




Como verificar se há conteúdo duplicado
como encontrar conteúdo duplicado
o conteúdo duplicado deve ser minimizado em um site, pois pode dificultar que os mecanismos de pesquisa decidam qual versão classificar para uma consulta.
embora uma ‘penalidade de conteúdo duplicado’ seja um mito em SEO, conteúdo muito semelhante pode causar ineficiências de rastreamento, diluir o PageRank e ser um sinal de conteúdo que pode ser consolidado, removido ou melhorado.
vale lembrar que conteúdo duplicado e semelhante é uma parte natural da web, o que muitas vezes não é um problema para os mecanismos de pesquisa que, por design, canonizam URLs e os filtram quando apropriado. No entanto, em escala pode ser mais problemático.
a prevenção de conteúdo duplicado coloca você no controle sobre o que é indexado e classificado – em vez de deixá-lo para os mecanismos de pesquisa. Você pode limitar o desperdício de orçamento de rastreamento e consolidar sinais de indexação e link para ajudar na classificação.
este tutorial mostra como você pode usar o Screaming Frog SEO Spider para encontrar o conteúdo duplicado exato e o conteúdo quase duplicado, onde algum texto corresponde entre as páginas de um site.
o conteúdo duplicado identificado por qualquer ferramenta, incluindo o SEO Spider, precisa ser revisado no contexto. Assista ao nosso vídeo ou continue lendo nosso guia abaixo.
para começar, baixe o SEO Spider, que é gratuito para rastrear até 500 URLs. As duas primeiras etapas estão disponíveis apenas com uma licença. Se você é um usuário gratuito, pule para o número 3 no Guia.
1) habilite ‘quase duplicatas’ Via ‘Config > conteúdo > duplicatas’
por padrão, o SEO Spider identificará automaticamente páginas duplicadas exatas. No entanto, para identificar ‘quase Duplicatas’, a configuração deve estar ativada, o que permite armazenar o conteúdo de cada página.
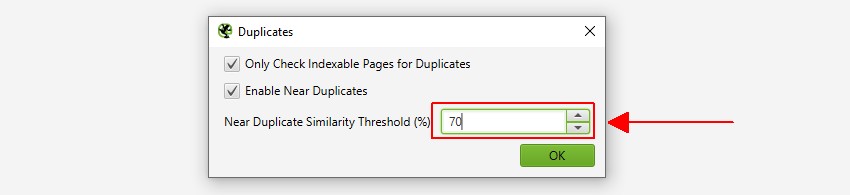
o SEO Spider identificará quase duplicatas com uma correspondência de similaridade de 90%, que pode ser ajustada para encontrar conteúdo com um limite de similaridade menor.
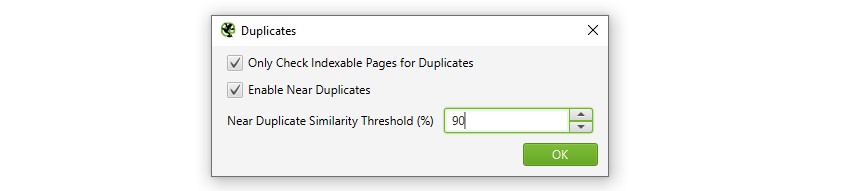
o SEO Spider também verificará apenas páginas ‘indexáveis’ para duplicatas (para duplicatas exatas e quase duplicadas). Isso significa que se você tiver dois URLs iguais, mas um for canonicalizado para o outro (e, portanto, ‘não indexável’), isso não será relatado-a menos que essa opção esteja desativada.
se você estiver interessado em encontrar problemas de orçamento de rastreamento, desmarque a opção ‘Verificar apenas páginas indexáveis para duplicatas’, pois isso pode ajudar a encontrar áreas de resíduos de rastreamento em potencial.
2) Ajuste ‘área de conteúdo’ para análise Via ‘Config > conteúdo > área’
você pode configurar o conteúdo usado para análise quase duplicada. Para um novo rastreamento, recomendamos usar a configuração padrão e refiná-la mais tarde, quando o conteúdo usado na análise puder ser visto e considerado.
o SEO Spider excluirá automaticamente os elementos nav e footer para se concentrar no conteúdo principal do corpo. No entanto, nem todo site é construído usando esses elementos HTML5, para que você possa refinar a área de conteúdo usada para a análise, se necessário. Você pode optar por’ incluir ‘ou’ excluir ‘ tags HTML, classes e IDs na análise.
por exemplo, o site Screaming Frog tem um menu móvel fora do elemento nav, que está incluído na análise de conteúdo por padrão. Embora isso não seja um grande problema, neste caso, para ajudar a se concentrar no texto principal do corpo da Página, seu nome de classe ‘menu móvel__dropdown’ pode ser inserido na caixa ‘Excluir Classes’.
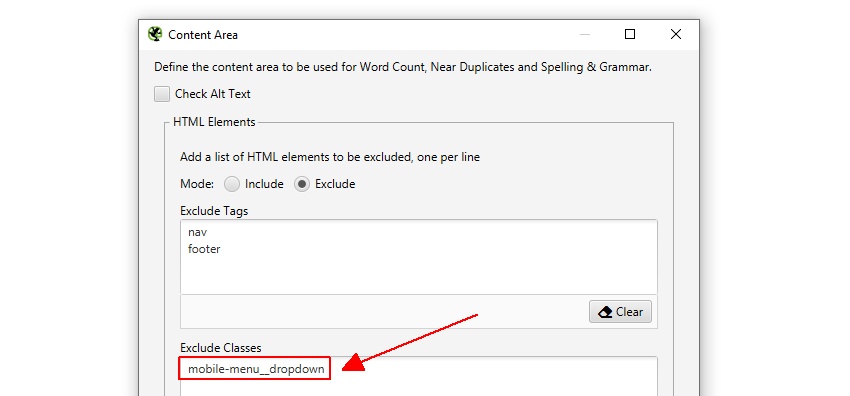
isso excluirá que o menu seja incluído no algoritmo de análise de conteúdo duplicado. Mais sobre isso mais tarde.
3) rastreie o site
abra a aranha SEO, digite ou copie no site que deseja rastrear na caixa ‘inserir URL para aranha’ e clique em ‘Iniciar’.
aguarde até que o rastreamento termine e chegue a 100%, mas você também pode visualizar alguns detalhes em tempo real.
4) visualize duplicatas na guia’ Conteúdo ‘
a guia Conteúdo tem 2 filtros relacionados a conteúdo duplicado,’ duplicatas exatas ‘e’quase duplicatas’.
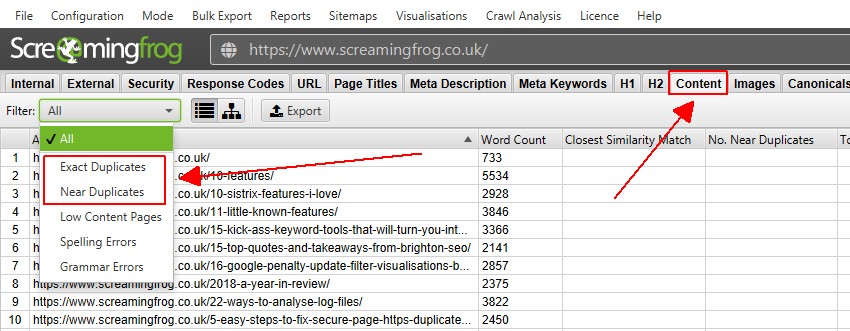
apenas ‘duplicatas exatas’ estão disponíveis para visualização em tempo real durante um rastreamento. ‘Quase duplicatas’ requerem cálculo no final do rastreamento por meio de ‘Análise de rastreamento’ pós para que ele seja preenchido com dados.
o painel ‘Visão geral’ do lado direito exibe uma mensagem’ (Análise de rastreamento necessária) ‘ contra filtros que exigem que a análise pós-rastreamento seja preenchida com dados.
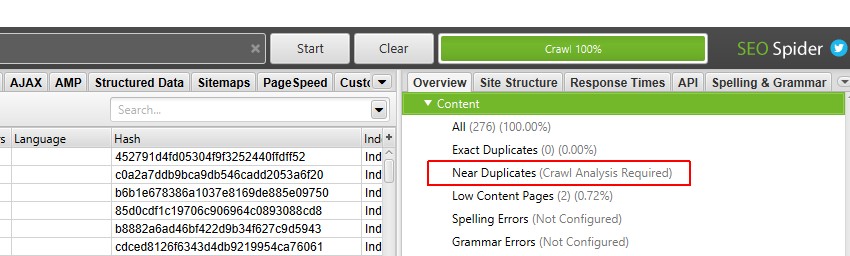
5) Clique em ‘Crawl Analysis > Start ‘to Populate’ Near Duplicates ‘Filter
To popul the’ Near Duplicates ‘filter, the’ Closest similar Match ‘ and ‘ No. Perto das colunas de duplicatas, você só precisa clicar em um botão no final do rastreamento.

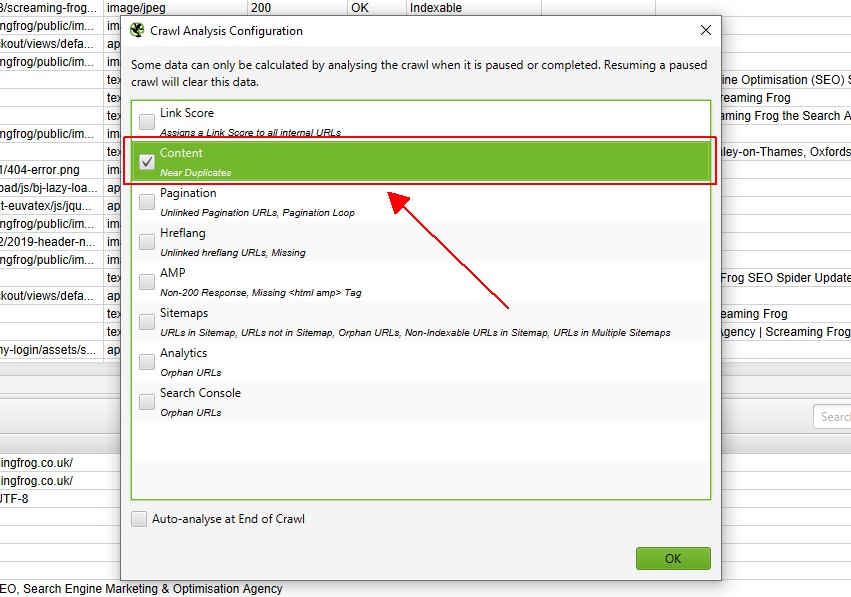
no entanto, se você configurou ‘Análise de rastreamento’ anteriormente, você pode querer verificar novamente, em ‘Análise de rastreamento > Configurar’ que ‘perto de duplicatas’ está marcado.
Você também pode desmarcar outros itens que também exigem análise pós-rastreamento para tornar esta etapa mais rápida.
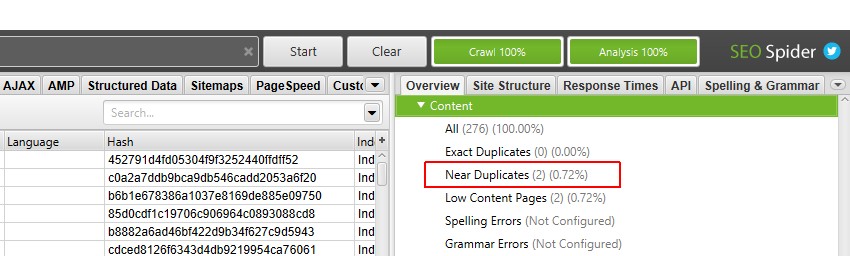
quando a análise de rastreamento tiver concluído, a barra de progresso de’ análise ‘estará em 100% e os filtros não terão mais a mensagem’ (Análise de rastreamento necessária)’.
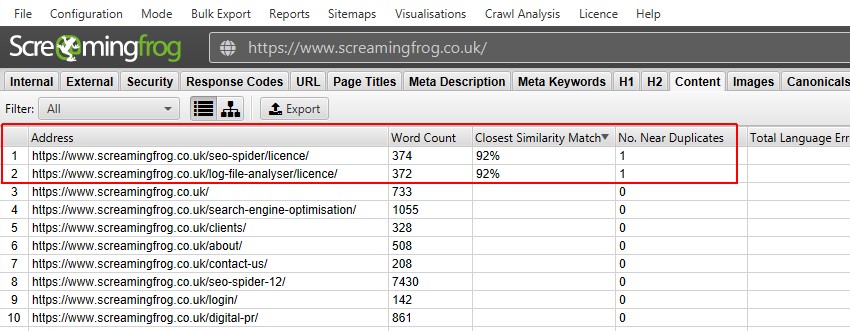
Agora você pode visualizar o filtro e as colunas quase duplicadas preenchidas.
6) exibir a guia ‘Conteúdo’ & ‘exato’ & ‘próximo’ duplica filtros
depois de realizar a análise pós-rastreamento, o filtro ‘perto de Duplicatas’, a ‘correspondência de similaridade mais próxima’ e ‘não. As colunas próximas a duplicatas serão preenchidas. Somente URLs com Conteúdo acima do limite de similaridade selecionado conterão dados, os outros permanecerão em branco. Neste caso, o site Screaming Frog tem apenas dois.
um rastreamento de um site maior, como a BBC, revelará muito mais.
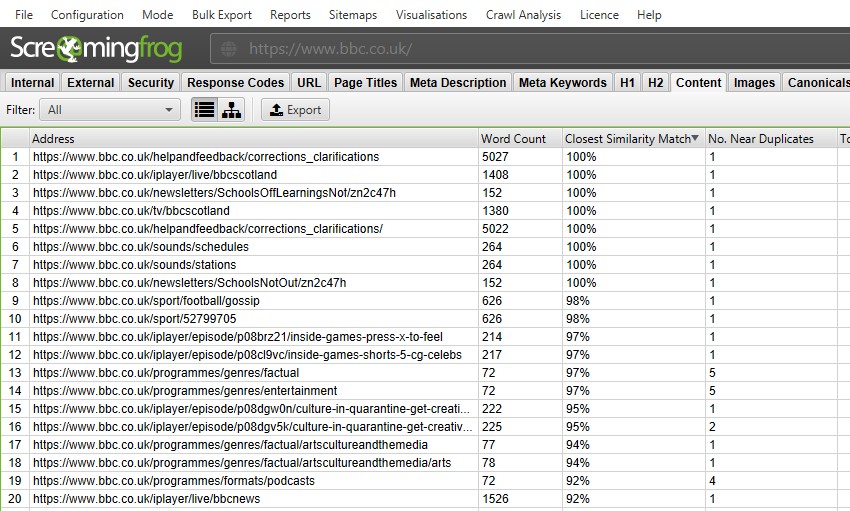
Você é capaz de filtrar o seguinte–
- Duplicatas Exatas – Este filtro mostrará páginas que são idênticos uns aos outros usando o algoritmo MD5, que calcula um ‘hash’ valor para cada página e pode ser visto no ‘hash’ coluna. Essa verificação é realizada em relação ao HTML completo da página. Ele mostrará todas as páginas com valores hash correspondentes que são exatamente os mesmos. Páginas duplicadas exatas podem levar à divisão de sinais PageRank e imprevisibilidade no ranking. Deve haver apenas uma única versão canônica de um URL que existe e está vinculada internamente. Outras versões não devem ser vinculadas e devem ser 301 redirecionadas para a versão canônica.
- perto de duplicatas – este filtro mostrará Páginas semelhantes com base no limite de similaridade configurado usando o algoritmo minhash. O limite pode ser ajustado em ‘Config > Spider > Content’ e é definido em 90% por padrão. A coluna ‘correspondência de similaridade mais próxima’ exibe a maior porcentagem de similaridade com outra página. O ‘ Não. A coluna Near Duplicates exibe o número de páginas que são semelhantes à página com base no limite de similaridade. O algoritmo é executado contra texto na página, em vez do HTML completo, como duplicatas exatas. O conteúdo usado para esta análise pode ser configurado em ‘Config > Content > Area’. As páginas podem ter uma similaridade de 100%, mas apenas ser uma duplicata quase duplicada, em vez de uma duplicata exata. Isso ocorre porque duplicatas exatas são excluídas como quase duplicatas, para evitar que sejam sinalizadas duas vezes. As pontuações de similaridade também são arredondadas, portanto, 99,5% ou mais serão exibidas como 100%.
as páginas duplicadas próximas devem ser revisadas manualmente, pois há muitas razões legítimas para algumas páginas serem muito semelhantes em conteúdo, como variações de produtos que têm volume de pesquisa em torno de seu atributo específico.
no entanto, os URLs sinalizados como quase duplicados devem ser revisados para considerar se devem existir como páginas separadas devido ao seu valor exclusivo para o usuário ou se devem ser removidos, consolidados ou aprimorados para tornar o conteúdo mais detalhado e exclusivo.
7) visualize URLs duplicadas por meio da guia ‘Detalhes duplicados’
para ‘duplicatas exatas’, é mais fácil visualizá – las na janela superior usando o filtro-pois elas são agrupadas e compartilham o mesmo valor ‘hash’.
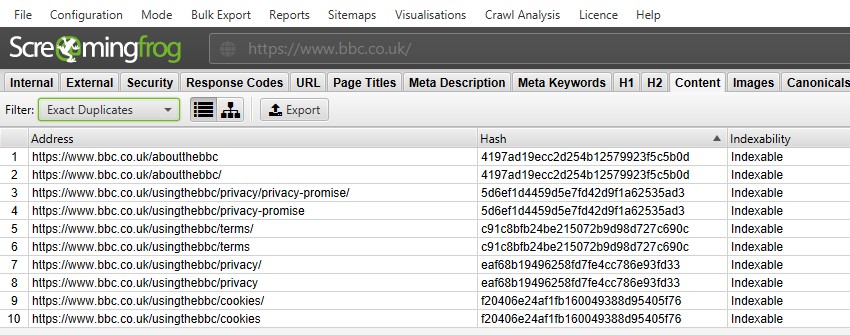
na captura de tela acima, cada URL tem uma duplicata exata correspondente devido a uma barra à direita e versão de barra Não à direita.
para ‘quase duplicatas’, clique na guia ‘Detalhes duplicados’ na parte inferior, que preenche o painel inferior da janela com o ‘endereço quase duplicado’ e semelhança de cada URL quase duplicado descoberto.
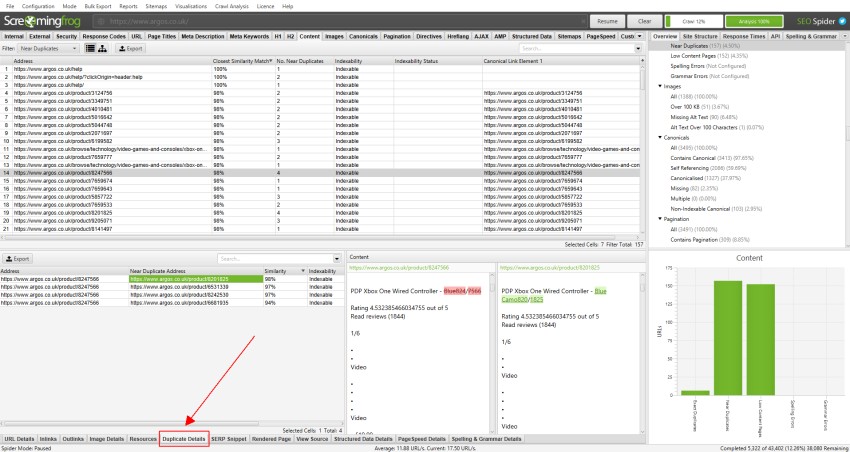
por exemplo, se houver 4 quase duplicatas descobertas para um URL na janela superior, todas elas podem ser visualizadas.
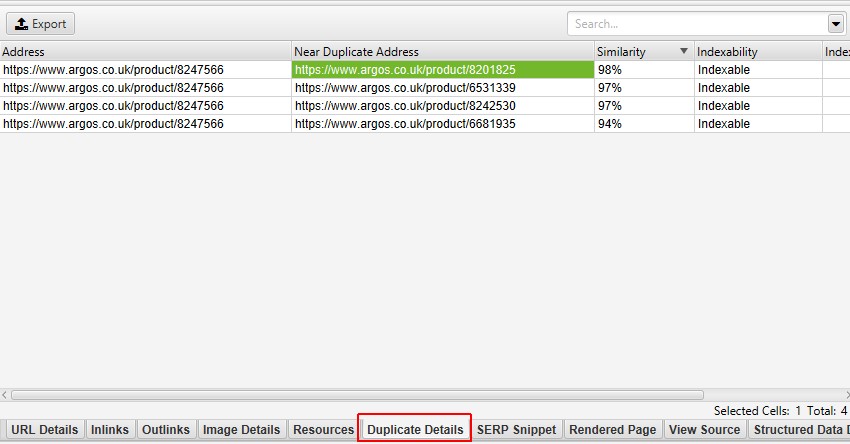
o lado direito da guia’ Detalhes duplicados ‘exibirá o conteúdo quase duplicado descoberto nas páginas e destacará as diferenças entre as páginas quando você clicar em cada’endereço quase duplicado’.
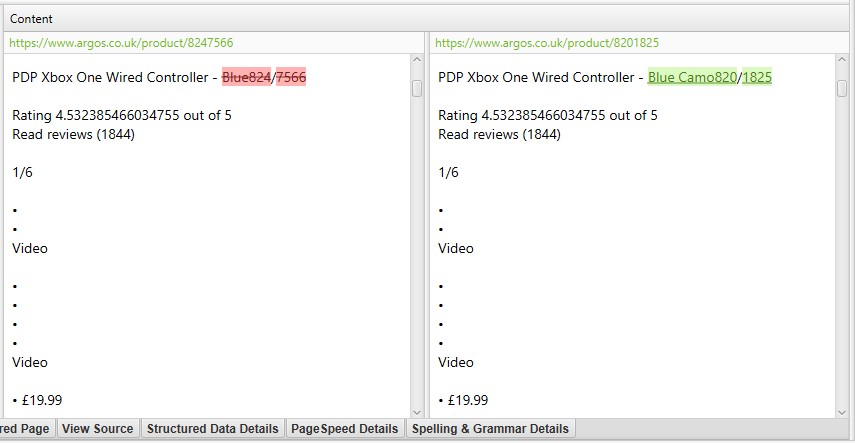
se houver algum conteúdo duplicado na guia Detalhes duplicados que você não deseja fazer parte da análise de conteúdo duplicado, excluir ou incluir elementos HTML, classes ou IDs (conforme destacado no ponto 2), & Executar novamente a análise de rastreamento.
8) duplicatas de exportação em massa
as duplicatas exatas e próximas podem ser exportadas em massa por meio das exportações’ exportação em massa > conteúdo > duplicatas exatas ‘e’ quase duplicatas’.

Dica Final! Refine o limite de similaridade & área de conteúdo, & re-executar análise de rastreamento
pós-rastreamento você é capaz de ajustar o limite de similaridade quase duplicada e a área de conteúdo usada para análise quase duplicada.
você pode então re-executar a análise de rastreamento novamente para encontrar conteúdo mais ou menos semelhante – sem re-rastrear o site.
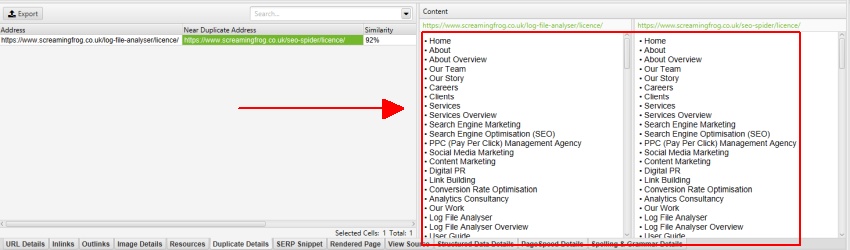
conforme descrito anteriormente, o site Screaming Frog possui um menu móvel fora do elemento nav, que é incluído na análise de conteúdo por padrão. O menu móvel pode ser visto na visualização de conteúdo da guia ‘Detalhes duplicados’.
excluindo o ‘menu móvel_ _ dropdown’ na caixa ‘Excluir Classes’ em ‘Config > Content > Area’, o menu móvel é removido da visualização do conteúdo e da análise quase duplicada.
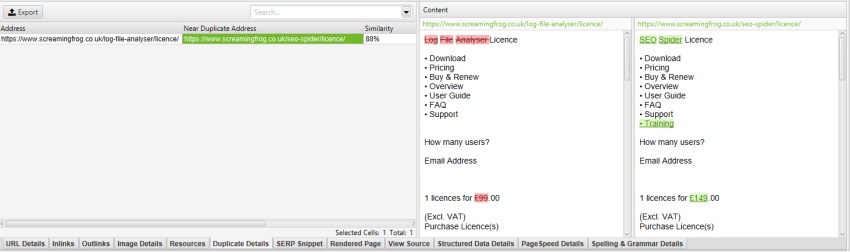
isso pode realmente ajudar ao ajustar a identificação de conteúdo quase duplicado para áreas de conteúdo principal, sem a necessidade de re-rastreamento.
resumo
o guia acima deve ilustrar como usar o SEO Spider como um verificador de conteúdo duplicado para o seu site. Para obter os resultados mais precisos, refine a área de conteúdo para análise e ajuste o limite para diferentes grupos de páginas.
leia também nossas FAQs Screaming Frog SEO Spider e guia completo do Usuário para obter mais informações sobre a ferramenta.
se você tiver mais dúvidas, comentários ou sugestões para melhorar a ferramenta de conteúdo duplicado no SEO Spider, basta entrar em contato por meio do suporte.