




Jak sprawdzić duplikat treści
jak znaleźć duplikat treści
duplikat treści powinien być zminimalizowany na całej stronie internetowej, ponieważ może to utrudnić wyszukiwarkom podjęcie decyzji, która wersja ma zostać uszeregowana dla zapytania.
podczas gdy „duplikat treści” jest mitem w SEO, bardzo podobna treść może powodować nieefektywność indeksowania, osłabiać PageRank i być oznaką treści, które można skonsolidować, usunąć lub poprawić.
warto pamiętać, że duplikaty i podobne treści są naturalną częścią sieci, co często nie stanowi problemu dla wyszukiwarek, które z założenia będą kanonikować adresy URL i filtrować je w stosownych przypadkach. Jednak w skali może to być bardziej problematyczne.
zapobieganie duplikowaniu treści daje Ci kontrolę nad tym, co jest indeksowane i klasyfikowane – zamiast pozostawiać to wyszukiwarkom. Możesz ograniczyć marnowanie budżetu indeksowania i skonsolidować indeksowanie i łączyć sygnały, aby pomóc w rankingu.
w tym samouczku dowiesz się, w jaki sposób możesz użyć Screaming Frog SEO Spider, aby znaleźć zarówno dokładnie zduplikowaną treść, jak i prawie zduplikowaną treść, w której niektóre teksty pasują do stron na stronie internetowej.
duplikaty treści zidentyfikowane przez dowolne narzędzie, w tym SEO Spider, muszą zostać zweryfikowane w kontekście. Obejrzyj nasz film lub przeczytaj nasz przewodnik poniżej.
aby rozpocząć, pobierz SEO Spider, który jest darmowy do indeksowania do 500 adresów URL. Pierwsze 2 kroki są dostępne tylko z licencją. Jeśli jesteś darmowym użytkownikiem, przejdź do numeru 3 w przewodniku.
1) Włącz 'Near Duplicates’ poprzez 'Config > Content > Duplicates’
domyślnie SEO Spider automatycznie zidentyfikuje dokładne duplikaty stron. Aby jednak zidentyfikować „bliskie duplikaty”, należy włączyć konfigurację, która umożliwia przechowywanie zawartości każdej strony.
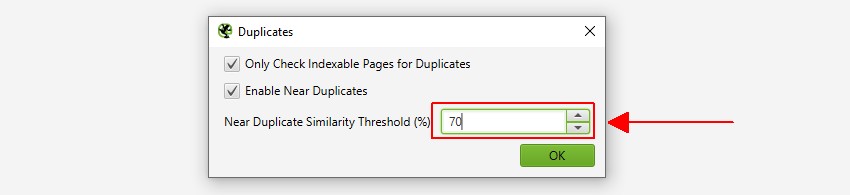
Pająk SEO zidentyfikuje w pobliżu duplikaty z dopasowaniem podobieństwa 90%, które można dostosować, aby znaleźć treści o niższym progu podobieństwa.
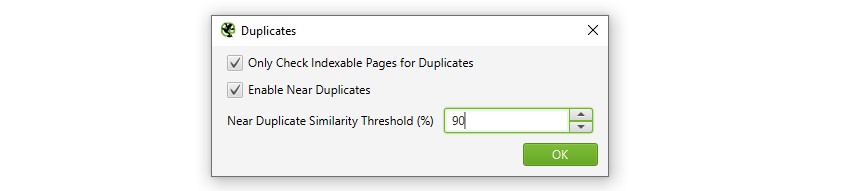
SEO Spider sprawdzi również tylko strony „Indeksowalne” pod kątem duplikatów (zarówno dla dokładnych, jak i bliskich duplikatów).
oznacza to, że jeśli masz dwa adresy URL, które są takie same, ale jeden jest kanoniczny dla drugiego (i dlatego „nieusuwalny”), nie zostanie to zgłoszone-chyba że ta opcja jest wyłączona.
jeśli chcesz znaleźć problemy z indeksowaniem budżetu, odznacz opcję „Sprawdź tylko strony indeksowane pod kątem duplikatów”, ponieważ może to pomóc w znalezieniu obszarów potencjalnych odpadów indeksowania.
2) Dostosuj „obszar zawartości” do analizy za pomocą „Config > zawartość > obszar”
możesz skonfigurować zawartość używaną do analizy niemal duplikatów. W przypadku nowego indeksowania zalecamy użycie domyślnej konfiguracji i dopracowanie jej później, gdy będzie można zobaczyć i rozważyć zawartość użytą w analizie.
Spider SEO automatycznie wykluczy zarówno elementy nawigacji, jak i stopki, aby skupić się na treści głównej. Jednak nie każda strona internetowa jest zbudowana przy użyciu tych elementów HTML5, więc w razie potrzeby możesz udoskonalić obszar treści używany do analizy. Możesz wybrać „dołączanie” lub „wykluczanie” znaczników HTML, klas i identyfikatorów w analizie.
na przykład strona Screaming Frog ma mobilne menu poza elementem nav, które jest domyślnie włączone do analizy treści. Chociaż nie jest to duży problem, w tym przypadku, aby pomóc skupić się na głównym tekście strony, jej nazwa klasy 'mobile-menu__dropdown’ może być wprowadzona do pola 'Wyklucz klasy’.
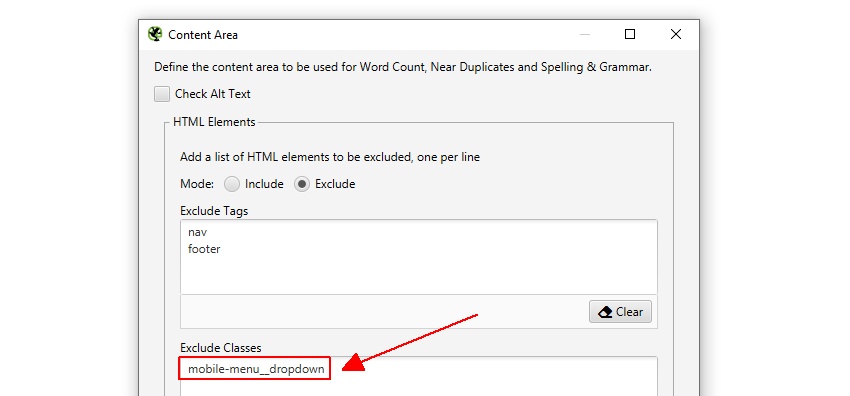
spowoduje to wykluczenie menu z włączenia do algorytmu analizy zduplikowanej zawartości. Więcej na ten temat później.
3) indeksowanie strony internetowej
Otwórz SEO Spider, wpisz lub skopiuj na stronie internetowej, którą chcesz indeksować w polu „Wprowadź adres URL do pająka” i naciśnij „Start”.
poczekaj, aż indeksowanie zakończy się i osiągnie 100%, ale możesz także wyświetlić niektóre szczegóły w czasie rzeczywistym.
4) Wyświetl duplikaty w zakładce „zawartość”
zakładka zawartość ma filtry 2 związane z duplikatami, „dokładne duplikaty” i „bliskie duplikaty”.
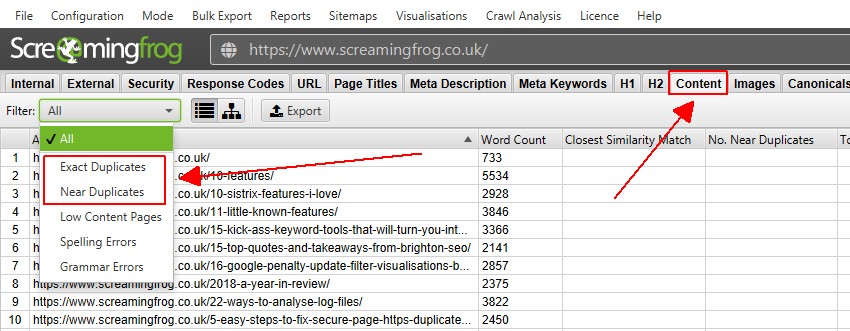
tylko 'dokładne duplikaty’ są dostępne do wyświetlenia w czasie rzeczywistym podczas indeksowania. „W pobliżu duplikatów” wymagają obliczeń na końcu indeksowania za pomocą postu „Analiza indeksowania”, aby mogły być wypełnione danymi.
po prawej stronie okienko „przegląd” wyświetla komunikat „(wymagana Analiza indeksowania) ” przeciwko filtrom, które wymagają wypełniania analizy po indeksowaniu danymi.
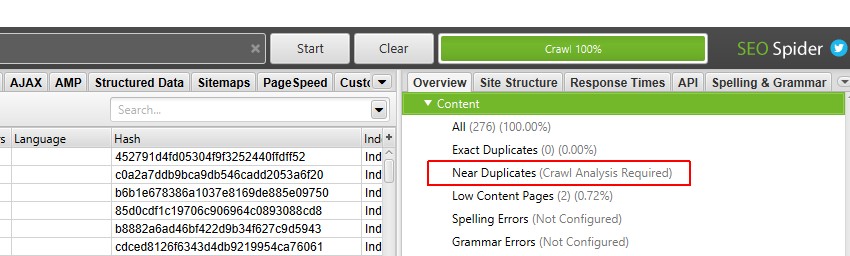
5) Kliknij „Analiza indeksowania > Start”, aby wypełnić Filtr „blisko duplikatów”
, aby wypełnić filtr „blisko duplikatów”, „Najbliższe dopasowanie podobieństwa” i ” nie. W pobliżu kolumn duplikatów wystarczy kliknąć przycisk na końcu indeksowania.

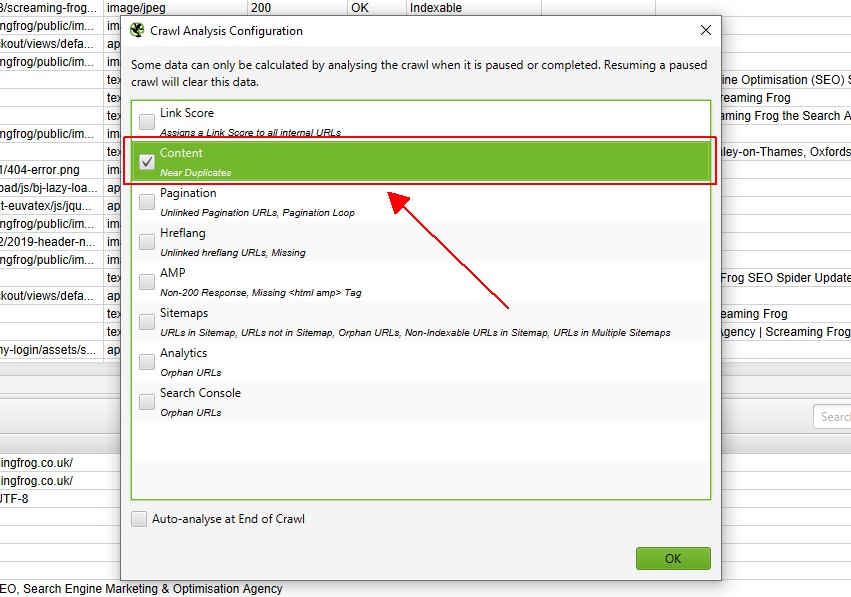
jeśli jednak wcześniej skonfigurowałeś „analizę indeksowania”, możesz dwukrotnie sprawdzić, w sekcji „Analiza indeksowania > Skonfiguruj”, czy zaznaczono opcję „blisko duplikatów”.
możesz także odznaczyć inne elementy, które również wymagają analizy indeksowania postów, aby ten krok był szybszy.
po zakończeniu analizy indeksowania pasek postępu „analizy” będzie na poziomie 100%, a filtry nie będą już miały komunikatu ” (wymagana Analiza indeksowania)”.
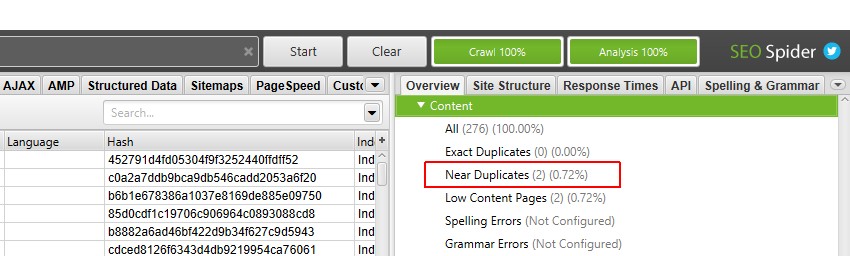
możesz teraz wyświetlić wypełniony filtr i kolumny w pobliżu duplikatów.
6) Zobacz zakładkę 'Content’ & 'Exact’ & 'Near’ filtry duplikatów
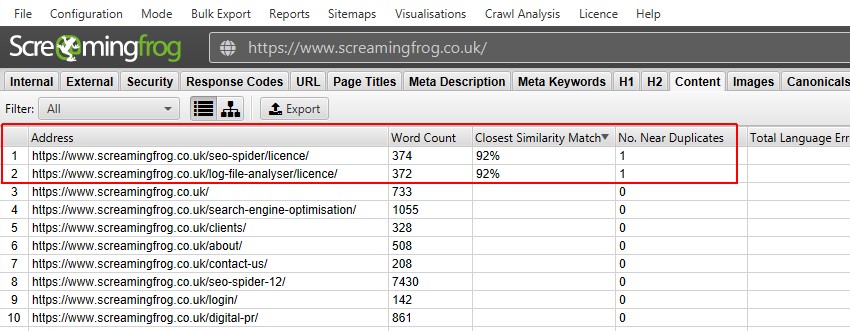
po wykonaniu analizy indeksowania postów, filtr 'Near Duplicates’, 'Closest Similarity Match’ i 'No. W pobliżu kolumn duplikatów zostaną wypełnione. Tylko adresy URL z zawartością powyżej wybranego progu podobieństwa będą zawierać dane, Pozostałe pozostaną puste. W tym przypadku strona Screaming Frog ma tylko dwa.
indeks większej strony internetowej, takiej jak BBC, ujawni wiele więcej.
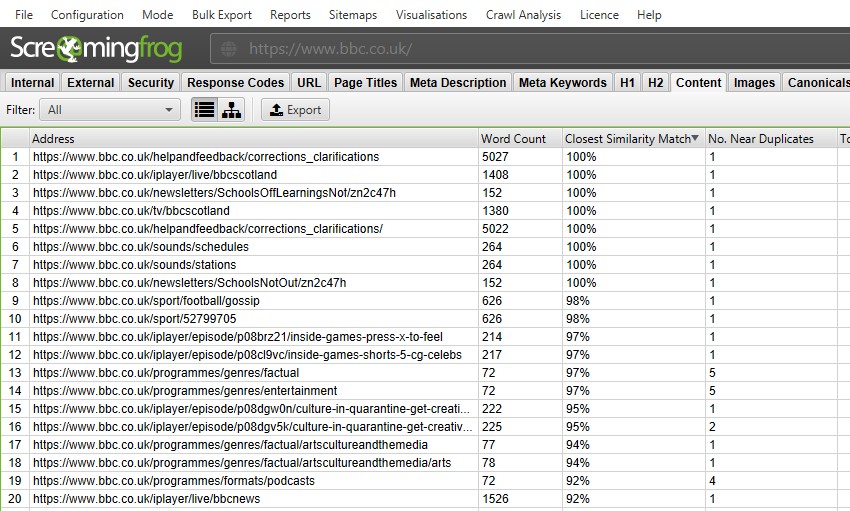
możesz filtrować według następujących–
- dokładne duplikaty-ten filtr pokaże strony, które są identyczne do siebie za pomocą algorytmu MD5, który oblicza wartość 'hash’ dla każdej strony i może być widoczny w kolumnie 'hash’. To sprawdzenie jest wykonywane z pełnym kodem HTML strony. Wyświetli wszystkie strony z pasującymi wartościami skrótu, które są dokładnie takie same. Dokładne duplikaty stron mogą prowadzić do podziału sygnałów PageRank i nieprzewidywalności w rankingu. Powinna istnieć tylko jedna kanoniczna wersja adresu URL, która istnieje i jest połączona wewnętrznie. Inne wersje nie powinny być łączone i powinny być przekierowane do wersji kanonicznej.
- w pobliżu duplikatów-ten filtr wyświetli podobne strony na podstawie skonfigurowanego progu podobieństwa przy użyciu algorytmu minhash. Próg ten można dostosować w sekcji „Config > spider > Content” i domyślnie jest ustawiony na 90%. Kolumna „dopasowanie do najbliższego podobieństwa” wyświetla najwyższy procent podobieństwa do innej strony. Nie. W pobliżu kolumny duplikatów wyświetlana jest liczba stron, które są podobne do strony w oparciu o próg podobieństwa. Algorytm jest uruchamiany na podstawie tekstu na stronie, a nie pełnego kodu HTML, takiego jak dokładne duplikaty. Zawartość użytą do tej analizy można skonfigurować w obszarze ” Config > Content >”. Strony mogą mieć 100% podobieństwa, ale tylko być „prawie duplikatem”, a nie dokładnym duplikatem. Wynika to z faktu, że dokładne duplikaty są wykluczone jako bliskie duplikaty, aby uniknąć ich dwukrotnego oznaczania. Wyniki podobieństwa są również zaokrąglane, więc 99,5% lub więcej będzie wyświetlane jako 100%.
w pobliżu zduplikowanych stron należy ręcznie przejrzeć, ponieważ istnieje wiele uzasadnionych powodów, dla których niektóre strony są bardzo podobne pod względem treści, takich jak odmiany produktów, które mają objętość wyszukiwania wokół ich określonego atrybutu.
jednak adresy URL oznaczone jako prawie duplikaty powinny zostać sprawdzone, aby rozważyć, czy powinny istnieć jako oddzielne strony ze względu na ich unikalną wartość dla użytkownika, czy też powinny zostać usunięte, skonsolidowane lub ulepszone, aby treść była bardziej dogłębna i unikalna.
7) Wyświetl duplikaty adresów URL za pomocą zakładki „duplikaty szczegółów”
w przypadku „dokładnych duplikatów” łatwiej jest po prostu wyświetlić je w górnym oknie za pomocą filtra – ponieważ są one zgrupowane i mają tę samą wartość „skrótu”.
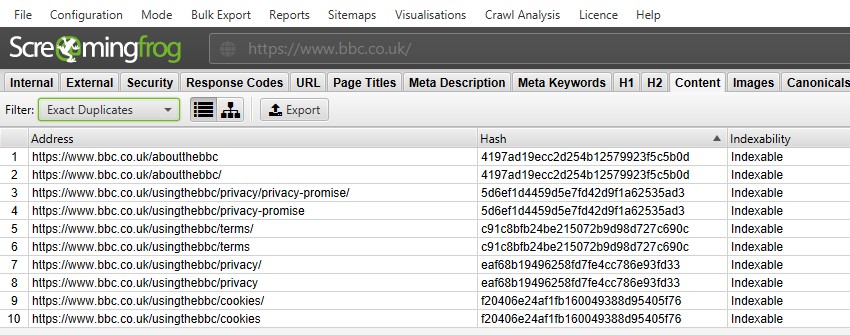
na powyższym zrzucie ekranu każdy adres URL ma odpowiedni dokładny duplikat ze względu na końcową wersję ukośnika i nie końcową wersję ukośnika.
w przypadku „blisko duplikatów” kliknij zakładkę „zduplikowane szczegóły” na dole, która wypełnia dolne okienko „prawie zduplikowanym adresem” i podobieństwem każdego wykrytego prawie zduplikowanego adresu URL.
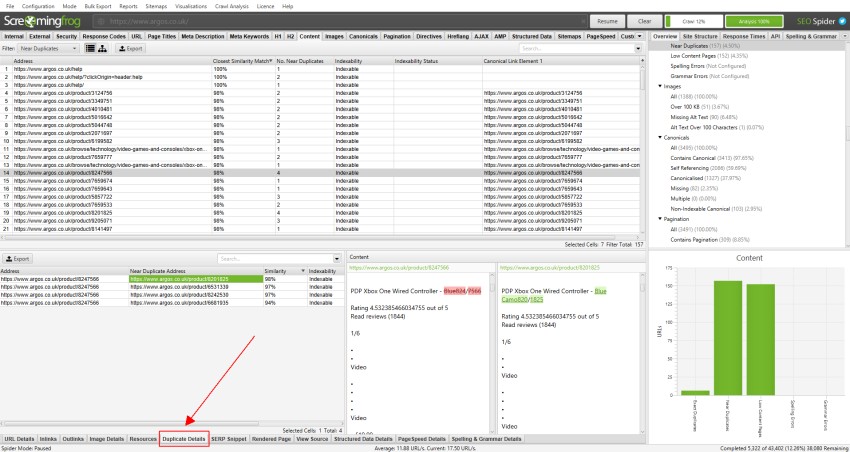
na przykład, jeśli w górnym oknie znajdują się 4 prawie duplikaty adresu URL, można je wszystkie wyświetlić.
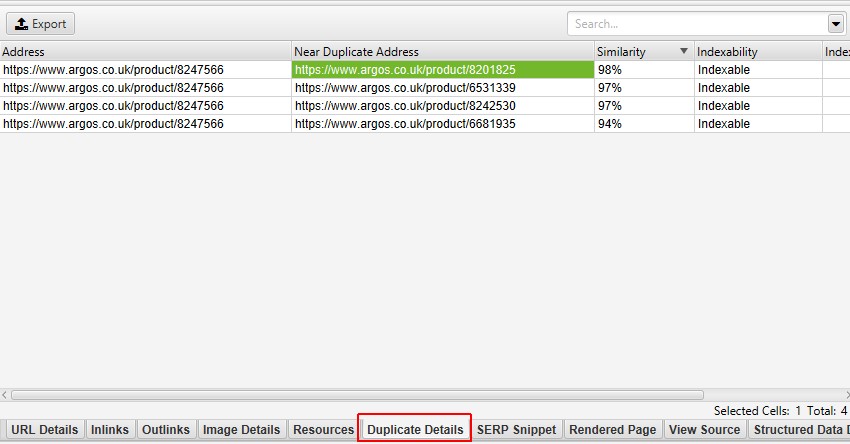
po prawej stronie zakładki „zduplikowane szczegóły” wyświetli prawie zduplikowaną zawartość odkrytą na stronach i podświetli różnice między stronami po kliknięciu każdego z nich.
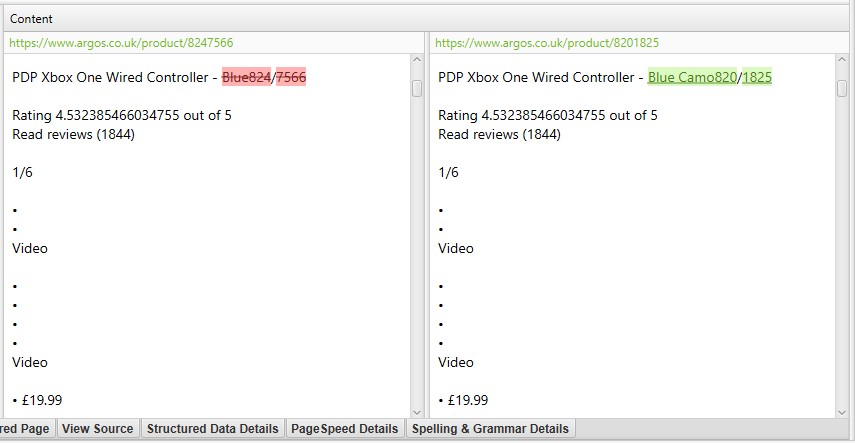
jeśli na karcie zduplikowane szczegóły znajduje się duplikat zawartości, którego nie chcesz brać pod uwagę w analizie zduplikowanej zawartości, Wyłącz lub dołącz elementy HTML, klasy lub identyfikatory (jak zaznaczono w punkcie 2), & uruchom ponownie analizę indeksowania.
8) duplikaty eksportu zbiorczego
zarówno dokładne, jak i bliskie duplikaty mogą być eksportowane zbiorczo za pomocą eksportów „eksport zbiorczy > zawartość > dokładne duplikaty” i „bliskie duplikaty”.

Ostatnia Wskazówka! Określ próg podobieństwa & obszar zawartości, & uruchom ponownie analizę indeksowania
po indeksowaniu możesz dostosować zarówno próg prawie zduplikowanego podobieństwa, jak i obszar zawartości używany do analizy prawie zduplikowanej.
możesz ponownie uruchomić analizę indeksowania, aby znaleźć mniej więcej podobną treść-bez ponownego indeksowania strony.
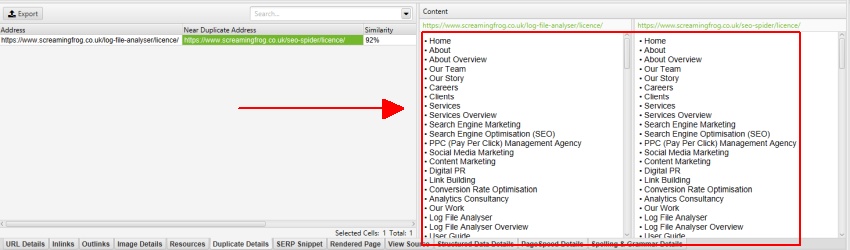
jak wspomniano wcześniej, strona Screaming Frog ma mobilne menu poza elementem nav, które jest domyślnie włączone do analizy zawartości. Menu mobilne można zobaczyć w podglądzie zawartości karty „zduplikowane szczegóły”.
wykluczając rozwijane menu mobilne__w polu „Wyklucz klasy” w obszarze ” Konfiguracja > zawartość >”, menu mobilne zostanie usunięte z podglądu zawartości i analizy prawie zduplikowanej.
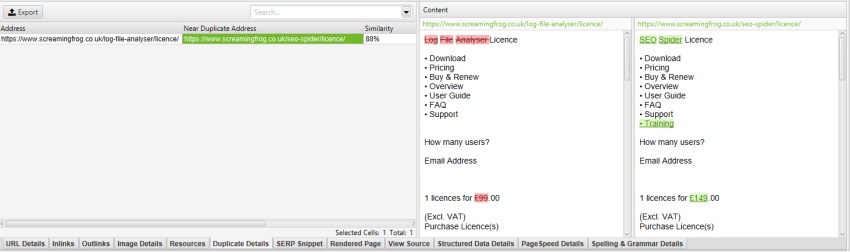
może to naprawdę pomóc podczas dostrajania identyfikacji prawie zduplikowanej zawartości do głównych obszarów zawartości, bez potrzeby ponownego indeksowania.
podsumowanie
powyższy przewodnik powinien zilustrować, jak używać SEO Spider jako duplikatu sprawdzania treści na swojej stronie internetowej. Aby uzyskać najdokładniejsze wyniki, udoskonal obszar treści do analizy i dostosuj próg dla różnych grup stron.
przeczytaj również nasze Screaming Frog SEO Spider FAQ i pełny podręcznik użytkownika, aby uzyskać więcej informacji na temat narzędzia.
jeśli masz jakieś dalsze pytania, opinie lub sugestie dotyczące ulepszenia narzędzia duplicate content W SEO Spider, skontaktuj się z nami za pośrednictwem pomocy technicznej.