kerne—og aggregeringsafbrydere-med 1RU-afbrydere indsat i stativerne er det muligt at centralisere de større kerne-og aggregeringsmodulære afbrydere. Dette kan forenkle strøm-og kabelinfrastrukturen og forbedre brugen af fast ejendom.
•![]() tillader lag 2 loop-fri topologi – et stort klyngenetværk ved hjælp af lag 3 ECMP-adgang kan bruge meget adresseplads på uplinkene og kan tilføje kompleksitet til designet. Dette er især vigtigt, hvis der bruges offentlige adresserum. Den tre-lags model tilgang egner sig godt til et lag 2 loop-fri adgang topologi, der reducerer antallet af undernet kræves.
tillader lag 2 loop-fri topologi – et stort klyngenetværk ved hjælp af lag 3 ECMP-adgang kan bruge meget adresseplads på uplinkene og kan tilføje kompleksitet til designet. Dette er især vigtigt, hvis der bruges offentlige adresserum. Den tre-lags model tilgang egner sig godt til et lag 2 loop-fri adgang topologi, der reducerer antallet af undernet kræves.
når der anvendes en Layer 2 loop-fri model, er det vigtigt at bruge en redundant standardportprotokol som f.eks HSRP eller GLBP for at eliminere et enkelt fejlpunkt, hvis en aggregeringsnode fejler. I dette design er aggregeringsmodulerne ikke sammenkoblet, hvilket tillader et loop-frit lag 2-design, der kan udnytte GLBP til automatisk serverstandardportbelastningsbalancering. GLBP distribuerer automatisk serverens standardporttildeling mellem de to noder i aggregeringsmodulet. Når en pakke ankommer til aggregeringslaget, afbalanceres den over kernen ved hjælp af 8-vejs ECMP-stof. Selvom GLBP ikke giver et lag 3 / lag 4 belastningsfordeling hash svarende til CEF, det er et alternativ, der kan bruges med et lag 2 adgang topologi.
beregning af overtegning
tretrinsmodellen introducerer to overtegningspunkter ved adgangs-og aggregeringslagene sammenlignet med to-lagsmodellen, der kun har et enkelt overtegningspunkt ved adgangslaget. For at beregne den omtrentlige båndbredde pr. server og overtegningsforholdet korrekt skal du udføre følgende to trin, der bruger figur 3-8 som et eksempel:
Trin 1 ![]() Beregn overtegningsforholdet og båndbredden pr.server for både aggregerings-og adgangslagene uafhængigt.
Beregn overtegningsforholdet og båndbredden pr.server for både aggregerings-og adgangslagene uafhængigt.
•![]() Access layer
Access layer
–![]() overtegning—48ge vedhæftede servere / 20g uplinks til aggregering = 2.4:1
overtegning—48ge vedhæftede servere / 20g uplinks til aggregering = 2.4:1
–![]() båndbredde per server-20g uplinks til aggregering / 48gige vedhæftede servere = 416Mbps
båndbredde per server-20g uplinks til aggregering / 48gige vedhæftede servere = 416Mbps
•![]() Aggregeringslag
Aggregeringslag
–![]() overtegning—120g nedlinks til access / 80G uplinks til core = 1.5:1
overtegning—120g nedlinks til access / 80G uplinks til core = 1.5:1
Trin 2 ![]() Beregn det kombinerede overtegningsforhold og båndbredde pr.server.
Beregn det kombinerede overtegningsforhold og båndbredde pr.server.
det faktiske overtegningsforhold er summen af de to overtegningspunkter ved adgangs-og aggregeringslagene.
1.5*2.4 = 3.6:1
for at bestemme den sande båndbredde pr. serverværdi skal du bruge den algebraiske formel for proportioner:
a:b = c:d
båndbredden pr.server ved adgangslaget er bestemt til at være 416 Mbps pr. server. Fordi aggregeringslagets overtegningsforhold er 1,5: 1, kan du anvende ovenstående formel som følger:
416:1 = 1.5
=~264 Mbps per server
anbefalet udstyr og moduler
de anbefalede platforme til serverklyngemodeldesign består af Cisco Catalyst 6500-familien med Sup720-processormodulet og Catalyst 4948-10GE 1RU-kontakten. Den høje skiftehastighed, stort skiftestof, lav latenstid, distribueret videresendelse og 10gige densitet gør Catalyst 6500-Seriekontakten ideel til alle lag i denne model. 1RU-formfaktoren kombineret med videresendelse af trådhastighed, 10GE uplinks og meget lav konstant latenstid gør 4948-10GE til en fremragende top af rackløsning til adgangslaget.
følgende anbefales:
•![]() Sup720-Sup720 kan bestå af både pfc3a (standard) eller de nyere pfc3b type datterkort.
Sup720-Sup720 kan bestå af både pfc3a (standard) eller de nyere pfc3b type datterkort.
•![]() linjekort – alle linjekort skal være 6700-serien og skal alle være aktiveret til distribueret videresendelse med dfc3a-eller DFC3B-datterkortene.
linjekort – alle linjekort skal være 6700-serien og skal alle være aktiveret til distribueret videresendelse med dfc3a-eller DFC3B-datterkortene.
Bemærk ![]() ved at bruge alle stoftilsluttede cef720-seriemoduler er den globale skiftetilstand kompakt, hvilket gør det muligt for systemet at fungere på sit højeste ydelsesniveau. Catalyst 6509 kan understøtte 10 GigE moduler i alle positioner, fordi hver slot understøtter dobbelt kanaler til kontakten stof (Cisco Catalyst 6513 understøtter ikke dette).
ved at bruge alle stoftilsluttede cef720-seriemoduler er den globale skiftetilstand kompakt, hvilket gør det muligt for systemet at fungere på sit højeste ydelsesniveau. Catalyst 6509 kan understøtte 10 GigE moduler i alle positioner, fordi hver slot understøtter dobbelt kanaler til kontakten stof (Cisco Catalyst 6513 understøtter ikke dette).
•![]() Cisco Catalyst 4948-10GE-den 4948-10GE giver en højtydende adgang lag løsning, der kan udnytte ECMP og 10gige uplinks. Ingen særlige krav er nødvendige. 4948-10GE kan bruge et lag 2 Cisco IOS-billede eller et lag 2/3 Cisco IOS-billede, hvilket giver en optimal pasform i begge omgivelser.
Cisco Catalyst 4948-10GE-den 4948-10GE giver en højtydende adgang lag løsning, der kan udnytte ECMP og 10gige uplinks. Ingen særlige krav er nødvendige. 4948-10GE kan bruge et lag 2 Cisco IOS-billede eller et lag 2/3 Cisco IOS-billede, hvilket giver en optimal pasform i begge omgivelser.