Amazon MTurk
Probabilmente pulirai il tuo set di dati, ad esempio in base a elementi di risposta istruiti (molto buoni), elementi fasulli (anche buoni) e/o tempi di risposta (giusto, considera l’uso di TIME_RSI).
Hai gli ID worker di tutti i record rimanenti che soddisfano i tuoi criteri di qualità. Naturalmente, è possibile controllare manualmente tutte le assegnazioni in MTurk, ma richiede molto tempo. Meglio lavorare con un file CSV.
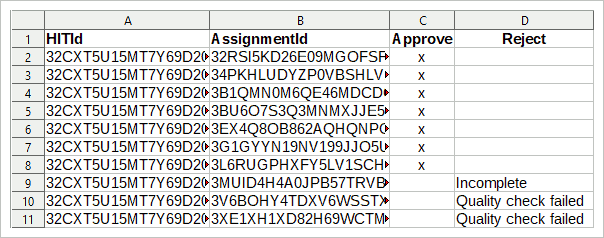
Per il file CSV, è necessario l’ID HIT e l’ID assegnazione. Se hai seguito il manuale sopra, avrai questi dati disponibili. Quindi, crea una tabella (con R, SPSS, LibreOffice Calc, Excel, …) con tre colonne dai tuoi dati: la prima colonna contiene l’ID HIT, la seconda colonna contiene l’ID assegnazione e la terza colonna deve contenere una “x” per ogni voce.
La prima riga della tabella è l’intestazione, i nomi delle variabili. Assicurarsi che i nomi delle variabili siano i seguenti (maiuscole e minuscole):
-
HITId
-
Assegnamentid
-
Approvare
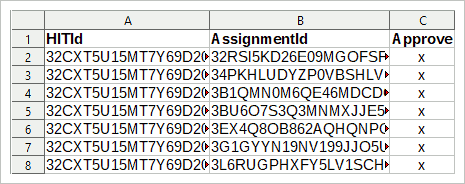
Quindi memorizzare la tabella come file CSV e in MTurk → Gestisci → Rivedi risultati fare clic sul pulsante Carica CSV. Selezionare il CSV appena salvato e confermare. MTurk ti chiederà se accettare questi incarichi.
Quando hai finito, rimangono solo le assegnazioni che non corrispondono ai criteri di qualità. Respingili, spiegando perché.
In alternativa, non eliminare immediatamente i record durante la pulizia dei dati, ma contrassegnarli. È quindi possibile caricare un file CSV con quattro colonne, il quarto chiamato “Rifiuta” e con una spiegazione per il rifiuto nella colonna. Questo farà in modo che non si rifiuta nessuno il cui ID si è perso.