




How to Check For Duplicate Content
så här hittar du Duplicate Content
Duplicate content bör minimeras över en webbplats, eftersom det kan göra det svårt för sökmotorer att bestämma vilken version som ska rankas för en fråga.
medan en ’duplicate content penalty’ är en myt i SEO, kan mycket liknande innehåll orsaka krypande ineffektivitet, utspädd PageRank och vara ett tecken på innehåll som kan konsolideras, tas bort eller förbättras.
det är värt att komma ihåg att duplicerat och liknande innehåll är en naturlig del av webben, vilket ofta inte är ett problem för sökmotorer som genom design kanoniserar webbadresser och filtrerar dem där det är lämpligt. Men i skala kan det vara mer problematiskt.
att förhindra duplicerat innehåll ger dig kontroll över vad som indexeras och rankas – snarare än att lämna det till sökmotorerna. Du kan begränsa crawl-budgetavfall och konsolidera indexering och länksignaler för att hjälpa till med rankning.
denna handledning går igenom hur du kan använda Screaming Frog SEO Spider för att hitta både exakt duplicerat innehåll och nästan duplicerat innehåll där någon text matchar mellan sidor på en webbplats.
duplicerat innehåll som identifieras av något verktyg, inklusive SEO-spindeln, måste ses över i sitt sammanhang. Titta på vår video, eller fortsätt läsa vår guide nedan.
för att komma igång, ladda ner SEO Spider som är gratis för att krypa upp till 500 webbadresser. De första 2 stegen är endast tillgängliga med licens. Om du är en gratis användare, hoppa sedan till nummer 3 i guiden.
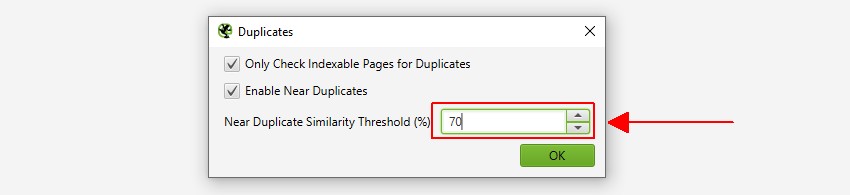
1) Aktivera ’nära dubbletter’ Via ’Config > innehåll > dubbletter’
som standard identifierar SEO Spider automatiskt exakta dubbla sidor. Men för att identifiera ’nära dubbletter’ måste konfigurationen vara aktiverad, vilket gör att den kan lagra innehållet på varje sida.
SEO Spider kommer att identifiera nära dubbletter med en 90% likhetsmatch, som kan justeras för att hitta innehåll med en lägre likhetströskel.
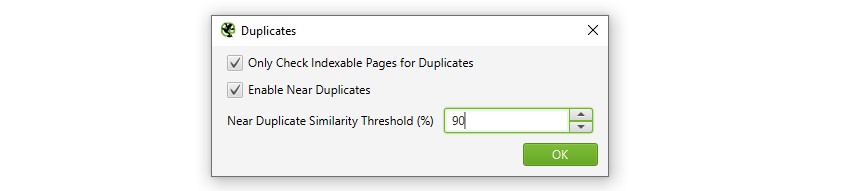
SEO Spider kommer också bara att kontrollera ’indexerbara’ sidor för dubbletter (för både exakta och nära dubbletter).
det betyder att om du har två webbadresser som är desamma, men en är kanoniserad till den andra (och därför ’icke-indexerbar’), kommer detta inte att rapporteras – om inte det här alternativet är inaktiverat.
om du är intresserad av att hitta problem med genomsökningsbudgeten, avmarkerar du alternativet ’kontrollera endast indexerbara sidor för dubbletter’, eftersom det kan hjälpa till att hitta områden med potentiellt genomsökningsavfall.
2) Justera ’innehållsområde’ för analys via ’Config > innehåll> område’
du kan konfigurera innehållet som används för nästan dubblettanalys. För en ny genomsökning rekommenderar vi att du använder standarduppsättningen och förfinar den senare när innehållet som används i analysen kan ses och övervägas.
SEO Spider utesluter automatiskt både nav-och sidfotelementen för att fokusera på huvudinnehållet. Men inte alla webbplatser är byggda med dessa HTML5-element, så du kan förfina innehållsområdet som används för analysen om det behövs. Du kan välja att inkludera eller utesluta HTML-taggar, klasser och ID i analysen.
till exempel har Screaming Frog-webbplatsen en mobilmeny utanför nav-elementet, som ingår i innehållsanalysen som standard. Även om detta inte är mycket av ett problem, i det här fallet, för att hjälpa till att fokusera på sidans huvudtext, kan klassnamnet ’mobile-menu__dropdown’ matas in i rutan ’Exclude Classes’.
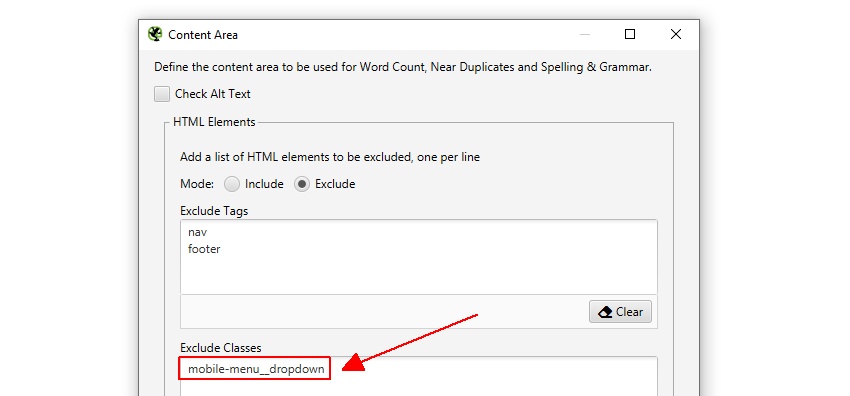
detta utesluter att menyn ingår i algoritmen för analys av duplicerat innehåll. Mer om detta senare.
3) genomsöka webbplatsen
öppna SEO-spindeln, skriv eller kopiera på webbplatsen du vill genomsöka i rutan ’Ange URL till spindel’ och tryck på ’Start’.
vänta tills genomsökningen är klar och når 100%, men du kan också se några detaljer i realtid.
4) Visa dubbletter på fliken ’Innehåll’
fliken innehåll har 2 filter relaterade till duplicerat innehåll, ’exakta dubbletter’ och ’nära dubbletter’.
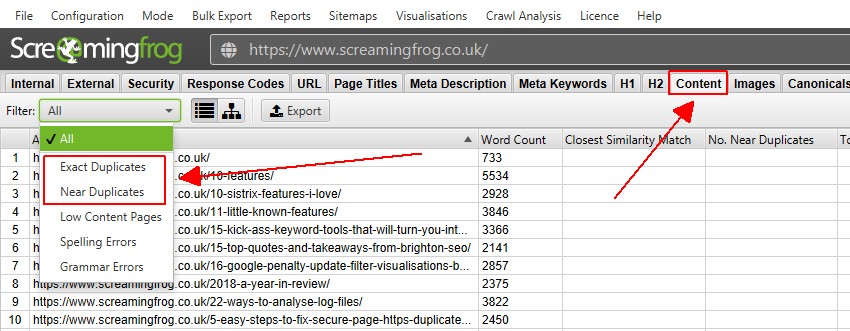
Endast ’exakta dubbletter’ är tillgängliga för visning i realtid under en genomsökning. ’Nära dubbletter’ kräver beräkning i slutet av genomsökningen via post ’Genomsökningsanalys’ för att den ska fyllas i med data.
det högra fönstret ’översikt’ visar ett meddelande ’(Crawl Analysis Required)’ mot filter som kräver att post crawl-analys fylls i med data.
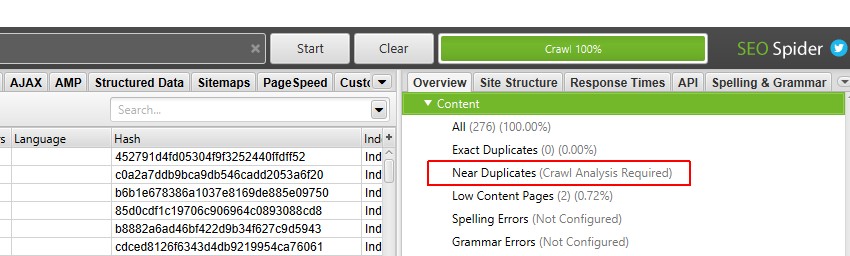
5) Klicka på ’Crawl Analysis> Start’ för att fylla i ’nära dubbletter’ Filter
för att fylla i ’nära dubbletter’ filter, ’närmaste likhet Match’ och ’nej. Nära Dubblettkolumner behöver du bara klicka på en knapp i slutet av genomsökningen.

men om du har konfigurerat ’Genomsökningsanalys’ tidigare, kanske du vill dubbelkolla, under ’Genomsökningsanalys > Konfigurera’ att ’nära dubbletter’ är markerad.
du kan också avmarkera andra objekt som också kräver post crawl-analys för att göra detta steg snabbare.
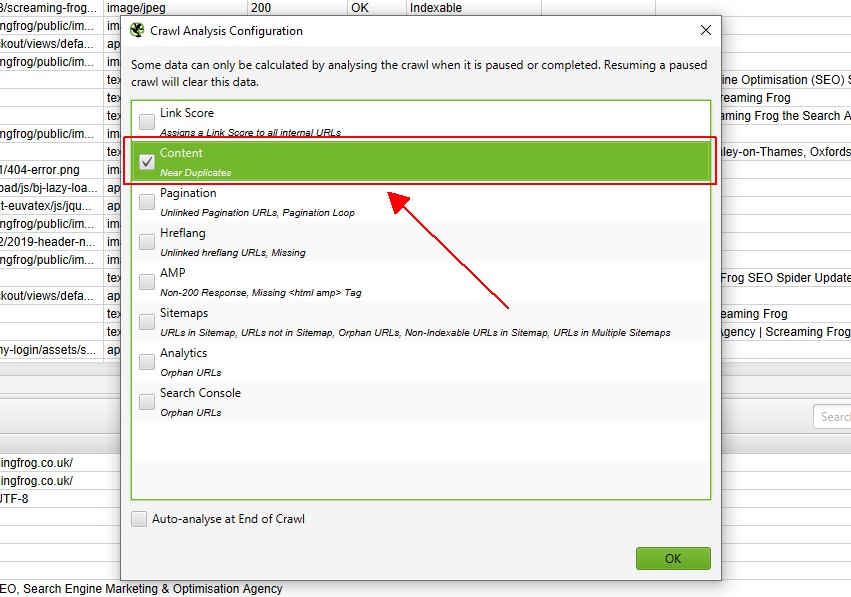
när crawl-analysen har slutförts kommer förloppsindikatorn ’analys’ att vara 100% och filtren kommer inte längre att ha meddelandet ’(Crawl Analysis Required)’.
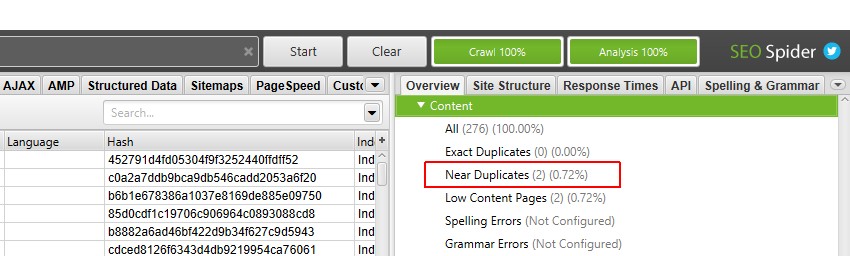
du kan nu visa det befolkade nära dubblettfiltret och kolumnerna.
6) Visa fliken ’Innehåll’ & ’exakt’ & ’nära’ dubbletter Filter
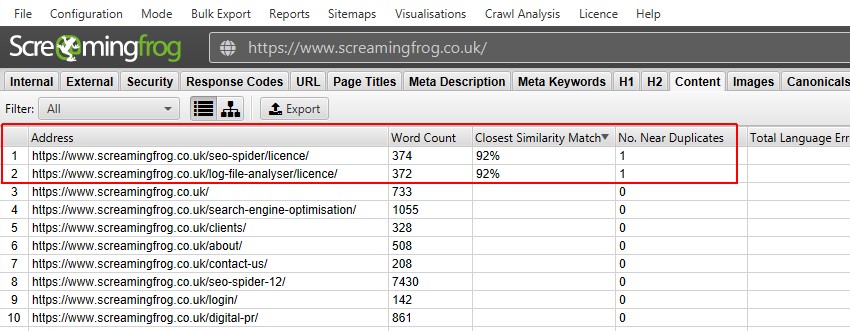
efter att ha utfört post crawl-analys, filtret ’nära dubbletter’, ’närmaste Likhetsmatchning’ och ’nej. Nära dubbletter kolumner kommer att fyllas. Endast webbadresser med innehåll över den valda likhetströskeln innehåller data, de andra förblir tomma. I det här fallet har Screaming Frog-webbplatsen bara två.
en genomsökning av en större webbplats, som BBC kommer att avslöja många fler.
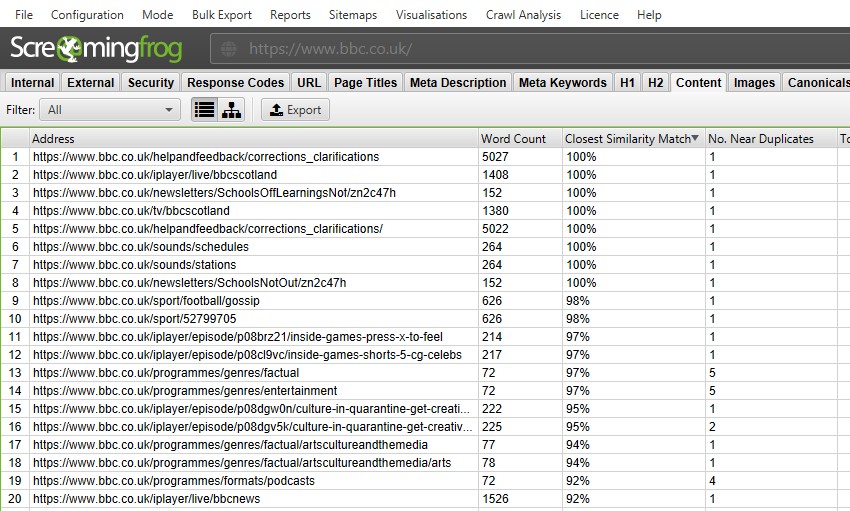
du kan filtrera efter följande–
- exakta dubbletter-detta filter visar sidor som är identiska med varandra med hjälp av MD5-algoritmen som beräknar ett ’hash’ – värde för varje sida och kan ses i kolumnen ’hash’. Denna kontroll utförs mot sidans fullständiga HTML. Det kommer att visa alla sidor med matchande hashvärden som är exakt samma. Exakta dubbla sidor kan leda till uppdelning av PageRank-signaler och oförutsägbarhet i rankningen. Det bör bara finnas en enda kanonisk version av en URL som finns och är länkad till internt. Andra versioner bör inte kopplas till, och de bör vara 301 omdirigeras till den kanoniska versionen.
- nära dubbletter-detta filter visar liknande sidor baserat på den konfigurerade likhetströskeln med minhash-algoritmen. Tröskeln kan justeras under ’Config > Spider > Content’ och är inställd på 90% som standard. Kolumnen närmaste Likhetsmatchning visar den högsta andelen likheter med en annan sida. Nej. Kolumnen nära dubbletter visar antalet sidor som liknar sidan baserat på likhetströskeln. Algoritmen körs mot text på sidan, snarare än hela HTML som exakta dubbletter. Innehållet som används för denna analys kan konfigureras under’Config > content > Area’. Sidor kan ha en 100% likhet, men bara vara en ’nära duplikat’ snarare än exakt duplikat. Detta beror på att exakta dubbletter utesluts så nära dubbletter, för att undvika att de flaggas två gånger. Likhetspoäng är också avrundade, så 99,5% eller högre visas som 100%.
nära dubbla sidor bör granskas manuellt eftersom det finns många legitima skäl för att vissa sidor är mycket lika i innehåll, till exempel variationer av produkter som har sökvolym runt deras specifika attribut.
webbadresser som flaggas som nästan dubbletter bör dock granskas för att överväga om de ska finnas som separata sidor på grund av deras unika värde för användaren, eller om de ska tas bort, konsolideras eller förbättras för att göra innehållet mer djupgående och unikt.
7) visa dubbla webbadresser via fliken ’Duplicate Details’
för ’exakta dubbletter’ är det lättare att bara visa dem i det övre fönstret med hjälp av filtret – eftersom de är grupperade tillsammans och delar samma ’hash’ – värde.
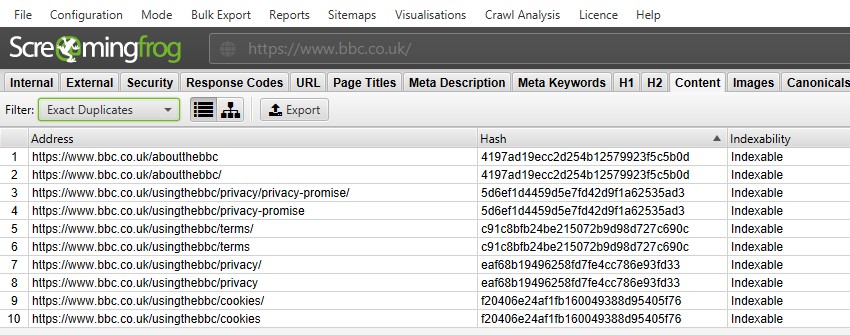
i ovanstående skärmdump har varje URL en motsvarande exakt dubblett på grund av en efterföljande snedstreck och icke-efterföljande snedstreckversion.
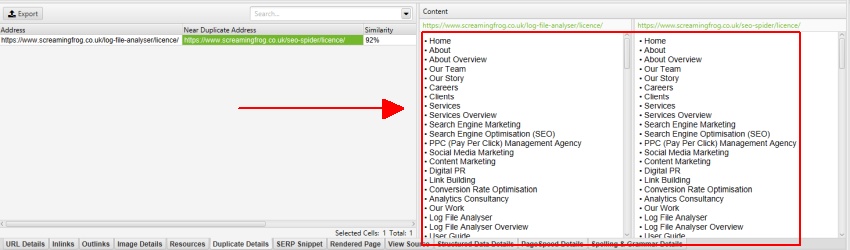
för’ Near duplicates’, klicka på fliken ’Duplicate Details’ längst ner som fyller den nedre fönsterrutan med ’near duplicate address’ och likheten för varje near-duplicate URL upptäckt.
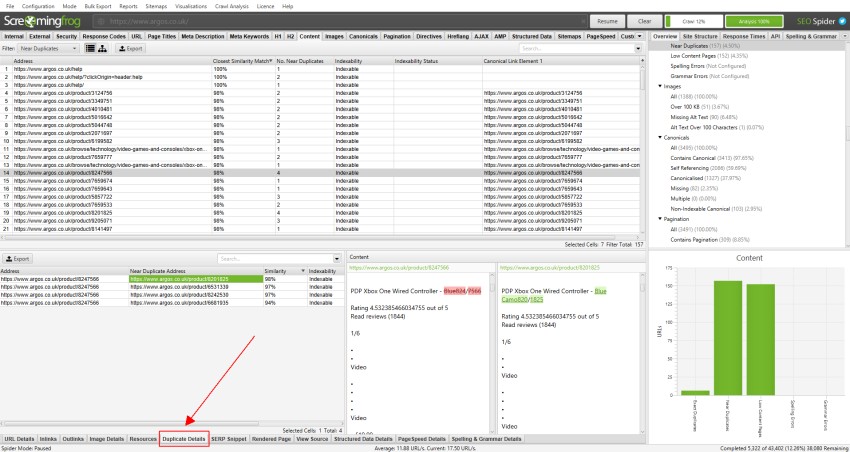
till exempel, om det finns 4 nästan dubbletter som upptäckts för en URL i det övre fönstret, kan dessa alla visas.
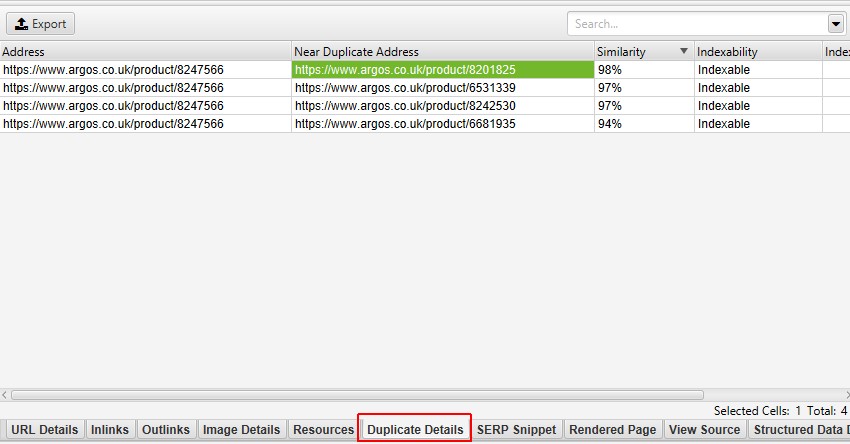
på höger sida av fliken Duplicate Details visas det Near duplicate-innehåll som upptäckts från sidorna och markerar skillnaderna mellan sidorna när du klickar på varje near duplicate-adress.
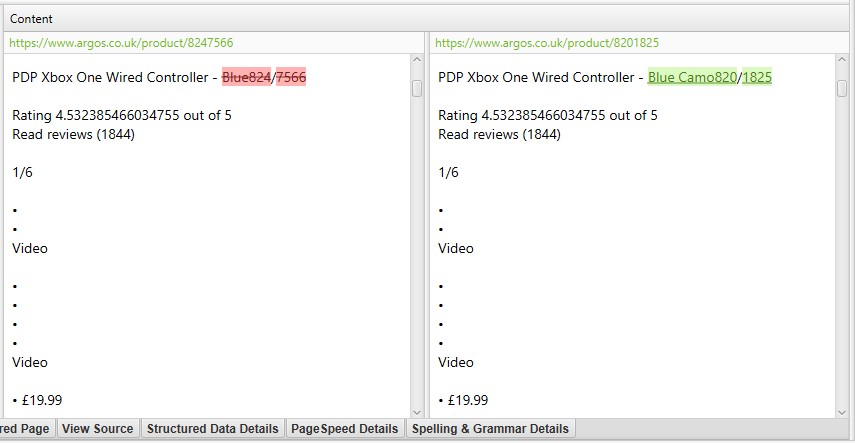
om det finns något duplicerat innehåll på fliken duplicerade detaljer som du inte vill vara en del av analysen av duplicerat innehåll, utesluter eller inkluderar HTML-element, klasser eller ID (som markeras i punkt 2), & kör igen genomsökningsanalys.
8) Bulk Export dubbletter
både exakt och nära dubbletter kan exporteras i bulk via ’Bulk Export > innehåll > exakt dubbletter’ och ’nära dubbletter’ export.

Sista Tips! Förfina tröskelvärdet för likhet & innehållsområde, & Re-run Crawl-analys
post-crawl du kan justera både tröskelvärdet för nära dubbletter och innehållsområdet som används för nära dubbletter.
du kan sedan köra genomsökningsanalys igen för att hitta mer eller mindre liknande innehåll – utan att genomsöka webbplatsen igen.
som tidigare beskrivits har Screaming Frog-webbplatsen en mobilmeny utanför nav-elementet, som ingår i innehållsanalysen som standard. Mobilmenyn kan ses i förhandsgranskningen av innehållet på fliken ’duplicate details’.
genom att exkludera rullgardinsmenyn ’mobile-menu__’ i rutan ’Exclude Classes’ under ’Config > content > Area’, tas mobilmenyn bort från innehållsförhandsgranskningen och near-duplicate-analysen.
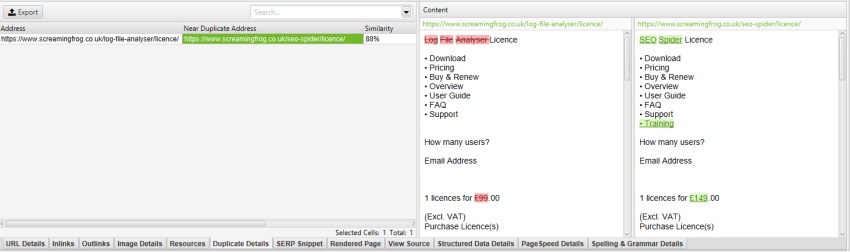
detta kan verkligen hjälpa till när du finjusterar identifieringen av nästan duplicerat innehåll till huvudinnehållsområden, utan att behöva genomsöka igen.
sammanfattning
guiden ovan ska illustrera hur du använder SEO Spider som en dubbel innehållskontroll för din webbplats. För de mest exakta resultaten, förfina innehållsområdet för analys och justera tröskeln för olika grupper av sidor.
läs även våra Vanliga frågor om Screaming Frog SEO Spider och fullständig användarhandbok för mer information om verktyget.
om du har ytterligare frågor, feedback eller förslag för att förbättra duplicate content-verktyget i SEO Spider, kontakta bara via support.