




Cum Să Găsiți Legături Rupte Folosind Selenium WebDriver?
ce gânduri vin în minte atunci când vin peste 404/Pagina nu a fost găsit/mort hyperlink-uri pe un site? Aargh! V-ar găsi enervant atunci când vin peste hyperlink-uri rupte, care este singurul motiv pentru care ar trebui să se concentreze continuu pe eliminarea existenței link-uri rupte în produsul web (sau site-ul). În loc de o inspecție manuală, puteți utiliza automatizarea pentru testarea legăturilor rupte folosind Selenium WebDriver.

când un anumit link este rupt și un vizitator aterizează pe pagină, aceasta afectează funcționalitatea acelei pagini și are ca rezultat o experiență slabă a utilizatorului. Link-urile moarte ar putea afecta credibilitatea produsului dvs., deoarece ar putea da impresia vizitatorilor dvs. că există un accent minim pe experiență.
dacă produsul dvs. web are multe pagini (sau link-uri) care duc la o eroare 404 (sau pagina nu a fost găsită), clasamentul produselor pe motoarele de căutare (de exemplu, Google) va fi, de asemenea, grav afectat. Eliminarea legăturilor moarte este una dintre părțile integrante ale activității SEO (optimizarea motorului de căutare).
în această parte a seriei tutorial seleniu WebDriver, ne arunca cu capul adânc în găsirea link-uri rupte folosind seleniu WebDriver. Am demonstrat testarea link-ul rupt folosind seleniu Python, seleniu Java, seleniu C#, și seleniu PHP.
Introducere în link-urile rupte în testarea Web
în termeni simpli, link-urile rupte (sau link-urile moarte) dintr-un site web (sau o aplicație web) sunt linkuri care nu sunt accesibile și nu funcționează conform așteptărilor. Link-urile ar putea fi temporar în jos din cauza problemelor de server sau configurate greșit la capătul din spate.
în afară de paginile care au ca rezultat eroarea 404, alte exemple proeminente de legături rupte sunt URL-uri malformate, linkuri către conținut (de exemplu, documente, pdf, imagini etc.) care au fost mutate sau șterse.
motive proeminente pentru link-uri rupte
iată câteva dintre motivele comune din spatele apariției link-uri rupte (link-uri moarte sau link-ul putrezeste):
- URL incorect sau scris greșit introdus de utilizator.
- modificările structurale ale site-ului web (adică legături permanente) cu redirecționări URL sau redirecționări interne nu sunt configurate corect.
- link – uri către conținut precum videoclipuri, documente etc. care sunt fie mutate, fie șterse. În cazul în care conținutul este mutat, ‘link-urile interne’ ar trebui redirecționate către link-urile desemnate.
- nefuncționare temporară a site-ului datorită întreținerii site-ului, ceea ce face ca site-ul web să fie temporar inaccesibil.
- etichete HTML rupte, erori JavaScript, personalizări incorecte HTML/CSS, elemente încorporate rupte etc., în cadrul paginii de conducere, poate duce la legături rupte.
- restricțiile de geolocalizare împiedică accesul la site-ul web de la anumite adrese IP (dacă sunt pe lista neagră) sau de la anumite țări din lume. Testarea geolocalizării cu Selenium ajută la asigurarea faptului că experiența este personalizată pentru locația (sau țara) de unde este accesat site-ul.
de ce ar trebui să verificați legăturile rupte?
link-urile rupte sunt un mare turn-off pentru vizitatorii care aterizează pe site-ul dvs. web. Iată câteva dintre principalele motive pentru care ar trebui să verificați legăturile rupte de pe site-ul dvs:
- legăturile rupte pot afecta experiența utilizatorului.
- eliminarea linkurilor rupte (sau moarte) este esențială pentru SEO (optimizarea motorului de căutare), deoarece poate afecta clasamentul site-ului pe motoarele de căutare (de exemplu, Google).
testarea legăturilor rupte se poate face folosind Selenium WebDriver pe o pagină web, care la rândul său poate fi utilizată pentru a elimina legăturile moarte ale site-ului.
legături rupte și coduri de stare HTTP
când un utilizator vizitează un site web, o solicitare este trimisă de browser către serverul site-ului. Serverul răspunde solicitării browserului cu un cod format din trei cifre numit cod de stare HTTP.’
un cod de stare HTTP este răspunsul serverului la o solicitare trimisă de browserul web. Aceste coduri de stare HTTP sunt considerate echivalente cu conversația dintre browser (de la care este trimisă solicitarea URL) și server.
deși diferite coduri de stare HTTP sunt utilizate în scopuri diferite, majoritatea codurilor sunt utile pentru diagnosticarea problemelor din site, minimizarea timpului de nefuncționare a site-ului, Numărul de linkuri moarte și multe altele. Prima cifră a fiecărui cod de stare din trei cifre începe cu numerele 1~5. Codurile de stare sunt reprezentate ca 1xx, 2xx.., 5xx pentru Indicarea codurilor de stare în acel interval special. Deoarece fiecare dintre aceste intervale constă dintr-o clasă diferită de răspuns la server, Am limita discuția la codurile de stare HTTP prezentate pentru legăturile rupte.
iată clasele comune de cod de stare care sunt utile în detectarea legăturilor rupte cu seleniul:
| clase de cod de stare HTTP | descriere |
|---|---|
| 1xx | serverul este încă de gândire prin cererea. |
| 2xx | cererea trimisă de browser a fost finalizată cu succes și răspunsul așteptat a fost trimis browserului de către server. |
| 3xx | aceasta indică faptul că se efectuează o redirecționare. De exemplu, redirecționarea 301 este utilizată popular pentru implementarea redirecționărilor permanente pe un site web. |
| 4xx | acest lucru indică faptul că fie o anumită pagină (sau site-ul complet) nu este accesibil. |
| 5xx | aceasta indică faptul că serverul nu a putut finaliza solicitarea, chiar dacă o solicitare validă a fost trimisă de browser. |
coduri de stare HTTP prezentate pe detectarea de link-uri rupte
aici sunt unele dintre codurile de stare HTTP comune prezentate de serverul de web pe care se confruntă cu o legătură întreruptă:
| cod de stare HTTP | descriere |
|---|---|
| 400 (cerere proastă) | serverul nu poate procesa cererea, deoarece adresa URL menționată este incorectă. |
| 400 (cerere proastă-gazdă proastă) | aceasta indică faptul că numele gazdei este nevalid din cauza căruia cererea nu poate fi procesată. |
| 400 (Bad Request-Bad URL) | acest lucru indică faptul că serverul nu poate procesa cererea ca URL-ul introdus este malformat (adică lipsă paranteze, slash-uri, etc.). |
| 400 (cerere proastă-Timeout) | aceasta indică faptul că cererile HTTP au expirat. |
| 400 (cerere proastă-gol) | răspunsul returnat de server este gol, fără conținut și fără cod de răspuns. |
| 400 (Solicitare proastă – Resetare) | aceasta indică faptul că serverul nu poate procesa solicitarea, deoarece este ocupat în procesarea altor solicitări sau a fost configurat greșit de proprietarul site-ului. |
| 403 (interzis) | o cerere reală este trimisă serverului, dar refuză să îndeplinească același lucru, deoarece este necesară autorizarea. |
| 404 (Pagina nu a fost găsită) | resursa (sau pagina) nu este disponibilă pe server. |
| 408 (cerere de expirare) | serverul a expirat în așteptarea cererii. Clientul (adică browserul) poate trimite aceeași solicitare în timpul în care serverul este pregătit să aștepte. |
| 410 (Gone) | un cod de stare HTTP care este mai permanent decât 404 (Pagina nu a fost găsită). 410 înseamnă că pagina a dispărut. pagina nu este disponibilă pe server și nici un mecanism de redirecționare (sau redirecționare) nu a fost configurat. Link-urile care indică o pagină 410 trimit vizitatori la o resursă moartă. |
| 503 (serviciu indisponibil) | aceasta indică faptul că serverul este supraîncărcat temporar, din cauza căruia nu poate procesa solicitarea. De asemenea, poate însemna că întreținerea se efectuează la server, indicând motoarele de căutare despre timpul de nefuncționare temporar al site-ului. |
Cum de a găsi link-uri rupte folosind Selenium WebDriver?
indiferent de limba utilizată cu Selenium WebDriver, principiile directoare pentru testarea legăturilor rupte folosind Selenium rămân aceleași. Iată pașii pentru testarea legăturilor rupte folosind Selenium WebDriver:
- utilizați eticheta pentru a colecta detalii despre toate linkurile prezente pe pagina web.
- trimite o cerere HTTP pentru fiecare link.
- Verificați codul de răspuns corespunzător primit ca răspuns la solicitarea trimisă în pasul anterior.
- validați dacă legătura este întreruptă sau nu pe baza codului de răspuns trimis de server.
- repetați pașii (2-4) pentru fiecare link prezent pe pagină.
în acest tutorial Selenium WebDriver, ne-ar demonstra modul de a efectua testarea link rupt folosind Selenium WebDriver în Python, Java, C#, și PHP. Testele sunt efectuate pe combinația (Chrome 85.0 + Windows 10), iar execuția se efectuează pe grila Selenium bazată pe cloud furnizată de LambdaTest.
pentru a începe cu LambdaTest, creați un cont pe platformă și notați numele de utilizator & cheie de acces disponibilă din secțiunea profil pe LambdaTest. Capacitățile browser-ul sunt generate folosind Lambdatest capabilități Generator.
aici este scenariul de testare folosit pentru a găsi link-uri rupte pe un site folosind seleniu:
scenariu de testare
- du-te la LambdaTest Blog adică https://www.lambdatest.com/blog/ pe Chrome 85.0
- colecta toate link-urile prezente pe pagina
- trimite cerere HTTP pentru fiecare link
- print dacă link-ul este rupt sau nu pe terminalul
este important să rețineți că timpul petrecut în link-uri rupte de testare folosind seleniu depinde de numărul de link-uri prezente pe ‘pagina web în curs de testare.’Cu cât numărul de link-uri de pe pagină este mai mare, cu atât mai mult timp va fi petrecut pentru a găsi link-uri rupte. De exemplu, LambdaTest are un număr foarte mare de link-uri (~150+); prin urmare, procesul de a găsi link-uri rupte ar putea dura ceva timp (aproximativ câteva minute).

rulați scriptul de testare pe SELENIUM GRID
2000+ browsere și sistem de operare
înscriere gratuită
testarea link-ului rupt folosind Selenium Java
implementare
Cod WalkThrough
1. Importați pachetele necesare
metodele din pachetul HttpURLConnection sunt utilizate pentru trimiterea cererilor HTTP și captarea codului de stare HTTP (sau răspuns).
metodele din regex.Pachet model verificați dacă linkul corespunzător conține o adresă de e-mail sau un număr de telefon utilizând o sintaxă specializată deținută într-un model.
|
1
2
|
import java. net. HttpURLConnection;
import java.util.regex.Model;
|
2. Colectați linkurile prezente pe pagina
linkurile prezente pe adresa URL testată (adică blogul LambdaTest) sunt localizate folosind tagname în Selenium. Numele tag-ului folosit pentru identificarea elementului (sau link-ului) este ‘a’.
linkurile sunt plasate într-o listă pentru a itera prin listă pentru a verifica linkurile rupte de pe pagină.
|
1
|
listă<WebElement > link-uri = driver.findElements(de.tagName(„a”));
|
3. Itera prin URL-uri
obiectul Iterator este utilizat pentru looping prin lista creată în etapa (2)
|
1
|
Iterator< WebElement> link = Link-uri.iterator();
|
4. Identificați și verificați URL-urile
o buclă while este executată până când Iteratorul de timp (adică link) nu are mai multe elemente de iterat. Href a tag-ul ancora este preluat, și același lucru este stocat în variabila URL.
|
1
2
3
|
în timp ce (link.hasNext())
{
url = legătură.următorul().getAttribute („href”);
|
săriți verificarea linkurilor dacă:
a. Link-ul este nul sau gol
|
1
2
3
4
5
|
dacă ((url = = null) / / (url.isEmpty()))
{
sistem.afară.println („URL-ul nu este configurat pentru anchor tag sau este gol”);
continuare;
}
|
b. Link-ul conține mailto sau numărul de telefon
|
1
2
3
4
5
|
dacă ((url.startsWith (mail_to)) / / (url.startsWith (tel)))
{
sistem.afară.println („adresă de e-mail sau telefon detectat”);
continuare;
}
|
când verificați pagina LinkedIn, codul de stare HTTP este 999. O variabilă booleană (i. e., LinkedIn) este setat la true pentru a indica faptul că nu este un link rupt.
|
1
2
3
4
5
|
dacă (url.startsWith (LinkedInPage))
{
sistem.afară.println („URL-ul începe cu LinkedIn, codul de stare așteptat este 999”);
bLinkedIn = adevărat;
}
|
5. Validați legăturile prin codul de stare
metodele din clasa HttpURLConnection oferă dispoziția pentru trimiterea cererilor HTTP și captarea codului de stare HTTP.
metoda openConnection a clasei URL deschide conexiunea la adresa URL specificată. Returnează o instanță URLConnection reprezentând o conexiune la obiectul de la distanță, care este menționată de URL-ul. Este de tip turnat la HttpURLConnection.
|
1
2
3
4
5
6
7
|
HttpURLConnection urlconnection = null;
……………………………………….
……………………………………….
……………………………………….
urlconnection = (HttpURLConnection) (URL nou(url).openConnection());
urlconnection.setRequestMethod („cap”);
|
setRequestMethod în clasa HttpURLConnection stabilește metoda de solicitare URL. Tipul de cerere este setat la cap, astfel încât numai anteturile sunt returnate. Pe de altă parte, tipul de solicitare GET ar fi returnat organismul documentului, ceea ce nu este necesar în acest scenariu de testare special.
metoda de conectare din clasa HttpURLConnection stabilește conexiunea la URL și trimite o solicitare HTTP.
|
1
|
urlconnection.conectează-te();
|
metoda getResponseCode returnează codul de stare HTTP pentru cererea trimisă anterior.
|
1
|
responseCode = urlconnection.getResponseCode();
|
pentru codul de stare HTTP este 400 (sau mai mult), variabila care conține numărul de legături rupte (adică, broken_links) este incrementat; altfel, variabila care conține legături valide (adică, valid_links) este incrementată.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
if (responseCode >= 400)
{
dacă ((bLinkedIn == true) && (responseCode = = LinkedInStatus))
{
sistem.afară.println (url + „este o pagină LinkedIn și nu este un link rupt”);
valid_links++;
}
else
{
sistem.afară.println (url + „este un link rupt”);
broken_links++;
}
}
else
{
sistem.afară.println (url + „este un link valid”);
valid_links++;
}
|
executie
pentru link-uri rupte de testare folosind seleniu Java, am creat un proiect în IntelliJ IDEA. Pom de bază.fișier xml a fost suficient pentru locuri de muncă!
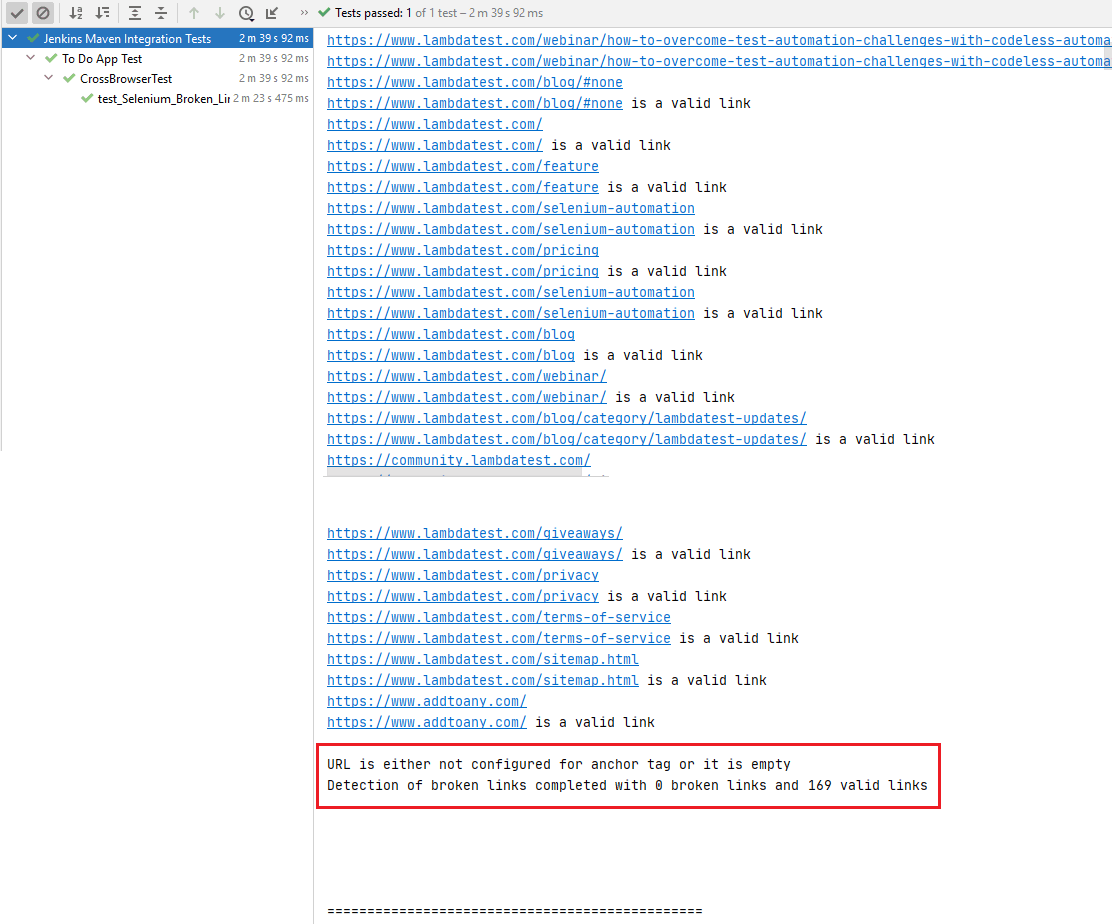
iată instantaneul de execuție, care indică 169 de linkuri valide și 0 linkuri rupte pe pagina blogului LambdaTest.
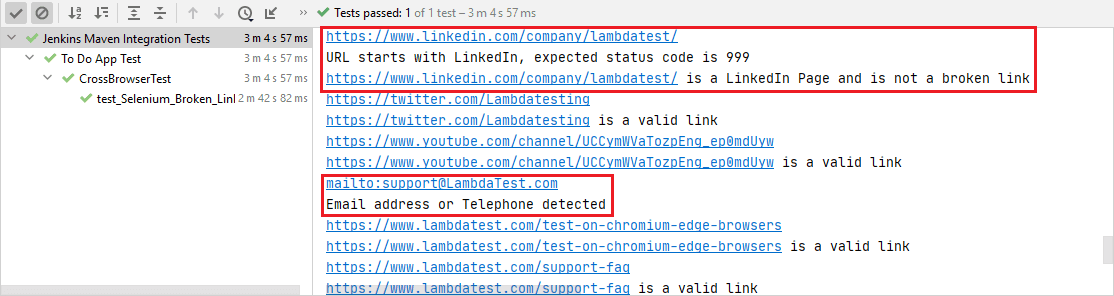
linkurile care conțin adresele de e-mail și numerele de telefon au fost excluse din lista de căutare, după cum se arată mai jos.
puteți vedea testul rulat în captura de ecran de mai jos și finalizarea acestuia în 2 min 35 secunde, așa cum se arată în jurnalele de automatizare ale LambdaTest.

testarea link-ul rupt folosind seleniu Python
punerea în aplicare
Cod WalkThrough
1. Importați module
în afară de importul modulelor Python pentru Selenium WebDriver, importăm și modulul requests. Modulul cereri vă permite să trimiteți tot felul de cereri HTTP. Poate fi folosit și pentru trecerea parametrilor în URL, trimiterea anteturilor personalizate și multe altele.
|
1
2
3
|
cereri de import
import urllib3
din cereri.excepții import MissingSchema, InvalidSchema, InvalidURL
|
2. Colectați linkurile prezente pe pagina
linkurile prezente pe URL-ul testat (adică blogul LambdaTest) se găsesc prin localizarea elementelor web de către selectorul CSS „a” Proprietate.
|
1
|
link – uri = conducător auto.find_elements(de.CSS_SELECTOR, „a”)
|
deoarece dorim ca elementul să fie iterabil, folosim metoda find_elements (și nu metoda find_element).
3. Itera prin URL-uri pentru validare
metoda head a modulului requests este utilizată pentru a trimite o cerere HEAD la URL-ul specificat. Metoda get_attribute este folosit pe fiecare link pentru a obține ‘href’ atribut al tag-ul ancora.
metoda head este utilizată în principal în scenarii în care sunt necesare numai anteturi status_code sau HTTP și nu este necesar conținutul fișierului (sau URL). Metoda capului returnează cererile.Obiect de răspuns care conține, de asemenea, codul de stare HTTP (adică cerere.status_code).
|
1
2
3
4
|
pentru link în link-uri:
try:
request = requests.cap(link.get_attribute (‘href’), date = {‘cheie’:’valoare’})
print(„starea” + link.get_attribute („href”) + „este” + str(cerere.status_code))
|
același set de operații sunt efectuate iterativ până când toate ‘link-urile’ prezente pe pagină au fost epuizate.
4. Validați legăturile prin codul de stare
dacă codul de răspuns HTTP pentru solicitarea HTTP trimisă la Pasul(3) este 404 (adică pagina nu a fost găsită), înseamnă că legătura este o legătură întreruptă. Pentru link-uri care nu sunt rupte, codul de stare HTTP este 200.
|
1
2
3
4
|
dacă (cerere.status_code == 404):
broken_links = (broken_links + 1)
altceva:
valid_links = (valid_links + 1)
|
5. Omiteți solicitările irelevante
atunci când sunt aplicate pe link-uri care nu conțin atributul ‘href’ (de exemplu, mailto, telefon etc.), metoda capului are ca rezultat o excepție (adică MissingSchema, InvalidSchema).
|
1
2
3
4
5
6
|
except requests.exceptions.MissingSchema:
print(„Encountered MissingSchema Exception”)
except requests.exceptions.InvalidSchema:
print(„Encountered InvalidSchema Exception”)
except:
print („am întâlnit o altă execuție”)
|
aceste excepții sunt prinse și același lucru este tipărit pe terminal.
executie
am folosit PyUnit (sau unittest) aici, cadrul de testare implicit în Python pentru link-uri rupte de testare folosind seleniu. Rulați următoarea comandă pe terminal:
|
1
|
python Broken_Links.py
|
execuția ar dura aproximativ 2-3 minute, deoarece pagina blogului LambdaTest este formată din aproximativ 150 de linkuri. Captura de ecran de execuție de mai jos arată că pagina are 169 de linkuri valide și zero linkuri rupte.
veți asista la excepția InvalidSchema sau la excepția MissingSchema în unele locuri, ceea ce indică faptul că aceste legături sunt omise din evaluare.
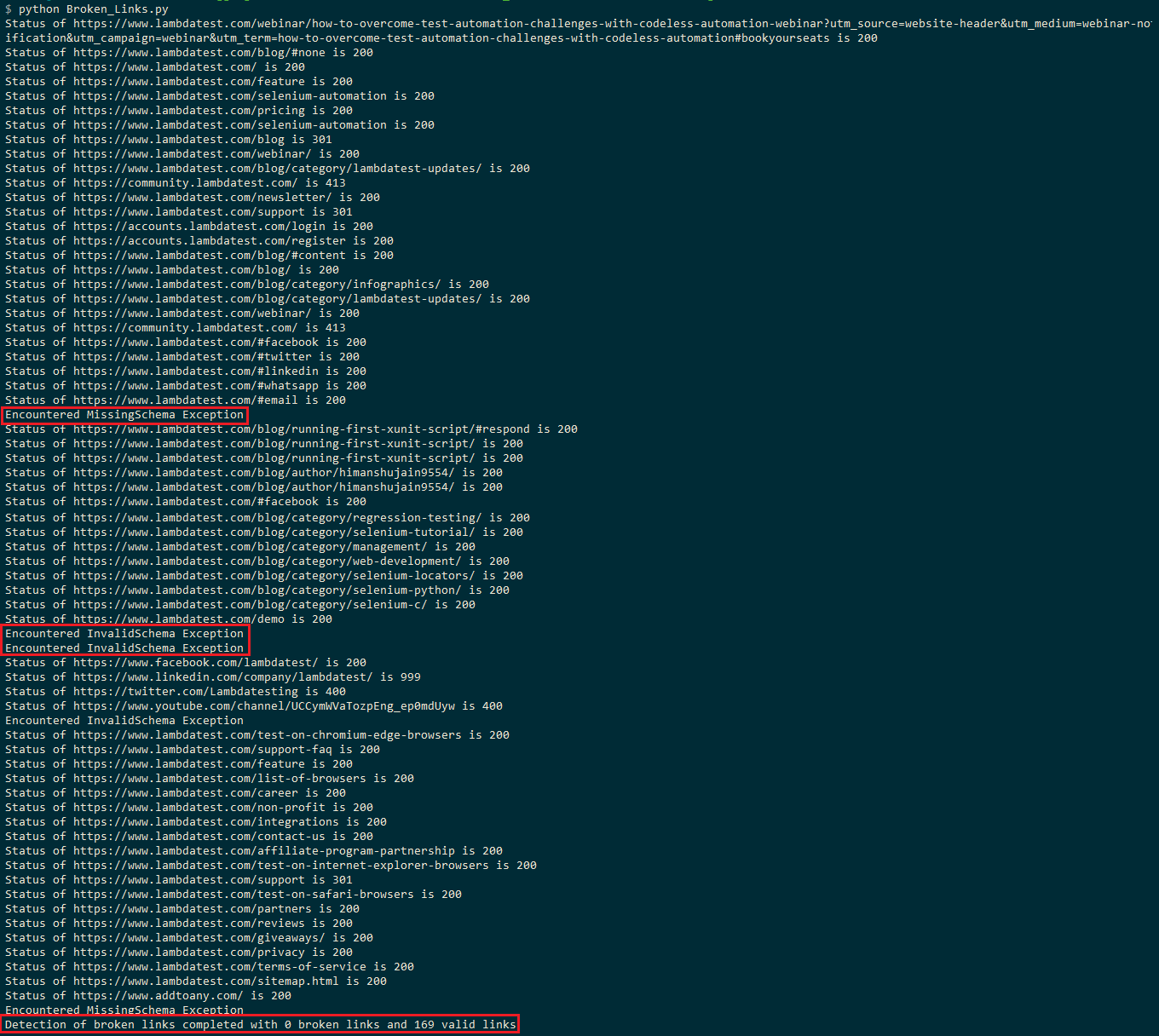
cererea principală către LinkedIn (adică) are ca rezultat un cod de stare HTTP de 999. După cum se menționează în acest thread pe StackOverflow, LinkedIn filtrează Cererile bazate pe user-agent, iar cererea a dus la ‘Acces refuzat’ (adică 999 ca cod de stare HTTP).

am verificat dacă link-ul LinkedIn prezent pe pagina blogului LambdaTest este rupt sau nu prin rularea aceluiași test pe grila locală Selenium, care a dus la HTTP/1.1 200 OK.
testarea link-ul rupt folosind seleniu C #
punerea în aplicare
Cod WalkThrough
cadrul NUnit este utilizat pentru testarea de automatizare; blogul nostru anterior despre automatizarea testelor NUnit cu Selenium C # vă poate ajuta să începeți cu cadrul.
1. Includeți HttpClient
spațiul de nume HttpClient este adăugat pentru utilizare prin directiva de utilizare. Clasa HttpClient din C# oferă o clasă de bază pentru trimiterea cererilor HTTP și primirea răspunsului HTTP de la o resursă identificată de URI.
Microsoft recomandă utilizarea System.Net.Http.HttpClient în loc de System.Net.HttpWebRequest; HttpWebRequest ar putea fi, de asemenea, utilizat pentru a detecta legăturile rupte în Selenium C#.
|
1
2
|
utilizarea System. Net. Http;
utilizarea sistemului.Filetare.SARCINI;
|
2. Definiți o metodă asincronă care returnează o activitate
o metodă de testare asincronă este definită ca folosind metoda GetAsync care trimite o solicitare GET către URI-ul specificat ca o operație asincronă.
|
1
2
|
sarcina asincronă publică LT_Broken_Links_Test()
{
|
3. Colectați linkurile prezente pe pagina
în primul rând, creăm o instanță a HttpClient.
|
1
|
folosind var client = nou HttpClient();
|
link-urile prezente pe URL-ul testat (de exemplu, LambdaTest Blog) sunt colectate prin localizarea elementelor web de TagName „a” Proprietate.
|
1
|
link-uri var = conducător auto.FindElements(De.TagName („a”));
|
metoda find_elements din Selenium este utilizată pentru localizarea legăturilor din pagină, deoarece returnează o matrice (sau o listă) care poate fi iterată pentru a verifica lucrabilitatea legăturilor.
4. Itera prin URL-urile pentru validare
linkurile localizate folosind metoda find_elements sunt verificate într-o buclă for.
|
1
2
|
foreach (var link în link-uri)
{
|
filtrăm linkurile care conțin/adrese de e-mail/numere de telefon / adrese LinkedIn. Linkurile fără text de legătură sunt, de asemenea, filtrate.
|
1
2
|
dacă (!(legătură.Text.Conține („E-mail”) | | link.Text.Conține („https://www.linkedin.com”) | | legătură.Text = = „” / / legătură.Egal (null)))
{
|
metoda GetAsync a clasei HttpClient trimite o cerere GET către URI-ul corespunzător ca o operație asincronă. Argumentul metodei GetAsync este valoarea atributului ‘href’ al ancorei colectate folosind metoda GetAttribute.
evaluarea metodei asincrone este suspendată de operatorul de așteptare până la finalizarea operației asincrone. La finalizarea operației asincrone, operatorul așteaptă returnează HttpResponseMessage care include datele și Codul de stare.
|
1
2
3
|
/* Obțineți URI * /
HttpResponseMessage response = așteptați clientul.GetAsync(legătură.GetAttribute („href”));
sistem.Consola.WriteLine ($”URL: {link.GetAttribute („href”)} starea este :{răspuns.Codul de stare}”);
|
5. Validați legăturile prin codul de stare
dacă codul de răspuns HTTP (adică răspuns.StatusCode) pentru cererea HTTP trimis în etapa(4) este HttpStatusCode.OK (adică 200), înseamnă că cererea a fost finalizată cu succes.
|
1
2
3
4
5
6
7
8
9
|
sistem.Console.WriteLine($”URL: {link.GetAttribute(„href”)} status is :{response.StatusCode}”);
if (response.StatusCode == HttpStatusCode.OK)
{
valid_links++;
}
else
{
broken_links++;
}
|
NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
|
1
2
3
4
5
6
7
8
|
catch (Exception ex)
{
if ((ex is ArgumentNullException) ||
(ex is NotSupportedException))
{
System.Console.WriteLine(„Exception occured\n”);
}
}
|
execuție
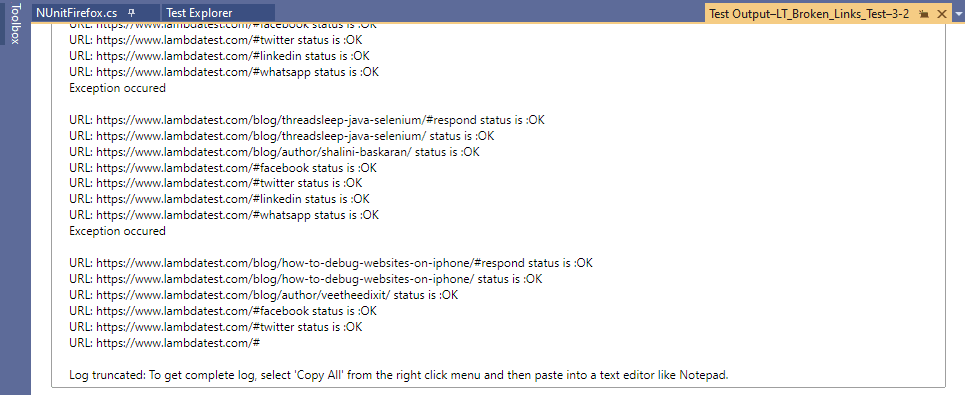
iată instantaneul de execuție, care arată că testul a fost executat cu succes.

excepții au apărut pentru link-uri către ‘icoane share,’ adică, WhatsApp, Facebook, Twitter, etc. În afară de aceste linkuri, restul linkurilor de pe pagina blogului LambdaTest returnează HttpStatusCode.OK (adică 200).
testarea link-ul rupt folosind seleniu PHP
punerea în aplicare
Cod WalkThrough
1. Citiți sursa paginii
funcția file_get_contents din PHP este utilizată pentru citirea sursei HTML a paginii într-o variabilă șir (de exemplu, $html).
|
1
2
|
$test_devine = „https://www.lambdatest.com/blog/”;
$html = file_get_contents ($test_url);
|
2. Instantiați clasa DOMDocument
clasa DOMDocument din PHP reprezintă un întreg document HTML și servește ca rădăcină a arborelui documentului.
|
1
|
$htmlDom = DOMDocument nou;
|
3. Analiza HTML a paginii
funcția DOMDocument::loadHTML() este utilizată pentru analizarea sursei HTML care este conținută în $html. La executarea cu succes, funcția returnează un obiect DOMDocument.
|
1
|
@$htmlDom – >loadHTML ($html);
|
4. Extrageți linkurile din pagina
linkurile prezente pe pagină sunt extrase folosind metoda getElementsByTagName din clasa DOMDocument. Elementele (sau linkurile) sunt căutate pe baza etichetei ‘a’ din sursa HTML analizată.
funcția getElementsByTagName returnează o nouă instanță de DOMNodeList care conține elementele (sau link-uri) de nume tag-ul local (adică. etichetă)
|
1
|
$link – uri = $ htmlDom- > getElementsByTagName (‘a’);
|
5. Itera prin URL-urile de validare
DOMNodeList, care a fost creat în etapa (4), este traversat pentru verificarea valabilității link-uri.
|
1
2
3
|
foreach ($link-uri ca $ link)
{
$linkText = $link – > nodeValue;
|
detaliile legăturii corespunzătoare sunt obținute folosind atributul href. Metoda GetAttribute este utilizată pentru aceeași.
|
1
|
$linkHref = $link- > getAttribute (‘href’);
|
săriți verificarea legăturilor dacă:
a. linkul este gol
|
1
2
3
4
|
dacă (strlen (trim ($linkHref)) == 0)
{
continuă;
}
|
b. Link-ul este un hashtag sau un link de ancorare
|
1
2
3
4
|
dacă ($linkHref == ‘#’)
{
continuă;
}
|
c. linkul conține mailto sau addtoany (adică Opțiuni de partajare socială).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
function check_nonlinks($test_url, $test_pattern)
{
dacă (preg_match ($test_pattern, $test_url) = = fals)
{
întoarce-te fals;
}
else
{
return true;
}
}
funcția publică test_Broken_Links()
{
$pattern_1 = ‘ / \baddtoany \ b/’;
$pattern_2 = ‘ / \ bmailto \ b/’;
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
dacă ((check_nonlinks($linkHref, $pattern_1)) / /(check_nonlinks ($linkHref, $pattern_2)))
{
print („\nAdd_To_Any sau e-mail întâlnite”);
continuare;
}
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
}
|
funcția preg_match utilizează o expresie regulată (regex) pentru efectuarea unei căutări insensibile la majuscule și minuscule pentru mailto și addtoany. Expresiile regulate pentru mailto & addtoany sunt ‘/\bmailto\b/’ & ‘/\baddtoany\B/’ respectiv.
6. Validați codul HTTP folosind cURL
folosim curl pentru a obține informații cu privire la starea legăturii corespunzătoare. Primul pas este inițializarea unei sesiuni de cURL cu ‘link’ pe care trebuie făcută validarea. Metoda returnează o instanță cURL care va fi utilizată în ultima parte a implementării.
|
1
|
$curl = curl_init ($linkHref);
|
metoda curl_setopt este utilizată pentru setarea opțiunilor pe mânerul de sesiune cURL dat (adică $curl).
|
1
|
curl_setopt ($curl, CURLOPT_NOBODY, adevărat) ;
|
metoda curl_exec este solicitată pentru executarea sesiunii cURL date. Returnează True la executarea cu succes.
|
1
|
$rezultat = curl_exec ($curl);
|
aceasta este cea mai importantă parte a logicii care verifică legăturile rupte de pe pagină. Funcția curl_getinfo care preia mânerul sesiunii cURL (adică $curl) și CURLINFO_RESPONSE_CODE (adică. CURLINFO_HTTP_CODE) sunt utilizate pentru a obține informații despre ultimul transfer. Returnează codul de stare HTTP ca răspuns.
|
1
|
$statusCode = curl_getinfo ($curl, CURLINFO_HTTP_CODE);
|
la finalizarea cu succes a cererii, codul de stare HTTP de 200 este returnat, iar variabila care deține numărul de legături valide (adică $valid_links) este incrementată. Pentru link-urile care au ca rezultat codul de stare HTTP de 400 (sau mai mult), se efectuează o verificare dacă link-ul testat a fost LambdaTest, pagina LinkedIn. Așa cum am menționat mai devreme, Codul De stare al paginii LinkedIn va fi 999; prin urmare, $valid_links este incrementat.
pentru toate celelalte linkuri care au returnat codul de stare HTTP de 400 (sau mai mult), variabila care deține numărul de legături rupte (adică $broken_links) este incrementată.
|
1
2
3
4
5
6
7
8
9
10
|
dacă (($linkedin_page_status) & &($statusCode == 999))
{
print („\nLink”. $ linkHref . „este pagina LinkedIn și starea este”.$statusCode);
$ validlinks++;
}
else
{
print („\nLink”. $ linkHref . „este legătura ruptă și starea este”.$statusCode);
$ brokenlinks++;
}
|
execuție
folosim cadrul PHPUnit pentru testarea legăturilor rupte din pagină. Pentru a descărca cadrul PHPUnit, adăugați compozitorul de fișiere.json în folderul rădăcină și a alerga compozitor necesită pe terminal.
rulați următoarea comandă pe terminal pentru a verifica legăturile rupte în Selenium PHP.
|
1
|
furnizor\Coș\teste phpunit\BrokenLinksTest.php
|
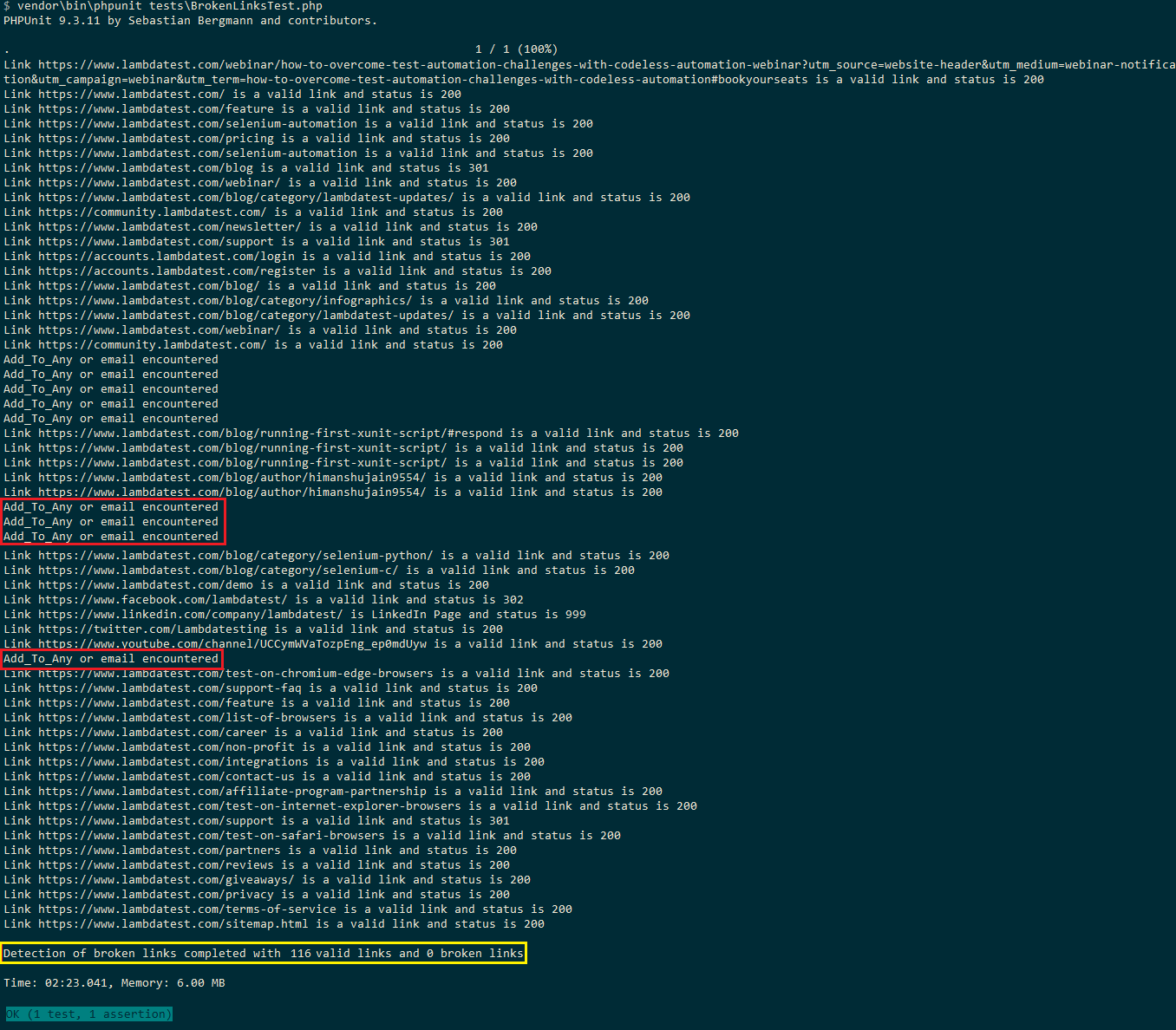
Iată instantaneul de execuție care arată un total de 116 link-uri valide și 0 link-uri rupte pe blogul LambdaTest. Deoarece linkurile pentru partajarea socială (adică addtoany) și adresa de e-mail sunt ignorate, numărul total este de 116 (169 în testul Selenium Python).
concluzie

linkurile rupte, numite și link-uri moarte sau link-uri rot, pot împiedica experiența utilizatorului dacă sunt prezente pe site. Link-urile rupte pot afecta, de asemenea, clasamentul pe motoarele de căutare. Prin urmare, testarea link-ului rupt ar trebui efectuată periodic pentru activități legate de dezvoltarea și testarea site-ului web.
în loc să se bazeze pe instrumente terțe sau metode manuale pentru verificarea legăturilor rupte pe un site web, testarea legăturilor rupte se poate face folosind Selenium WebDriver cu Java, Python, C# sau PHP. Codul de stare HTTP, returnat la accesarea oricărei pagini web, trebuie utilizat pentru a verifica legăturile rupte folosind cadrul Selenium.
Întrebări frecvente
cum pot găsi link-uri rupte în seleniu Python?
pentru verificarea legăturilor rupte, va trebui să colectați toate linkurile din pagina web pe baza etichetei. Apoi trimiteți o solicitare HTTP pentru linkuri și citiți codul de răspuns HTTP. Aflați dacă linkul este valid sau rupt pe baza codului de răspuns HTTP.
Cum verific legăturile rupte?
pentru a monitoriza continuu site-ul dvs. pentru link-uri rupte folosind Google Search Console, urmați acești pași:
- Conectați-vă la Contul Google Search Console.
- Faceți clic pe site-ul pe care doriți să îl monitorizați.
- Faceți clic pe Accesare Cu Crawlere, apoi faceți clic pe preluare ca Google.
- după ce Google accesează cu crawlere site-ul, pentru a accesa rezultatele, faceți clic pe Crawl, apoi faceți clic pe Crawl erori.
- sub erori URL, puteți vedea orice link-uri rupte pe care Google le-a descoperit în timpul procesului de accesare cu crawlere.
Cum pot găsi imagini rupte pe web folosind seleniu?
vizitați pagina. Itera prin fiecare imagine în arhiva HTTP și a vedea dacă are un cod de stare 404. Stoca fiecare imagine rupt într-o colecție. Verificați dacă colecția de imagini rupte este goală.
Cum obțin toate legăturile din seleniu?
puteți obține toate linkurile prezente pe o pagină web pe baza etichetei < a> prezente. Fiecare etichetă<a > reprezintă o legătură. Utilizați localizatoarele de seleniu pentru a găsi cu ușurință toate aceste etichete.
de ce sunt rău legăturile rupte?
pot afecta experiența utilizatorului – atunci când utilizatorii fac clic pe link-uri și ajung la erori 404, se frustrează și nu se mai pot întoarce niciodată. Acestea devalorizează eforturile dvs. de SEO – legăturile rupte restricționează fluxul de echitate a linkurilor pe site-ul dvs., afectând negativ clasamentul.

Himanshu Sheth
Himanshu Sheth este un tehnolog experimentat și blogger cu peste 15 ani de experiență de lucru diversă. În prezent lucrează ca ‘evanghelist Dezvoltator principal’ și ‘Senior Manager’ la LambdaTest. El este foarte activ cu comunitatea de pornire din Bengaluru (și în sud) și iubește interacțiunea cu fondatorii pasionați pe blogul său personal (pe care îl menține de la ultimii 15 ani).