




Jak Znaleźć Niedziałające Linki Za Pomocą Selenium WebDriver?
jakie myśli przychodzą na myśl, gdy natkniesz się na 404/Page Not Found / Dead Hyperlinks on a website? Aargh! Byłoby to denerwujące, gdy natkniesz się na uszkodzone hiperłącza, co jest jedynym powodem, dla którego powinieneś stale koncentrować się na usuwaniu niedziałających linków w swoim produkcie internetowym (lub stronie internetowej). Zamiast ręcznej kontroli, możesz wykorzystać automatyzację do testowania uszkodzonych łączy za pomocą Selenium WebDriver.

gdy konkretny link jest uszkodzony, a odwiedzający ląduje na stronie, wpływa to na funkcjonalność tej strony i powoduje słabe wrażenia użytkownika. Martwe linki mogą zaszkodzić wiarygodności Twojego produktu, ponieważ „mogą” sprawiać wrażenie, że odwiedzający w minimalnym stopniu koncentrują się na doświadczeniu.
jeśli twój produkt internetowy ma wiele stron (lub linków), które powodują błąd 404 (lub nie znaleziono strony), pozycja produktów w wyszukiwarkach (np. Usuwanie martwych linków jest jedną z integralnych części działań SEO (Search Engine Optimization).
w tej części serii samouczków Selenium WebDriver zagłębiamy się w znajdowanie niedziałających linków za pomocą Selenium WebDriver. Zademonstrowaliśmy testowanie uszkodzonych łączy przy użyciu Selenium Python, Selenium Java, Selenium C# i Selenium PHP.
Wprowadzenie do uszkodzonych linków w testach internetowych
Mówiąc najprościej, uszkodzone linki (lub martwe linki) w witrynie (lub aplikacji internetowej) są linkami, które nie są dostępne i nie działają zgodnie z przewidywaniami. Łącza mogą być tymczasowo niedostępne z powodu problemów z serwerem lub nieprawidłowo skonfigurowane na zapleczu.
oprócz stron, które powodują błąd 404, inne widoczne przykłady uszkodzonych linków to zniekształcone adresy URL, linki do treści (np.), które zostały przeniesione lub usunięte.
główne przyczyny niedziałających linków
oto niektóre z typowych przyczyn występowania niedziałających linków (martwe linki lub gnije link):
- nieprawidłowy lub błędny adres URL wprowadzony przez użytkownika.
- zmiany strukturalne w witrynie (tj. linki bezpośrednie) z przekierowaniami URL lub przekierowaniami wewnętrznymi nie są prawidłowo skonfigurowane.
- linki do treści takich jak filmy, dokumenty itp. które są przenoszone lub usuwane. Jeśli treść zostanie przeniesiona, „linki wewnętrzne” powinny zostać przekierowane do wyznaczonych linków.
- Tymczasowy przestój witryny spowodowany utrzymaniem witryny, co tymczasowo uniemożliwia dostęp do witryny.
- uszkodzone znaczniki HTML, błędy JavaScript, nieprawidłowe dostosowania HTML / CSS, uszkodzone elementy osadzone itp., w obrębie strony wiodącej, może prowadzić do niedziałających linków.
- ograniczenia geolokalizacyjne uniemożliwiają dostęp do witryny z określonych adresów IP (jeśli znajdują się na czarnej liście) lub określonych krajów na świecie. Testy geolokalizacyjne z użyciem Selenium pomagają zapewnić, że doświadczenie jest dostosowane do lokalizacji (lub kraju), z którego uzyskuje się dostęp do witryny.
dlaczego warto sprawdzać Niedziałające linki?
Niedziałające linki są dużym Wyłącznikiem dla odwiedzających, którzy lądują na twojej stronie. Oto niektóre z głównych powodów, dla których powinieneś sprawdzić niedziałające linki na swojej stronie:
- uszkodzone linki mogą zaszkodzić użytkownikowi.
- usuwanie uszkodzonych (lub martwych) linków jest niezbędne dla SEO (Search Engine Optimization), ponieważ może wpływać na pozycję witryny w wyszukiwarkach (np.
testowanie uszkodzonych linków można wykonać za pomocą Selenium WebDriver na stronie internetowej, który z kolei może być użyty do usunięcia martwych linków witryny.
Niedziałające linki i kody statusu HTTP
gdy użytkownik odwiedza witrynę, żądanie jest wysyłane przez przeglądarkę do serwera witryny. Serwer odpowiada na żądanie przeglądarki za pomocą trzycyfrowego kodu zwanego ” kodem stanu HTTP.”
kod statusu HTTP jest odpowiedzią serwera na żądanie wysłane z przeglądarki internetowej. Te kody statusu HTTP są uważane za równoważne rozmowie między przeglądarką (z której wysyłane jest żądanie adresu URL) a serwerem.
chociaż różne kody statusu HTTP są używane do różnych celów, większość kodów jest przydatna do diagnozowania problemów w witrynie, minimalizowania przestojów witryny, liczby martwych linków i innych. Pierwsza cyfra każdego trzycyfrowego kodu statusu zaczyna się od cyfr 1~5. Kody statusu są reprezentowane jako 1xx, 2xx.., 5xx za Wskazanie kodów stanu w danym zakresie. Ponieważ każdy z tych zakresów składa się z innej klasy odpowiedzi serwera, ograniczylibyśmy dyskusję do kodów statusu HTTP prezentowanych dla niedziałających łączy.
oto typowe klasy kodu stanu, które są przydatne w wykrywaniu niedziałających linków z Selenium:
| klasy kodu statusu HTTP | opis |
|---|---|
| 1xx | serwer nadal myśli o żądaniu. |
| 2xx | żądanie wysłane przez przeglądarkę zostało pomyślnie zakończone, a oczekiwana odpowiedź została wysłana do przeglądarki przez serwer. |
| 3xx | oznacza to, że jest wykonywane przekierowanie. Na przykład przekierowanie 301 jest popularnie używane do wdrażania stałych przekierowań na stronie internetowej. |
| 4xx | oznacza to, że konkretna strona (lub cała strona) nie jest osiągalna. |
| 5xx | oznacza to, że serwer nie był w stanie wykonać żądania, mimo że przeglądarka wysłała prawidłowe żądanie. |
kody statusu HTTP prezentowane po wykryciu niedziałających linków
oto niektóre z typowych kodów statusu HTTP prezentowanych przez serwer WWW po napotkaniu niedziałającego łącza:
| kod statusu HTTP | opis |
|---|---|
| 400 (Bad Request) | serwer nie jest w stanie przetworzyć żądania, ponieważ wspomniany URL jest nieprawidłowy. |
| 400 (Bad Request – Bad Host) | oznacza to, że nazwa hosta jest nieprawidłowa, przez co żądanie nie może zostać przetworzone. |
| 400 (Bad Request – zły adres URL) | oznacza to, że serwer nie może przetworzyć żądania, ponieważ wprowadzony adres URL jest nieprawidłowo sformatowany (tzn. brakujące nawiasy, ukośniki itp.). |
| 400 (Bad Request – Timeout) | oznacza to, że żądania HTTP zostały przekroczone. |
| 400 (Bad Request – Empty) | odpowiedź zwracana przez serwer jest pusta bez zawartości i bez kodu odpowiedzi. |
| 400 (Bad Request – Reset) | oznacza to, że serwer nie jest w stanie przetworzyć żądania, ponieważ jest zajęty przetwarzaniem innych żądań lub został źle skonfigurowany przez właściciela witryny. |
| 403 (zabronione) | prawdziwe żądanie jest wysyłane do serwera, ale odmawia spełnienia tego samego, ponieważ wymagana jest autoryzacja. |
| 404 (Nie znaleziono strony) | Zasób (lub strona) nie jest dostępna na serwerze. |
| 408 (Request Time Out) | serwer ma czas oczekiwania na żądanie. Klient (tj. przeglądarka) może wysłać to samo żądanie w czasie, na jaki serwer jest przygotowany. |
| 410 (Gone) | kod statusu HTTP, który jest bardziej trwały niż 404 (Strona nie została znaleziona). 410 oznacza, że strona zniknęła. strona nie jest dostępna na serwerze, ani nie został skonfigurowany żaden mechanizm przekierowania (lub przekierowania). Linki wskazujące na stronę 410 wysyłają odwiedzających do martwego zasobu. |
| 503 (Usługa niedostępna) | oznacza to, że serwer jest tymczasowo przeciążony, przez co nie może przetworzyć żądania. Może to również oznaczać, że konserwacja jest wykonywana na serwerze, wskazując wyszukiwarkom tymczasowy czas przestoju witryny. |
jak znaleźć uszkodzone linki za pomocą Selenium WebDriver?
niezależnie od języka używanego w Selenium WebDriver, Przewodnie zasady testowania uszkodzonych łączy przy użyciu Selenium pozostają takie same. Oto kroki testowania uszkodzonych linków przy użyciu Selenium WebDriver:
- użyj tagu, aby zebrać szczegóły wszystkich linków obecnych na stronie internetowej.
- Wyślij żądanie HTTP dla każdego linku.
- Sprawdź odpowiedni kod odpowiedzi otrzymany w odpowiedzi na żądanie wysłane w poprzednim kroku.
- sprawdź, czy łącze jest uszkodzone, czy nie, na podstawie kodu odpowiedzi wysłanego przez serwer.
- powtórz kroki (2-4) dla każdego linku znajdującego się na stronie.
w tym samouczku Selenium WebDriver zademonstrujemy, jak wykonać testowanie uszkodzonych łączy przy użyciu Selenium WebDriver w Pythonie, Javie, C# i PHP. Testy są przeprowadzane na kombinacji (Chrome 85.0 + Windows 10), a ich wykonanie odbywa się na opartej na chmurze siatce Selenium dostarczanej przez LambdaTest.
aby rozpocząć korzystanie z LambdaTest, Utwórz konto na platformie i zanotuj nazwę użytkownika & klucz dostępu dostępny w sekcji Profil na LambdaTest. Możliwości przeglądarki są generowane za pomocą generatora możliwości LambdaTest.
oto scenariusz testowy używany do znajdowania uszkodzonych linków na stronie internetowej za pomocą Selenium:
scenariusz testowy
- przejdź do bloga LambdaTest, tj. https://www.lambdatest.com/blog/ na Chrome 85.0
- Zbierz wszystkie linki obecne na stronie
- Wyślij zapytanie HTTP dla każdego linku
- Drukuj, czy Link jest uszkodzony, czy nie na terminalu
ważne jest, aby pamiętać, że czas spędzony na testowaniu uszkodzonych linków przy użyciu Selenium zależy od liczby linków obecnych na testowanej stronie.”Im więcej linków na stronie, tym więcej czasu poświęcimy na znalezienie niedziałających linków. Na przykład LambdaTest ma ogromną liczbę linków (~150+); dlatego proces znajdowania uszkodzonych linków może zająć trochę czasu (około kilku minut).

uruchom skrypt testowy na SELENIUM GRID
ponad 2000 przeglądarek i systemów operacyjnych
DARMOWA REJESTRACJA
testowanie uszkodzonych linków przy użyciu Selenium Java
implementacja
przeglądanie kodu
1. Import wymaganych pakietów
metody w pakiecie HttpURLConnection służą do wysyłania żądań HTTP i przechwytywania kodu statusu HTTP (lub odpowiedzi).
metody w wyrażeniu regularnym.Pakiet Pattern sprawdź, czy odpowiedni link zawiera adres e – mail lub numer telefonu, używając specjalnej składni utrzymanej we wzorze.
|
1
2
|
Importuj java. net. HttpURLConnection;
Importuj Javę.util.regex.Wzór;
|
2. Zbierz linki obecne na stronie
linki obecne na testowanym URL (tj. blogu LambdaTest) znajdują się za pomocą tagname w Selenium. Nazwa znacznika używana do identyfikacji elementu (lub łącza) to „a”.
linki są umieszczane na liście do iteracji na liście, aby sprawdzić niedziałające linki na stronie.
|
1
|
List< WebElement> links = driver.findElements (By.tagName („a”));
|
3. Iterate poprzez adresy URL
obiekt Iterator służy do zapętlania listy utworzonej w Kroku (2)
|
1
|
Iterator< WebElement> link = linki.iterator();
|
4. Zidentyfikuj i zweryfikuj adresy URL
pętla while jest wykonywana do czasu, gdy Iterator (tj. link) nie ma więcej elementów do iteracji. Pobierany jest’ href ’ znacznika anchor, który jest zapisywany w zmiennej URL.
|
1
2
3
|
while (link.hasNext())
{
url = link.next().getAttribute („href”);
|
Pomiń sprawdzanie linków, jeśli:
a. Link jest null lub pusty
|
1
2
3
4
5
|
if ((url == null) / / (url.isEmpty()))
{
System.Wynocha.println („URL nie jest skonfigurowany dla znacznika kotwicy lub jest pusty”);
Kontynuuj;
}
|
B. Link zawiera mailto lub numer telefonu
|
1
2
3
4
5
|
if ((url.startsWith (mail_to)) / / (url.startsWith (tel)))
{
System.Wynocha.println („adres e-mail lub telefon wykryty”);
Kontynuuj;
}
|
podczas sprawdzania strony LinkedIn kod statusu HTTP to 999. Zmienna logiczna (tzn., LinkedIn) jest ustawiony na true, aby wskazać, że nie jest to uszkodzony link.
|
1
2
3
4
5
|
if (url.startsWith(LinkedInPage))
{
System.Wynocha.println („URL zaczyna się od LinkedIn, oczekiwany kod statusu to 999”);
bLinkedIn = true,;
}
|
5. Walidacja łączy za pomocą kodu statusu
metody w klasie HttpURLConnection zapewniają przepis do wysyłania żądań HTTP i przechwytywania kodu statusu HTTP.
metoda openConnection klasy URL otwiera połączenie z podanym adresem URL. Zwraca instancję URLConnection reprezentującą połączenie ze zdalnym obiektem, do którego odnosi się adres URL. Jest to typ-rzucony na HttpURLConnection.
|
1
2
3
4
5
6
7
|
HttpURLConnection urlconnection = null;
……………………………………….
……………………………………….
……………………………………….
urlconnection = (HttpURLConnection) (nowy URL (url).openConnection());
urlconnection.setRequestMethod („Głowa”);
|
setRequestMethod w klasie HttpURLConnection ustawia metodę żądania URL. Typ żądania jest ustawiony na HEAD tak, że zwracane są tylko nagłówki. Z drugiej strony, żądanie typu GET zwróciłoby treść dokumentu, co nie jest wymagane w tym konkretnym scenariuszu testowym.
metoda connect w klasie HttpURLConnection ustanawia połączenie z adresem URL i wysyła żądanie HTTP.
|
1
|
urlconnection.połącz();
|
metoda getResponseCode zwraca kod statusu HTTP dla wcześniej wysłanego żądania.
|
1
|
responseCode = urlconnection.getResponseCode();
|
dla kodu statusu HTTP wynosi 400 (lub więcej), zmienna zawierająca liczbę uszkodzonych linków (np. broken_links) jest zwiększana; w przeciwnym razie zmienna zawierająca poprawne linki (np. valid_links) jest zwiększana.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
if (responseCode >= 400)
{
if ((bLinkedIn == true) && (responseCode = = LinkedInStatus))
{
System.Wynocha.println (url + „jest stroną LinkedIn i nie jest uszkodzonym linkiem”);
valid_links++;
}
else
{
System.Wynocha.println (url + „jest uszkodzony link”);
broken_links++;
}
}
else
{
System.Wynocha.println (url + „jest poprawnym linkiem”);
valid_links++;
}
|
wykonanie
do testowania uszkodzonych linków przy użyciu Selenium Java, stworzyliśmy projekt w IntelliJ IDEA. Podstawowy pom.plik xml był wystarczający do tego zadania!
oto migawka wykonania, która wskazuje 169 poprawnych linków i 0 uszkodzonych linków na stronie bloga LambdaTest.
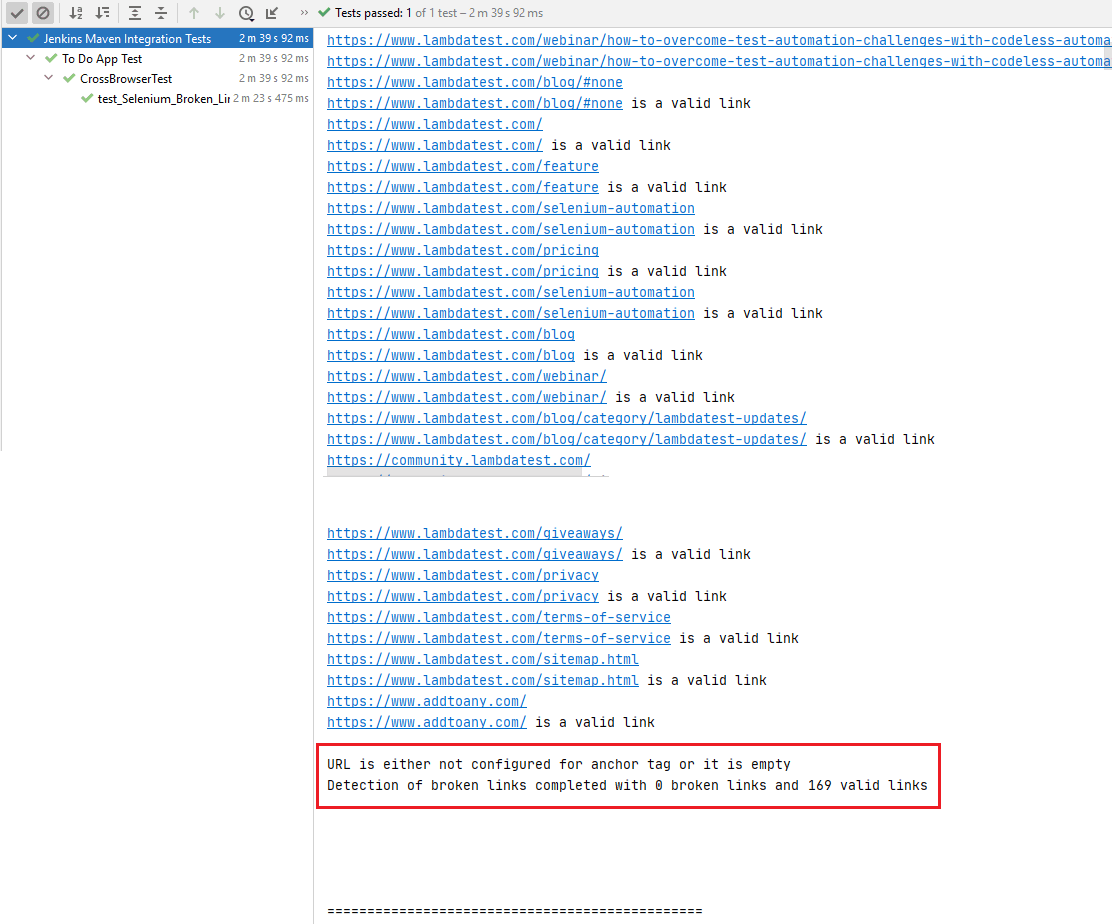
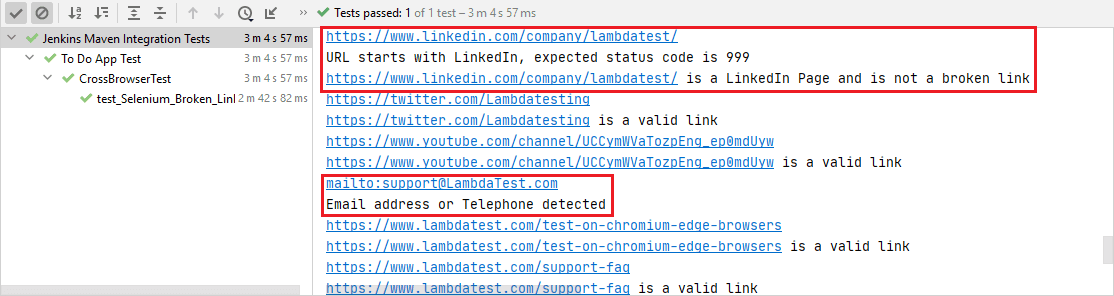
linki zawierające adresy e-mail i numery telefonów zostały wyłączone z listy wyszukiwania, Jak pokazano poniżej.
możesz zobaczyć, że test jest uruchamiany na poniższym zrzucie ekranu i kończy się w ciągu 2 min 35 sekund, jak pokazano w dziennikach automatyzacji LambdaTest.

testowanie uszkodzonych linków przy użyciu Selenium Python
implementacja
Przejście kodu
1. Import modułów
oprócz importowania modułów Pythona dla Selenium WebDriver, importujemy również moduł requests. Moduł requests umożliwia wysyłanie wszelkiego rodzaju żądań HTTP. Może być również używany do przekazywania parametrów w adresie URL, wysyłania niestandardowych nagłówków i innych.
|
1
2
3
|
Importuj żądania
Importuj urllib3
z żądań.wyjątki import MissingSchema, InvalidSchema, InvalidURL
|
2. Zbieraj linki obecne na stronie
linki obecne na testowanym adresie URL (np. blogu LambdaTest) znajdują się poprzez zlokalizowanie elementów sieci Web za pomocą właściwości CSS Selector „a”.
|
1
|
links = driver.find_elements (Autor:CSS_SELECTOR, „a”)
|
ponieważ chcemy, aby element był iteracyjny, używamy metody find_elements (a nie metody find_element).
3. Iteracja poprzez adresy URL w celu walidacji
metoda head modułu requests jest używana do wysłania żądania HEAD do podanego adresu URL. Metoda get_attribute jest używana na każdym dowiązaniu do uzyskania atrybutu’ href ’ znacznika kotwicy.
metoda head jest używana głównie w scenariuszach, w których wymagane są tylko nagłówki status_code lub HTTP, a zawartość pliku (lub URL) nie jest potrzebna. Metoda head zwraca żądania.Obiekt Response, który zawiera również kod statusu HTTP (tzn. żądanie.status_code).
|
1
2
3
4
|
dla linku w linkach:
spróbuj:
request = requests.Głowa (link.get_attribute (’href’), data = {’key’:’value’})
print („Status” + link.get_attribute (’href’) + ” is ” + str (request.status_code))
|
ten sam zestaw operacji jest wykonywany iteracyjnie do wyczerpania wszystkich „linków” obecnych na stronie.
4. Zweryfikuj łącza za pomocą kodu stanu
jeśli kod odpowiedzi HTTP dla żądania HTTP wysłanego w kroku (3) wynosi 404 (tj. strona nie została znaleziona), oznacza to, że łącze jest uszkodzonym łączem. Dla linków, które nie są uszkodzone, kod statusu HTTP to 200.
|
1
2
3
4
|
if (request.status_code == 404):
broken_links = (broken_links + 1)
else:
valid_links = (valid_links + 1)
|
5. Pomija nieistotne żądania
, gdy są stosowane do łączy, które nie zawierają atrybutu 'href’ (np. mailto, telefon, itp.), metoda głowy powoduje wyjątek (np. MissingSchema, InvalidSchema).
|
1
2
3
4
5
6
|
except requests.exceptions.MissingSchema:
print(„Encountered MissingSchema Exception”)
except requests.exceptions.InvalidSchema:
print(„Encountered InvalidSchema Exception”)
except:
print („napotkał jakieś inne execuption”)
|
te wyjątki są przechwytywane i to samo jest drukowane na terminalu.
wykonanie
użyliśmy tutaj PyUnit (lub unittest), domyślnego frameworka testowego w Pythonie do testowania uszkodzonych linków przy użyciu Selenium. Uruchom następujące polecenie na terminalu:
|
1
|
python Broken_Links.py
|
wykonanie zajmie około 2-3 minut, ponieważ strona bloga LambdaTest składa się z około 150+ linków. Poniższy zrzut ekranu pokazuje, że strona ma poprawne linki 169 i zero uszkodzonych linków.
w niektórych miejscach będziesz świadkiem wyjątku InvalidSchema lub MissingSchema, co oznacza, że te linki są pomijane z oceny.
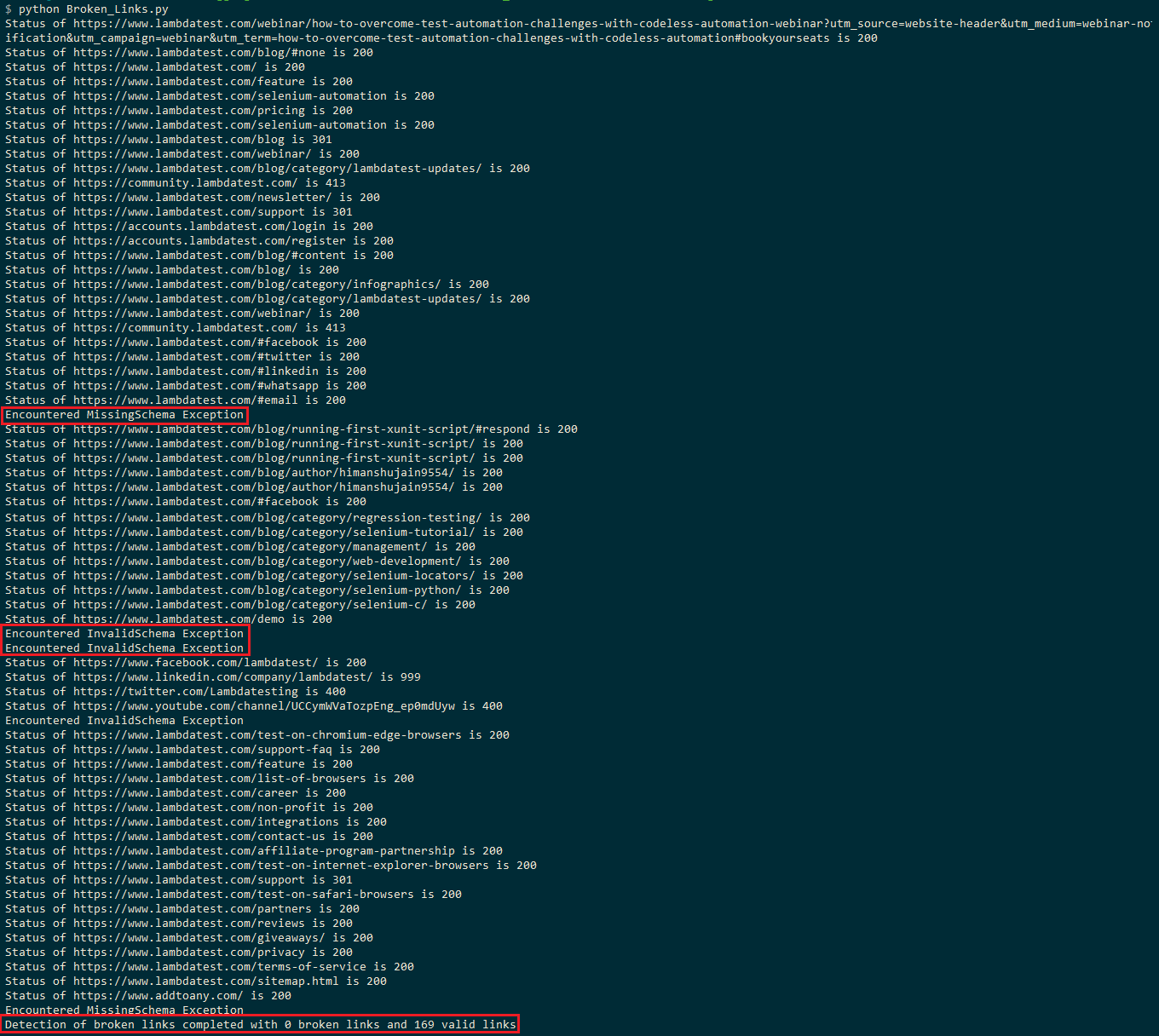
żądanie HEAD do LinkedIn (tj. Jak wspomniano w tym wątku na StackOverflow, LinkedIn filtruje żądania w oparciu o User-agent, A żądanie spowodowało „odmowę dostępu” (tj. 999 jako kod statusu HTTP).

sprawdziliśmy, czy link LinkedIn obecny na stronie bloga LambdaTest jest zepsuty, czy nie, uruchamiając ten sam test na lokalnej siatce Selenium, co zaowocowało HTTP/1.1 200 OK.
testowanie uszkodzonych linków przy użyciu Selenium C #
implementacja
Przejście kodu
framework NUnit służy do testowania automatyzacji; nasz wcześniejszy blog o automatyzacji testów NUnit z Selenium C# może pomóc ci rozpocząć pracę z frameworkiem.
1. Include HttpClient
Przestrzeń nazw HttpClient jest dodawana do użycia za pomocą dyrektywy using. Klasa HttpClient w C# zapewnia klasę bazową do wysyłania żądań HTTP i odbierania odpowiedzi HTTP z zasobu identyfikowanego przez URI.
Microsoft zaleca używanie System. Net. Http. HttpClient zamiast System. Net. HttpWebRequest; HttpWebRequest może być również używany do wykrywania niedziałających linków w Selenium c#.
|
1
2
|
korzystanie z systemu. Net. Http;
korzystanie z systemu.Gwintowanie.Zadania;
|
2. Definiowanie metody asynchronicznej, która zwraca zadanie
metoda testowa asynchroniczna jest zdefiniowana jako przy użyciu metody GetAsync, która wysyła żądanie GET do podanego URI jako operacja asynchroniczna.
|
1
2
|
publiczne zadanie asynchroniczne LT_Broken_Links_Test()
{
|
3. Zbierz linki obecne na stronie
najpierw tworzymy instancję HttpClient.
|
1
|
używanie var client = new HttpClient();
|
linki znajdujące się na testowanym adresie URL (tj. blogu LambdaTest) są zbierane poprzez lokalizację elementów internetowych za pomocą właściwości tagname „a”.
|
1
|
var links = driver.FindElements (By.TagName („a”));
|
metoda find_elements w Selenium jest używana do lokalizowania linków na stronie, ponieważ zwraca tablicę (lub listę), którą można iterować, aby zweryfikować funkcjonalność linków.
4. Iteracja poprzez adresy URL do walidacji
linki znajdujące się przy użyciu metody find_elements są weryfikowane w pętli for.
|
1
2
|
foreach (var link in links)
{
|
filtrujemy linki, które zawierają / adresy e-mail/numery telefonów / adresy LinkedIn. Linki bez tekstu linku są również filtrowane.
|
1
2
|
jeśli (!(link.SMS.Contains („Email”) | | link.SMS.Contains („https://www.linkedin.com”) / / link.Tekst = „” / link.Equals (null)))
{
|
metoda GetAsync klasy HttpClient wysyła żądanie GET do odpowiedniego URI jako operację asynchroniczną. Argumentem metody GetAsync jest wartość atrybutu 'href’ kotwicy zebrana przy użyciu metody GetAttribute.
ocena metody asynchronicznej jest zawieszona przez operatora oczekującego do czasu zakończenia operacji asynchronicznej. Po zakończeniu operacji asynchronicznej Operator oczekujący zwraca HttpResponseMessage, który zawiera dane i kod stanu.
|
1
2
3
|
/* Pobierz URI * /
httpresponsemessage response = oczekuj klienta . GetAsync (link.GetAttribute („href”));
System.Konsola.WriteLine ($”URL: {link.GetAttribute („href”)} status to: {response.StatusCode}”);
|
5. Zweryfikuj łącza za pomocą kodu stanu
, jeśli kod odpowiedzi HTTP(tj. odpowiedź.StatusCode) dla żądania HTTP wysłanego w kroku(4) jest HttpStatusCode.OK (tj. 200), to znaczy, że żądanie zostało zakończone pomyślnie.
|
1
2
3
4
5
6
7
8
9
|
System.Console.WriteLine($”URL: {link.GetAttribute(„href”)} status is :{response.StatusCode}”);
if (response.StatusCode == HttpStatusCode.OK)
{
valid_links++;
}
else
{
broken_links++;
}
|
NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
|
1
2
3
4
5
6
7
8
|
catch (Exception ex)
{
if ((ex is ArgumentNullException) ||
(ex is NotSupportedException))
{
System.Console.WriteLine(„Exception occured\n”);
}
}
|
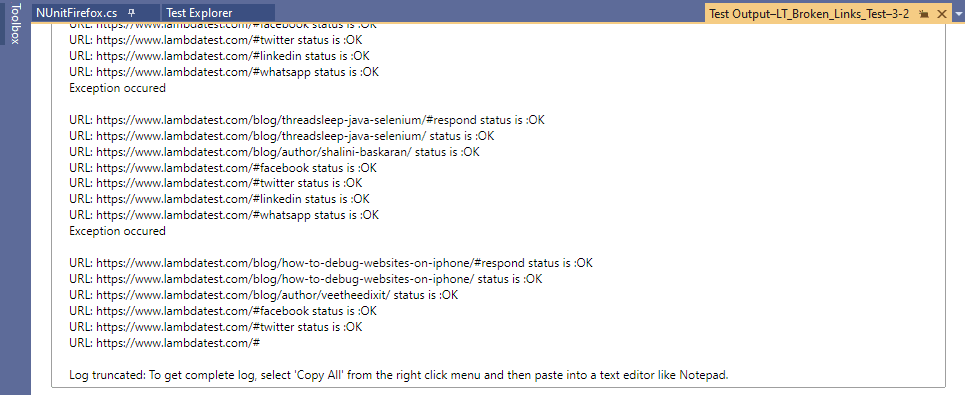
wykonanie
oto migawka wykonania, która pokazuje, że test został pomyślnie wykonany.

wyjątki wystąpiły dla linków do „Udostępnij ikony”, tj. Facebook, Twitter itp. Oprócz tych linków, reszta linków na stronie bloga LambdaTest zwraca HttpStatusCode.OK (tj. 200).
testowanie uszkodzonego łącza przy użyciu Selenium PHP
implementacja
Przejście kodu
1. Odczyt źródła strony
funkcja file_get_contents w PHP służy do odczytu źródła HTML strony do zmiennej łańcuchowej (np. $html).
|
1
2
|
$test_url = „https://www.lambdatest.com/blog/”;
$html = file_get_contents ($test_url);
|
2. Tworzy instancję klasy DOMDocument
Klasa DOMDocument w PHP reprezentuje cały dokument HTML i służy jako korzeń drzewa dokumentów.
|
1
|
$htmlDom = new DOMDocument;
|
3. Parse HTML strony
funkcja DOMDocument::loadHTML() służy do parsowania źródła HTML zawartego w $html. Po pomyślnym wykonaniu funkcja zwraca obiekt DOMDocument.
|
1
|
@$htmlDom – > loadHTML ($html);
|
4. Wyodrębnij linki ze strony
linki obecne na stronie są wyodrębniane przy użyciu metody getElementsByTagName klasy DOMDocument. Elementy (lub linki) są przeszukiwane na podstawie znacznika ” a ” z analizowanego źródła HTML.
funkcja getElementsByTagName zwraca nową instancję DOMNodeList, która zawiera elementy (lub linki) lokalnej nazwy znacznika (tzn. / tag)
|
1
|
$links = $htmlDom – > getElementsByTagName (’a’);
|
5. Iteracja adresów URL w celu walidacji
lista DOMNodeList, która została utworzona w kroku (4), jest przeglądana w celu sprawdzenia ważności linków.
|
1
2
3
|
foreach ($links as $link)
{
$linkText = $link – >nodeValue;
|
szczegóły odpowiedniego linku uzyskuje się za pomocą atrybutu „href”. Do tego samego celu służy metoda GetAttribute.
|
1
|
$linkHref = $link – > getAttribute (’href’);
|
Pomiń sprawdzanie linków, jeśli:
a. link jest pusty
|
1
2
3
4
|
if (strlen (trim ($linkHref)) == 0)
{
Kontynuuj;
}
|
B. Link jest hashtagiem lub linkiem kotwicznym
|
1
2
3
4
|
if ($linkHref == '#’)
{
Kontynuuj;
}
|
C. link zawiera mailto lub addtoany (tj. opcje udostępniania społecznościowego).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
function check_nonlinks($test_url, $test_pattern)
{
if (preg_match ($test_pattern, $test_url) = = false)
{
return false;
}
else
{
return true;
}
}
Public function test_Broken_Links()
{
$pattern_1 = ’ / \baddtoany\b/’;
$pattern_2 = ’ / \bmailto\B/’;
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
if ((check_nonlinks($linkHref, $pattern_1))||(check_nonlinks ($linkHref, $pattern_2)))
{
print („\nAdd_To_Any lub email”);
continue;
}
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
}
|
funkcja preg_match używa wyrażenia regularnego (regex) do wyszukiwania bez rozróżniania wielkości liter dla mailto i addtoany. Wyrażenia regularne dla mailto & addtoany to odpowiednio '/\bmailto\B /’ & '/\baddtoany \ b/’.
6. Zweryfikuj Kod HTTP za pomocą cURL
używamy curl, aby uzyskać informacje dotyczące statusu odpowiedniego łącza. Pierwszym krokiem jest zainicjowanie sesji cURL za pomocą 'linku’, na której należy wykonać walidację. Metoda zwraca instancję cURL, która będzie używana w drugiej części implementacji.
|
1
|
$curl = curl_init ($linkHref);
|
metoda curl_setopt służy do ustawiania opcji na danym uchwycie sesji cURL (np. $curl).
|
1
|
curl_setopt ($curl, CURLOPT_NOBODY, true);
|
metoda curl_exec jest wywoływana do wykonania danej sesji cURL. Zwraca True przy pomyślnym wykonaniu.
|
1
|
$result = curl_exec ($curl);
|
jest to najważniejsza część logiki, która sprawdza, czy nie ma uszkodzonych linków na stronie. Funkcja curl_getinfo, która pobiera uchwyt sesji cURL (np. $curl) i CURLINFO_RESPONSE_CODE (np. CURLINFO_HTTP_CODE) służą do uzyskania informacji o ostatnim transferze. W odpowiedzi zwraca kod statusu HTTP.
|
1
|
$statusCode = curl_getinfo ($curl, CURLINFO_HTTP_CODE);
|
po pomyślnym zakończeniu żądania zwracany jest kod statusu HTTP o wartości 200,a zmienna posiadająca prawidłową liczbę linków (np. $valid_links) jest zwiększana. W przypadku linków, które skutkują kodem statusu HTTP 400 (lub więcej), sprawdzane jest, czy „link testowany” był stroną LambdaTest, LinkedIn. Jak wspomniano wcześniej, kod statusu strony LinkedIn będzie wynosił 999; w związku z tym $valid_links jest zwiększany.
dla wszystkich innych linków, które zwróciły kod statusu HTTP 400 (lub więcej), zmienna zawierająca liczbę uszkodzonych linków (np. $broken_links) jest zwiększana.
|
1
2
3
4
5
6
7
8
9
10
|
if (($linkedin_page_status) && ($statusCode == 999))
{
print („\nLink”. $linkHref . is LinkedIn Page and status is (ang.).$statusCode);
$validlinks++;
}
else
{
print („\nLink”. $linkHref . „is broken link and status is”.$statusCode);
$brokenlinks++;
}
|
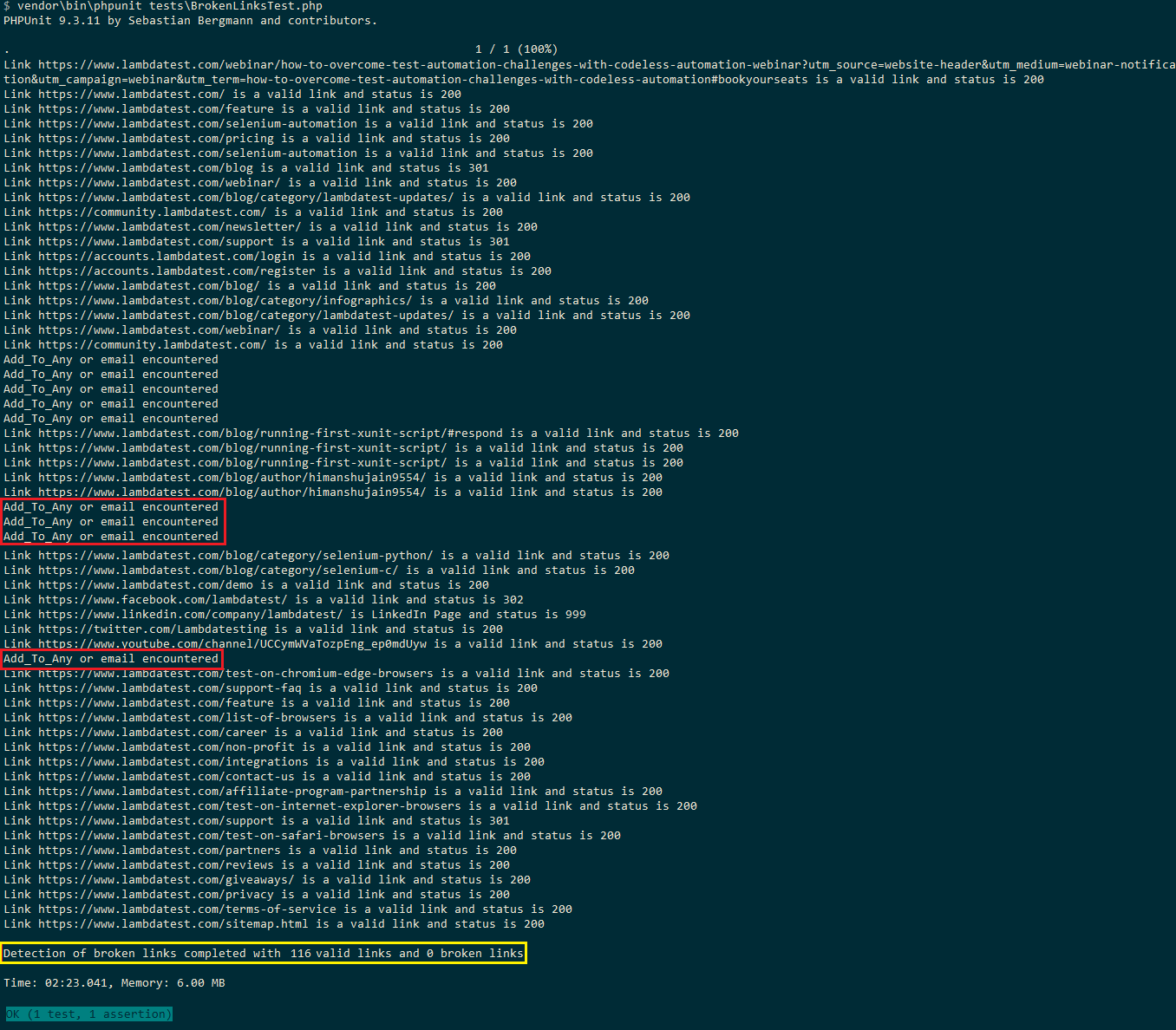
wykonanie
używamy frameworka PHPUnit do testowania niedziałających linków na stronie. Aby pobrać framework PHPUnit, dodaj kompozytor plików.JSON w folderze głównym i uruchom composer wymagają na terminalu.
uruchom następujące polecenie na terminalu, aby sprawdzić niedziałające linki w Selenium PHP.
|
1
|
vendor \ bin \ phpunit tests\BrokenLinksTest.php
|
oto migawka wykonania, która pokazuje w sumie 116 poprawnych linków i 0 uszkodzonych linków na blogu LambdaTest. Ponieważ linki do udostępniania społecznościowego (tj. addtoany) i adres e-mail są ignorowane, całkowita liczba wynosi 116 (169 W teście Selenium Python).
wniosek

uszkodzone linki, zwane również martwymi linkami lub rot linkami, mogą utrudniać korzystanie z witryny, jeśli są obecne na stronie. Uszkodzone linki mogą również wpływać na rankingi w wyszukiwarkach. W związku z tym testowanie uszkodzonych linków powinno być okresowo przeprowadzane w przypadku działań związanych z tworzeniem i testowaniem stron internetowych.
zamiast polegać na narzędziach innych firm lub ręcznych metodach sprawdzania uszkodzonych linków na stronie internetowej, testowanie uszkodzonych linków można wykonać za pomocą Selenium WebDriver z Java, Python, C# lub PHP. Kod statusu HTTP, zwracany podczas uzyskiwania dostępu do dowolnej strony internetowej, powinien być używany do sprawdzania niedziałających linków za pomocą Selenium framework.
Często zadawane pytania
jak znaleźć niedziałające linki w selenium Python?
aby sprawdzić niedziałające linki, musisz zebrać wszystkie linki na stronie internetowej na podstawie tagu. Następnie wyślij żądanie HTTP dla linków i odczytaj kod odpowiedzi HTTP. Sprawdź, czy łącze jest poprawne, czy uszkodzone na podstawie kodu odpowiedzi HTTP.
Jak sprawdzić, czy nie ma uszkodzonych linków?
aby stale monitorować witrynę pod kątem niedziałających linków za pomocą Google Search Console, wykonaj następujące kroki:
- Zaloguj się na swoje konto Google Search Console.
- kliknij witrynę, którą chcesz monitorować.
- kliknij Crawl, a następnie kliknij Pobierz jako Google.
- po przeszukiwaniu witryny przez Google, aby uzyskać dostęp do wyników, kliknij Crawl, a następnie kliknij Crawl Errors.
- w sekcji błędy adresu URL możesz zobaczyć uszkodzone linki odkryte przez Google podczas procesu indeksowania.
jak znaleźć uszkodzone obrazy w Internecie za pomocą selenium?
odwiedź Stronę. Wykonaj iterację każdego obrazu w archiwum HTTP i sprawdź, czy ma kod statusu 404. Przechowuj każdy uszkodzony obraz w kolekcji. Sprawdź, czy kolekcja uszkodzonych obrazów jest pusta.
jak zdobyć wszystkie linki w selenium?
możesz uzyskać wszystkie linki obecne na stronie internetowej w oparciu o < a > tag obecny. Każdy <a> tag reprezentuje link. Użyj lokalizatorów selenium, aby łatwo znaleźć wszystkie takie tagi.
dlaczego uszkodzone linki są złe?
mogą zaszkodzić użytkownikowi – gdy użytkownicy klikają linki i osiągają ślepe błędy 404, są sfrustrowani i mogą nigdy nie wrócić. Dewaluują twoje wysiłki SEO – uszkodzone linki ograniczają przepływ kapitału linków w całej witrynie, wpływając negatywnie na rankingi.

Himanshu Sheth
Himanshu Sheth jest doświadczonym technologiem i blogerem z ponad 15-letnim doświadczeniem w pracy. Obecnie pracuje jako „Lead Developer Evangelist” i „Senior Manager” w LambdaTest. Jest bardzo aktywny w społeczności startupów w Bengaluru (i na południu) i uwielbia wchodzić w interakcje z zapalonymi założycielami na swoim osobistym blogu (który prowadzi od ponad 15 lat).