




hoe te controleren op dubbele inhoud
hoe dubbele inhoud te vinden
dubbele inhoud moet worden geminimaliseerd op een website, omdat het voor zoekmachines moeilijk kan maken om te beslissen welke versie voor een query te rangschikken.
hoewel een ‘duplicate content penalty’ een mythe is in SEO, kan zeer vergelijkbare content leiden tot kruipende inefficiënties, verdunnen PageRank, en een teken zijn van content die kan worden geconsolideerd, verwijderd of verbeterd.
het is de moeite waard om te onthouden dat dupliceren en soortgelijke inhoud een natuurlijk onderdeel van het web is, wat vaak geen probleem is voor zoekmachines die, door het ontwerp, URL ‘ s canonicaliseren en waar nodig filteren. Op grote schaal kan het echter problematischer zijn.
het voorkomen van dubbele inhoud geeft u controle over wat er geà ndexeerd en gerangschikt wordt – in plaats van het over te laten aan de zoekmachines. U kunt crawl budget afval te beperken en te consolideren indexering en link signalen om te helpen bij het rangschikken.
deze tutorial laat u zien hoe u de Screaming Frog SEO Spider kunt gebruiken om zowel exacte dubbele inhoud te vinden als bijna-dubbele inhoud waar sommige tekst overeenkomt tussen pagina ‘ s op een website.
Duplicate content geïdentificeerd door een tool, met inbegrip van de SEO Spider moet worden herzien in de context. Bekijk onze video, of lees verder onze gids hieronder.
om te beginnen, download de SEO Spider die gratis is voor het kruipen tot 500 url ‘ s. De eerste 2 stappen zijn alleen beschikbaar met een licentie. Als je een gratis gebruiker bent, ga dan naar nummer 3 in de gids.
1) Schakel ‘Near Duplicates’ in Via ‘Config > Content > Duplicates’
standaard zal SEO Spider automatisch exacte duplicaten identificeren. Echter, om ‘Near Duplicates’ te identificeren moet de configuratie ingeschakeld zijn, waardoor de inhoud van elke pagina kan worden opgeslagen.
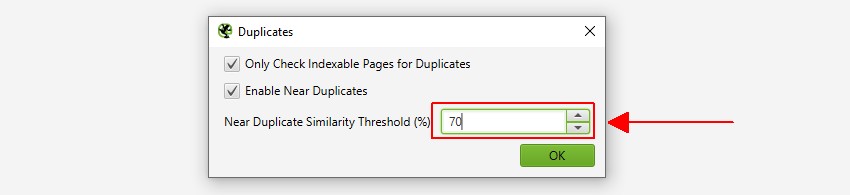
de SEO Spider identificeert bijna duplicaten met een overeenkomst van 90%, die kan worden aangepast om content te vinden met een lagere gelijkheidsdrempel.
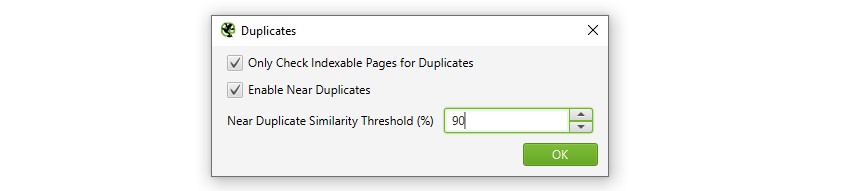
de SEO Spider zal ook alleen ‘indexeerbare’ pagina ‘ s controleren op duplicaten (voor zowel exacte als bijna-duplicaten).
dit betekent dat als u twee url ’s hebt die hetzelfde zijn, maar de ene is gecanoniseerd voor de andere (en dus’ niet-indexeerbaar’), dit niet zal worden gerapporteerd – tenzij deze optie is uitgeschakeld.
als u geïnteresseerd bent in het vinden van crawl budget problemen, vink dan de optie ‘Alleen indexeerbare pagina’ s controleren op duplicaten ‘ uit, omdat dit kan helpen bij het vinden van gebieden met potentieel crawl afval.
2) pas ‘Content Area’ aan voor analyse Via ‘Config > Content > Area’
u kunt de inhoud instellen die wordt gebruikt voor bijna-duplicaatanalyse. Voor een nieuwe crawl raden we aan de standaard set-up te gebruiken en deze later te verfijnen wanneer de inhoud die wordt gebruikt in de analyse kan worden gezien en overwogen.
de SEO Spider zal automatisch zowel de nav-als voettekstelementen uitsluiten om zich te concentreren op de inhoud van het hoofdlichaam. Echter, niet elke website is gebouwd met behulp van deze HTML5 elementen, dus je bent in staat om de inhoud gebied gebruikt voor de analyse te verfijnen indien nodig. U kunt kiezen voor ‘include’ of ‘exclude’ HTML tags, klassen en ID ‘ s in de analyse.
de website van Screaming Frog heeft bijvoorbeeld een mobiel menu buiten het nav-element, dat standaard in de inhoudsanalyse is opgenomen. Hoewel dit niet veel van een probleem, in dit geval, om te helpen zich te concentreren op de belangrijkste tekst van de pagina de class Naam ‘mobile-menu__dropdown’ kan worden ingevoerd in de ‘uitsluiten klassen’ doos.
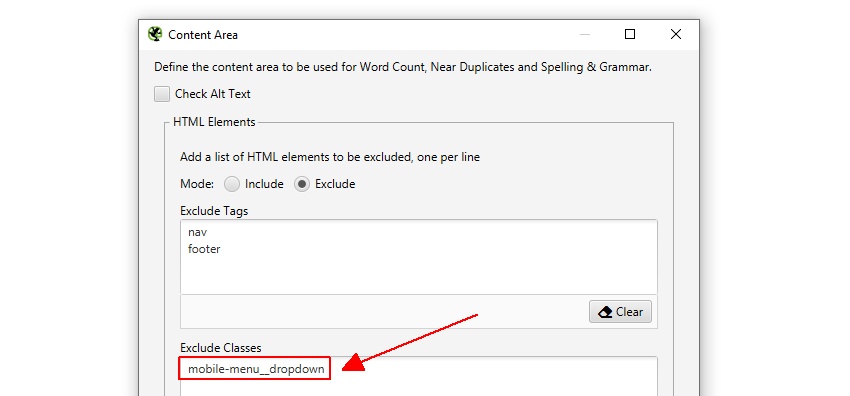
dit sluit het menu uit van het duplicate content analysis algoritme. Meer hierover later.
3) Crawl The Website
Open de SEO Spider, typ of kopieer de website die u wilt crawlen in de’ Enter URL to spider ‘box en druk op’Start’.
wacht tot de crawl voltooid is en 100% bereikt, maar u kunt ook enkele details in real-time bekijken.
4) Bekijk duplicaten in het tabblad’ Content ‘
het tabblad Content heeft 2 filters die gerelateerd zijn aan duplicaten,’ exact duplicaten ‘en’near duplicates’.
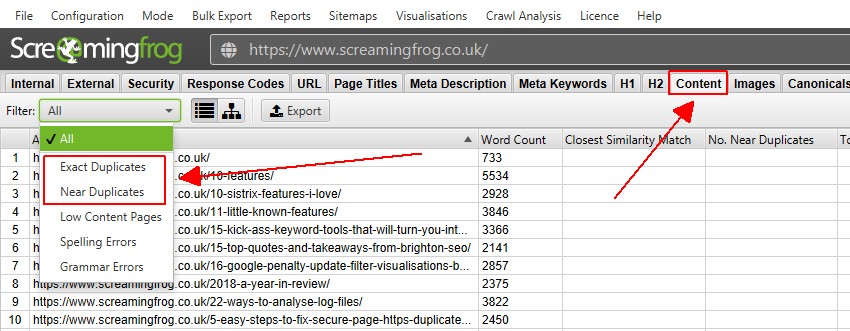
alleen ‘exacte duplicaten’ is beschikbaar om in real-time te bekijken tijdens een crawl. ‘Near Duplicates ‘vereisen berekening aan het einde van de crawl via post’ Crawl Analysis ‘ om het te vullen met gegevens.
in het rechterdeelvenster ‘ overzicht ‘wordt een’ (Crawl Analysis Required) ‘ – bericht weergegeven tegen filters die vereisen dat post crawl analysis wordt gevuld met gegevens.
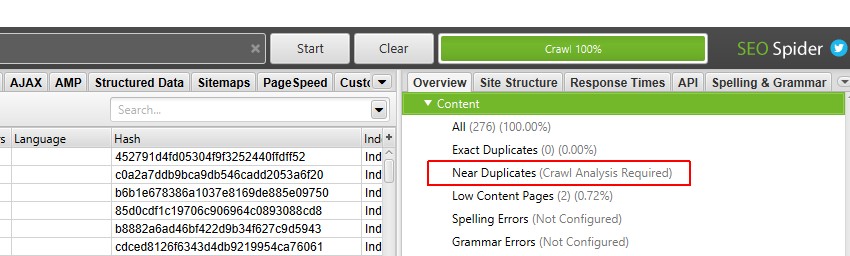
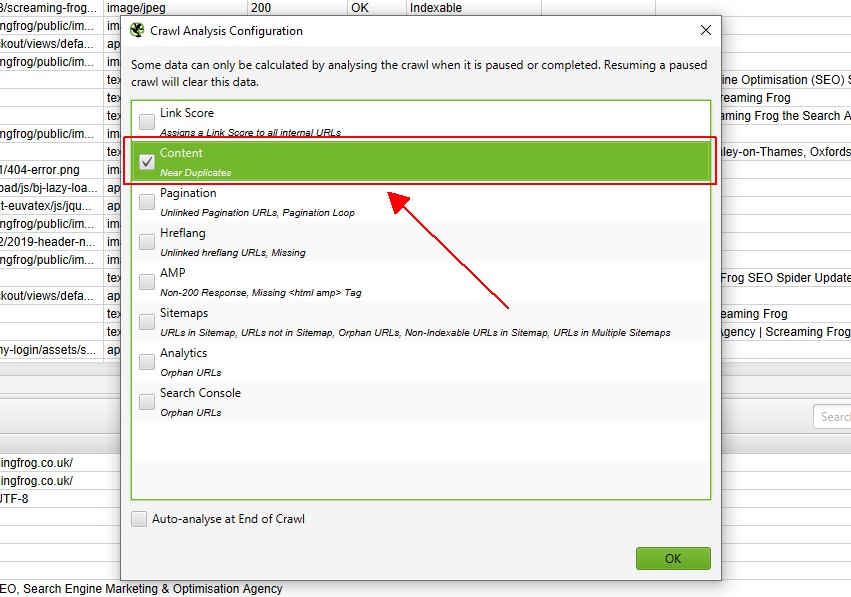
5) Klik op ‘Crawl Analysis> Start’ om ‘Near Duplicates’ Filter
te vullen om het ‘Near Duplicates’ filter, de ‘Closest similar Match’ en ‘No. In de buurt van de kolommen van duplicaten, hoeft u alleen maar op een knop te klikken aan het einde van de crawl.

echter, als u ‘Crawl Analysis’ eerder hebt geconfigureerd, kunt u onder ‘Crawl Analysis > Configure’ dubbel controleren of ‘Near Duplicates’ is aangevinkt.
u kunt ook andere items die ook post crawl analyse vereisen verwijderen om deze stap sneller te maken.
wanneer crawl analyse is voltooid, zal de voortgangsbalk voor’ analyse ‘100% zijn en zullen de filters niet langer het bericht’ (Crawl Analysis Required) ‘ hebben.
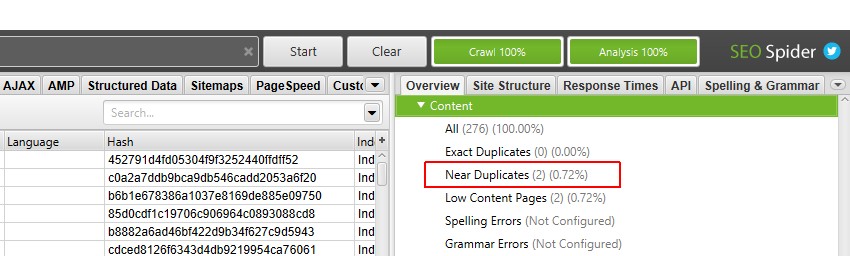
u kunt nu het filter en de kolommen voor dichtbevolkte near-duplicaten bekijken.
6) Bekijk ‘Content’ Tab & ‘Exact’ & ‘Near’ Duplicates Filters
na het uitvoeren van post crawl analyse, het ‘Near Duplicates’ filter, de ‘Closest similar Match’ en ‘No. Kolommen in de buurt van duplicaten zullen worden ingevuld. Alleen url ‘ s met inhoud boven de geselecteerde gelijkvormigheidsdrempel zullen gegevens bevatten, de andere zullen leeg blijven. In dit geval, de Screaming Frog website heeft slechts twee.
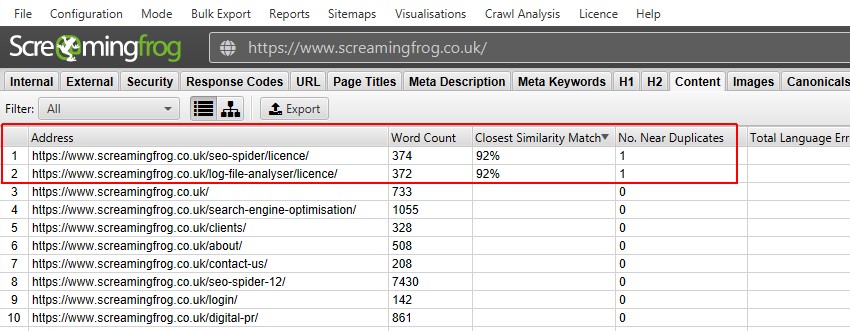
een crawl van een grotere website, zoals de BBC zal veel meer onthullen.
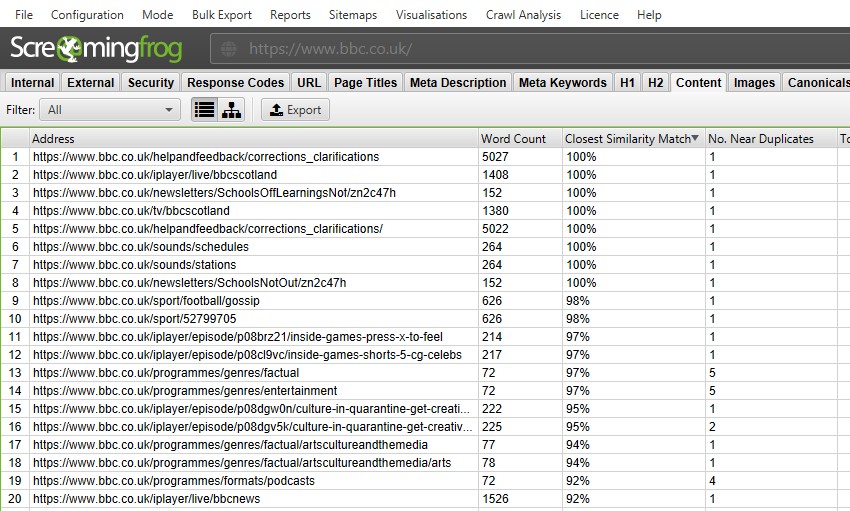
u kunt filteren op het volgende–
- exacte duplicaten-dit filter toont pagina ’s die identiek zijn aan elkaar met behulp van het MD5 algoritme dat een’ hash ‘waarde berekent voor elke pagina en kan worden gezien in de’ hash ‘ kolom. Deze controle wordt uitgevoerd aan de hand van de volledige HTML van de pagina. Het toont alle pagina ‘ s met overeenkomende hashwaarden die precies hetzelfde zijn. Exacte dubbele pagina ‘ s kunnen leiden tot het splitsen van PageRank signalen en onvoorspelbaarheid in ranking. Er zou slechts een enkele canonieke versie van een URL moeten zijn die bestaat en intern is gekoppeld. Andere versies moeten niet worden gekoppeld aan, en ze moeten worden 301 omgeleid naar de canonieke versie.
- in de buurt van duplicaten-dit filter toont vergelijkbare pagina ‘ s op basis van de geconfigureerde gelijkvormigheidsdrempel met behulp van het minhash-algoritme. De drempelwaarde kan worden aangepast onder ‘Config > Spider > Content’ en is standaard ingesteld op 90%. De kolom ‘dichtstbijzijnde overeenkomst’ toont het hoogste percentage gelijkenis met een andere pagina. De ‘ Nee. In de kolom Near Duplicates wordt het aantal pagina ‘ s weergegeven dat vergelijkbaar is met de pagina op basis van de gelijkvormigheidsdrempel. Het algoritme wordt uitgevoerd tegen tekst op de pagina, in plaats van de volledige HTML zoals exacte duplicaten. De inhoud die voor deze analyse wordt gebruikt, kan worden geconfigureerd onder ‘Config > Content > Area’. Pagina ’s kunnen een 100% gelijkenis hebben, maar alleen een’ bijna duplicaat ‘ zijn in plaats van een exact duplicaat. Dit komt omdat exacte duplicaten worden uitgesloten als dichtbijgelegen duplicaten, om te voorkomen dat ze twee keer worden gemarkeerd. Gelijkvormigheidsscores zijn ook afgerond, dus 99,5% of hoger wordt weergegeven als 100%.
bijna dubbele pagina ’s moeten handmatig worden bekeken omdat er vele legitieme redenen zijn dat sommige pagina’ s qua inhoud zeer vergelijkbaar zijn, zoals variaties van producten met zoekvolume rond hun specifieke attribuut.
URL ’s die als bijna-duplicaten zijn gemarkeerd, moeten echter worden herzien om na te gaan of ze als afzonderlijke pagina’ s moeten bestaan vanwege hun unieke waarde voor de gebruiker, of dat ze moeten worden verwijderd, geconsolideerd of verbeterd om de inhoud dieper en uniek te maken.
7) Bekijk Dubbele URL ’s via het tabblad’ Duplicate Details ‘
voor’ exacte duplicaten ‘is het makkelijker om ze gewoon in het bovenste venster te bekijken met behulp van het filter – omdat ze gegroepeerd zijn en dezelfde’ hash ‘ – waarde delen.
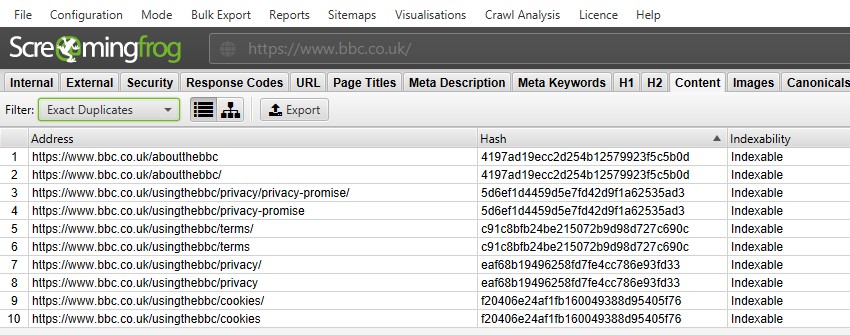
in de bovenstaande schermafbeelding heeft elke URL een overeenkomstig exact duplicaat als gevolg van een schuine en niet-schuine schuine versie.
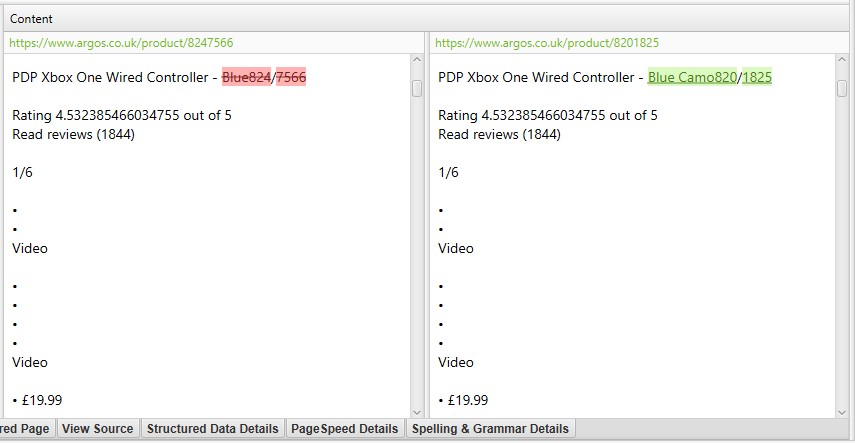
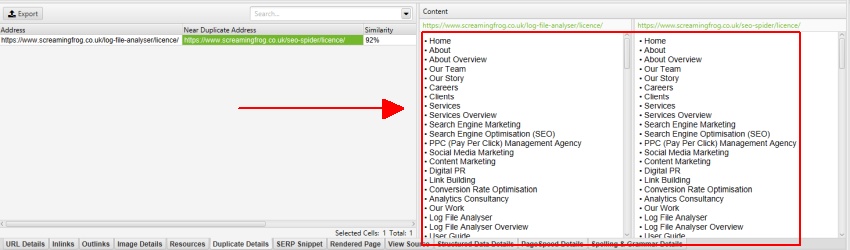
voor’ near duplicates’, klik op de’ Duplicate Details ’tab onderaan die het onderste venster vult met het’ near duplicate address ‘ en gelijkenis van elke near-duplicate url gevonden.
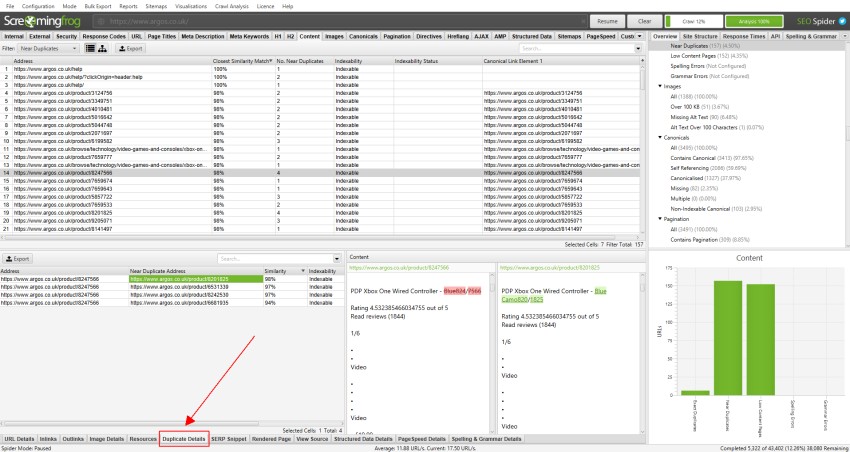
bijvoorbeeld, als er 4 bijna-duplicaten zijn gevonden voor een URL in het bovenste venster, kunnen deze allemaal worden bekeken.
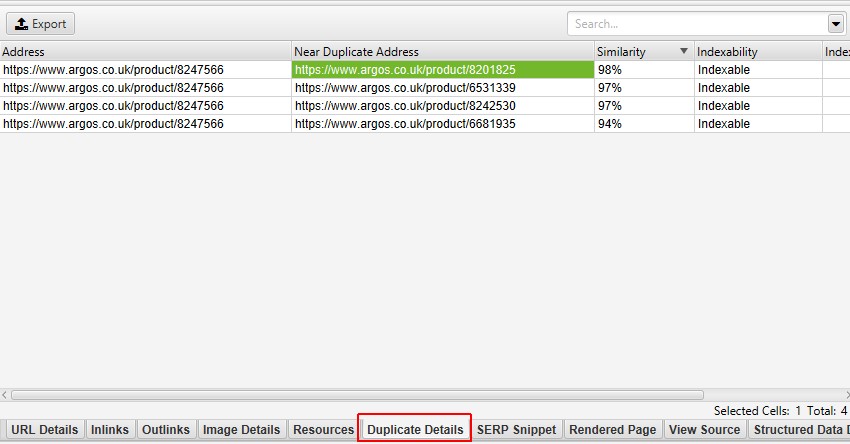
de rechterkant van het tabblad’ Duplicate Details ’toont de bijna dubbele inhoud die op de pagina’s is gevonden en markeert de verschillen tussen de pagina’ s wanneer u op elk ‘near duplicate address’ klikt.
als er sprake is van duplicate content in het tabblad duplicate details die u niet wilt gebruiken voor de duplicate content analysis, sluit dan HTML-elementen, klassen of ID ‘ s uit of voeg deze toe (zoals benadrukt in punt 2), & voer crawl analysis opnieuw uit.
8) Bulkuitvoer duplicaten
zowel exacte als bijna-duplicaten kunnen in bulk worden uitgevoerd via de “Bulkuitvoer > inhoud > exacte duplicaten” en “bijna-duplicaten” – uitvoer.

Laatste Tip! Similarity Threshold & Content Area, & re-run Crawl Analysis
Post-crawl u kunt zowel de similarity threshold als de content area die gebruikt wordt voor bijna-duplicate analyse aanpassen.
u kunt dan crawl analysis opnieuw uitvoeren om min of meer vergelijkbare inhoud te vinden – zonder de website opnieuw te crawlen.
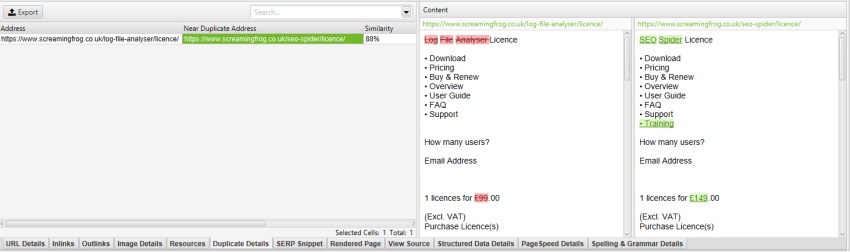
zoals eerder beschreven, heeft de Screaming Frog-website een mobiel menu buiten het nav-element, dat standaard in de inhoudanalyse is opgenomen. Het mobiele menu is te zien in de inhoud preview van het tabblad ‘duplicate details’.
door het ‘mobile-menu__dropdown’ uit te sluiten in het vak ‘Exclude Classes’ onder ‘Config > Content > Area’, wordt het mobiele menu verwijderd uit het contentvoorbeeld en de analyse van bijna-duplicaten.
dit kan echt helpen bij het verfijnen van de identificatie van bijna-dubbele inhoud naar hoofdinhoud gebieden, zonder de noodzaak om opnieuw te crawlen.
samenvatting
de bovenstaande gids moet illustreren hoe de SEO Spider te gebruiken als een duplicaat contentcontrole voor uw website. Voor de meest nauwkeurige resultaten, verfijn de inhoud gebied voor analyse en pas de drempel voor verschillende groepen pagina ‘ s.
lees ook onze Screaming Frog SEO Spider FAQs en de volledige gebruikershandleiding voor meer informatie over de tool.
als u nog vragen, feedback of suggesties heeft om de duplicate content tool in de SEO Spider te verbeteren, neem dan gewoon contact op via support.