




Slik Sjekker Du Etter Duplikatinnhold
Slik Finner Du Duplikatinnhold
Duplikatinnhold bør minimeres på tvers av et nettsted, da det kan gjøre det vanskelig for søkemotorer å bestemme hvilken versjon som skal rangeres for en spørring.
selv om en ‘duplikat innholdsstraff’ er en myte I SEO, kan svært likt innhold forårsake ineffektivitet i gjennomsøking, utvanne PageRank og være et tegn på innhold som kan konsolideres, fjernes eller forbedres.
det er verdt å huske at duplikat og lignende innhold er en naturlig del av nettet, noe som ofte ikke er et problem for søkemotorer som vil, ved design, kanonisere Nettadresser og filtrere dem der det er hensiktsmessig. Men i skala kan det være mer problematisk.
Ved Å Forhindre duplikatinnhold har Du kontroll over hva som er indeksert og rangert – i stedet for å overlate det til søkemotorene. Du kan begrense kravlesøk budsjett avfall og konsolidere indeksering og koble signaler for å hjelpe i rangeringen.
denne opplæringen går deg gjennom hvordan du kan bruke Screaming Frog SEO Spider til å finne både eksakt duplikat innhold og nesten duplikat innhold der noen tekst samsvarer mellom sider på et nettsted.
Duplikatinnhold identifisert av et hvilket som helst verktøy, inkludert SEO Spider, må gjennomgås i kontekst. Se vår video, eller fortsett å lese vår guide nedenfor.
FOR å komme i gang, last NED SEO Spider som er gratis for å krype opp til 500 Nettadresser. De første 2 trinnene er bare tilgjengelige med en lisens. Hvis du er en gratis bruker, så hopp til nummer 3 i guiden.
1) Aktiver ‘Nær Duplikater’ Via ‘Config > Innhold > Duplikater’
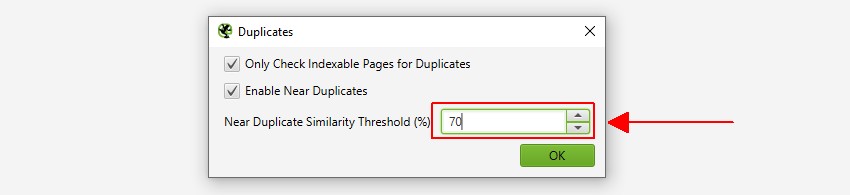
SOM STANDARD VIL SEO Spider automatisk identifisere eksakte dupliserte sider. Men for å identifisere ‘Nær Duplikater’ må konfigurasjonen være aktivert, noe som gjør det mulig å lagre innholdet på hver side.
SEO Spider vil identifisere nær duplikater med en 90% likhet kamp, som kan justeres for å finne innhold med en lavere likhet terskel.
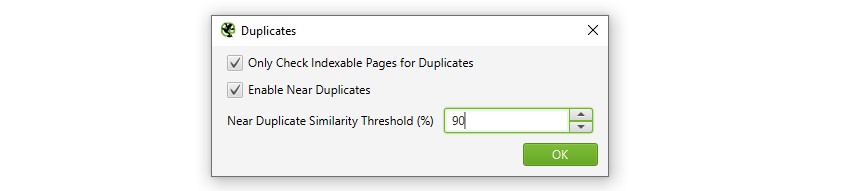
SEO Spider vil også bare sjekke Indekserbare sider for duplikater (for både eksakte og nær duplikater).
dette betyr at hvis du har to Nettadresser som er like, men den ene er kanonisert til den andre (og derfor ‘ikke-indekserbar’), vil dette ikke bli rapportert-med mindre dette alternativet er deaktivert.
hvis du er interessert i å finne problemer med kravlesøkbudsjett, fjerner du merket For Alternativet Bare Sjekk Indekserbare Sider for Duplikater, da dette kan bidra til å finne områder med potensielt kravlesøkavfall.
2) Juster ‘Innholdsområde’ For Analyse Via ‘Config > Innhold > Område’
du kan konfigurere innholdet som brukes til nesten duplikat analyse. For en ny gjennomgang anbefaler vi å bruke standardoppsettet og raffinere det senere når innholdet som brukes i analysen, kan ses og vurderes.
SEO Spider vil automatisk ekskludere både nav-og bunntekstelementene for å fokusere på hovedinnholdet. Imidlertid er ikke alle nettsteder bygget ved hjelp av DISSE HTML5-elementene, slik at du kan finjustere innholdsområdet som brukes til analysen om nødvendig. DU kan velge Å ‘inkludere’ ELLER ‘ekskludere’ HTML-koder, klasser og Id-Er i analysen.
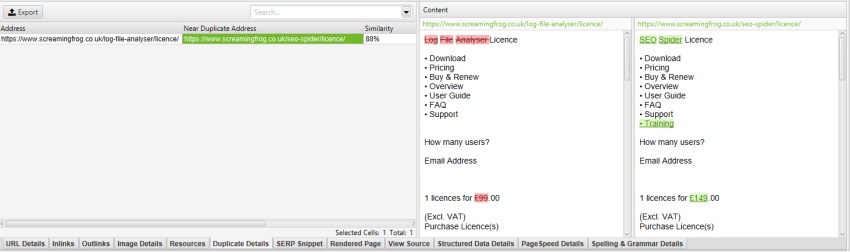
For Eksempel Har Screaming Frog-nettstedet en mobilmeny utenfor nav-elementet, som er inkludert i innholdsanalysen som standard. Selv om dette ikke er mye av et problem, i dette tilfellet, for å bidra til å fokusere på hovedteksten på siden, kan klassenavnet ‘mobile-menu__dropdown’ legges inn i’ Ekskluder Klasser ‘ – boksen.
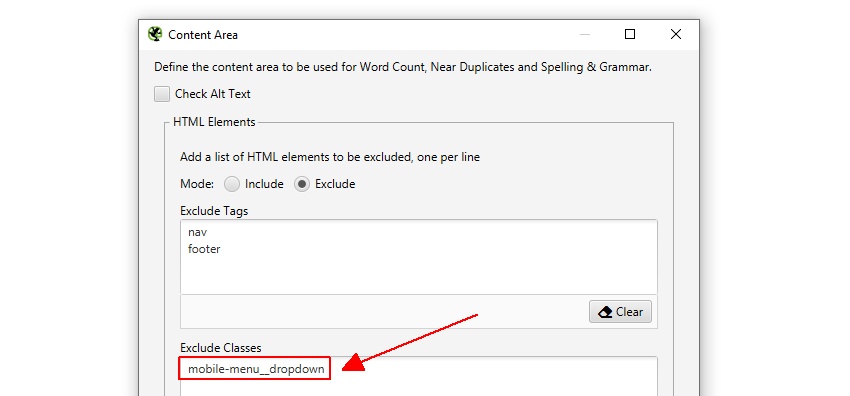
dette vil utelukke at menyen blir inkludert i algoritmen for duplikat innholdsanalyse. Mer om dette senere.
3) Gjennomsøk Nettstedet
Åpne SEO-Edderkoppen, skriv eller kopier på nettstedet du ønsker å gjennomsøke i Boksen’ Skriv INN URL til edderkopp ‘og trykk ‘Start’.
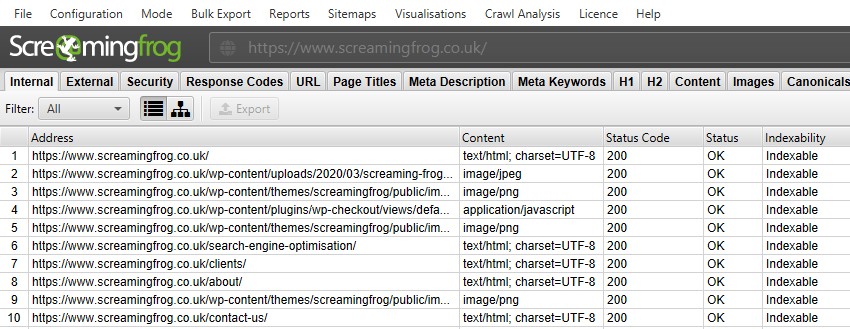
Vent Til gjennomsøkingen er ferdig og når 100%, men du kan også se noen detaljer i sanntid.
4) Se Duplikater I Innholdsfanen
innholdsfanen har 2 filtre relatert til duplikatinnhold, ‘eksakte duplikater ‘og’nær duplikater’.
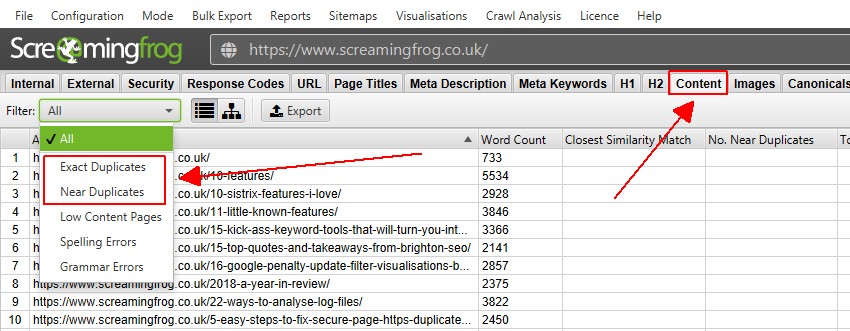
Bare ‘eksakte duplikater’ er tilgjengelig for visning i sanntid under en gjennomgang. ‘Nær Duplikater’ krever beregning på slutten av gjennomsøkingen via post ‘Gjennomsøkingsanalyse’ for at den skal fylles ut med data.
den høyre’ oversikt ‘ruten viser en’ (Kravlesøk Analyse Kreves) ‘ melding mot filtre som krever post gjennomsøk analyse fylles med data.
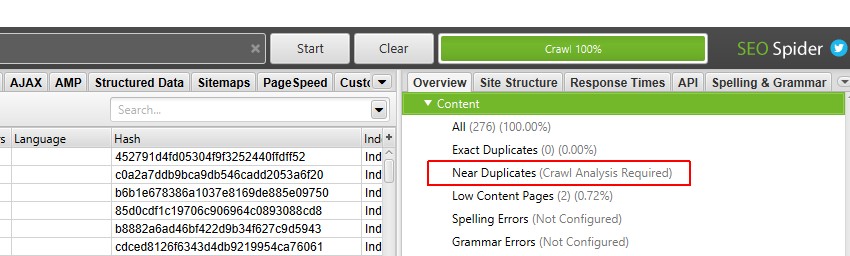
5) Klikk ‘Gjennomsøkingsanalyse > Start ‘For Å Fylle Ut’ Nær Duplikater ‘Filter
for å fylle ut Filteret’ nær Duplikater’, ‘Nærmeste Likhet’ Og ‘ Nei. Nær Duplikater kolonner, du trenger bare å klikke på en knapp på slutten av gjennomgangen.

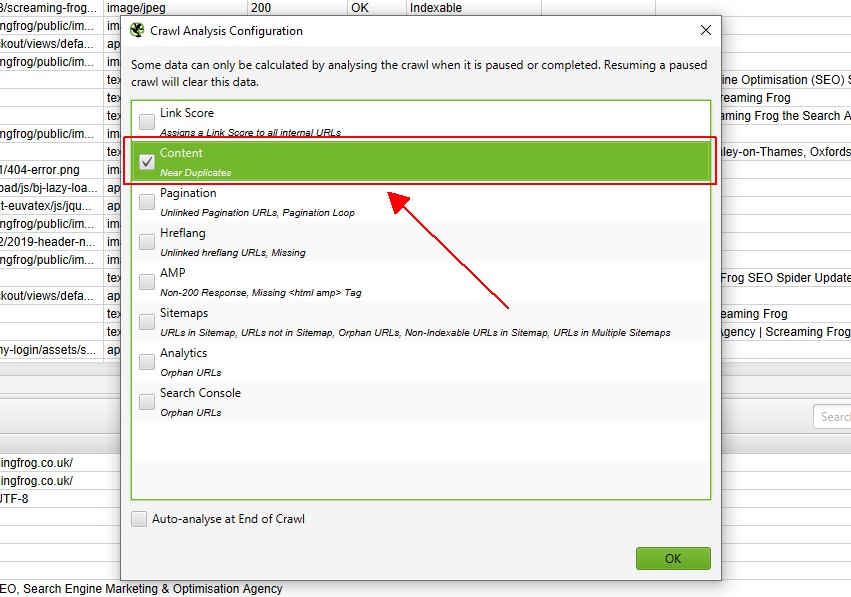
men hvis du har konfigurert Gjennomsøkingsanalyse tidligere, kan det hende du ønsker å dobbeltsjekke, Under ‘Gjennomsøkingsanalyse > Konfigurer’ At ‘Nær Duplikater’ er krysset av.
du kan også fjerne merket for andre elementer som også krever analyse av ettersøking for å gjøre dette trinnet raskere.
når kravlesøk analyse er fullført fremdriftslinjen ‘analyse’ vil være på 100% og filtrene vil ikke lenger ha meldingen’ (Kravlesøk Analyse Kreves)’.
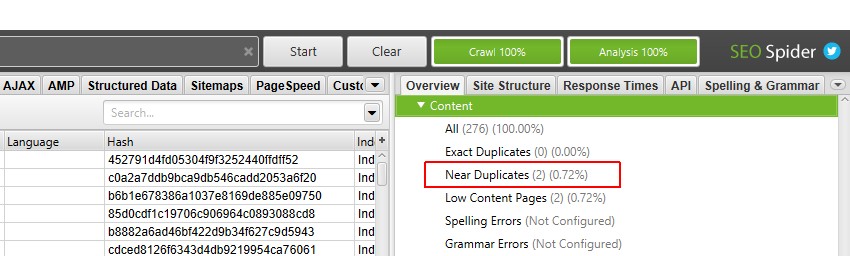
Du kan nå vise det befolkede nær duplikatfilteret og kolonnene.
6) Se ‘Innhold’ – Fanen & ‘Nøyaktig’ & ‘ Nær ‘ Duplikatfiltre
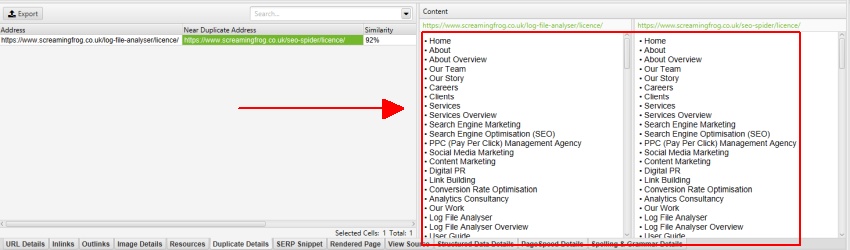
etter å ha utført analyse av etterkryp, filteret ‘Nær Duplikater’, ‘Nærmeste Likhetskamp’ Og ‘Nei. Nær Duplikater kolonner vil bli befolket. Bare Nettadresser med innhold over den valgte likhetsgrensen vil inneholde data, de andre vil forbli tomme. I Dette tilfellet Har Screaming Frog-nettstedet bare to.
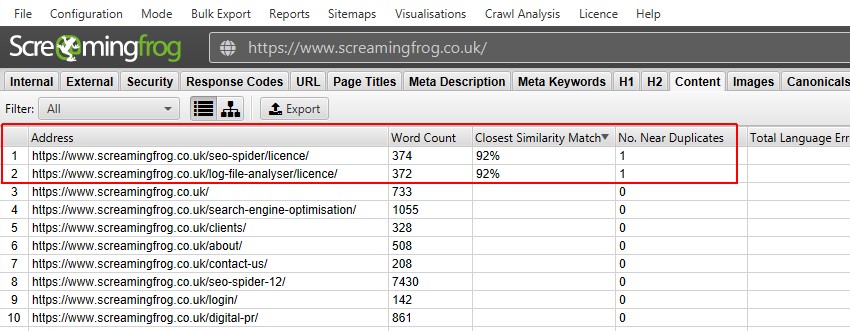
en gjennomgang av et større nettsted, som BBC, vil avsløre mange flere.
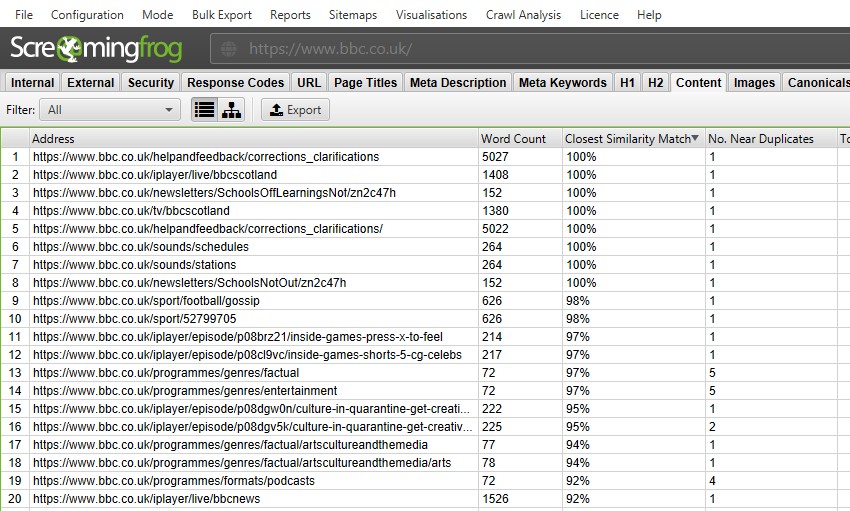
du kan filtrere etter følgende–
- Eksakte Duplikater – dette filteret viser sider som er identiske med hverandre ved HJELP AV MD5-algoritmen som beregner en ‘hash’ – verdi for hver side og kan ses i’ hash ‘ – kolonnen. Denne sjekken utføres mot hele HTML på siden. Det vil vise alle sider med matchende hash verdier som er nøyaktig det samme. Eksakte dupliserte sider kan føre til splitting Av PageRank signaler og uforutsigbarhet i rangeringen. DET bør bare være en enkelt kanonisk versjon AV EN URL som eksisterer og er knyttet til internt. Andre versjoner skal ikke knyttes til, og de skal være 301 omdirigert til den kanoniske versjonen.
- Nær Duplikater – dette filteret vil vise lignende sider basert på den konfigurerte likhetsgrensen ved hjelp av minhash-algoritmen. Terskelen kan justeres under ‘Config > Spider > Innhold’ og er satt til 90% som standard. Kolonnen Nærmeste Likhetskamp viser den høyeste prosentandelen av likhet med en annen side. Nei. Kolonnen nær Duplikater viser antall sider som ligner på siden basert på likhetstærskelen. Algoritmen kjøres mot tekst på siden, i stedet for full HTML som eksakte duplikater. Innholdet som brukes til denne analysen, kan konfigureres under ‘Config > Content > Area’. Sider kan ha en 100% likhet, men bare være en ‘nær duplikat’ i stedet for eksakt duplikat. Dette er fordi eksakte duplikater er ekskludert som nær duplikater, for å unngå at de blir flagget to ganger. Likhetsresultater er også avrundet, så 99,5% eller høyere vil bli vist som 100%.
Nær dupliserte sider bør vurderes manuelt, da det er mange legitime grunner til at enkelte sider er svært like i innhold, for eksempel variasjoner av produkter som har søkevolum rundt deres spesifikke attributt.
Imidlertid Bør Nettadresser som er flagget som nær duplikater, gjennomgås for å vurdere om De skal eksistere som separate sider på grunn av deres unike verdi for brukeren, eller om De skal fjernes, konsolideres eller forbedres for å gjøre innholdet mer grundig og unikt.
7) Se Dupliserte Nettadresser Via Fanen’ Dupliserte Detaljer ‘
for ‘eksakte duplikater’, er det lettere å bare se dem i toppvinduet ved å bruke filteret – da de er gruppert sammen og deler samme ‘hash’ – verdi.
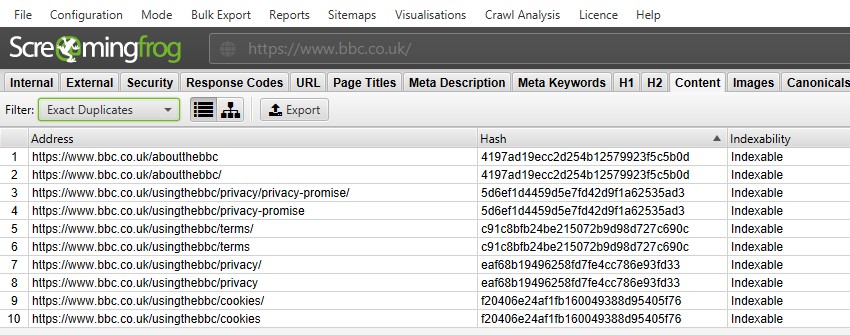
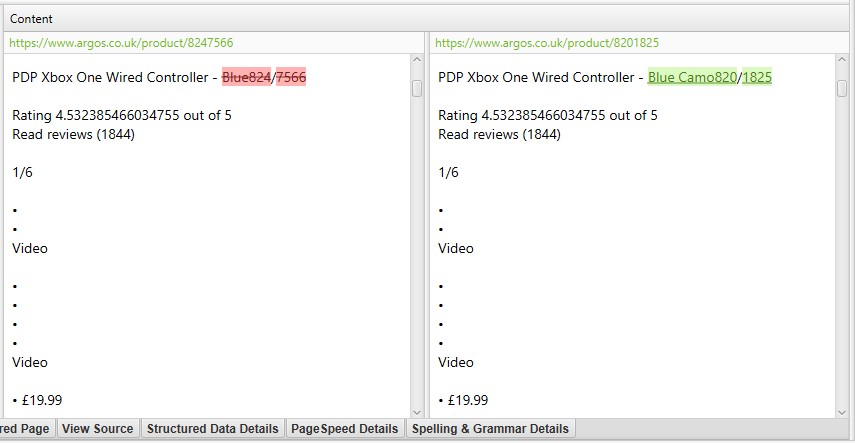
i skjermbildet ovenfor har hver URL en tilsvarende eksakt duplikat på grunn av en etterfølgende skråstrek og ikke-etterfølgende skråstrekversjon.
for’ nær duplikater’, klikk På ‘Dupliserte Detaljer’ – fanen nederst som fyller den nedre vindusruten med ‘nær duplikatadresse’ og likhet for hver nær duplikat URL oppdaget.
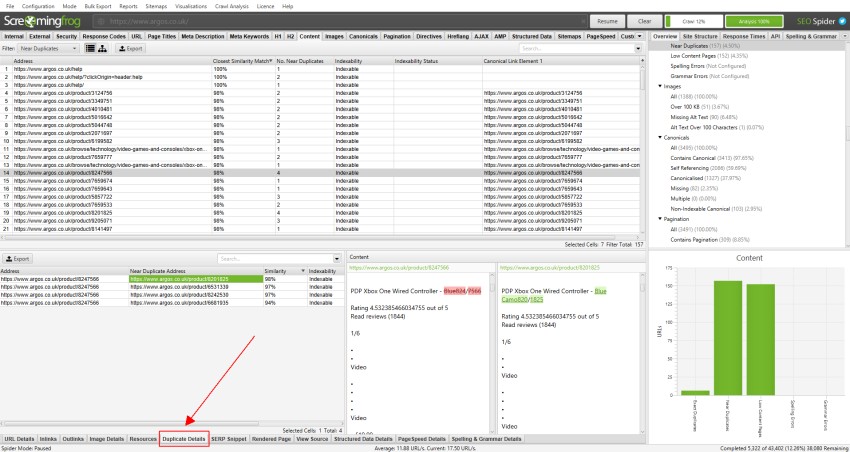
hvis det for eksempel oppdages 4 nær duplikater for EN URL i toppvinduet, kan alle disse vises.
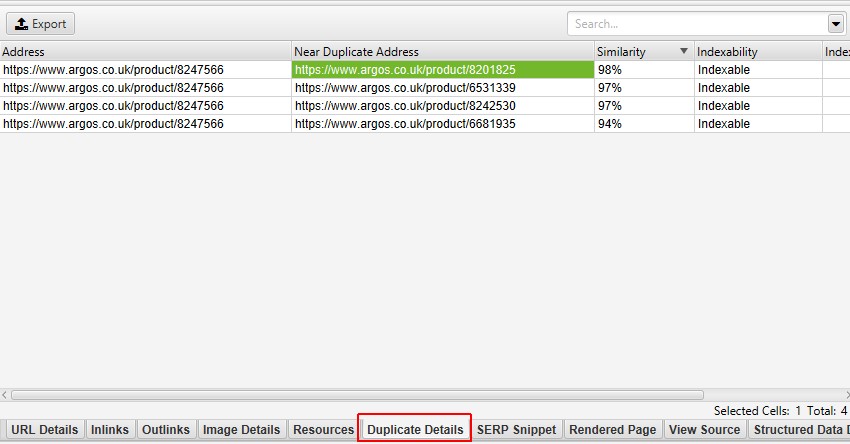
høyre side av ‘Duplicate Details’-fanen vil vise det nesten dupliserte innholdet som er oppdaget fra sidene og markere forskjellene mellom sidene når du klikker på hver ‘near duplicate address’.
hvis det er duplikatinnhold i kategorien duplikatdetaljer som du ikke ønsker å være en del av duplikatinnholdsanalysen, kan DU ekskludere ELLER inkludere HTML-elementer, klasser eller Id-er (som uthevet i punkt 2),& kjøre gjennomsøkingsanalyse på nytt.
8) Bulkeksport Duplikater
både eksakte og nær duplikater kan eksporteres i bulk via Eksporten ‘Bulkeksport > Innhold > Eksakte Duplikater’ og ‘Nær Duplikater’.

Siste Tips! Begrens Likhetsgrensen & Innholdsområde, & kjør Gjennomsøkingsanalyse
Etter gjennomsøking du kan justere både terskelen for nær duplikat likhet og innholdsområdet som brukes til nær duplikat analyse.
Du kan deretter kjøre gjennomsøkingsanalyse på nytt for å finne mer eller mindre lignende innhold – uten å gjennomsøke nettstedet på nytt.
Som beskrevet tidligere har Screaming Frog-nettstedet en mobilmeny utenfor nav-elementet, som er inkludert i innholdsanalysen som standard. Mobilmenyen kan ses i innholdsforhåndsvisningen av’ duplicate details ‘ – fanen.
ved å ekskludere rullegardinmenyen ‘mobil-meny__’ i Boksen ‘Ekskluder Klasser’ Under ‘Config > Innhold > Område’, fjernes mobilmenyen fra forhåndsvisningen av innhold og nær duplikatanalyse.
dette kan virkelig hjelpe når du finjusterer identifikasjonen av nær duplikatinnhold til hovedinnholdsområder, uten å måtte gjennomgå på nytt.
Sammendrag
veiledningen ovenfor skal illustrere hvordan DU bruker SEO Spider som en duplikat innholdskontroll for nettstedet ditt. Hvis du vil ha de mest nøyaktige resultatene, kan du finjustere innholdsområdet for analyse og justere terskelen for ulike grupper av sider.
Les Også Vår Screaming Frog SEO Spider Vanlige Spørsmål og full brukerhåndbok for mer informasjon om verktøyet.
hvis du har ytterligere spørsmål, tilbakemeldinger eller forslag til å forbedre duplikat innhold verktøyet I SEO Spider så bare ta kontakt via support.