




Cisco Data Center Infrastructure 2.5 Design Guide
Server Cluster Designs with Ethernet
Una panoramica di alto livello dei server e dei componenti di rete utilizzati nel modello di cluster server è fornita nel Capitolo 1 “Data Center Architecture Overview.”Questo capitolo descrive lo scopo e la funzione di ogni livello del modello di cluster server in modo più dettagliato. Sono incluse le seguenti sezioni:
•![]() Obiettivi Tecnici
Obiettivi Tecnici
•![]() Distribuite l’Inoltro e la Latenza
Distribuite l’Inoltro e la Latenza
•![]() Parità di Costo di Routing Multi-Path
Parità di Costo di Routing Multi-Path
•![]() Cluster di Server di Design—Modello dualistico
Cluster di Server di Design—Modello dualistico
•![]() Cluster di Server di Design—Modello a Tre livelli
Cluster di Server di Design—Modello a Tre livelli
•![]() Hardware e Moduli
Hardware e Moduli

Nota ![]() I modelli trattati in questo capitolo non sono state verificate in Cisco test di laboratorio a causa delle dimensioni e la portata di test che sarebbe necessario. I modelli a due livelli che sono coperti sono disegni simili che sono stati implementati nelle reti di produzione del cliente.
I modelli trattati in questo capitolo non sono state verificate in Cisco test di laboratorio a causa delle dimensioni e la portata di test che sarebbe necessario. I modelli a due livelli che sono coperti sono disegni simili che sono stati implementati nelle reti di produzione del cliente.
Obiettivi tecnici
Quando si progetta una grande rete di cluster aziendali, è fondamentale considerare obiettivi specifici. Non esistono due cluster esattamente uguali; ognuno ha i propri requisiti specifici e deve essere esaminato da una prospettiva applicativa per determinare i requisiti di progettazione particolari. Tenere conto delle seguenti considerazioni tecniche:
•![]() Latenza – Nel trasporto di rete, la latenza può influire negativamente sulle prestazioni complessive del cluster. L’utilizzo di piattaforme di commutazione che impiegano un’architettura di commutazione a bassa latenza aiuta a garantire prestazioni ottimali. La principale fonte di latenza è lo stack di protocollo e l’implementazione hardware NIC utilizzata sul server. L’ottimizzazione dei driver e le tecniche di offload della CPU, come TCP Offload Engine (TOE) e Remote Direct Memory Access (RDMA), possono aiutare a ridurre la latenza e ridurre il sovraccarico di elaborazione sul server.
Latenza – Nel trasporto di rete, la latenza può influire negativamente sulle prestazioni complessive del cluster. L’utilizzo di piattaforme di commutazione che impiegano un’architettura di commutazione a bassa latenza aiuta a garantire prestazioni ottimali. La principale fonte di latenza è lo stack di protocollo e l’implementazione hardware NIC utilizzata sul server. L’ottimizzazione dei driver e le tecniche di offload della CPU, come TCP Offload Engine (TOE) e Remote Direct Memory Access (RDMA), possono aiutare a ridurre la latenza e ridurre il sovraccarico di elaborazione sul server.
La latenza potrebbe non essere sempre un fattore critico nella progettazione del cluster. Ad esempio, alcuni cluster potrebbero richiedere un’elevata larghezza di banda tra i server a causa di una grande quantità di trasferimento di file in blocco, ma potrebbero non fare molto affidamento sulla messaggistica IPC (Inter-Process Communication) da server a server, che può essere influenzata da un’elevata latenza.
•![]() Connettività mesh / mesh parziale-I progetti di cluster di server di solito richiedono una mesh o un tessuto mesh parziale per consentire la comunicazione tra tutti i nodi del cluster. Questo tessuto mesh viene utilizzato per condividere stato, dati e altre informazioni tra i server master-to-compute e compute-to-compute nel cluster. Anche la connettività mesh o mesh parziale dipende dall’applicazione.
Connettività mesh / mesh parziale-I progetti di cluster di server di solito richiedono una mesh o un tessuto mesh parziale per consentire la comunicazione tra tutti i nodi del cluster. Questo tessuto mesh viene utilizzato per condividere stato, dati e altre informazioni tra i server master-to-compute e compute-to-compute nel cluster. Anche la connettività mesh o mesh parziale dipende dall’applicazione.
•![]() Throughput elevato: la possibilità di inviare un file di grandi dimensioni in un determinato periodo di tempo può essere fondamentale per il funzionamento e le prestazioni del cluster. I cluster di server in genere richiedono una quantità minima di larghezza di banda non bloccante disponibile, che si traduce in un modello di oversubscription basso tra i livelli di accesso e core.
Throughput elevato: la possibilità di inviare un file di grandi dimensioni in un determinato periodo di tempo può essere fondamentale per il funzionamento e le prestazioni del cluster. I cluster di server in genere richiedono una quantità minima di larghezza di banda non bloccante disponibile, che si traduce in un modello di oversubscription basso tra i livelli di accesso e core.
•![]() Rapporto di oversubscription-Il rapporto di oversubscription deve essere esaminato in più punti di aggregazione nel progetto, tra cui la scheda di linea per cambiare larghezza di banda fabric e l’input fabric per passare alla larghezza di banda uplink.
Rapporto di oversubscription-Il rapporto di oversubscription deve essere esaminato in più punti di aggregazione nel progetto, tra cui la scheda di linea per cambiare larghezza di banda fabric e l’input fabric per passare alla larghezza di banda uplink.
•![]() Supporto Jumbo frame – Sebbene i frame jumbo potrebbero non essere utilizzati nell’implementazione iniziale di un cluster di server, è una caratteristica molto importante necessaria per una maggiore flessibilità o per possibili requisiti futuri. La costruzione del pacchetto TCP/IP pone un sovraccarico aggiuntivo sulla CPU del server. L’uso di frame jumbo può ridurre il numero di pacchetti, riducendo così questo sovraccarico.
Supporto Jumbo frame – Sebbene i frame jumbo potrebbero non essere utilizzati nell’implementazione iniziale di un cluster di server, è una caratteristica molto importante necessaria per una maggiore flessibilità o per possibili requisiti futuri. La costruzione del pacchetto TCP/IP pone un sovraccarico aggiuntivo sulla CPU del server. L’uso di frame jumbo può ridurre il numero di pacchetti, riducendo così questo sovraccarico.
•![]() Densità delle porte: i cluster di server potrebbero dover scalare fino a decine di migliaia di porte. In quanto tali, richiedono piattaforme con un alto livello di prestazioni di commutazione di pacchetto, una grande quantità di larghezza di banda del tessuto switch e un alto livello di densità delle porte.
Densità delle porte: i cluster di server potrebbero dover scalare fino a decine di migliaia di porte. In quanto tali, richiedono piattaforme con un alto livello di prestazioni di commutazione di pacchetto, una grande quantità di larghezza di banda del tessuto switch e un alto livello di densità delle porte.
Ha distribuito l’inoltro e la latenza
Il commutatore di serie del catalizzatore 6500 di Cisco ha la capacità unica di sostenere un pacchetto centrale che inoltra o l’architettura distribuita facoltativa di inoltro, mentre il catalizzatore 4948-10GE di Cisco è una singola progettazione centrale di ASIC con la linea fissa velocità che inoltra la prestazione. I moduli della scheda di linea Cisco 6700 supportano un modulo opzionale della scheda figlia chiamato DFC (Distributed Forwarding Card). Il DFC consente decisioni di routing locali si verificano su ogni scheda di linea implementando una base di informazioni di inoltro locale (FIB). La tabella FIB sul PFC Sup720 mantiene la sincronizzazione con ogni tabella FIB DFC sulle schede di linea per garantire l’integrità del routing in tutto il sistema.
Quando la scheda DFC opzionale non è presente, una ricerca di intestazione compatta viene inviata al PFC3 sul Sup720 per determinare dove sul tessuto switch inoltrare ogni pacchetto. Quando è presente un DFC, la scheda di linea può passare un pacchetto direttamente attraverso il tessuto switch alla scheda di linea di destinazione senza consultare Sup720. La differenza di prestazioni può variare da 30 MPP a livello di sistema senza DFC a 48 Mpp per slot con DFC. Il commutatore fisso del catalizzatore 4948-10GE di configurazione ha un tasso del cavo, architettura non bloccante che sostiene fino alla prestazione di 101,18 Mpps, fornente la prestazione superiore di strato di accesso per la cima delle progettazioni dello scaffale.
Le prestazioni di latenza possono variare in modo significativo quando si confrontano i modelli di inoltro distribuito e centrale. La tabella 3-1 fornisce un esempio di latenze misurate su una scheda di linea 6704 con e senza DFC.
| 6704 con DFC (Porta-a-Porta in Microsecondi attraverso Fabric Switch) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
dimensione del Pacchetto (B) |
||||||||||
|
la Latenza (ms) |
||||||||||
| 6704 senza DFC (Porta-a-Porta in Microsecondi attraverso Fabric Switch) | ||||||||||
|
dimensione del Pacchetto (B) |
||||||||||
|
la Latenza (ms) |
||||||||||
La differenza di latenza tra un DFC abilitato e la scheda di linea non abilitata per DFC potrebbe non apparire significativa. Tuttavia, in un’architettura di inoltro centrale 6500, la latenza può aumentare all’aumentare dei tassi di traffico a causa della contesa per la ricerca condivisa sul bus centrale. Con un DFC, il percorso di ricerca è dedicato a ciascuna scheda di linea e la latenza è costante.
Larghezza di banda del sistema Catalyst 6500
La larghezza di banda del sistema disponibile non cambia quando vengono utilizzati DFC. I DFC migliorano l’elaborazione dei pacchetti al secondo (pps) del sistema complessivo. La tabella 3-2 riassume le prestazioni di throughput e larghezza di banda per i moduli che supportano i DFC, oltre ai vecchi moduli bus CEF256 e classic.
| Configurazione di Sistema con Sup720 | velocità di trasmissione in Mpps | Gbps di larghezza di Banda in |
|
la serie Classica di moduli |
Fino a 15 Mpps (per sistema) |
16 G bus condiviso (classico bus) |
|
CEF256 moduli della Serie |
Fino al 30 Mpps (per sistema) |
1x 8 G (dedicato per slot) |
|
Mix di classico con CEF256 o CEF720 moduli della Serie |
Fino a 15 Mpps (per sistema) |
Scheda dipendente |
|
CEF720 moduli della Serie (6748, 6704, 6724) |
Fino al 30 Mpps (per sistema) |
2x 20 G (dedicato per slot) |
|
CEF720 Serie di moduli con DFC3 (6704 con DFC3, 6708 con DFC3, 6748 con DFC3 6724+DFC3) |
Sostenere fino a 48 Mpps (per slot) |
2x 20 G (dedicato per slot) |
anche se il 6513 potrebbe essere una valida soluzione per il livello di accesso di un cluster di grandi dimensioni modello, nota che c’è una miscela di canale singolo e doppio slot in questo telaio. Slot 1 a 8 sono a canale singolo e slot 9 a 13 sono a doppio canale, come mostrato in Figura 3-1.
Figura 3-1 Catalyst 6500 Canali in tessuto per Chassis e slot (6513 Focus
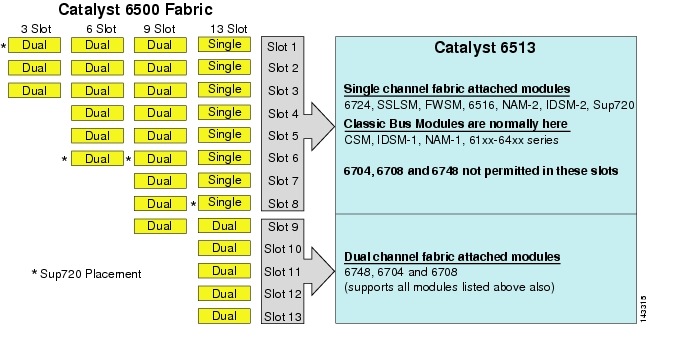
Quando viene utilizzato un Cisco Catalyst 6513, le schede a doppio canale, come la porta 6704-4 10GigE, la porta 6708-8 10GigE e le schede di linea SFP / rame 6748-48 possono essere posizionate solo negli slot da 9 a 13. Le schede di linea a canale singolo come le schede di linea SFP/rame 6724-24 possono essere utilizzate negli slot da 1 a 8. Il Sup720 utilizza slot 7 e 8, che sono singolo canale 20G tessuto attaccato. In contrasto con il 6513, il 6509 ha meno slot disponibili, ma in grado di supportare moduli a doppio canale in tutti gli slot perché ogni slot ha due canali al tessuto interruttore.
Nota ![]() Poiché l’ambiente cluster server richiede solitamente un’elevata larghezza di banda con caratteristiche di bassa latenza, si consiglia di utilizzare DFC in questi tipi di design.
Poiché l’ambiente cluster server richiede solitamente un’elevata larghezza di banda con caratteristiche di bassa latenza, si consiglia di utilizzare DFC in questi tipi di design.
Equal Cost Multi-Path Routing
Equal Cost multi-path (ECMP) routing è una tecnologia di bilanciamento del carico che ottimizza i flussi su più percorsi IP tra due sottoreti in un ambiente Cisco Express Forwarding-enabled. ECMP applica il bilanciamento del carico per i pacchetti TCP e UDP su base per flusso. I pacchetti non TCP / UDP, come ICMP, sono distribuiti su base pacchetto per pacchetto. ECMP è basato su RFC 2991 ed è sfruttato su altre piattaforme Cisco, come i prodotti PIX e Cisco Content Services Switch (CSS). ECMP è supportato su entrambe le piattaforme 6500 e 4948-10GE raccomandate nella progettazione del cluster di server.
I cambiamenti drammatici derivanti dal Layer 3 switching hardware ASICS e Cisco Express Forwarding hashing algoritmi aiuta a distinguere ECMP dal suo predecessore tecnologie. Il vantaggio principale in un progetto ECMP per le implementazioni del cluster di server è l’algoritmo di hashing combinato con un sovraccarico minimo o nullo della CPU nella commutazione di livello 3. L’algoritmo di hashing Cisco Express Forwarding è in grado di distribuire flussi granulari su più schede di linea a velocità di linea nell’hardware. L’impostazione predefinita dell’algoritmo di hashing è quella di hashare i flussi in base agli indirizzi IP di origine-destinazione di livello 3 e facoltativamente l’aggiunta di numeri di porta di livello 4 per un ulteriore livello di differenziazione. Il numero massimo di percorsi ECMP consentiti è otto.
La figura 3-2 illustra la progettazione di un cluster di server ECMP a 8 vie. Per semplificare l’illustrazione, vengono mostrati solo due switch di livello di accesso, ma possono essere supportati fino a 32 (64 10GigEs per nodo principale).
Figura 3-2 Progettazione di cluster di server ECMP a 8 vie
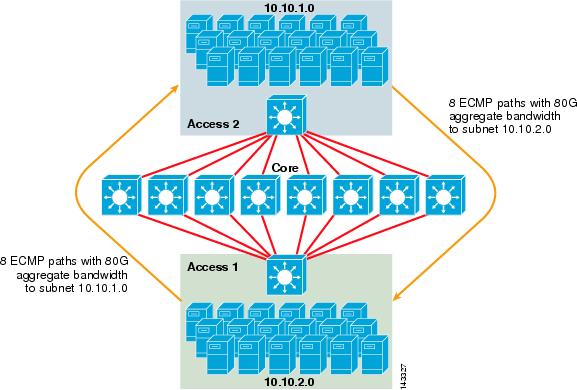
Nella Figura 3-2, ogni switch di livello di accesso può supportare una o più sottoreti di server collegati. Ogni interruttore ha una singola connessione 10GigE a ciascuno degli otto interruttori core utilizzando due 6704 schede di linea. Questa configurazione fornisce otto percorsi di 10GigE per un totale di 80 G di larghezza di banda Cisco Express Forwarding-enabled a qualsiasi altra sottorete nel tessuto cluster di server. Una query mostra percorso ip a un’altra sottorete su un altro switch mostra otto voci a costo uguale.
Il core è popolato da schede di linea 10GigE con DFC per consentire un tessuto di commutazione ad alta velocità completamente distribuito con latenza port-to-port molto bassa. Una query mostra percorso ip a uno switch livello di accesso mostra una singola voce di percorso su ciascuno degli otto switch principali.
Nota ![]() Anche se non è stato testato per questa guida, c’è un nuovo modulo 8 porte 10 Gigabit Ethernet (WS-X6708-10G-3C) che è stato recentemente introdotto per lo switch Catalyst serie 6500. Questa scheda di linea sarà testata per l’inclusione in questa guida in un secondo momento. Per domande sulla scheda 10GigE a 8 porte, fare riferimento alla scheda tecnica del prodotto.
Anche se non è stato testato per questa guida, c’è un nuovo modulo 8 porte 10 Gigabit Ethernet (WS-X6708-10G-3C) che è stato recentemente introdotto per lo switch Catalyst serie 6500. Questa scheda di linea sarà testata per l’inclusione in questa guida in un secondo momento. Per domande sulla scheda 10GigE a 8 porte, fare riferimento alla scheda tecnica del prodotto.
Ridondanza nella progettazione del cluster di server
La progettazione del cluster di server non è in genere implementata con CPU ridondanti o processori switch fabric. La resilienza è tipicamente raggiunta intrinsecamente nella progettazione e dal metodo che il cluster funziona nel suo complesso. Come descritto nel Capitolo 1″ Panoramica dell’architettura del data Center”, i nodi di calcolo nel cluster sono gestiti da nodi master che sono responsabili dell’assegnazione di processi specifici a ciascun nodo di calcolo e del monitoraggio delle loro prestazioni. Se un nodo di calcolo esce dal cluster, viene riassegnato a un nodo disponibile e continua a funzionare, anche se con minore potenza di elaborazione, fino a quando il nodo non è disponibile. Sebbene sia importante diversificare le connessioni dei nodi master nel cluster tra diversi switch di accesso, non è fondamentale per i nodi di calcolo.
Sebbene le CPU ridondanti siano certamente opzionali, è importante considerare la densità delle porte, in particolare per quanto riguarda le porte 10GE, dove è disponibile uno slot aggiuntivo al posto di un modulo Sup720 ridondante.
Nota ![]() Gli esempi in questo capitolo utilizzano progetti di CPU non ridondanti, che consentono un massimo di 64 porte 10GE per 6509 core node disponibili per le connessioni uplink di access node basate sull’utilizzo di una scheda di linea 10GigE a 8 porte 6708.
Gli esempi in questo capitolo utilizzano progetti di CPU non ridondanti, che consentono un massimo di 64 porte 10GE per 6509 core node disponibili per le connessioni uplink di access node basate sull’utilizzo di una scheda di linea 10GigE a 8 porte 6708.
Progettazione cluster di server—Modello a due livelli
Questa sezione descrive i vari approcci di una progettazione cluster di server che sfrutta ECMP e CEF distribuito. Ogni progetto dimostra come diverse configurazioni possono raggiungere vari livelli di oversubscription e possono scalare in modo flessibile, a partire da pochi nodi e crescendo a molti che supportano migliaia di server.
La progettazione del cluster server segue in genere un modello a due livelli costituito da livelli core e access. Poiché gli obiettivi di progettazione richiedono l’uso di Layer 3 ECMP e distributed forwarding per ottenere una larghezza di banda e una latenza altamente deterministica per server, un modello a tre livelli che introduce un altro punto di oversubscription non è solitamente desiderabile. I vantaggi di un modello a tre livelli sono descritti in Server Cluster Design-Three-Tier Model.
I tre calcoli principali da considerare quando si progetta una soluzione cluster di server sono le connessioni massime del server, la larghezza di banda per server e il rapporto di oversubscription. I progettisti cluster possono determinare questi valori in base alle prestazioni dell’applicazione, all’hardware del server e ad altri fattori, tra cui:
•![]() Numero massimo di connessioni GigE server su scala-I progettisti di cluster hanno in genere un’idea della scala massima richiesta al concetto iniziale. Un vantaggio della funzione di progettazione ECMP è che possono iniziare con un numero minimo di switch e server che soddisfano un particolare requisito di larghezza di banda, latenza e oversubscription e crescere in modo flessibile in modo basso/non dirompente fino alla massima scala mantenendo gli stessi valori di larghezza di banda, latenza e oversubscription.
Numero massimo di connessioni GigE server su scala-I progettisti di cluster hanno in genere un’idea della scala massima richiesta al concetto iniziale. Un vantaggio della funzione di progettazione ECMP è che possono iniziare con un numero minimo di switch e server che soddisfano un particolare requisito di larghezza di banda, latenza e oversubscription e crescere in modo flessibile in modo basso/non dirompente fino alla massima scala mantenendo gli stessi valori di larghezza di banda, latenza e oversubscription.
•![]() Larghezza di banda approssimativa per server – Questo valore può essere determinato semplicemente dividendo la larghezza di banda totale aggregata uplink per le connessioni GigE server totali sullo switch livello di accesso. Ad esempio, un livello di accesso Cisco 6509 con quattro uplink 10GigE ECMP con 336 porte di accesso al server può essere calcolato come segue:
Larghezza di banda approssimativa per server – Questo valore può essere determinato semplicemente dividendo la larghezza di banda totale aggregata uplink per le connessioni GigE server totali sullo switch livello di accesso. Ad esempio, un livello di accesso Cisco 6509 con quattro uplink 10GigE ECMP con 336 porte di accesso al server può essere calcolato come segue:
Uplink 4x10GigE con 336 server = 120 Mbps per server
Regolazione entrambi i lati dell’equazione diminuisce o aumenta la quantità di larghezza di banda per server.
Nota ![]() Questo è solo un valore approssimativo e serve solo come linea guida. Vari fattori influenzano la quantità effettiva di larghezza di banda che ogni server ha a disposizione. L’algoritmo di hash di distribuzione del carico ECMP divide il carico in base ai valori del livello 3 più il livello 4 e varia in base ai modelli di traffico. Inoltre, i parametri di configurazione come la limitazione della velocità, l’accodamento e i valori QoS possono influenzare la larghezza di banda effettiva raggiunta per server.
Questo è solo un valore approssimativo e serve solo come linea guida. Vari fattori influenzano la quantità effettiva di larghezza di banda che ogni server ha a disposizione. L’algoritmo di hash di distribuzione del carico ECMP divide il carico in base ai valori del livello 3 più il livello 4 e varia in base ai modelli di traffico. Inoltre, i parametri di configurazione come la limitazione della velocità, l’accodamento e i valori QoS possono influenzare la larghezza di banda effettiva raggiunta per server.
•![]() Rapporto di Oversubscription per server – Questo valore può essere determinato semplicemente dividendo il numero totale di connessioni GigE server per la larghezza di banda totale uplink aggregata sullo switch livello di accesso. Ad esempio, un access layer 6509 con quattro uplink ECMP 10GigE con 336 porte di accesso al server può essere calcolato come segue:
Rapporto di Oversubscription per server – Questo valore può essere determinato semplicemente dividendo il numero totale di connessioni GigE server per la larghezza di banda totale uplink aggregata sullo switch livello di accesso. Ad esempio, un access layer 6509 con quattro uplink ECMP 10GigE con 336 porte di accesso al server può essere calcolato come segue:
336 connessioni server GigE con larghezza di banda uplink 40G = 8.4:1 oversubscription ratio
Le sezioni seguenti dimostrano come questi valori variano, in base a diverse configurazioni hardware e di interconnessione, e servono come linea guida nella progettazione di configurazioni cluster di grandi dimensioni.
Nota ![]() Ai fini del calcolo, si presume che non vi sia alcuna scheda di linea per commutare l’oversubscription fabric sullo switch della serie Catalyst 6500. Lo slot a doppio canale fornisce una larghezza di banda massima di 40G al tessuto dell’interruttore. Una scheda 10GigE a 4 porte con tutte le porte a velocità di linea utilizzando pacchetti di dimensioni massime è considerata la migliore condizione possibile con poca o nessuna oversubscription. La quantità effettiva di larghezza di banda switch fabric disponibile varia in base alle dimensioni medie dei pacchetti. Questi calcoli dovrebbero essere ricalcolati se si dovesse utilizzare la scheda WS-X6708 a 8 porte 10GigE che è sovraiscritta a 2: 1.
Ai fini del calcolo, si presume che non vi sia alcuna scheda di linea per commutare l’oversubscription fabric sullo switch della serie Catalyst 6500. Lo slot a doppio canale fornisce una larghezza di banda massima di 40G al tessuto dell’interruttore. Una scheda 10GigE a 4 porte con tutte le porte a velocità di linea utilizzando pacchetti di dimensioni massime è considerata la migliore condizione possibile con poca o nessuna oversubscription. La quantità effettiva di larghezza di banda switch fabric disponibile varia in base alle dimensioni medie dei pacchetti. Questi calcoli dovrebbero essere ricalcolati se si dovesse utilizzare la scheda WS-X6708 a 8 porte 10GigE che è sovraiscritta a 2: 1.
Progetti ECMP a 4 e 8 vie con accesso modulare
I seguenti quattro esempi di progettazione dimostrano vari metodi di creazione e ridimensionamento del modello di cluster server a due livelli utilizzando ECMP a 4 e 8 vie. I problemi principali da considerare sono il numero di nodi principali e il numero massimo di uplink, poiché questi influenzano direttamente la scala massima, la larghezza di banda per server e i valori di oversubscription.
Nota ![]() Anche se non è stato testato per questa guida, c’è un nuovo modulo 8 porte 10 Gigabit Ethernet (WS-X6708-10G-3C) che è stato recentemente introdotto per lo switch Catalyst serie 6500. Questa scheda di linea sarà testata per l’inclusione nella guida in un secondo momento. Per domande sulla scheda 10GigE a 8 porte, fare riferimento alla scheda tecnica del prodotto.
Anche se non è stato testato per questa guida, c’è un nuovo modulo 8 porte 10 Gigabit Ethernet (WS-X6708-10G-3C) che è stato recentemente introdotto per lo switch Catalyst serie 6500. Questa scheda di linea sarà testata per l’inclusione nella guida in un secondo momento. Per domande sulla scheda 10GigE a 8 porte, fare riferimento alla scheda tecnica del prodotto.
Nota ![]() I collegamenti necessari per collegare il cluster di server a una rete esterna di campus o metropolitana non sono mostrati in questi esempi di progettazione, ma dovrebbero essere considerati.
I collegamenti necessari per collegare il cluster di server a una rete esterna di campus o metropolitana non sono mostrati in questi esempi di progettazione, ma dovrebbero essere considerati.
La figura 3-3 fornisce un esempio in cui due nodi principali vengono utilizzati per fornire una soluzione ECMP a 4 vie.
Figura 3-3 ECMP a 4 vie che utilizza due nodi Core
Un vantaggio di questo approccio è che un numero minore di switch core può supportare un numero elevato di server. Il possibile svantaggio è un’elevata oversubscription: bassa larghezza di banda per valore del server e grande esposizione a un errore del nodo principale. Si noti che gli uplink sono uplink L3 individuali e non sono EtherChannels.
La figura 3-4 mostra come l’aggiunta di due nodi principali al progetto precedente può aumentare notevolmente la scala massima mantenendo gli stessi valori di oversubscription e larghezza di banda per server.
Figura 3-4 ECMP a 4 vie con quattro nodi principali
La figura 3-5 mostra un design ECMP a 8 vie con due nodi principali.
Figura 3-5 ECMP a 8 vie con due nodi principali
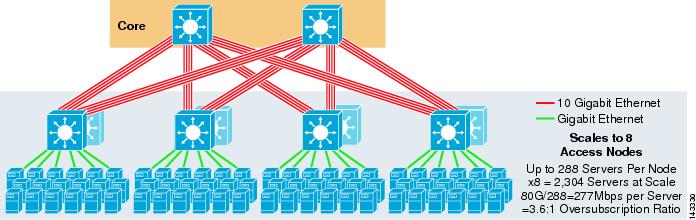
Come previsto, la larghezza di banda uplink aggiuntiva aumenta notevolmente la larghezza di banda per server e riduce il rapporto di oversubscription per server. Si noti come gli slot aggiuntivi presi in ogni switch di livello di accesso per supportare gli uplink a 8 vie riducono la scala massima in quanto il numero di server per switch viene ridotto a 288. Si noti che gli uplink sono uplink L3 individuali e non sono EtherChannels.
La figura 3-6 mostra un design ECMP a 8 vie con otto nodi principali.
Figura 3-6 ECMP a 8 vie che utilizza otto nodi core
Ciò dimostra come l’aggiunta di quattro nodi core allo stesso progetto precedente possa aumentare drasticamente la scala massima mantenendo gli stessi valori di oversubscription e larghezza di banda per server.
Progettazione ECMP a 2 vie con accesso 1RU
In molti ambienti cluster, la commutazione server basata su rack utilizzando piccoli switch nella parte superiore di ciascun rack server è desiderata o richiesta a causa di problemi di cablaggio, amministrativi, immobiliari o per soddisfare particolari obiettivi del modello di distribuzione.
La figura 3-7 mostra un esempio in cui due nodi principali vengono utilizzati per fornire una soluzione ECMP a 2 vie con switch di accesso 1RU 4948-10GE.
Figura 3-7 ECMP a 2 vie con due nodi principali e accesso 1RU
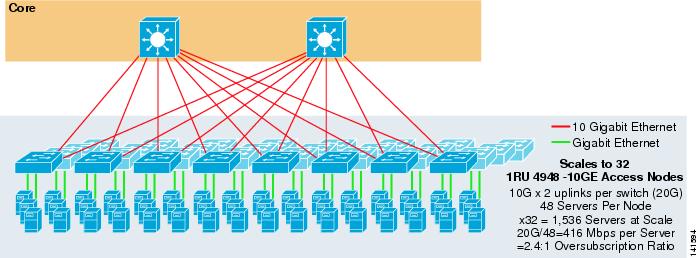
La scala massima è limitata a 1536 server ma fornisce oltre 400 Mbps di larghezza di banda con un basso rapporto di oversubscription. Poiché il 4948 ha solo due uplink 10GigE, questo design non può scalare oltre questi valori.
Nota ![]() Ulteriori informazioni sulla commutazione server basata su rack sono fornite nel Capitolo 3 “Server Cluster Designs with Ethernet.”
Ulteriori informazioni sulla commutazione server basata su rack sono fornite nel Capitolo 3 “Server Cluster Designs with Ethernet.”
Progettazione cluster di server—Modello a tre livelli
Sebbene un modello a due livelli sia più comune nei progetti di cluster di grandi dimensioni, è possibile utilizzare anche un modello a tre livelli. Il modello a tre livelli viene in genere utilizzato per supportare implementazioni di cluster di server di grandi dimensioni utilizzando switch 1RU o livello di accesso modulare.
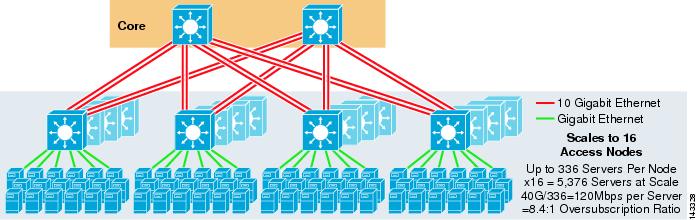
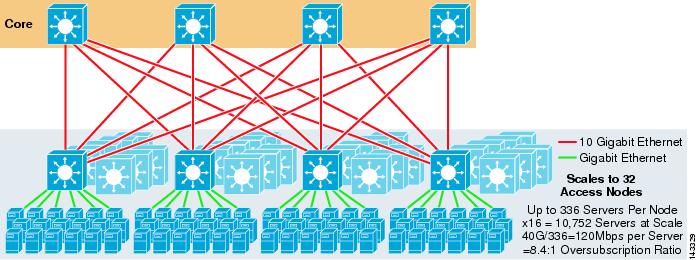
La figura 3-8 mostra un esempio su larga scala che sfrutta l’ECMP a 8 vie con 6500 switch core e di aggregazione e switch 1RU 4948-10GE access layer.
Figura 3-8 Modello a tre livelli con ECMP a 8 vie
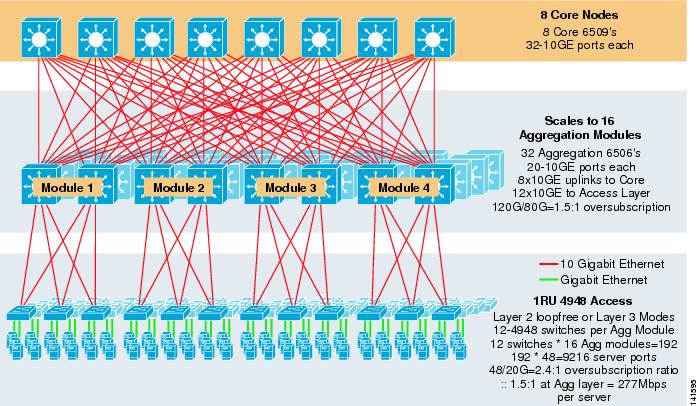
La scala massima è di oltre 9200 server con 277 Mbps di larghezza di banda con un basso rapporto di oversubscription. I vantaggi dell’approccio a tre livelli che utilizza gli switch di accesso 1RU includono quanto segue:
•![]() Modelli di distribuzione 1RU – Come accennato in precedenza, molte distribuzioni di modelli cluster di grandi dimensioni richiedono un approccio 1RU per un’installazione semplificata. Ad esempio, un ASP rotola fuori rack di server in un momento in cui scalare applicazioni cluster di grandi dimensioni. Il server rack è pre-assemblato e messo in scena fuori sede in modo tale che possa essere rapidamente installato e aggiunto al cluster in esecuzione. Questo di solito coinvolge una terza parte che costruisce i rack, pre-configura i server, e li pre-cavi con alimentazione ed Ethernet ad uno switch 1RU. Il rack rotola nel data center ed è semplicemente collegato e aggiunto al cluster dopo aver collegato gli uplink.
Modelli di distribuzione 1RU – Come accennato in precedenza, molte distribuzioni di modelli cluster di grandi dimensioni richiedono un approccio 1RU per un’installazione semplificata. Ad esempio, un ASP rotola fuori rack di server in un momento in cui scalare applicazioni cluster di grandi dimensioni. Il server rack è pre-assemblato e messo in scena fuori sede in modo tale che possa essere rapidamente installato e aggiunto al cluster in esecuzione. Questo di solito coinvolge una terza parte che costruisce i rack, pre-configura i server, e li pre-cavi con alimentazione ed Ethernet ad uno switch 1RU. Il rack rotola nel data center ed è semplicemente collegato e aggiunto al cluster dopo aver collegato gli uplink.
Senza un livello di aggregazione, la dimensione massima del modello di accesso 1RU è limitata a poco più di 1500 server. L’aggiunta di un livello di aggregazione consente al modello di accesso 1RU di scalare a dimensioni molto più grandi pur sfruttando il modello ECMP.
•![]() Centralizzazione degli switch core e aggregation-Con gli switch 1RU distribuiti nei rack, è possibile centralizzare gli switch modulari core e aggregation più grandi. Ciò può semplificare l’infrastruttura di alimentazione e cablaggio e migliorare l’utilizzo di rack real estate.
Centralizzazione degli switch core e aggregation-Con gli switch 1RU distribuiti nei rack, è possibile centralizzare gli switch modulari core e aggregation più grandi. Ciò può semplificare l’infrastruttura di alimentazione e cablaggio e migliorare l’utilizzo di rack real estate.
•![]() Consente la topologia senza loop di livello 2-Una grande rete di cluster che utilizza l’accesso ECMP di livello 3 può utilizzare molto spazio di indirizzamento sugli uplink e può aggiungere complessità al design. Ciò è particolarmente importante se viene utilizzato lo spazio degli indirizzi pubblici. L’approccio del modello a tre livelli si presta bene a una topologia di accesso senza loop di livello 2 che riduce il numero di sottoreti richieste.
Consente la topologia senza loop di livello 2-Una grande rete di cluster che utilizza l’accesso ECMP di livello 3 può utilizzare molto spazio di indirizzamento sugli uplink e può aggiungere complessità al design. Ciò è particolarmente importante se viene utilizzato lo spazio degli indirizzi pubblici. L’approccio del modello a tre livelli si presta bene a una topologia di accesso senza loop di livello 2 che riduce il numero di sottoreti richieste.
Quando viene utilizzato un modello senza loop Layer 2, è importante utilizzare un protocollo gateway predefinito ridondante come HSRP o GLBP per eliminare un singolo punto di errore se un nodo di aggregazione fallisce. In questo progetto, i moduli di aggregazione non sono interconnessi, consentendo un design Layer 2 senza loop che può sfruttare GLBP per il bilanciamento automatico del carico del gateway predefinito del server. GLBP distribuisce automaticamente l’assegnazione del gateway predefinito dei server tra i due nodi nel modulo di aggregazione. Dopo che un pacchetto arriva al livello di aggregazione, viene bilanciato attraverso il core utilizzando il tessuto ECMP a 8 vie. Sebbene GLBP non fornisca un hash di distribuzione del carico Layer 3/Layer 4 simile a CEF, è un’alternativa che può essere utilizzata con una topologia di accesso Layer 2.
Calcolo dell’Oversubscription
Il modello a tre livelli introduce due punti di oversubscription ai livelli di accesso e aggregazione, rispetto al modello a due livelli che ha un solo punto di oversubscription al livello di accesso. Per calcolare correttamente la larghezza di banda approssimativa per server e il rapporto di oversubscription, eseguire i seguenti due passaggi, che utilizzano Figura 3-8 come esempio:
Passo 1 ![]() Calcolare il rapporto di oversubscription e la larghezza di banda per server per entrambi i livelli di aggregazione e di accesso in modo indipendente.
Calcolare il rapporto di oversubscription e la larghezza di banda per server per entrambi i livelli di aggregazione e di accesso in modo indipendente.
•![]() livello di Accesso
livello di Accesso
–![]() Oversubscription—48GE server collegati/20G uplink di aggregazione = 2.4:1
Oversubscription—48GE server collegati/20G uplink di aggregazione = 2.4:1
–![]() la larghezza di Banda per server—20G uplink di aggregazione/48GigE server collegati = 416Mbps
la larghezza di Banda per server—20G uplink di aggregazione/48GigE server collegati = 416Mbps
•![]() a livello di Aggregazione
a livello di Aggregazione
–![]() Oversubscription—120G collegamenti di accesso/80G di uplink al core = 1.5:1
Oversubscription—120G collegamenti di accesso/80G di uplink al core = 1.5:1
Passo 2 ![]() Calcolare il combinato oversubscription rapporto e la larghezza di banda al server.
Calcolare il combinato oversubscription rapporto e la larghezza di banda al server.
Il rapporto di oversubscription effettivo è la somma dei due punti di oversubscription ai livelli di accesso e aggregazione.
1.5*2.4 = 3.6:1
Per determinare il valore di larghezza di banda reale per server, utilizzare la formula algebrica per le proporzioni:
a: b = c:d
La larghezza di banda per server al livello di accesso è stata determinata a 416 Mbps per server. Poiché il rapporto di oversubscription del livello di aggregazione è 1.5:1, è possibile applicare la formula di cui sopra come segue:
416:1 = x: 1.5
x=~264 Mbps per server
Hardware e moduli consigliati
Le piattaforme consigliate per la progettazione del modello cluster di server sono costituite dalla famiglia Cisco Catalyst 6500 con il modulo processore Sup720 e lo switch Catalyst 4948-10GE 1RU. L’alto tasso di commutazione, il tessuto di commutazione di grandi dimensioni, la bassa latenza, l’inoltro distribuito e la densità 10GigE rendono lo switch Catalyst serie 6500 ideale per tutti gli strati di questo modello. Il fattore di forma 1RU combinato con l’inoltro della velocità del filo, gli uplink 10GE e la latenza costante molto bassa rendono il 4948-10GE un’eccellente soluzione top of rack per il livello di accesso.
I seguenti sono raccomandati:
•![]() Sup720-Il Sup720 può essere costituito sia da PFC3A (default) o le più recenti schede figlia tipo PFC3B.
Sup720-Il Sup720 può essere costituito sia da PFC3A (default) o le più recenti schede figlia tipo PFC3B.
•![]() Schede di linea-Tutte le schede di linea devono essere serie 6700 e devono essere abilitate per l’inoltro distribuito con le schede figlie DFC3A o DFC3B.
Schede di linea-Tutte le schede di linea devono essere serie 6700 e devono essere abilitate per l’inoltro distribuito con le schede figlie DFC3A o DFC3B.
Nota ![]() Utilizzando tutti i moduli della serie CEF720 collegati a tessuto, la modalità di commutazione globale è compatta, il che consente al sistema di operare al massimo livello di prestazioni. Il catalizzatore 6509 può sostenere 10 moduli GigE in tutte le posizioni perché ogni scanalatura sostiene i canali doppi al tessuto dell’interruttore (il catalizzatore 6513 di Cisco non sostiene questo).
Utilizzando tutti i moduli della serie CEF720 collegati a tessuto, la modalità di commutazione globale è compatta, il che consente al sistema di operare al massimo livello di prestazioni. Il catalizzatore 6509 può sostenere 10 moduli GigE in tutte le posizioni perché ogni scanalatura sostiene i canali doppi al tessuto dell’interruttore (il catalizzatore 6513 di Cisco non sostiene questo).
•![]() Cisco Catalyst 4948-10GE—Il 4948-10GE fornisce una soluzione di livello di accesso ad alte prestazioni che può sfruttare ECMP e uplink 10GigE. Non sono necessari requisiti speciali. Il 4948-10GE può usare un’immagine dell’IOS di Cisco di strato 2 o un’immagine dell’IOS di Cisco di strato 2/3, permettendo una misura ottimale in entrambi gli ambienti.
Cisco Catalyst 4948-10GE—Il 4948-10GE fornisce una soluzione di livello di accesso ad alte prestazioni che può sfruttare ECMP e uplink 10GigE. Non sono necessari requisiti speciali. Il 4948-10GE può usare un’immagine dell’IOS di Cisco di strato 2 o un’immagine dell’IOS di Cisco di strato 2/3, permettendo una misura ottimale in entrambi gli ambienti.