




cum să verificați conținutul duplicat
cum să găsiți conținutul duplicat
conținutul duplicat ar trebui redus la minimum pe un site web, deoarece poate îngreuna motoarele de căutare să decidă ce Versiune să clasifice pentru o interogare.
în timp ce o ‘penalizare de conținut duplicat’ este un mit în SEO, conținutul foarte similar poate provoca ineficiențe de crawling, poate dilua PageRank-ul și poate fi un semn de conținut care ar putea fi consolidat, eliminat sau îmbunătățit.
merită să ne amintim că conținutul duplicat și similar este o parte naturală a web-ului, care adesea nu este o problemă pentru motoarele de căutare care, prin design, vor canoniza adresele URL și le vor filtra acolo unde este cazul. Cu toate acestea, la scară poate fi mai problematică.
prevenirea conținutului duplicat vă pune în control asupra a ceea ce este indexat și clasat – mai degrabă decât lăsându-l la motoarele de căutare. Puteți limita deșeurile bugetare cu crawlere și consolida indexarea și semnalele de legătură pentru a ajuta la clasare.
acest tutorial vă prezintă modul în care puteți utiliza păianjenul SEO Screaming Frog pentru a găsi atât conținut duplicat exact, cât și conținut aproape duplicat în care unele texte se potrivesc între paginile unui site web.
conținutul duplicat identificat de orice instrument, inclusiv SEO Spider, trebuie revizuit în context. Urmăriți videoclipul nostru sau continuați să citiți ghidul nostru de mai jos.
pentru a începe, descărcați SEO Spider, care este gratuit pentru accesarea cu crawlere a până la 500 de adrese URL. Primii 2 pași sunt disponibili numai cu licență. Dacă sunteți utilizator gratuit, treceți la numărul 3 din Ghid.
1) Activați ‘lângă duplicate’ prin ‘Config > conținut > duplicate’
implicit SEO Spider va identifica automat paginile duplicate exacte. Cu toate acestea, pentru a identifica ‘aproape duplicate’ configurația trebuie să fie activată, ceea ce îi permite să stocheze conținutul fiecărei pagini.
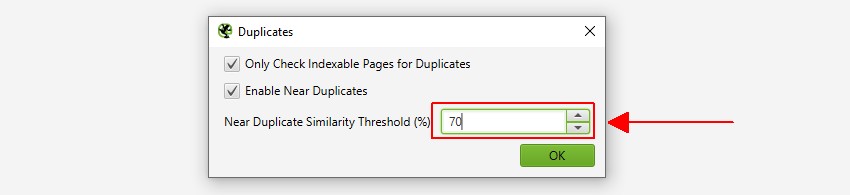
SEO Spider va identifica aproape duplicate cu o potrivire de similitudine de 90%, care poate fi ajustată pentru a găsi conținut cu un prag de similitudine mai mic.
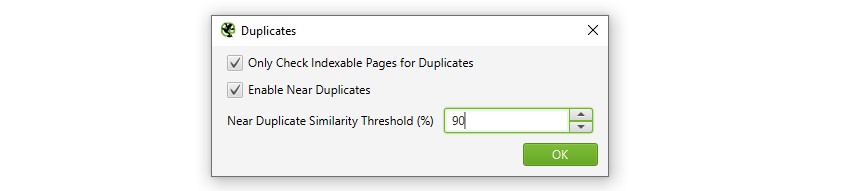
SEO Spider va verifica, de asemenea, doar paginile ‘indexabile’ pentru duplicate (atât pentru duplicate exacte, cât și pentru duplicate apropiate).
aceasta înseamnă că dacă aveți două URL-uri care sunt identice, dar una este canonicalizată la cealaltă (și, prin urmare, ‘non – indexabile’), aceasta nu va fi raportată-cu excepția cazului în care această opțiune este dezactivată.
dacă sunteți interesat să găsiți probleme legate de bugetul de accesare cu crawlere, debifați opțiunea ‘Verificați numai paginile indexabile pentru duplicate’, deoarece acest lucru vă poate ajuta să găsiți zone cu potențiale deșeuri de accesare cu crawlere.
2) ajustați ‘zona de conținut’ pentru analiză prin ‘Config > zona de conținut >’
puteți configura conținutul utilizat pentru analiza aproape duplicat. Pentru un crawl nou, vă recomandăm să utilizați setarea implicită și să o rafinați mai târziu când conținutul utilizat în analiză poate fi văzut și luat în considerare.
SEO Spider va exclude automat atât elementele nav, cât și elementele de subsol pentru a se concentra pe conținutul principal al corpului. Cu toate acestea, nu fiecare site web este construit folosind aceste elemente HTML5, astfel încât să puteți rafina zona de conținut utilizată pentru analiză, dacă este necesar. Puteți alege să ‘includeți’ sau ‘excludeți’ tag-uri HTML, clase și ID-uri în analiză.
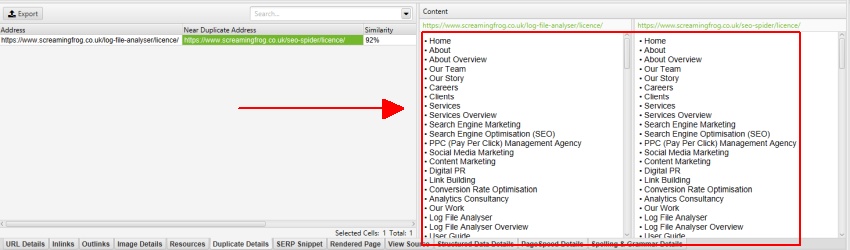
de exemplu, site-ul Screaming Frog are un meniu mobil în afara elementului nav, care este inclus în mod implicit în analiza conținutului. În timp ce acest lucru nu este de mult de o problemă, în acest caz, pentru a ajuta se concentreze pe textul corpul principal al paginii numele său de clasă ‘mobile-menu__dropdown’ poate fi introdus în caseta ‘Exclude clase’.
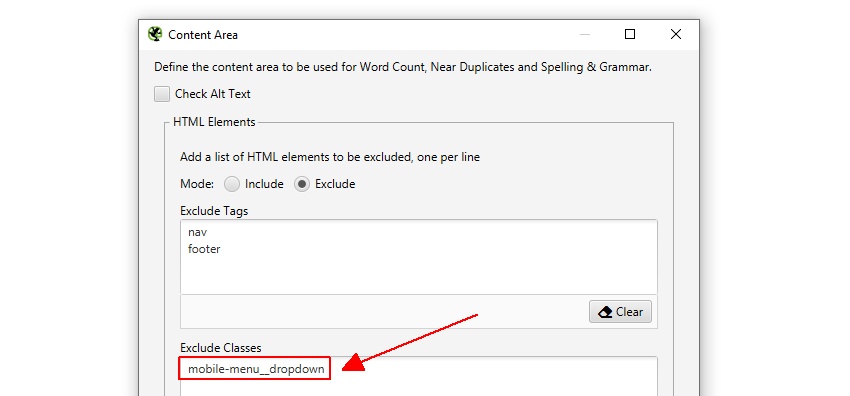
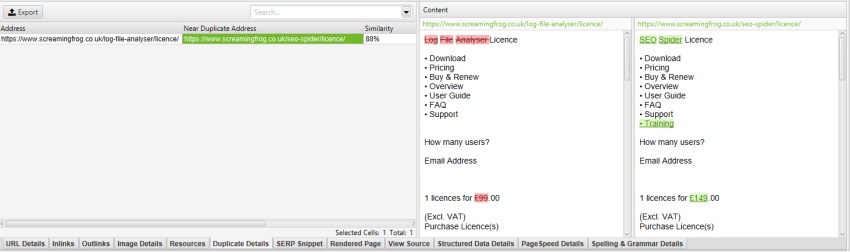
aceasta va exclude meniul de a fi inclus în algoritmul de analiză a conținutului duplicat. Mai multe despre asta mai târziu.
3) accesați cu crawlere site-ul web
deschideți SEO Spider, tastați sau copiați în site-ul web pe care doriți să îl accesați cu crawlere în caseta ‘Enter URL to spider’ și apăsați ‘Start’.
așteptați până când crawl-ul se termină și ajunge la 100%, dar puteți vizualiza și unele detalii în timp real.
4) Vizualizați duplicatele în fila ‘Conținut’
fila Conținut are 2 filtre legate de conținutul duplicat, ‘duplicate exacte’ și ‘duplicate apropiate’.
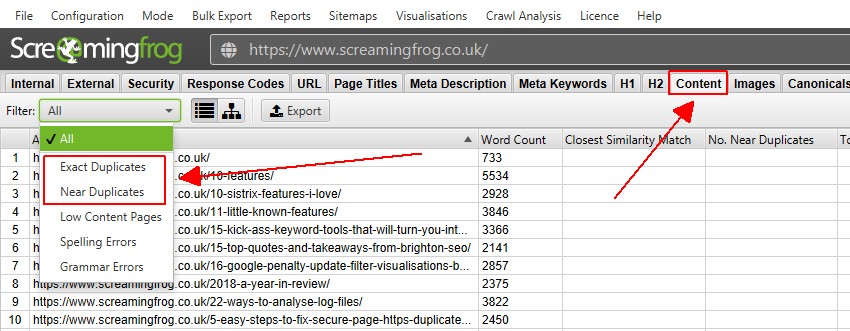
numai ‘duplicate exacte’ sunt disponibile pentru vizualizare în timp real în timpul unui crawl. ‘Near Duplicates’ necesită calcul la sfârșitul crawl-ului prin post ‘Crawl Analysis’ pentru ca acesta să fie populat cu date.
panoul ‘prezentare generală’ din dreapta afișează un mesaj ‘(analiza Crawl necesară)’ împotriva filtrelor care necesită ca analiza post crawl să fie populată cu date.
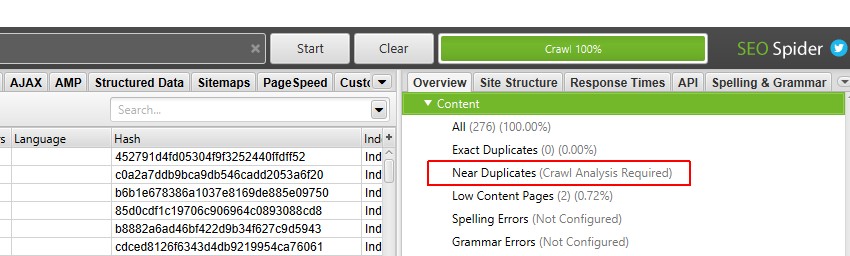
5) Faceți clic pe ‘Crawl Analysis >Start’ pentru a popula ‘near Duplicates’ Filter
pentru a popula ‘near Duplicates’ filter, ‘cel mai apropiat meci de similitudine’ și ‘No. Lângă coloanele duplicatelor, trebuie doar să faceți clic pe un buton de la sfârșitul crawl-ului.

cu toate acestea, dacă ați configurat ‘Crawl Analysis’ anterior, poate doriți să verificați din nou, sub ‘Crawl Analysis > Configure’ că ‘near Duplicates’ este bifat.
de asemenea, puteți debifa alte elemente care necesită, de asemenea, analiza post crawl pentru a face acest pas mai rapid.
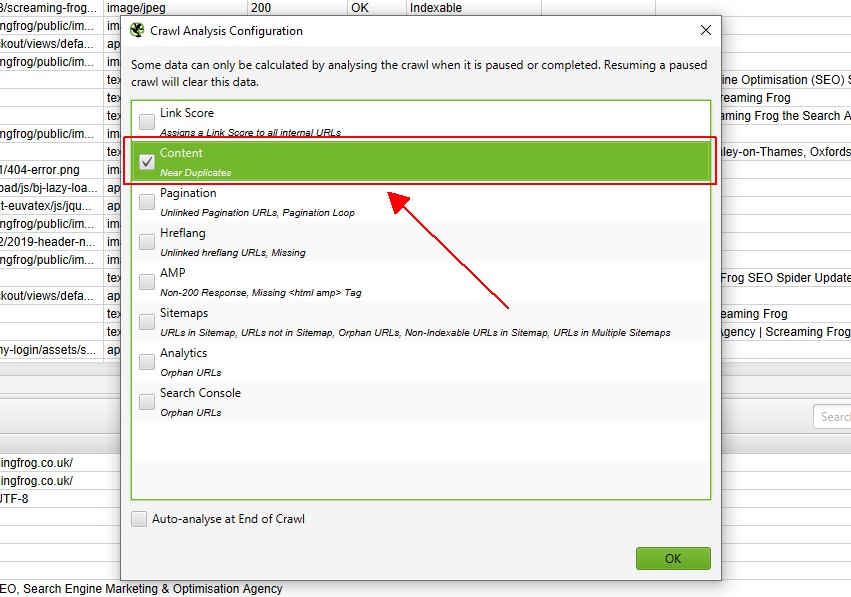
când crawl analysis a finalizat bara de progres ‘analysis’ va fi la 100%, iar filtrele nu vor mai avea mesajul ‘(Crawl Analysis Required)’.
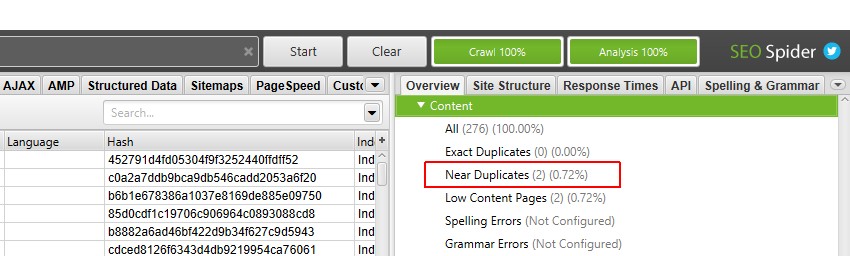
acum Puteți vizualiza filtrul și coloanele populate aproape duplicate.
6) Vezi ‘Content’ Tab & ‘Exact’& ‘near’ Duplicates Filters
după efectuarea analizei post crawl, filtrul ‘near Duplicates’, ‘cel mai apropiat meci de similitudine’ și ‘No. Coloanele din apropierea duplicatelor vor fi populate. Numai adresele URL cu conținut peste pragul de similitudine selectat vor conține date, celelalte vor rămâne necompletate. În acest caz, site-ul Screaming Frog are doar două.
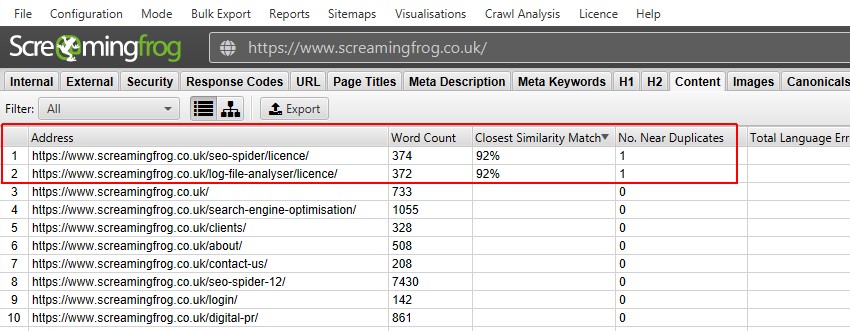
un crawl de un site mai mare, cum ar fi BBC va dezvălui multe altele.
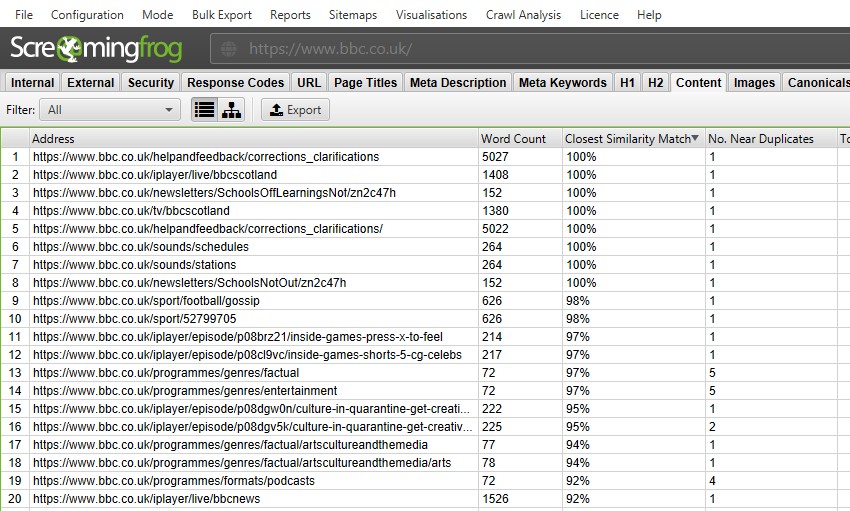
puteți filtra după următoarele–
- duplicate exacte – acest filtru va afișa pagini care sunt identice între ele folosind algoritmul MD5 care calculează o valoare ‘ hash ‘pentru fiecare pagină și poate fi văzut în coloana’ hash’. Această verificare este efectuată în funcție de HTML-ul complet al paginii. Acesta va afișa toate paginile cu valori hash potrivite care sunt exact aceleași. Paginile duplicate exacte pot duce la împărțirea semnalelor PageRank și imprevizibilitatea în clasament. Ar trebui să existe doar o singură versiune canonică a unei adrese URL care există și este legată de intern. Alte versiuni nu ar trebui să fie legate și ar trebui să fie redirecționate 301 către versiunea canonică.
- Near Duplicates – acest filtru va afișa pagini similare pe baza pragului de similitudine configurat folosind algoritmul minhash. Pragul poate fi ajustat în ‘Config > Spider > Content’ și este setat la 90% în mod implicit. Coloana’ cel mai apropiat meci de similitudine ‘ afișează cel mai mare procent de similitudine cu o altă pagină. ‘Nu. Coloana Near Duplicates afișează numărul de pagini care sunt similare cu pagina pe baza pragului de similitudine. Algoritmul este rulat împotriva textului de pe pagină, mai degrabă decât HTML-ul complet, cum ar fi duplicatele exacte. Conținutul utilizat pentru această analiză poate fi configurat în ‘Config > Content > Area’. Paginile pot avea o similitudine de 100%, dar pot fi doar un duplicat apropiat, mai degrabă decât un duplicat exact. Acest lucru se datorează faptului că duplicatele exacte sunt excluse ca duplicate apropiate, pentru a evita ca acestea să fie marcate de două ori. Scorurile de similitudine sunt, de asemenea, rotunjite, astfel încât 99,5% sau mai mare vor fi afișate ca 100%.
paginile duplicate ar trebui revizuite manual, deoarece există multe motive legitime pentru ca unele pagini să fie foarte asemănătoare în conținut, cum ar fi variațiile produselor care au volumul de căutare în jurul atributului lor specific.
cu toate acestea, adresele URL marcate ca aproape duplicate ar trebui revizuite pentru a lua în considerare dacă ar trebui să existe ca pagini separate datorită valorii lor unice pentru utilizator sau dacă ar trebui eliminate, consolidate sau îmbunătățite pentru a face conținutul mai aprofundat și unic.
7) Vizualizați adresele URL Duplicate prin fila ‘Detalii Duplicate’
pentru ‘duplicate exacte’, este mai ușor să le vizualizați doar în fereastra de sus utilizând filtrul – deoarece sunt grupate împreună și împărtășesc aceeași valoare ‘hash’.
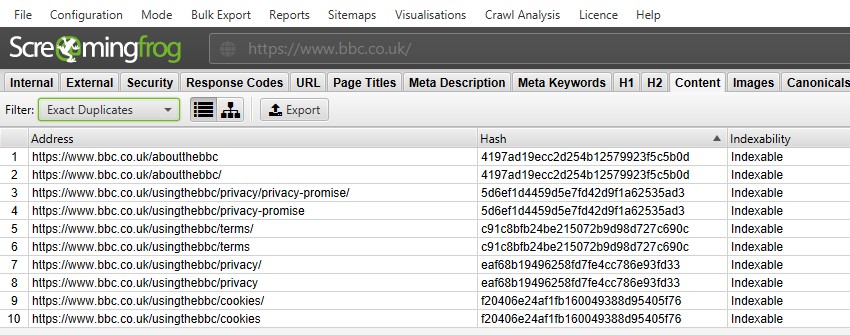
în captura de ecran de mai sus, fiecare adresă URL are un duplicat exact corespunzător datorită unei versiuni slash trailing și non-trailing slash.
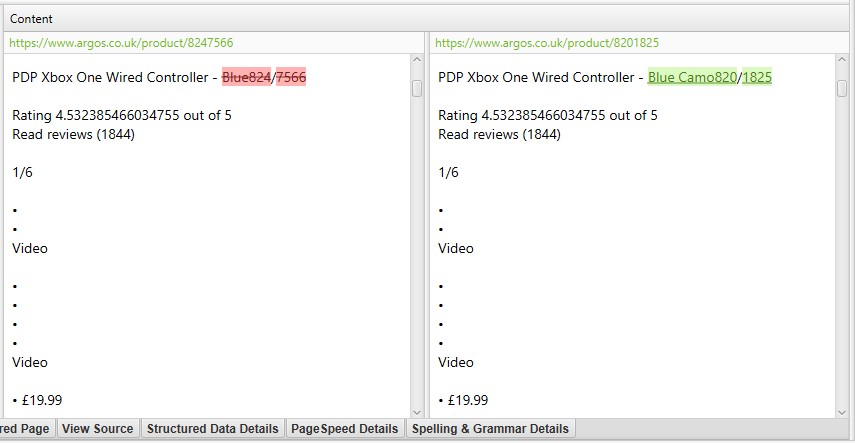
pentru ‘duplicate apropiate’, faceți clic pe fila ‘Duplicate Details’ din partea de jos, care populează panoul inferior al ferestrei cu ‘near duplicate address’ și similitudinea fiecărei adrese URL aproape duplicate descoperite.
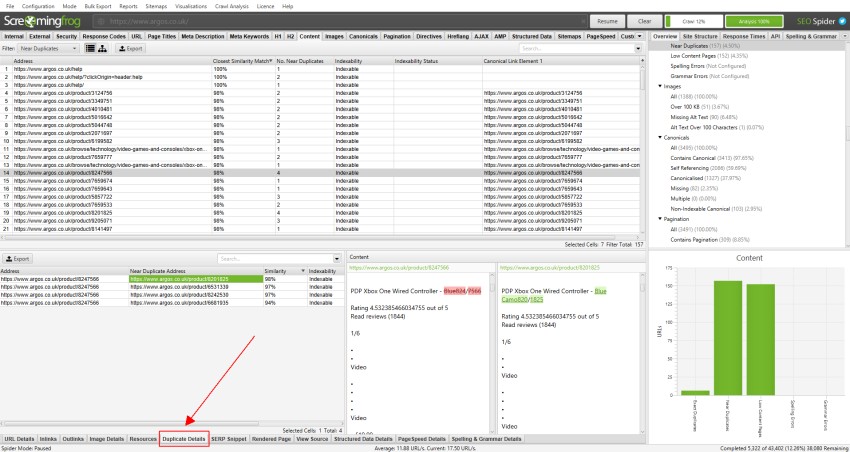
de exemplu, dacă există 4 duplicate apropiate descoperite pentru o adresă URL în fereastra de sus, toate acestea pot fi vizualizate.
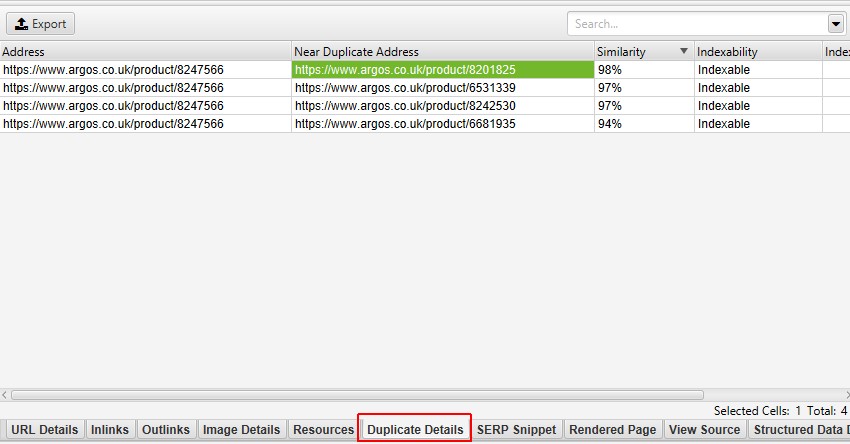
partea dreaptă a filei ‘Duplicate Details’ va afișa conținutul aproape duplicat descoperit din pagini și va evidenția diferențele dintre pagini atunci când faceți clic pe fiecare ‘near duplicate address’.
dacă există conținut duplicat în fila Detalii duplicat care nu doriți să faceți parte din analiza de conținut duplicat, excludeți sau includeți orice elemente HTML, clase sau ID-uri (așa cum este evidențiat la punctul 2), & re-rulați analiza crawl.
8) duplicatele de export în vrac
atât duplicatele exacte, cât și cele apropiate pot fi exportate în vrac prin exporturile de ‘export în vrac > conținut > duplicate exacte’ și ‘duplicate apropiate’.

Sfat Final! Rafinare prag similitudine & zona de conținut, & re-rula analiza Crawl
Post-crawl aveți posibilitatea să ajustați atât pragul de similitudine aproape duplicat, și zona de conținut utilizat pentru analiza aproape duplicat.
puteți rula din nou analiza crawl pentru a găsi conținut mai mult sau mai puțin similar-fără a accesa din nou site – ul web.
după cum sa subliniat mai devreme, site-ul Screaming Frog are un meniu mobil în afara elementului nav, care este inclus în mod implicit în analiza conținutului. Meniul mobil poate fi văzut în previzualizarea conținutului din fila ‘duplicate details’.
excluzând meniul vertical ‘mobile-menu__’ din caseta ‘excludere clase’ din zona ‘Config > Content >’, meniul mobil este eliminat din previzualizarea conținutului și din analiza aproape duplicat.
acest lucru poate ajuta cu adevărat la reglarea fină a identificării conținutului aproape duplicat în zonele principale de conținut, fără a fi nevoie să re-accesați cu crawlere.
rezumat
ghidul de mai sus ar trebui să ilustreze modul de utilizare a SEO Spider ca verificator de conținut duplicat pentru site-ul dvs. web. Pentru cele mai precise rezultate, rafinați zona de conținut pentru analiză și ajustați pragul pentru diferite grupuri de pagini.
vă rugăm să citiți și Întrebările frecvente Screaming Frog SEO Spider și ghidul complet de utilizare pentru mai multe informații despre instrument.
dacă aveți întrebări suplimentare, feedback sau sugestii pentru a îmbunătăți instrumentul de conținut duplicat în SEO Spider, atunci luați legătura prin asistență.