




Sådan kontrolleres for Duplikatindhold
Sådan finder du Duplikatindhold
Duplikatindhold skal minimeres på tværs af en hjemmeside, da det kan gøre det vanskeligt for søgemaskiner at beslutte, hvilken version der skal rangeres for en forespørgsel.
mens en ‘duplicate content penalty’ er en myte i SEO, kan meget lignende indhold forårsage kravlende ineffektivitet, fortynde PageRank og være et tegn på indhold, der kan konsolideres, fjernes eller forbedres.
det er værd at huske, at duplikat og lignende indhold er en naturlig del af internettet, hvilket ofte ikke er et problem for søgemaskiner, der efter design kanonikaliserer URL ‘ er og filtrerer dem, hvor det er relevant. Men i skala kan det være mere problematisk.
forebyggelse af duplikatindhold giver dig kontrol over, hvad der er indekseret og rangeret – i stedet for at overlade det til søgemaskinerne. Du kan begrænse gennemgang budget affald og konsolidere indeksering og link signaler til at hjælpe i ranking.
denne tutorial går dig igennem, hvordan du kan bruge Screaming Frog SEO Spider til at finde både nøjagtigt duplikatindhold og næsten duplikatindhold, hvor noget tekst matcher mellem sider på en hjemmeside.
duplikeret indhold identificeret af ethvert værktøj, herunder SEO Spider skal gennemgås i sammenhæng. Se vores video, eller fortsæt med at læse vores guide nedenfor.
for at komme i gang, hente SEO Spider, som er gratis for at kravle op til 500 URL ‘ er. De første 2 trin er kun tilgængelige med en licens. Hvis du er en Gratis bruger, skal du springe til nummer 3 i guiden.
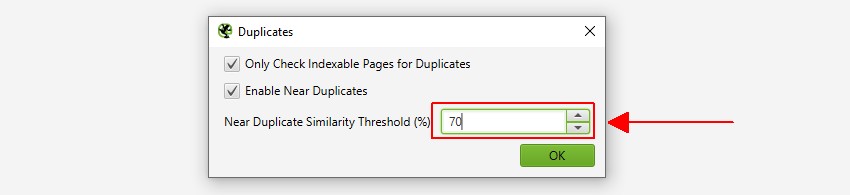
1) Aktiver ‘nær dubletter’ Via ‘Config > indhold > dubletter’
som standard identificerer SEO Spider automatisk nøjagtige duplikatsider. For at identificere ‘nær duplikater’ skal konfigurationen dog være aktiveret, hvilket gør det muligt at gemme indholdet på hver side.
SEO Spider vil identificere nær dubletter med en 90% lighedsmatch, som kan justeres for at finde indhold med en lavere lighedstærskel.
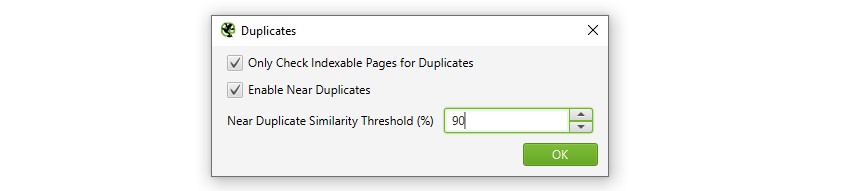
SEO Spider vil også kun kontrollere ‘indekserbare’ sider for dubletter (for både nøjagtige og næsten dubletter).
dette betyder, at hvis du har to URL ‘er, der er ens, men den ene er kanonikaliseret til den anden (og derfor’ ikke-indekserbar’), vil dette ikke blive rapporteret – medmindre denne indstilling er deaktiveret.
hvis du er interesseret i at finde gennemsøgningsbudgetproblemer, skal du fjerne markeringen i indstillingen ‘Kontroller kun indekserbare sider for duplikater’, da dette kan hjælpe med at finde områder med potentielt gennemsøgningsaffald.
2) Juster ‘indholdsområde’ til analyse via ‘Config > indhold > område’
du kan konfigurere det indhold, der bruges til næsten duplikatanalyse. For en ny gennemgang anbefaler vi at bruge standardopsætningen og forfine den senere, når det indhold, der bruges i analysen, kan ses og overvejes.
SEO Spider udelukker automatisk både nav-og sidefodselementerne for at fokusere på hovedkropsindhold. Imidlertid er ikke alle hjemmesider bygget ved hjælp af disse HTML5-elementer, så du er i stand til at forfine det indholdsområde, der bruges til analysen, hvis det kræves. Du kan vælge at ‘inkludere’ eller ‘ekskludere’ HTML-tags, klasser og ID ‘ er i analysen.
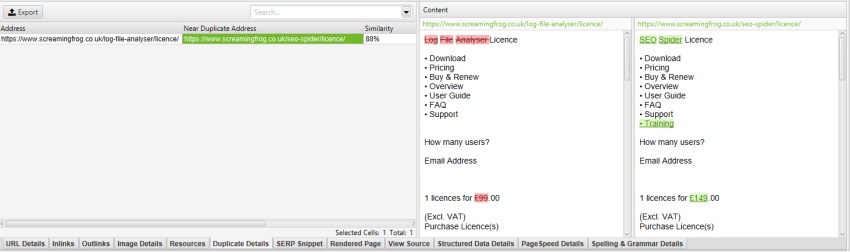
for eksempel har Screaming Frog-hjemmesiden en mobilmenu uden for nav-elementet, som som standard er inkluderet i indholdsanalysen. Selvom dette ikke er meget af et problem, kan det i dette tilfælde hjælpe med at fokusere på hovedteksten på siden, dets klassenavn ‘mobil-menu__rullemenu’ kan indtastes i feltet ‘Ekskluder klasser’.
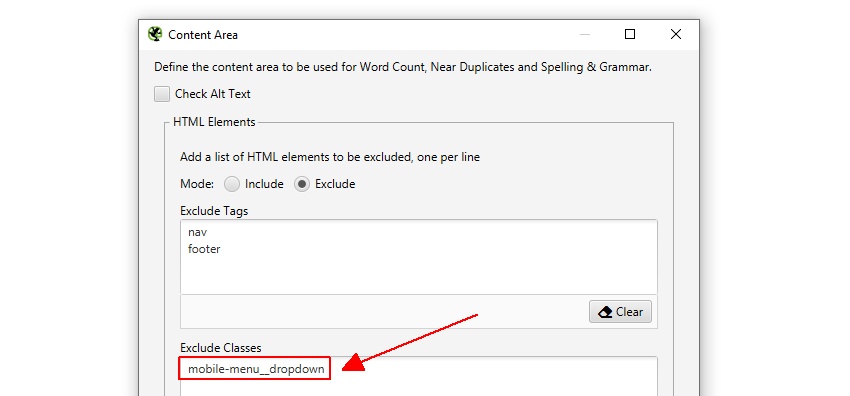
dette udelukker menuen fra at blive inkluderet i algoritmen til analyse af duplicate content. Mere om dette senere.
3) gennemgå hjemmesiden
Åbn SEO Spider, skriv eller kopier på den hjemmeside, du ønsker at gennemgå i feltet ‘Indtast URL til spider’ og tryk på ‘Start’.
vent, indtil gennemgangen er færdig og når 100%, men du kan også se nogle detaljer i realtid.
4) Se dubletter under fanen ‘Indhold’
fanen Indhold har 2 filtre relateret til duplikatindhold, ‘nøjagtige dubletter’ og ‘nær dubletter’.
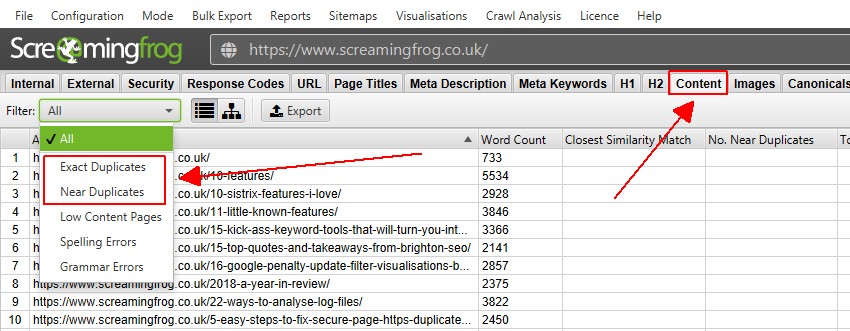
kun ‘eksakte dubletter’ kan ses i realtid under en gennemgang. ‘Nær dubletter’ kræver beregning i slutningen af gennemgangen via post ‘Gennemsøgningsanalyse’ for at den kan udfyldes med data.
højre rude ‘oversigt’ viser en ‘(Gennemsøgningsanalyse påkrævet)’ – meddelelse Mod filtre, der kræver, at eftersøgningsanalyse udfyldes med data.
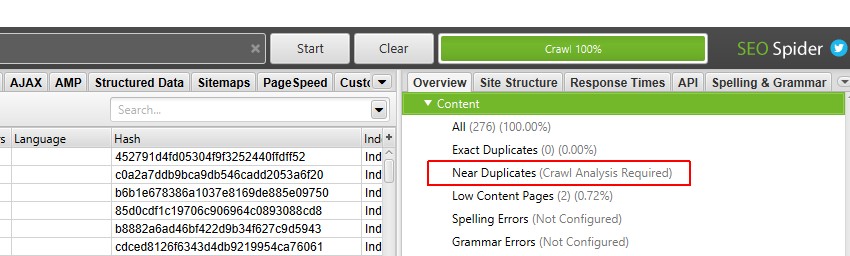
5) Klik på ‘Gennemsøgningsanalyse> Start’ for at udfylde ‘i nærheden af dubletter’ Filter
for at udfylde filteret ‘i nærheden af dubletter’, ‘nærmeste Lighedsmatch’ og ‘nej. I nærheden af Duplikatkolonner skal du bare klikke på en knap i slutningen af gennemgangen.

men hvis du tidligere har konfigureret ‘Gennemsøgningsanalyse’, kan du ønske at dobbelttjekke under ‘Gennemsøgningsanalyse > Konfigurer’ at ‘nær dubletter’ er markeret.
du kan også fjerne markeringen af andre elementer, der også kræver analyse efter gennemgang for at gøre dette trin hurtigere.
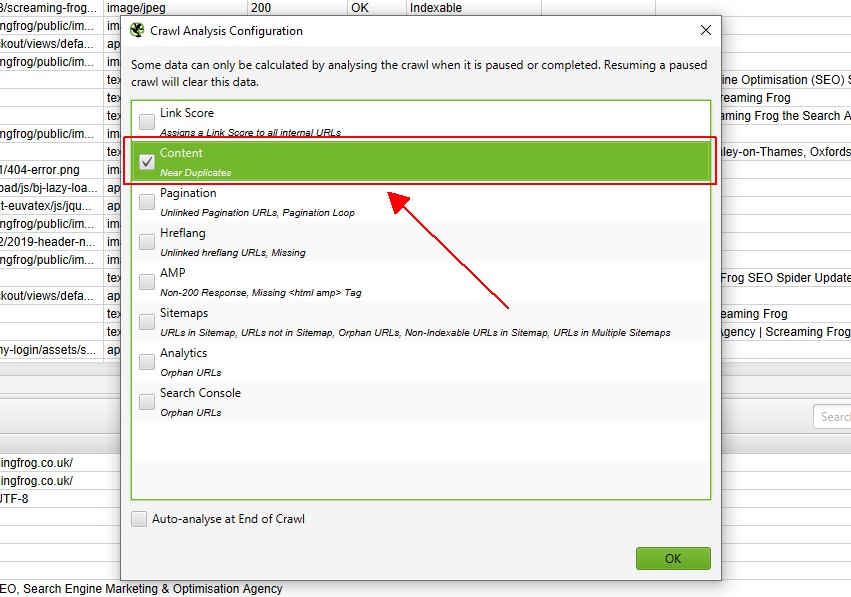
når gennemsøgningsanalysen er afsluttet, vil statuslinjen ‘analyse’ være på 100%, og filtrene vil ikke længere have meddelelsen ‘(Gennemsøgningsanalyse påkrævet)’.
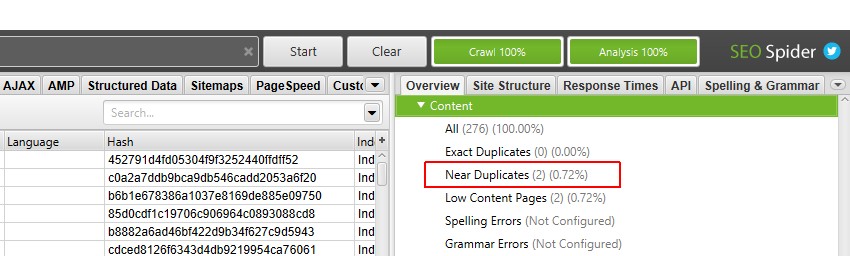
du kan nu se det udfyldte næsten dublerede filter og kolonner.
6) Se fanen ‘Indhold’ & ‘eksakt’ & ‘nær’ Duplikatfiltre
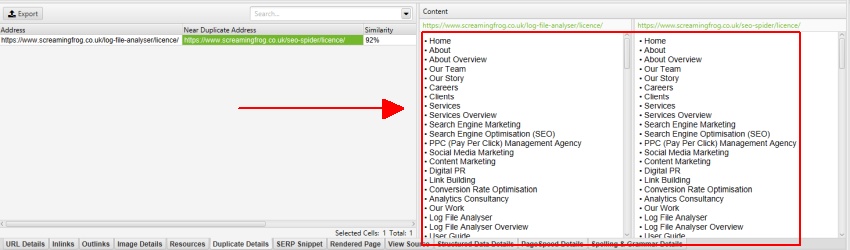
efter udførelse af analyse efter gennemgang, filteret ‘nær duplikater’, ‘nærmeste Lighedsmatch’ og ‘nej. I nærheden af dubletter’ kolonner vil blive befolket. Kun URL ‘ er med indhold over den valgte lighedstærskel indeholder data, de andre forbliver tomme. I dette tilfælde har Screaming Frog hjemmeside kun to.
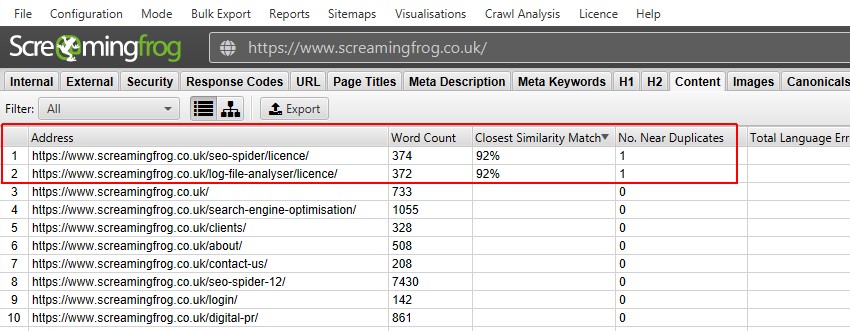
en gennemgang af en større hjemmeside, som BBC vil afsløre mange flere.
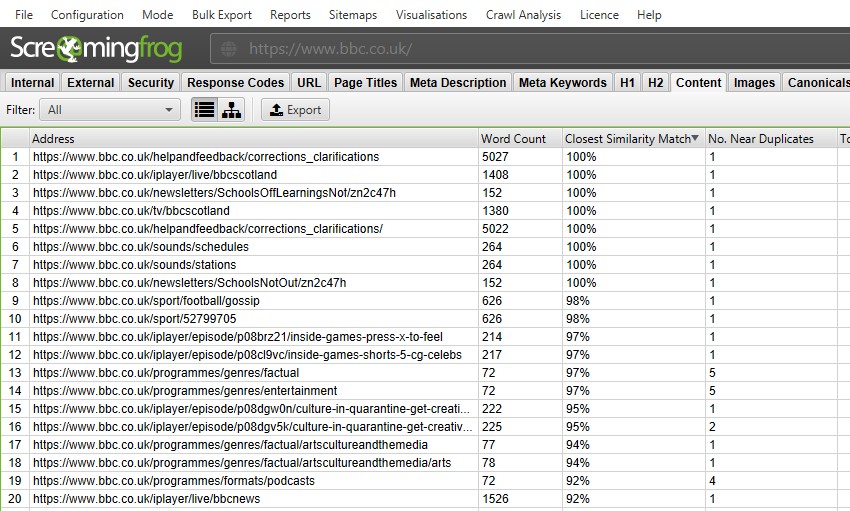
du er i stand til at filtrere efter følgende–
- nøjagtige dubletter – dette filter viser sider, der er identiske med hinanden ved hjælp af MD5-algoritmen, der beregner en ‘hash’ – værdi for hver side og kan ses i kolonnen ‘hash’. Denne kontrol udføres mod den fulde HTML på siden. Det viser alle sider med matchende hashværdier, der er nøjagtigt de samme. Nøjagtige duplikatsider kan føre til opdeling af PageRank-signaler og uforudsigelighed i rangordningen. Der bør kun være en enkelt kanonisk version af en URL, der findes og er knyttet til internt. Andre versioner bør ikke være knyttet til, og de bør være 301 omdirigeret til den kanoniske version.
- nær dubletter – dette filter viser lignende sider baseret på den konfigurerede lighedstærskel ved hjælp af minhash-algoritmen. Tærsklen kan justeres under’ Config > Spider > indhold ‘ og er som standard indstillet til 90%. Kolonnen’ nærmeste Lighedsmatch ‘ viser den højeste procentdel af lighed med en anden side. Nej. I nærheden af dubletter’ kolonne vises antallet af sider, der ligner siden baseret på lighedstærsklen. Algoritmen køres mod tekst på siden, snarere end den fulde HTML som nøjagtige dubletter. Indholdet, der bruges til denne analyse, kan konfigureres under ‘Config > indhold > område’. Sider kan have en 100% lighed, men kun være en ‘nær duplikat’ snarere end nøjagtig duplikat. Dette skyldes, at nøjagtige dubletter udelukkes som nær dubletter for at undgå, at de markeres to gange. Lighedsscore er også afrundet, så 99,5% eller højere vises som 100%.
i nærheden af dublerede sider skal gennemgås manuelt, da der er mange legitime grunde til, at nogle sider er meget ens i indhold, såsom variationer af produkter, der har søgevolumen omkring deres specifikke attribut.
URL ‘ er, der er markeret som næsten dubletter, bør dog gennemgås for at overveje, om de skal eksistere som separate sider på grund af deres unikke værdi for brugeren, eller om de skal fjernes, konsolideres eller forbedres for at gøre indholdet mere dybtgående og unikt.
7) Se dublerede URL ‘er via fanen’ dublerede detaljer ‘
for’ nøjagtige dubletter ‘er det lettere at bare se dem i det øverste vindue ved hjælp af filteret – da de er grupperet sammen og deler den samme’ hash ‘ – værdi.
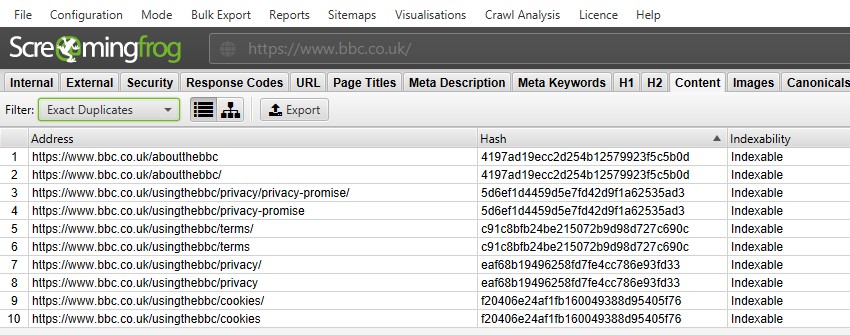
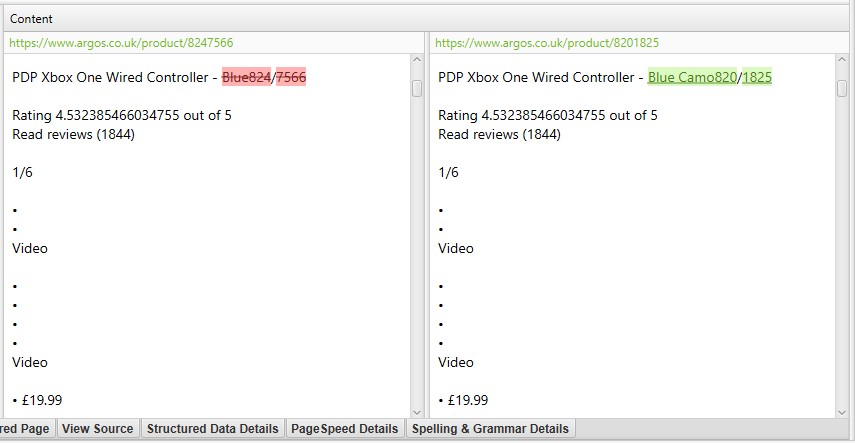
i ovenstående skærmbillede har hver URL en tilsvarende nøjagtig duplikat på grund af en efterfølgende skråstreg og ikke-efterfølgende skråstreg-version.
for ‘nær duplikater’ skal du klikke på fanen ‘Duplikatoplysninger’ nederst, som udfylder den nederste vinduesrude med ‘nær duplikatadresse’ og lighed for hver næsten duplikat URL opdaget.
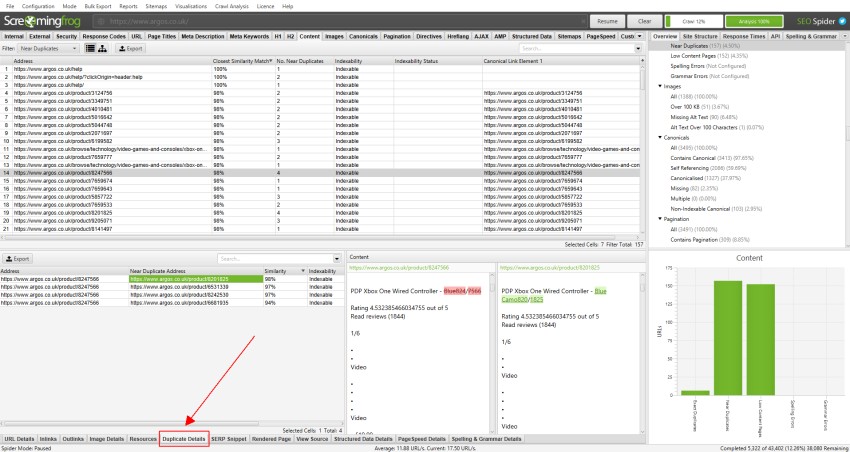
hvis der f.eks. er 4 næsten dubletter opdaget for en URL i det øverste vindue, kan disse alle ses.
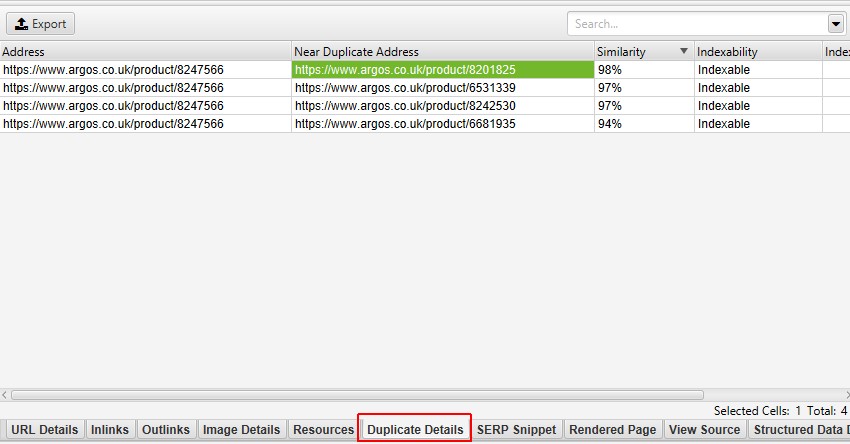
højre side af fanen ‘Duplicate Details’ viser det næsten duplikerede indhold, der er opdaget fra siderne, og fremhæver forskellene mellem siderne, når du klikker på hver ‘near duplicate address’.
hvis der er duplikatindhold på fanen duplikatoplysninger, som du ikke ønsker at være en del af analysen af duplikatindhold, skal du ekskludere eller medtage HTML-elementer, klasser eller ID ‘ er (som fremhævet i punkt 2), & genkør gennemgangsanalyse.
8) bulk eksport dubletter
både nøjagtige og næsten-dubletter kan eksporteres i bulk via ‘Bulk eksport > indhold > nøjagtige dubletter’ og ‘nær dubletter’ eksport.

Sidste Tip! Afgræns Lighedstærsklen & indholdsområde, & genkør Gennemsøgningsanalyse
efter gennemsøgning du kan justere både tærsklen for næsten duplikeret lighed og indholdsområdet, der bruges til næsten duplikatanalyse.
du kan derefter køre gennemsøgningsanalyse igen for at finde mere eller mindre lignende indhold-uden at gennemgå hjemmesiden igen.
som beskrevet tidligere har Screaming Frog-hjemmesiden en mobilmenu uden for nav-elementet, som som standard er inkluderet i indholdsanalysen. Mobilmenuen kan ses i indholdseksemplet på fanen ‘duplicate details’.
ved at ekskludere rullemenuen ‘mobile-menu__’ i feltet ‘Ekskluder klasser’ under ‘Config > Content > Area’ fjernes menuen mobile fra indholdseksemplet og næsten duplikatanalyse.
dette kan virkelig hjælpe, når du finjusterer identifikationen af næsten duplikatindhold til hovedindholdsområder uden behov for at gennemgå igen.
Resume
vejledningen ovenfor skal illustrere, hvordan du bruger SEO Spider som en duplikatindholdskontrol til din hjemmeside. For at få de mest nøjagtige resultater skal du forfine indholdsområdet til analyse og justere tærsklen for forskellige grupper af sider.
Læs også vores Screaming Frog SEO Spider Ofte Stillede Spørgsmål og fuld brugervejledning for mere information om værktøjet.
hvis du har yderligere spørgsmål, feedback eller forslag til forbedring af duplikatindholdsværktøjet i SEO Spider, skal du bare kontakte via support.