




Hur Hittar Man Trasiga Länkar Med Selenium WebDriver?
vilka tankar kommer att tänka på när du stöter på 404/sidan hittades inte/döda hyperlänkar på en webbplats? Aargh! Du skulle tycka att det är irriterande när du stöter på trasiga hyperlänkar, vilket är den enda anledningen till att du kontinuerligt bör fokusera på att ta bort förekomsten av trasiga länkar i din webbprodukt (eller webbplats). Istället för en manuell inspektion kan du utnyttja automatisering för trasig länktestning med Selenium WebDriver.

när en viss länk bryts och en besökare landar på sidan påverkar den sidans funktionalitet och resulterar i en dålig användarupplevelse. Döda länkar kan skada din produkts trovärdighet, eftersom det kan ge ett intryck för dina besökare att det finns ett minimalt fokus på upplevelsen.
om din webbprodukt har många sidor (eller länkar) som resulterar i ett 404-fel (eller sidan hittades inte), kommer produktrankningen på sökmotorer (t.ex. Google) också att påverkas hårt. Borttagning av döda länkar är en av de integrerade delarna av SEO (Sökmotoroptimering) aktivitet.
i den här delen av Selenium WebDriver-handledningsserien dyker vi djupt in i att hitta trasiga länkar med Selenium WebDriver. Vi har visat bruten länktestning med Selenium Python, Selenium Java, Selenium C# och Selenium PHP.
introduktion till trasiga länkar i Webbtestning
enkelt uttryckt är trasiga länkar (eller döda länkar) på en webbplats (eller webbapp) länkar som inte kan nås och inte fungerar som förväntat. Länkarna kan vara tillfälligt nere på grund av serverproblem eller felaktigt konfigurerade på baksidan.
bortsett från sidor som resulterar i 404 Fel, andra framträdande exempel på trasiga länkar är felaktiga webbadresser, länkar till innehåll (t.ex. dokument, pdf, bilder, etc.) som har flyttats eller tagits bort.
framträdande orsaker till trasiga länkar
här är några av de vanligaste orsakerna bakom förekomsten av trasiga länkar (döda länkar eller länk ruttnar):
- felaktig eller felstavad URL som användaren har angett.
- strukturella förändringar på webbplatsen (dvs. permalänkar) med URL-omdirigeringar eller interna omdirigeringar är inte korrekt konfigurerade.
- länkar till innehåll som Videor, Dokument etc. som antingen flyttas eller raderas. Om innehållet flyttas ska de interna länkarna omdirigeras till de angivna länkarna.
- tillfällig driftstopp på grund av webbplatsunderhåll vilket gör webbplatsen tillfälligt otillgänglig.
- trasiga HTML-taggar, JavaScript-fel, felaktiga HTML / CSS-anpassningar,trasiga inbäddade element etc., inom sidan som leder, kan leda till trasiga länkar.
- geolokaliseringsbegränsningar förhindrar åtkomst till webbplatsen från vissa IP-adresser (om de är svartlistade) eller specifika länder i världen. Geolokaliseringstestning med selen hjälper till att säkerställa att upplevelsen är skräddarsydd för platsen (eller landet) där webbplatsen nås.
varför ska du kontrollera trasiga länkar?
trasiga länkar är en stor avstängning för besökare som landar på din webbplats. Här är några av de viktigaste anledningarna till varför du bör kontrollera om trasiga länkar på din webbplats:
- trasiga länkar kan skada användarupplevelsen.
- borttagning av trasiga (eller döda) länkar är viktigt för SEO (Sökmotoroptimering), eftersom det kan påverka webbplatsens ranking på sökmotorer (t.ex. Google).
trasiga länkar testning kan göras med Selenium WebDriver på en webbsida, som i sin tur kan användas för att ta bort webbplatsens döda länkar.
trasiga länkar och HTTP-statuskoder
när en användare besöker en webbplats skickas en begäran från webbläsaren till Webbplatsens server. Servern svarar på webbläsarens begäran med en tresiffrig kod som kallas HTTP-statuskoden.’
en HTTP-statuskod är serverns svar på en begäran som skickas från webbläsaren. Dessa HTTP-statuskoder anses motsvara konversationen mellan webbläsaren (från vilken URL-begäran skickas) och servern.
även om olika HTTP-statuskoder används för olika ändamål, är de flesta koderna användbara för att diagnostisera problem på webbplatsen, minimera driftstopp, antalet döda länkar och mer. Den första siffran i varje tresiffrig statuskod börjar med siffrorna 1~5. Statuskoderna representeras som 1xx, 2xx.., 5xx för att ange statuskoderna i det specifika intervallet. Eftersom vart och ett av dessa intervall består av en annan klass av serversvar, skulle vi begränsa diskussionen till HTTP-statuskoder som presenteras för trasiga länkar.
här är de vanliga statuskodklasserna som är användbara för att upptäcka trasiga länkar med selen:
| klasser av HTTP-statuskod | beskrivning |
|---|---|
| 1XX | servern tänker fortfarande igenom begäran. |
| 2xx | begäran som skickades av webbläsaren slutfördes framgångsrikt och förväntat svar skickades till webbläsaren av servern. |
| 3xx | detta indikerar att en omdirigering utförs. Till exempel är 301 omdirigering populärt används för att genomföra permanenta omdirigeringar på en webbplats. |
| 4xx | detta indikerar att antingen en viss sida (eller fullständig webbplats) inte kan nås. |
| 5xx | detta indikerar att servern inte kunde slutföra begäran, även om en giltig begäran skickades av webbläsaren. |
HTTP – statuskoder som presenteras vid detektering av trasiga länkar
här är några av de vanliga HTTP-Statuskoderna som presenteras av webbservern när de stöter på en trasig länk:
| HTTP-statuskod | beskrivning |
|---|---|
| 400 (Bad Request) | servern kan inte behandla begäran eftersom den nämnda webbadressen är felaktig. |
| 400 (Bad Request-Bad Host) | detta indikerar att värdnamnet är ogiltigt på grund av vilket begäran inte kan behandlas. |
| 400 (Bad Request-Bad URL) | detta indikerar att servern inte kan behandla begäran eftersom den angivna webbadressen är felaktig (dvs. saknade parenteser, snedstreck etc.). |
| 400 (Bad Request-Timeout) | detta indikerar att HTTP-förfrågningarna har tagit slut. |
| 400 (Bad Request-Empty) | svaret som returneras av servern är tomt utan innehåll och ingen svarskod. |
| 400 (Bad Request – Reset) | detta indikerar att servern inte kan behandla begäran, eftersom den är upptagen med att behandla andra förfrågningar eller att den har felkonfigurerats av webbplatsägaren. |
| 403 (Förbjudet) | en äkta begäran skickas till servern men den vägrar att uppfylla samma sak, eftersom tillstånd krävs. |
| 404 (sidan hittades inte) | resursen (eller sidan) är inte tillgänglig på servern. |
| 408 (Request Time Out) | servern har timed-out väntar på begäran. Klienten (dvs. webbläsaren) kan skicka samma begäran inom den tid som servern är beredd att vänta. |
| 410 (borta) | en HTTP-statuskod som är mer permanent än 404 (sidan hittades inte). 410 betyder att sidan är borta. sidan är varken tillgänglig på servern, eller någon vidarebefordran (eller omdirigering) mekanism har ställts in. Länkarna som pekar på en 410-sida skickar besökare till en död resurs. |
| 503 (Tjänsten är inte tillgänglig) | detta indikerar att servern är tillfälligt överbelastad, på grund av vilken den inte kan behandla begäran. Det kan också innebära att underhåll utförs på servern, vilket indikerar sökmotorerna om webbplatsens tillfälliga driftstopp. |
Hur hittar man trasiga länkar med Selenium WebDriver?
oavsett vilket språk som används med Selenium WebDriver förblir de vägledande principerna för bruten länktestning med selen densamma. Här är stegen för trasiga länkar testning med Selenium WebDriver:
- använd taggen för att samla in information om alla länkar som finns på webbsidan.
- skicka en HTTP-begäran för varje länk.
- verifiera motsvarande svarskod som mottagits som svar på begäran som skickades i föregående steg.
- bekräfta om länken är trasig eller inte baserat på svarskoden som skickas av servern.
- Upprepa steg (2-4) För varje länk som finns på sidan.
i denna Selenium WebDriver-handledning skulle vi visa hur man utför trasig länktestning med Selenium WebDriver i Python, Java, C# och PHP. Testerna utförs på (Chrome 85.0 + Windows 10) kombination, och utförandet utförs på det molnbaserade Selenium-nätet som tillhandahålls av LambdaTest.
för att komma igång med LambdaTest, skapa ett konto på plattformen och notera användarnamnet & åtkomstnyckel tillgänglig från profilavsnittet på LambdaTest. Webbläsarens funktioner genereras med LambdaTest Capabilities Generator.
här är testscenariot som används för att hitta trasiga länkar på en webbplats med Selenium:
testscenario
- gå till LambdaTest Blog dvs https://www.lambdatest.com/blog/ på Chrome 85.0
- samla alla länkar som finns på sidan
- skicka HTTP-begäran för varje länk
- skriv ut om länken är trasig eller inte på terminalen
det är viktigt att notera att tiden som spenderas i trasiga Länktestning med Selenium beror på antalet länkar som finns på webbsidan som testas.’Ju mer antalet länkar på sidan, desto mer tid kommer att spenderas på att hitta trasiga länkar. Till exempel har LambdaTest ett stort antal länkar (~150+); därför kan processen att hitta trasiga länkar ta lite tid (ca några minuter).

kör ditt testskript på SELENIUM GRID
2000+ webbläsare och operativsystem
gratis registrering
trasig Länktestning med Selenium Java
implementering
Kodgenomgång
1. Importera de nödvändiga paketen
metoderna i HttpURLConnection-paketet används för att skicka HTTP-förfrågningar och fånga HTTP-statuskoden (eller svaret).
metoderna i regex.Mönsterpaket kontrollera om motsvarande länk innehåller en e-postadress eller ett telefonnummer med hjälp av en specialiserad syntax som hålls i ett mönster.
|
1
2
|
importera java. net.HttpURLConnection;
importera java.util.regex.Mönster;
|
2. Samla länkarna som finns på sidan
länkarna som finns på webbadressen som testas (dvs. LambdaTest-bloggen) finns med tagname i Selenium. Taggnamnet som används för identifiering av elementet (eller länken) är ’a’.
länkarna placeras i en lista för att iterera genom listan för att kontrollera trasiga länkar på sidan.
|
1
|
lista< WebElement> länkar = drivrutin.findElements (av.tagName (”a”);
|
3. Iterate genom webbadresserna
Iterator-objektet används för looping genom listan skapad i steg (2)
|
1
|
Iterator< WebElement> länk = länkar.iterator();
|
4. Identifiera och verifiera webbadresserna
en While loop körs tills time Iterator (dvs länk) inte har fler element att iterera. ’Href’ för ankartaggen hämtas och samma lagras i URL-variabeln.
|
1
2
3
|
medan (länk.hasNext())
{
url = länk.nästa().getAttribute (”href”);
|
hoppa över att kontrollera länkarna om:
a. Länken är null eller tom
|
1
2
3
4
5
|
om ((url = = null) / / (url.isEmpty()))
{
systemet.ut.println (”URL är antingen inte konfigurerad för anchor tag eller den är tom”);
fortsätt;
}
|
b. Länken innehåller mailto eller telefonnummer
|
1
2
3
4
5
|
om ((url.startsWith (mail_to)) | | (url.startsWith (tel)))
{
systemet.ut.println (”e-postadress eller telefon upptäckt”);
fortsätt;
}
|
när du letar efter LinkedIn-sidan är HTTP-statuskoden 999. En boolesk variabel (dvs., LinkedIn) är inställd på true för att indikera att det inte är en trasig länk.
|
1
2
3
4
5
|
om (url.startsWith (LinkedInPage))
{
systemet.ut.println (”URL börjar med LinkedIn, förväntad statuskod är 999”);
bLinkedIn = sant;
}
|
5. Validera länkarna genom statuskoden
metoderna i HttpURLConnection-klassen ger möjlighet att skicka HTTP-förfrågningar och fånga HTTP-statuskoden.
openConnection-metoden för URL-klassen öppnar anslutningen till den angivna webbadressen. Den returnerar en URLConnection-instans som representerar en anslutning till det fjärrobjekt som refereras av webbadressen. Det är typgjutet till HttpURLConnection.
|
1
2
3
4
5
6
7
|
HttpURLConnection urlconnection = null;
……………………………………….
……………………………………….
……………………………………….
urlconnection = (HttpURLConnection) (ny URL(url).openConnection());
urlconnection.setRequestMethod (”Huvud”);
|
setRequestMethod i HttpURLConnection-klassen anger metoden för URL-begäran. Förfrågningstypen är inställd på HEAD så att endast rubriker returneras. Å andra sidan skulle begäran typ GET ha returnerat dokumentkroppen, vilket inte krävs i det här testscenariot.
connect-metoden i HttpURLConnection-klassen etablerar anslutningen till webbadressen och skickar en HTTP-begäran.
|
1
|
urlconnection.Anslut();
|
getResponseCode-metoden returnerar HTTP-statuskoden för den tidigare skickade begäran.
|
1
|
responseCode = urlconnection.getResponseCode();
|
för HTTP-statuskoden är 400 (eller mer) ökas variabeln som innehåller brutna länkar (dvs broken_links); annars ökas variabeln som innehåller giltiga länkar (dvs valid_links).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
om (responseCode >= 400)
{
om ((bLinkedIn = = true) &&(responseCode = = LinkedInStatus))
{
systemet.ut.println (url + ”är en LinkedIn-sida och är inte en trasig länk”);
valid_links++;
}
annat
{
systemet.ut.println (url + ”är en trasig länk”);
broken_links++;
}
}
annat
{
systemet.ut.println (url + ”är en giltig länk”);
valid_links++;
}
|
Execution
för trasiga länkar testning med Selenium Java, skapade vi ett projekt i IntelliJ IDEA. Den grundläggande pom.xml-filen var tillräcklig för jobbet!
här är exekveringsbilden, som indikerar 169 giltiga länkar och 0 trasiga länkar på LambdaTest-bloggsidan.
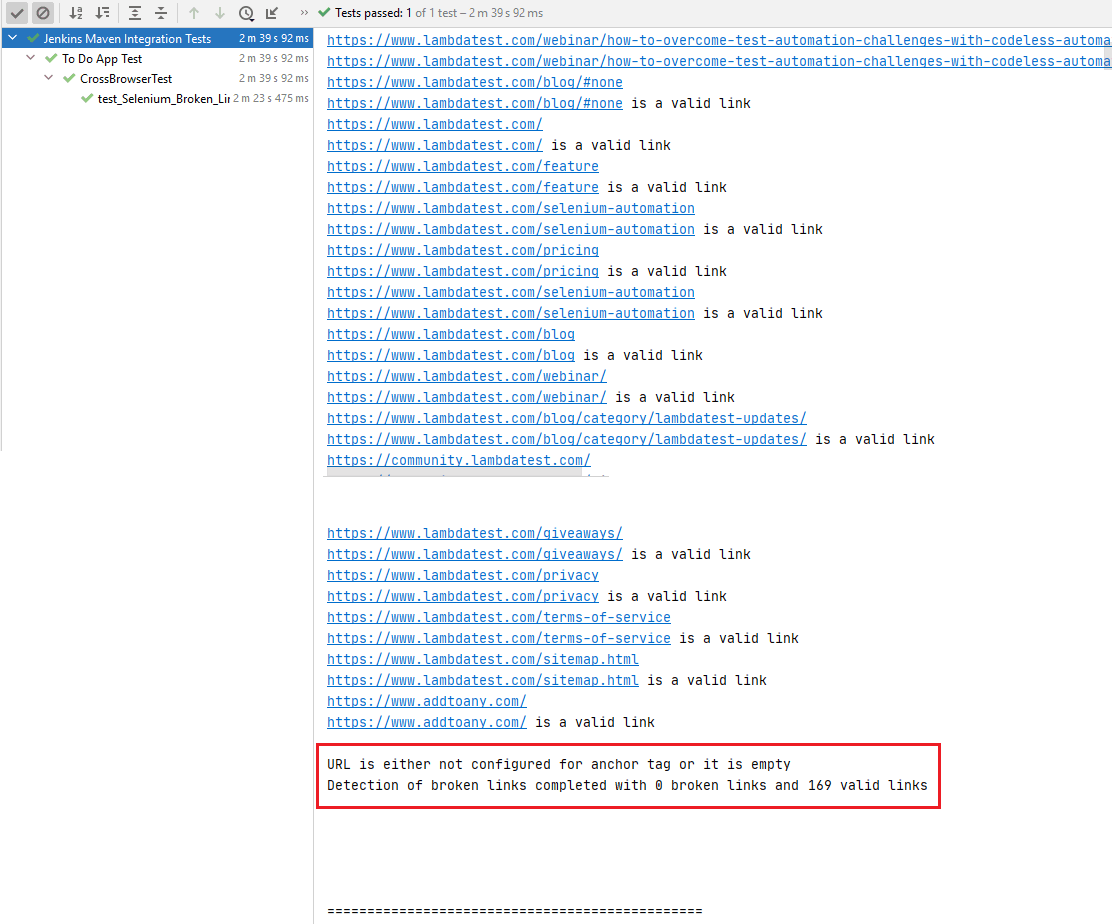
länkarna som innehåller e-postadresser och telefonnummer utesluts från söklistan, som visas nedan.
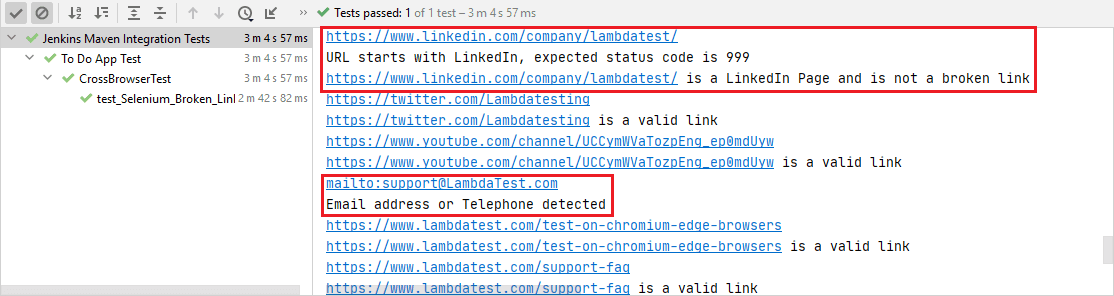
du kan se att testet körs i nedanstående skärmdump och slutförs på 2 min 35 sekunder, som visas på Lambdatests automatiseringsloggar.

trasig länk testning med selen Python
genomförande
kod genomgång
1. Importera moduler
förutom att importera Python-modulerna för Selenium WebDriver, importerar vi också förfrågningsmodulen. Modulen requests låter dig skicka alla typer av HTTP-förfrågningar. Det kan också användas för att skicka parametrar i URL, skicka anpassade rubriker och mer.
|
1
2
3
|
importera förfrågningar
importera urllib3
från förfrågningar.undantag import MissingSchema, InvalidSchema, InvalidURL
|
2. Samla länkarna som finns på sidan
länkarna som finns på webbadressen som testas (dvs. LambdaTest-bloggen) hittas genom att hitta webbelementen med CSS-Väljaren ”a” – egenskapen.
|
1
|
länkar = förare.find_elements (av.CSS_SELECTOR, ”a”)
|
eftersom vi vill att elementet ska vara iterabelt använder vi find_elements-metoden (och inte find_element-metoden).
3. Iterera genom webbadresserna för validering
head-metoden för requests-modulen används för att skicka en HEAD-begäran till den angivna webbadressen. Get_attribute metoden används på varje länk för att få’ href ’ attribut av ankartaggen.
huvudmetoden används främst i scenarier där endast status_code eller HTTP-rubriker krävs, och innehållet i filen (eller URL) behövs inte. Huvudmetoden returnerar förfrågningar.Svarsobjekt som också innehåller HTTP-statuskoden(dvs. begäran.statuskod).
|
1
2
3
4
|
för länk i länkar:
försök:
request = requests.Huvud (länk.get_attribute (’href’), data ={’nyckel’:’värde’})
Skriv ut(”Status för” + länk.get_attribute (’href’) + ” är ” + str(begäran.status_code))
|
samma uppsättning operationer utförs iterativt tills alla ’länkar’ som finns på sidan har uttömts.
4. Validera länkarna via statuskoden
om HTTP-svarskoden för HTTP-begäran som skickas i steg(3) är 404 (dvs. sidan hittades inte) betyder det att länken är en trasig länk. För länkar som inte är trasiga är HTTP-statuskoden 200.
|
1
2
3
4
|
om (begäran.status_code == 404):
broken_links = (broken_links + 1)
annat:
valid_links = (valid_links + 1)
|
5. Hoppa över irrelevanta förfrågningar
när de tillämpas på länkar som inte innehåller attributet ’href’ (t.ex. mailto, telefon etc.), resulterar huvudmetoden i ett undantag (dvs MissingSchema, InvalidSchema).
|
1
2
3
4
5
6
|
except requests.exceptions.MissingSchema:
print(”Encountered MissingSchema Exception”)
except requests.exceptions.InvalidSchema:
print(”Encountered InvalidSchema Exception”)
except:
Skriv ut (”stött på någon annan execption”)
|
dessa undantag fångas, och detsamma skrivs ut på terminalen.
Execution
vi har använt PyUnit (eller unittest) här, standardtestramen i Python för trasiga länktestning med Selenium. Kör följande kommando på terminalen:
|
1
|
python Broken_Links.py
|
utförandet skulle ta cirka 2-3 minuter eftersom LambdaTest-bloggsidan består av cirka 150+ länkar. Exekveringsskärmbilden nedan visar att sidan har 169 giltiga länkar och noll trasiga länkar.
du skulle bevittna InvalidSchema undantag eller MissingSchema undantag på vissa ställen, vilket tyder på att dessa länkar hoppas över från utvärderingen.
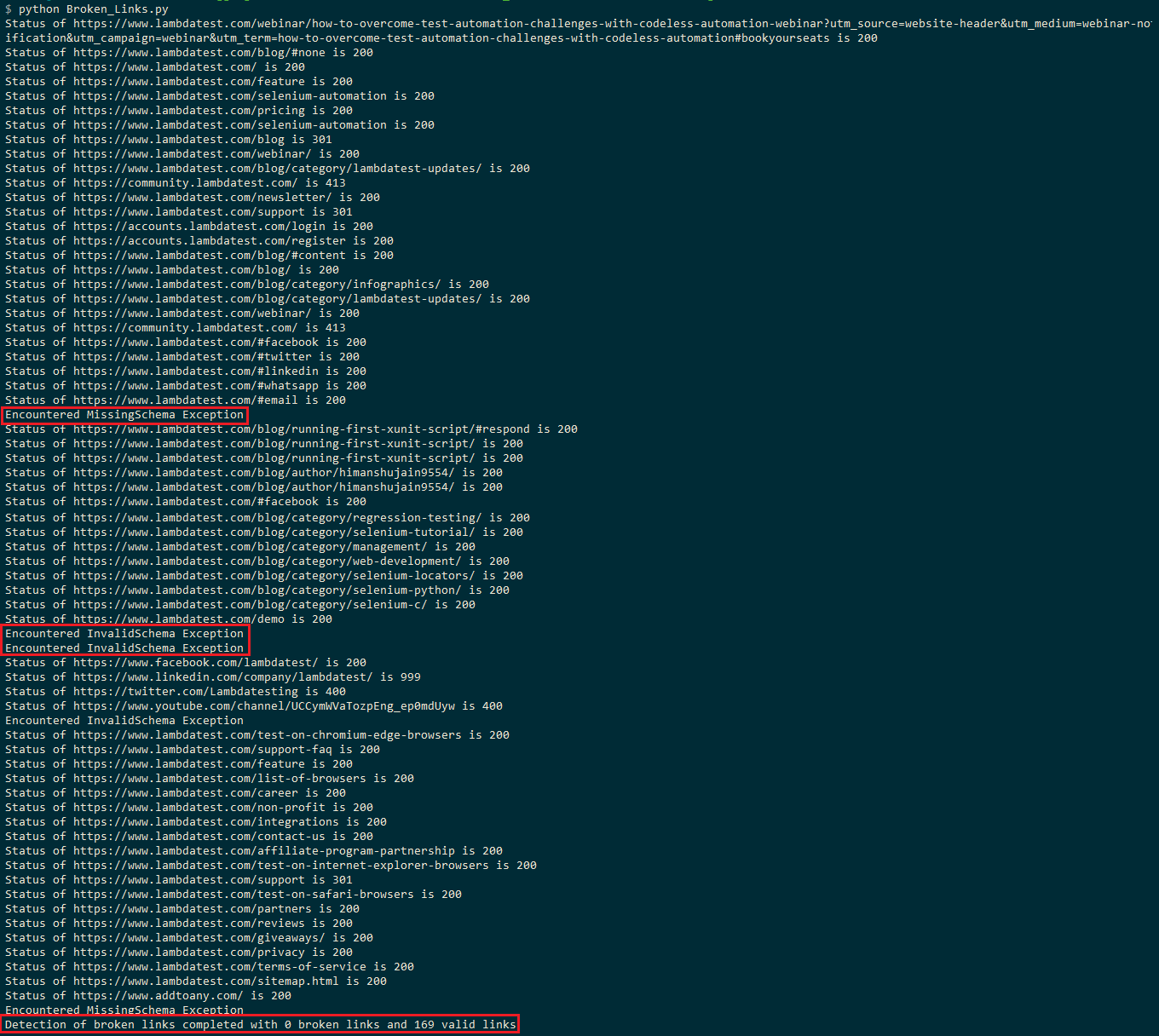
HUVUDFÖRFRÅGAN till LinkedIn (dvs.) resulterar i en HTTP-statuskod på 999. Som anges i denna tråd på StackOverflow filtrerar LinkedIn förfrågningarna baserat på användaragenten, och begäran resulterade i ’Åtkomst nekad’ (dvs. 999 som HTTP-statuskod).

vi verifierade om LinkedIn-länken som finns på LambdaTest-bloggsidan är trasig eller inte genom att köra samma test på det lokala Seleniumnätet, vilket resulterade i HTTP/1.1 200 OK.
trasig Länktestning med Selenium C #
implementering
Kodgenomgång
NUnit framework används för automatiseringstestning; vår tidigare blogg om NUnit testautomatisering med Selenium C # kan hjälpa dig att komma igång med ramverket.
1. Inkludera HttpClient
HttpClient-namnområdet läggs till för användning genom användardirektivet. HttpClient-klassen i C# tillhandahåller en basklass för att skicka HTTP-förfrågningar och ta emot HTTP-svaret från en resurs som identifieras av URI.
Microsoft rekommenderar att du använder System. Net.Http.HttpClient istället för System.Net.HttpWebRequest; HttpWebRequest kan också användas för att upptäcka trasiga länkar i Selenium C#.
|
1
2
|
använda System. Net.Http;
använda systemet.Gängning.Uppgifter;
|
2. Definiera en async-metod som returnerar en aktivitet
en async-testmetod definieras som att använda GetAsync-metoden som skickar en GET-begäran till den angivna URI som en asynkron operation.
|
1
2
|
offentliga Async uppgift LT_Broken_Links_Test()
{
|
3. Samla länkarna som finns på sidan
för det första skapar vi en instans av HttpClient.
|
1
|
använda var client = new HttpClient();
|
länkarna som finns på webbadressen som testas (dvs. LambdaTest-bloggen) samlas in genom att lokalisera webbelementen med egenskapen TagName ”a”.
|
1
|
var länkar = förare.FindElements (Av.TagName (”a”));
|
find_elements-metoden i selen används för att lokalisera länkarna på sidan eftersom den returnerar en array (eller lista) som kan itereras för att verifiera länkarnas bearbetbarhet.
4. Iterera genom webbadresserna för validering
länkarna som finns med find_elements-metoden verifieras i en for-slinga.
|
1
2
|
foreach (var länk i länkar)
{
|
vi filtrerar länkarna som innehåller / e-postadresser/telefonnummer / LinkedIn-adresser. Länkarna utan länktext filtreras också bort.
|
1
2
|
om (!(länk.Text.Innehåller(”E-post”) || länk.Text.Innehåller (”https://www.linkedin.com”) | | länk.Text = = ”” / / länk.Lika med (null)))
{
|
GetAsync-metoden i HttpClient-klassen skickar en GET-begäran till motsvarande URI som en asynkron operation. Argumentet till GetAsync-metoden är värdet på ankarets href-attribut som samlats in med getattribute-metoden.
utvärderingen av async-metoden avbryts av väntar-operatören tills den asynkrona operationen är klar. Efter avslutad asynkron operation returnerar väntar operatören HttpResponseMessage som innehåller data och statuskod.
|
1
2
3
|
/* hämta URI * /
HttpResponseMessage response = väntar på klienten.GetAsync (länk.GetAttribute (”href”));
systemet.Konsol.WriteLine ($”URL: {länk.GetAttribute (”href”)} status är :{svar.StatusCode}”);
|
5. Validera länkarna genom statuskoden
om HTTP-svarskoden(dvs. svar.StatusCode) för HTTP-begäran skickas i steg(4) är HttpStatusCode.OK (dvs 200), det betyder att begäran slutfördes framgångsrikt.
|
1
2
3
4
5
6
7
8
9
|
systemet.Console.WriteLine($”URL: {link.GetAttribute(”href”)} status is :{response.StatusCode}”);
if (response.StatusCode == HttpStatusCode.OK)
{
valid_links++;
}
else
{
broken_links++;
}
|
NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
|
1
2
3
4
5
6
7
8
|
catch (Exception ex)
{
if ((ex is ArgumentNullException) ||
(ex is NotSupportedException))
{
System.Console.WriteLine(”Exception occured\n”);
}
}
|
utförande
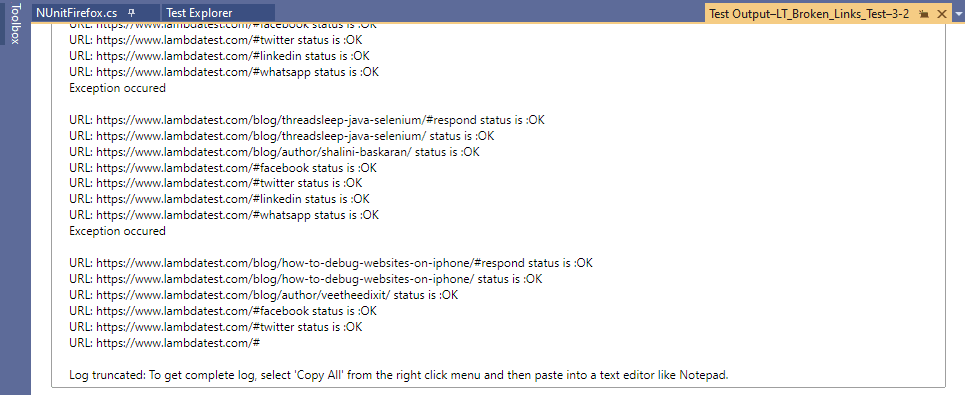
här är exekveringsbilden, som visar att testet utfördes framgångsrikt.

undantag har inträffat för länkar till ’dela ikoner’, dvs WhatsApp, Facebook, Twitter, etc. Bortsett från dessa länkar returnerar resten av länkarna på LambdaTest-bloggsidan HttpStatusCode.OK (dvs 200).
trasig Länktestning med Selenium PHP
implementering
Kodgenomgång
1. Läs sidkällan
funktionen file_get_contents i PHP används för att läsa sidans HTML-källa i en strängvariabel (t.ex. $html).
|
1
2
|
$test_url = ”https://www.lambdatest.com/blog/”;
$html = file_get_contents ($test_url);
|
2. Instansiera DOMDocument-klassen
domdocument-klassen i PHP representerar ett helt HTML-dokument och fungerar som dokumentträdets rot.
|
1
|
$htmlDom = nytt Domdokument;
|
3. Tolka HTML på sidan
funktionen DOMDocument:: loadHTML() används för att analysera HTML-källan som finns i $html. Vid framgångsrik körning returnerar funktionen ett DOMDocument-objekt.
|
1
|
@$htmlDom- >loadHTML ($html);
|
4. Extrahera länkarna från sidan
länkarna som finns på sidan extraheras med getElementsByTagName-metoden för DOMDocument-klassen. Elementen (eller länkarna) söks baserat på taggen ’a’ från den tolkade HTML-källan.
funktionen getElementsByTagName returnerar en ny instans av DOMNodeList som innehåller elementen (eller länkarna) i det lokala taggnamnet (dvs. tagg)
|
1
|
$länkar = $htmlDom – > getElementsByTagName (’a’);
|
5. Iterera genom webbadresserna för validering
DOMNodeList, som skapades I steg (4), korsas för att kontrollera länkarnas giltighet.
|
1
2
3
|
foreach ($länkar som $ länk)
{
$linkText = $ link – >nodeValue;
|
detaljerna för motsvarande länk erhålls med attributet ’href’. GetAttribute-metoden används för samma.
|
1
|
$linkHref = $ länk – > getAttribute (’href’);
|
hoppa över att kontrollera länkarna om:
a. länken är tom
|
1
2
3
4
|
om (strlen (trim ($linkHref)) == 0)
{
fortsätt;
}
|
b. Länken är en hashtag eller en ankarlänk
|
1
2
3
4
|
om ($linkHref == ’#’)
{
fortsätt;
}
|
C. länken innehåller mailto eller addtoany (dvs. sociala delningsalternativ).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
function check_nonlinks($test_url, $ test_pattern)
{
om (preg_match ($test_pattern, $test_url) = = false)
{
returnera falskt;
}
annat
{
returnera sant;
}
}
allmän funktion test_Broken_Links()
{
$pattern_1 = ’ / \baddtoany\b/’;
$pattern_2 = ’ / \bmailto\b/’;
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
om ((check_nonlinks ($linkHref, $pattern_1))//(check_nonlinks ($linkHref, $pattern_2)))
{
Skriv ut (”\nAdd_To_Any eller e-post stött på”);
fortsätt;
}
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
}
|
preg_match-funktionen använder ett reguljärt uttryck (regex) för att utföra en skiftlägeskänslig sökning efter mailto och addtoany. De reguljära uttrycken för mailto & addtoany är ’/ \ bmailto \ b /’&’/ \baddtoany\b / ’ respektive.
6. Validera HTTP-koden med cURL
vi använder curl för att få information om status för motsvarande länk. Det första steget är att initiera en cURL-session med länken där validering måste göras. Metoden returnerar en cURL instans som kommer att användas i den senare delen av genomförandet.
|
1
|
$curl = curl_init ($linkHref);
|
curl_setopt-metoden används för att ställa in Alternativ på det givna cURL-sessionhandtaget (dvs. $curl).
|
1
|
curl_setopt ($curl, CURLOPT_NOBODY, sant);
|
curl_exec-metoden kallas för utförande av den givna cURL-sessionen. Den returnerar True vid framgångsrikt utförande.
|
1
|
$resultat = curl_exec ($curl);
|
Detta är den viktigaste delen av logiken som kontrollerar brutna länkar på sidan. Funktionen curl_getinfo som tar cURL session handle (dvs. $curl) och CURLINFO_RESPONSE_CODE (dvs. CURLINFO_HTTP_CODE) används för att få information om den senaste överföringen. Den returnerar HTTP-statuskoden som svar.
|
1
|
$statusCode = curl_getinfo ($curl, CURLINFO_HTTP_CODE);
|
när begäran har slutförts returneras HTTP-statuskoden på 200, och variabeln som håller giltiga länkar räknas (dvs. $valid_links) ökas. För länkar som resulterar i HTTP-statuskoden på 400 (eller mer) utförs en kontroll om ’länken under test’ var Lambdatests LinkedIn-sida. Som tidigare nämnts kommer LinkedIn-sidans statuskod att vara 999; därför ökas $ valid_links.
för alla andra länkar som returnerade HTTP-statuskoden på 400 (eller mer) ökas variabeln som håller de trasiga länkarna (dvs. $broken_links).
|
1
2
3
4
5
6
7
8
9
10
|
om (($linkedin_page_status) &&($statusCode == 999))
{
Skriv ut (”\nLink”. $linkHref . ”är LinkedIn-sida och status är”.$statusCode);
$ validlinks++;
}
annat
{
Skriv ut (”\nLink”. $linkHref . ”är trasig länk och status är”.$ statusCode );
$ trasiga länkar++;
}
|
utförande
vi använder PHPUnit-ramverket för testning för trasiga länkar på sidan. För att ladda ner PHPUnit framework, Lägg till file composer.json i rotmappen och kör kompositör kräver på terminalen.
kör följande kommando på terminalen för att kontrollera trasiga länkar i Selenium PHP.
|
1
|
leverantör \ bin \ phpunit tester\BrokenLinksTest.php
|
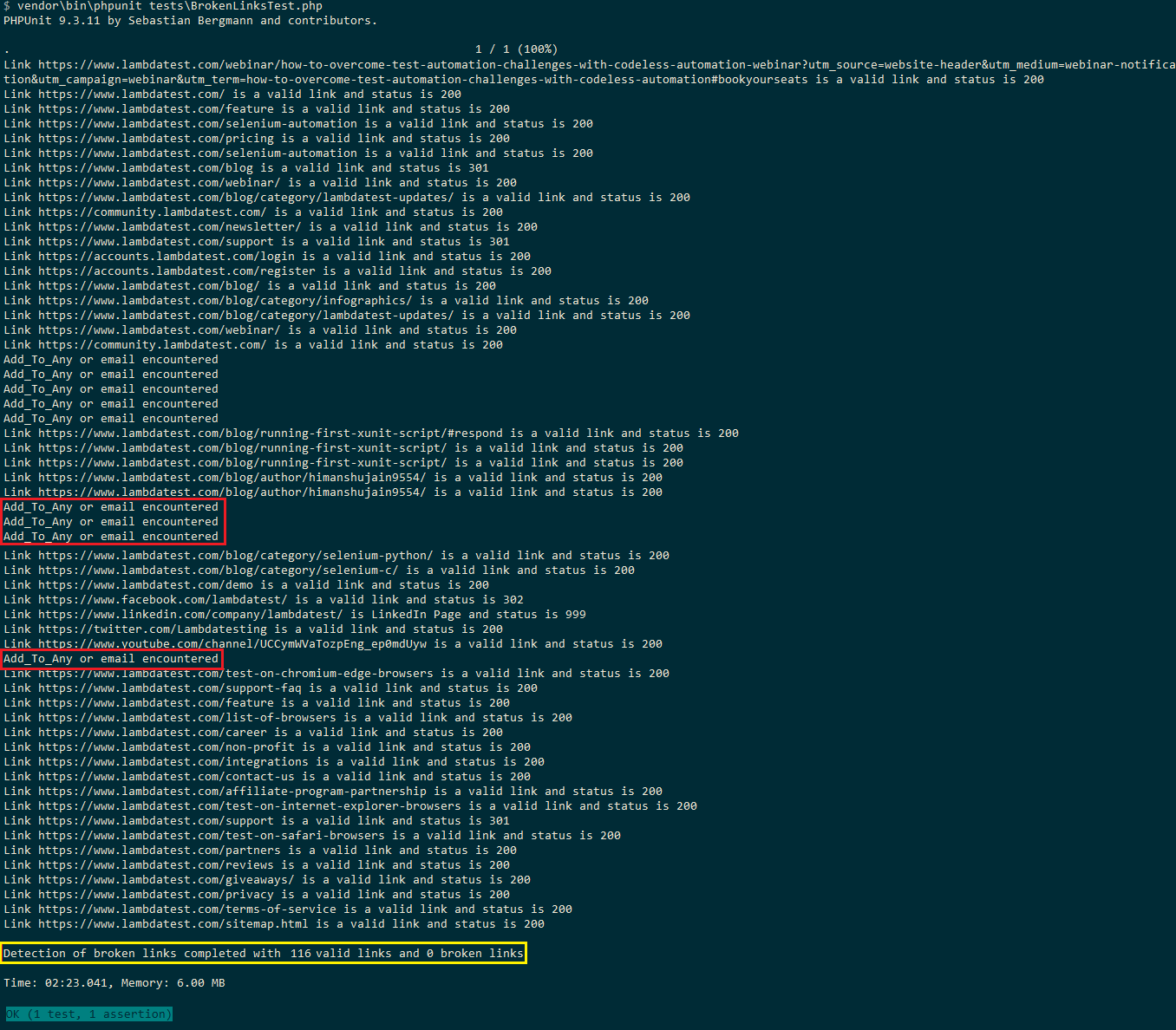
här är exekveringsbilden som visar totalt 116 giltiga länkar och 0 trasiga länkar på LambdaTest-bloggen. Eftersom länkar för social delning (dvs. addtoany) och e-postadress ignoreras är det totala antalet 116 (169 i Selenium Python-testet).
slutsats

trasiga länkar, även kallade döda länkar eller rotlänkar, kan hindra användarupplevelsen om de finns på webbplatsen. Trasiga länkar kan också påverka rankningen på sökmotorer. Därför bör bruten länktestning utföras regelbundet för aktiviteter relaterade till webbplatsutveckling och testning.
snarare än att förlita sig på tredjepartsverktyg eller manuella metoder för att kontrollera trasiga länkar på en webbplats, kan trasiga länkar testning göras med Selenium WebDriver med Java, Python, C# eller PHP. HTTP-statuskoden, som returneras vid åtkomst till en webbsida, bör användas för att kontrollera trasiga länkar med Selenium framework.
Vanliga frågor
hur hittar jag trasiga länkar i selenium Python?
för att kontrollera de trasiga länkarna måste du samla alla länkar på webbsidan baserat på taggen. Skicka sedan en HTTP-begäran om länkarna och läs HTTP-svarskoden. Ta reda på om länken är giltig eller trasig baserat på HTTP-svarskoden.
Hur söker jag efter trasiga länkar?
för att kontinuerligt övervaka din webbplats för trasiga länkar med Google Search Console, följ dessa steg:
- logga in på ditt Google Search Console-konto.
- klicka på webbplatsen du vill övervaka.
- klicka på Genomsökningoch klicka sedan på Hämta som Google.
- när Google genomsöker webbplatsen klickar du på genomsökning för att komma åt resultaten och sedan på genomsökningsfel.
- Under URL-fel kan du se alla trasiga länkar som Google upptäckte under genomsökningsprocessen.
Hur hittar jag trasiga bilder på webben med selenium?
besök sidan. Iterera genom varje bild i HTTP-arkivet och se om den har en 404 statuskod. Lagra varje trasig bild i en samling. Kontrollera att samlingen trasiga bilder är tom.
Hur får jag alla länkar i selen?
du kan få alla länkar som finns på en webbsida baserat på<a > taggen närvarande. Varje<en > – tagg representerar en länk. Använd selenium locators för att enkelt hitta alla sådana taggar.
varför är trasiga länkar dåliga?
de kan skada användarupplevelsen-när användare klickar på länkar och når återvändsgränd 404 fel, de blir frustrerade och kan aldrig återvända. De devalverar dina SEO – ansträngningar-trasiga länkar begränsar flödet av länkkapital på hela din webbplats, vilket påverkar rankningen negativt.

Himanshu Sheth
Himanshu Sheth är en erfaren teknolog och bloggare med mer än 15+ års mångsidig arbetslivserfarenhet. Han arbetar för närvarande som ’Lead Developer Evangelist’ och ’Senior Manager’ på LambdaTest. Han är väldigt aktiv med startgemenskapen i Bengaluru (och söderut) och älskar att interagera med passionerade grundare på sin personliga blogg (som han har behållit sedan de senaste 15+ åren).