vanwege het feit dat veel vrienden moeite hebben met het bespreken van gegevens normalisatie, dus in dit artikel willen we u leren hoe u gegevens in SPSS normaliseren op een visuele en stap-voor-stap manier met volledige uitleg.
Wat is het doel van standaardisatie van gegevens?Dit is een vraag die veel van onze landgenoten zich stellen: Wat is het nut van standaardisatie van gegevens? Het antwoord is dat standaardisatie van gegevens helpt dat hun belang niet afhankelijk is van hun meeteenheid. Als gevolg hiervan worden gestandaardiseerde gegevens gebruikt in gevallen zoals datamining en multivariate data-analyse.
normalisatie is ook van toepassing op kwantitatieve en kwalitatieve gegevens en er zijn verschillende normalisatiemethoden.
stap-voor-stap handleiding over normaliseren van gegevens in SPSS:
na het bekijken van de video hierboven, gaan we naar de stap-voor-stap instructie van deze operatie. U kunt deze stappen volgen om de gegevens normalisatie eenvoudig en succesvol te voltooien.
Stap 1 – We voeren de gegevens in in de SPSS-softwareomgeving . In deze stap kunnen de gegevens handmatig worden ingevoerd of worden gekopieerd vanuit een andere omgeving zoals Excel.
Stap 2-Na het invoeren van de gegevens, Ga naar de analyseren tab en voer de beschrijvende statistieken en verkennen secties .
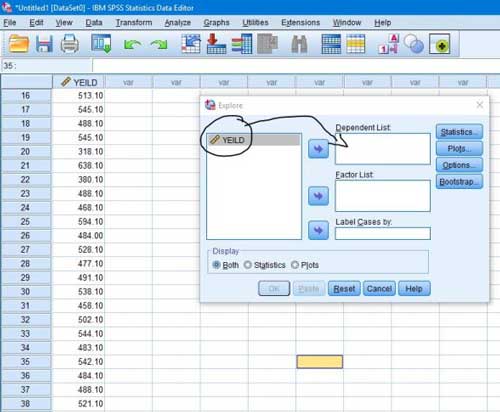
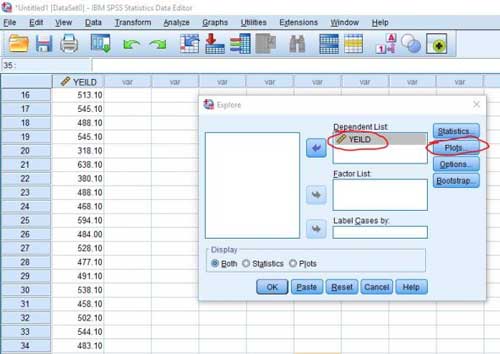
Stap 3-in het venster dat wordt geopend, voert u het gewenste kenmerk in de afhankelijke keuzelijst . In deze stap, als we meerdere attributen hebben, kunnen we de normaliteitstest op alle attributen tegelijkertijd uitvoeren, dus we voeren alle attributen in de afhankelijke keuzelijst in .
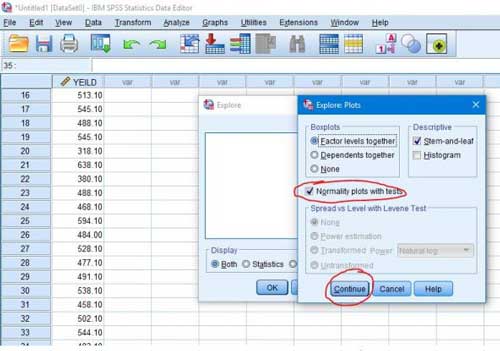
Stap 4-Na het invoeren van de attributen, moeten we de zin normaliteit plots activeren met tests uit de Plots sectie en klik op de doorgaan en Ok knop zodat de testresultaten verschijnen in het uitvoervenster .
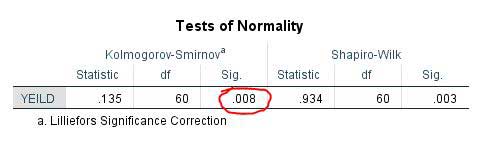
Stap 5-Je zag hoe gemakkelijk met twee tests, de normaliteit van de gegevens werd gecontroleerd. Volgens het bovenstaande onderzoeken we nu de resultaten van de Kolmogorov-Smirnov-test. In deze tabel als de waarde van sig . Als het meer dan 0 is.01, de gegevens zijn normaal, en als het minder is dan 0,01, worden de gegevens niet normaal verdeeld, en we moeten het converteren voordat we de variantie analyseren.