




Selenium WebDriverを使用して壊れたリンクを見つける方法は?
あなたが404/ページが見つかりません/ウェブサイト上の死んだハイパーリンクに遭遇したときにどのような考えが頭に浮かぶ? アーッ! あなたが継続的にあなたのweb製品(またはウェブサイト)内の壊れたリンクの存在を削除することに焦点を当てるべき唯一の理由である壊れたハイ 手動検査の代わりに、Selenium WebDriverを使用して、壊れたリンクテストの自動化を活用できます。

特定のリンクが壊れ、訪問者がページに着陸すると、そのページの機能に影響を与え、ユーザーエクスペリエンスが低下します。 死んだリンクは経験の最低の焦点があることあなたの訪問者に印象を与える’かもしれないのであなたのプロダクトの信頼性を傷つけることが
ウェブ製品に404エラー(またはページが見つかりません)になる多くのページ(またはリンク)がある場合、検索エンジン(Googleなど)の製品ランキングにも深刻な影響 死んだリンクの除去は、SEO(検索エンジン最適化)活動の不可欠な部分の1つです。
Selenium WebDriverチュートリアルシリーズのこの部分では、Selenium WebDriverを使用して壊れたリンクを見つけることに深く掘り下げます。 私たちは、Selenium Python、Selenium Java、Selenium C#、およびSelenium PHPを使用した壊れたリンクテストを実証しました。
Webテストにおける壊れたリンクの概要
簡単に言えば、ウェブサイト(またはwebアプリ)内の壊れたリンク(または死んだリンク)は、到達できず、予想どおり サーバーの問題が原因でリンクが一時的にダウンしたり、バックエンドで誤って構成されたりする可能性があります。
404エラーが発生するページとは別に、壊れたリンクの他の顕著な例は、不正な形式のUrl、コンテンツへのリンク(文書、pdf、画像など)です。)移動または削除されたもの。
リンク切れの顕著な理由
リンク切れの発生の背後にある一般的な理由のいくつかは次のとおりです(デッドリンクまたはリンクの腐敗):
- ユーザーが入力したURLが間違っているか、スペルミスがあります。
- URLリダイレクトや内部リダイレクトによるウェブサイトの構造変更(パーマリンクなど)が正しく設定されていません。
- 動画、ドキュメントなどのコンテンツへのリンク。 それは移動または削除されます。 コンテンツが移動された場合は、”内部リンク”を指定されたリンクにリダイレクトする必要があります。
- サイトメンテナンスによる一時的なウェブサイトのダウンタイムにより、ウェブサイトが一時的にアクセスできなくなります。
- 壊れたHTMLタグ、JavaScriptエラー、不適切なHTML/CSSのカスタマイズ、壊れた埋め込み要素など、先頭のページ内では、壊れたリンクにつながることができます。
- 位置情報の制限により、特定のIPアドレス(ブラックリストに登録されている場合)または世界の特定の国からのウェブサイトへのアクセスが禁止さ Seleniumを使用した地理位置情報テストは、サイトがアクセスされた場所(または国)に合わせて操作をカスタマイズするのに役立ちます。
なぜ壊れたリンクをチェックする必要がありますか?
壊れたリンクは、あなたのウェブサイトに着陸する訪問者にとって大きなターンオフです。 ここにあなたのウェブサイトの壊れたリンクがあるようになぜ点検するべきであるか主な理由のいくつかはある:
- リンクが壊れていると、ユーザーエクスペリエンスが損なわれる可能性があります。
- 壊れた(または死んだ)リンクの除去は、検索エンジン(Googleなど)上のサイトのランキングに影響を与える可能性があるため、SEO(検索エンジン最適化)に不可欠
リンク切れのテストは、WebページでSelenium WebDriverを使用して行うことができ、これを使用してサイトの死んだリンクを削除することができます。
リンク切れとHTTPステータスコード
ユーザーがウェブサイトを訪問すると、ブラウザからサイトのサーバーにリクエストが送信されます。 サーバーは、ブラウザの要求に「HTTPステータスコード」と呼ばれる3桁のコードで応答します。’
HTTPステータスコードは、webブラウザから送信された要求に対するサーバーの応答です。 これらのHTTPステータスコードは、ブラウザー(URL要求の送信元)とサーバー間の会話と同等と見なされます。
HTTPステータスコードは目的によって異なりますが、ほとんどのコードはサイトの問題の診断、サイトのダウンタイムの最小化、デッドリンクの数などに役 すべての3桁のステータスコードの最初の桁は、1〜5の数字で始まります。 ステータスコードは1xx、2xxとして表されます。.、その特定の範囲内のステータスコードを示すための5xx。 これらの範囲はそれぞれ異なるクラスのサーバー応答で構成されているため、壊れたリンクに対して提示されるHTTPステータスコードに限定します。
Seleniumで壊れたリンクを検出するのに役立つ一般的なステータスコードクラスは次のとおりです:
| HTTPステータスコード | のクラス説明 |
|---|---|
| 1xx | サーバーはまだリクエストを考えています。 |
| 2xx | ブラウザから送信された要求は正常に完了し、サーバーから期待される応答がブラウザに送信されました。 |
| 3xx | リダイレクトが実行されていることを示します。 たとえば、301リダイレクトは、webサイトに永続的なリダイレクトを実装するために一般的に使用されます。 |
| 4xx | これは、特定のページ(またはサイト全体)に到達できないことを示します。 |
| 5xx | これは、ブラウザによって有効な要求が送信されたにもかかわらず、サーバーが要求を完了できなかったことを示します。 |
壊れたリンクの検出時に表示されるHTTPステータスコード
壊れたリンクに遭遇したときにwebサーバーによって表示される一般的なHTTPステータスコードの一部:
| HTTPステータスコード | 説明 |
|---|---|
| 400 (Bad Request) | 上記のURLが正しくないため、サーバーは要求を処理できません。 |
| 400 (Bad Request-Bad Host) | これは、ホスト名が無効であり、要求を処理できないことを示します。 |
| 400 (Bad Request-BAD URL) | これは、入力されたURLの形式が間違っている(角かっこ、スラッシュなどがない)ため、サーバーが要求を処理できないことを示します。). |
| 400 (Bad Request-Timeout) | これは、HTTP要求がタイムアウトしたことを示します。 |
| 400 (Bad Request-Empty) | サーバーから返された応答は空で、コンテンツも応答コードもありません。 |
| 400 (Bad Request-Reset) | これは、サーバーが他の要求の処理にビジー状態であるか、サイト所有者によって誤って構成されているため、要求を処理できないことを示します。 |
| 403 (禁止されている) | 本物の要求がサーバーに送信されますが、承認が必要なため、同じ要求を満たすことを拒否しています。 |
| 404 (ページが見つかりません) | リソース(またはページ)がサーバー上で使用できません。 |
| 408 (要求タイムアウト) | サーバーが要求を待ってタイムアウトしました。 クライアント(ブラウザ)は、サーバーが待機する準備ができている時間内に同じ要求を送信することができます。 |
| 410 ( | 404(ページが見つかりません)よりも永続的なHTTPステータスコード。 410は、ページがなくなったことを意味します。 このページはサーバー上で使用できず、転送(またはリダイレクト)メカニズムも設定されていません。 410ページを指すリンクは、デッドリソースへの訪問者を送信しています。 |
| 503 (Service Unavailable) | これは、サーバーが一時的に過負荷になっているため、要求を処理できないことを示します。 また、メンテナンスがサーバーで実行されていることを意味し、サイトの一時的なダウンタイムについて検索エンジンを示します。 |
Selenium WebDriverを使用して壊れたリンクを見つける方法は?
Selenium WebDriverで使用される言語に関係なく、Seleniumを使用した壊れたリンクテストの指針は同じままです。 Selenium WebDriverを使用したリンク切れテストの手順は次のとおりです:
- このタグを使用して、webページに存在するすべてのリンクの詳細を収集します。
- すべてのリンクに対してHTTP要求を送信します。
- 前のステップで送信された要求に応答して受信した対応する応答コードを確認します。
- サーバーから送信された応答コードに基づいて、リンクが切断されているかどうかを検証します。
- ページ上に存在するすべてのリンクについて、手順(2-4)を繰り返します。このSelenium WebDriverチュートリアルでは、Python、Java、C#、およびPHPでSelenium WebDriverを使用して壊れたリンクテストを実行する方法を説明します。 テストは(Chrome85.0+Windows10)の組み合わせで実行され、実行はLambdaTestが提供するクラウドベースのSeleniumグリッドで実行されます。
LambdaTestの使用を開始するには、プラットフォーム上でアカウントを作成し、LambdaTestのプロファイルセクションから利用可能なユーザー名&アクセスキーをメモします。 ブラウザの機能は、LambdaTest Capabilities Generatorを使用して生成されます。
Seleniumを使用してwebサイトで壊れたリンクを見つけるために使用されるテストシナリオは次のとおりです。
テストシナリオ
- LambdaTestブログに移動します。https://www.lambdatest.com/blog/On Chrome85.0
- ページに存在するすべてのリンクを収集します。
- 各リンクのHTTPリクエストを送信します。
- 端末でリンクが壊れているかどうかを出力する
Seleniumを使用したリンク切れテストに費やされる時間は、テスト中のWebページに存在するリンクの数に依存することに注意することが重要です。’ページ上のリンクの数が多いほど、壊れたリンクを見つけるのに時間がかかります。 たとえば、LambdaTestには膨大な数のリンクがあります(〜150+);したがって、壊れたリンクを見つけるプロセスには時間がかかる場合があります(約数分)。

SELENIUM GRIDでテストスクリプトを実行
2000+ブラウザとOS
無料サインアップ
Selenium Javaを使用したリンク切れテスト
実装
コードチュートリアル
1. 必要なパッケージのインポート
HttpURLConnectionパッケージ内のメソッドは、HTTP要求の送信とHTTPステータスコード(または応答)のキャプチャに使用されます。
正規表現のメソッド。パターンパッケージ対応するリンクに、パターンで保持されている特殊な構文を使用して、電子メールアドレスまたは電話番号が含まれているかどうかを確認します。
12インポートjava.net.HttpURLConnection;インポートjava.net.HttpURLConnection;インポートjava。ユーティル正規表現。パターン;2. ページに存在するリンクを収集する
テスト中のURLに存在するリンク(つまり、LambdaTestブログ)は、Seleniumのtagnameを使用して配置されています。 要素(またはリンク)の識別に使用されるタグ名は’a’です。
リンクは、ページ上の壊れたリンクをチェックするためにリストを反復処理するためにリストに配置されます。
1リスト<WebElement>リンク=ドライバ。findElements(By.tagName(“a”));3. Urlを反復処理する
Iteratorオブジェクトは、ステップで作成されたリストをループ処理するために使用されます(2)
1Iterator<WebElement>link=リンク。イテレータ();4. Urlを特定して検証する
時間反復子(リンク)に反復する要素がなくなるまでwhileループが実行されます。 アンカータグの’href’が取得され、同じものがURL変数に格納されます。
123while(リンク。ハスネクスト()){url=リンク。次へ()。getAttribute(“href”);の場合は、リンクのチェックをスキップします。a. リンクがnullまたは空です
12345if((url==null)||(url.isEmpty())){システム。出ろprintln(“URLはアンカータグ用に構成されていないか、空です”);continue;}b. リンクにはmailtoまたは電話番号が含まれています
12345if((url.startsWith(mail_to))||(url.スタートアップ(電話)))){システム。出ろprintln(“メールアドレスまたは電話番号が検出されました”);continue;}LinkedInページを確認すると、HTTPステータスコードは999になります。 ブール変数( LinkedIn)は、壊れたリンクではないことを示すためにtrueに設定されています。
12345if(url.startsWith(LinkedInPage)){システム。出ろprintln(“URLはLinkedInで始まり、期待されるステータスコードは次のとおりです999”);bLinkedIn=true;}5. ステータスコード
を使用したリンクの検証HttpURLConnectionクラスのメソッドは、HTTP要求の送信とHTTPステータスコードのキャプチャのための準備を提供します。
URLクラスのopenConnectionメソッドは、指定されたURLへの接続を開きます。 URLによって参照されるリモートオブジェクトへの接続を表すURLConnectionインスタンスを返します。 これはHttpURLConnectionに型キャストされます。
1234567HttpURLConnection urlconnection=null;。……………………………………………………………………………….……………………………………….urlconnection=(HttpURLConnection)(新しいURL(url).openConnection());url接続。setRequestMethod(“HEAD”);HttpURLConnectionクラスのsetRequestMethodは、URL要求のメソッドを設定します。 要求の種類は、ヘッダーのみが返されるようにHEADに設定されています。 一方、要求タイプGETはドキュメント本文を返していましたが、この特定のテストシナリオでは必要ありません。
HttpURLConnectionクラスのconnectメソッドは、URLへの接続を確立し、HTTP要求を送信します。
1url接続。接続();getResponseCodeメソッドは、以前に送信された要求のHTTPステータスコードを返します。
1responseCode=urlconnectionです。getResponseCode();HTTPステータスコードが400(またはそれ以上)の場合、壊れたリンク数を含む変数(broken_links)が増加し、そうでない場合、有効なリンクを含む変数(valid_links)が増加します。
123456789101112131415161718if(responseCode>= 400){if((bLinkedIn==true)&&(responseCode==LinkedInStatus)){システム。出ろprintln(url+”はLinkedInページであり、壊れたリンクではありません”);valid_links++;}その他{システム。出ろprintln(url+”壊れたリンクです”);broken_links++;}}その他{システム。出ろprintln(url+”有効なリンクです”);valid_links++;}実行
Selenium Javaを使用した壊れたリンクテストのために、IntelliJ IDEAでプロジェクトを作成しました。 基本的なpom。xmlファイルは仕事のために十分でした!
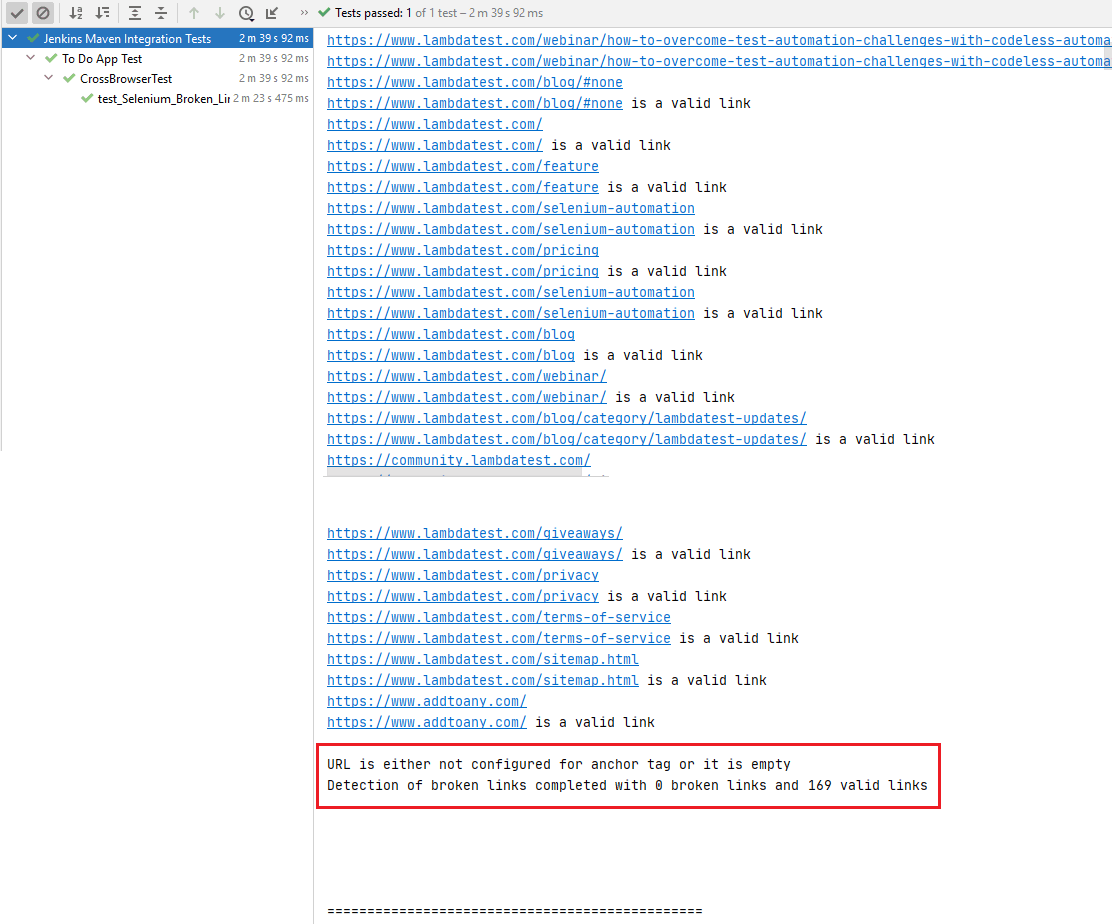
これは実行スナップショットで、LambdaTestブログページの有効なリンクが169個、壊れたリンクが0個を示しています。
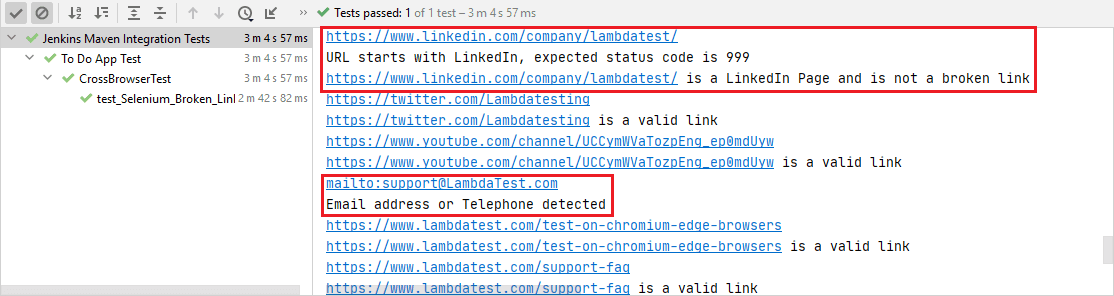
以下に示すように、電子メールアドレスと電話番号を含むリンクが検索リストから除外されました。
LambdaTestの自動化ログに示すように、以下のスクリーンショットで実行され、2分35秒で完了するテストを見ることができます。

Selenium Pythonを使用したリンク切れテスト
実装
コードウォークスルー
1. モジュールのインポート
Selenium WebDriver用のPythonモジュールのインポートとは別に、requestsモジュールもインポートします。 Requestsモジュールを使用すると、すべての種類のHTTP要求を送信できます。 また、URLでパラメータを渡したり、カスタムヘッダーを送信したりするためにも使用できます。
123要求をインポート要求からurllib3をインポートします。例外インポートMissingSchema,InvalidSchema,InvalidURL2. ページに存在するリンクを収集する
テスト中のURL(つまり、LambdaTestブログ)に存在するリンクは、CSSセレクタ”a”プロパティによってweb要素を見つけることによ
1リンク=ドライバ。find_elements(By.CSS_SELECTOR、”a”)要素を反復可能にしたいので、find_elementsメソッドを使用します(find_elementメソッドではありません)。
3. 検証のためにUrlを反復処理する
requestsモジュールのheadメソッドは、指定されたURLにHEAD要求を送信するために使用されます。 Get_attributeメソッドは、アンカータグの’href’属性を取得するためにすべてのリンクで使用されます。
headメソッドは、主にstatus_codeまたはHTTPヘッダーのみが必要で、ファイル(またはURL)の内容が必要ないシナリオで使用されます。 Headメソッドは要求を返します。HTTPステータスコードも含むResponseオブジェクト(つまりrequest。ステータス_コード)。
1234リンク内のリンクの場合:試してみてください:request=リクエスト。ヘッド(リンク。get_attribute(‘href’),data={‘key’:’value’})print(“ステータス”+リンク.get_attribute(‘href’)+”is”+str(request.status_code))ページ上に存在するすべての「リンク」が使い果たされるまで、同じ一連の操作が反復的に実行されます。
4. ステータスコード
を使用してリンクを検証します。ステップ(3)で送信されたHTTP要求のHTTP応答コードが404ページが見つかりませんの場合は、リンクが壊れたリンクであることを意味します。 壊れていないリンクの場合、HTTPステータスコードは200です。
1234if(リクエスト。status_code== 404):else:valid_links=(valid_links+1)valid_links=(valid_links+1)valid_links=(valid_links+1)+ 1)5. ‘Href’属性を含まないリンク(mailto、telephoneなど)に適用された場合、無関係な要求
をスキップします。この場合、headメソッドは例外(つまり、MissingSchema、InvalidSchema)になります。
123456except requests.exceptions.MissingSchema:print(“Encountered MissingSchema Exception”)except requests.exceptions.InvalidSchema:print(“Encountered InvalidSchema Exception”)except:print(“他のいくつかの実行が発生しました”)これらの例外はキャッチされ、同じことが端末に出力されます。
実行
ここでは、PythonのデフォルトのテストフレームワークであるPyUnit(またはunittest)を使用して、Seleniumを使用した壊れたリンクテスト用に使用しました。 ターミナルで次のコマンドを実行します:
1python Broken_Links.pyLambdaTestブログページは約150以上のリンクで構成されているため、実行には約2-3分かかります。 以下の実行スクリーンショットは、ページに169の有効なリンクとゼロの壊れたリンクがあることを示しています。
いくつかの場所でInvalidSchema例外またはMissingSchema例外が発生し、これらのリンクが評価からスキップされていることを示します。
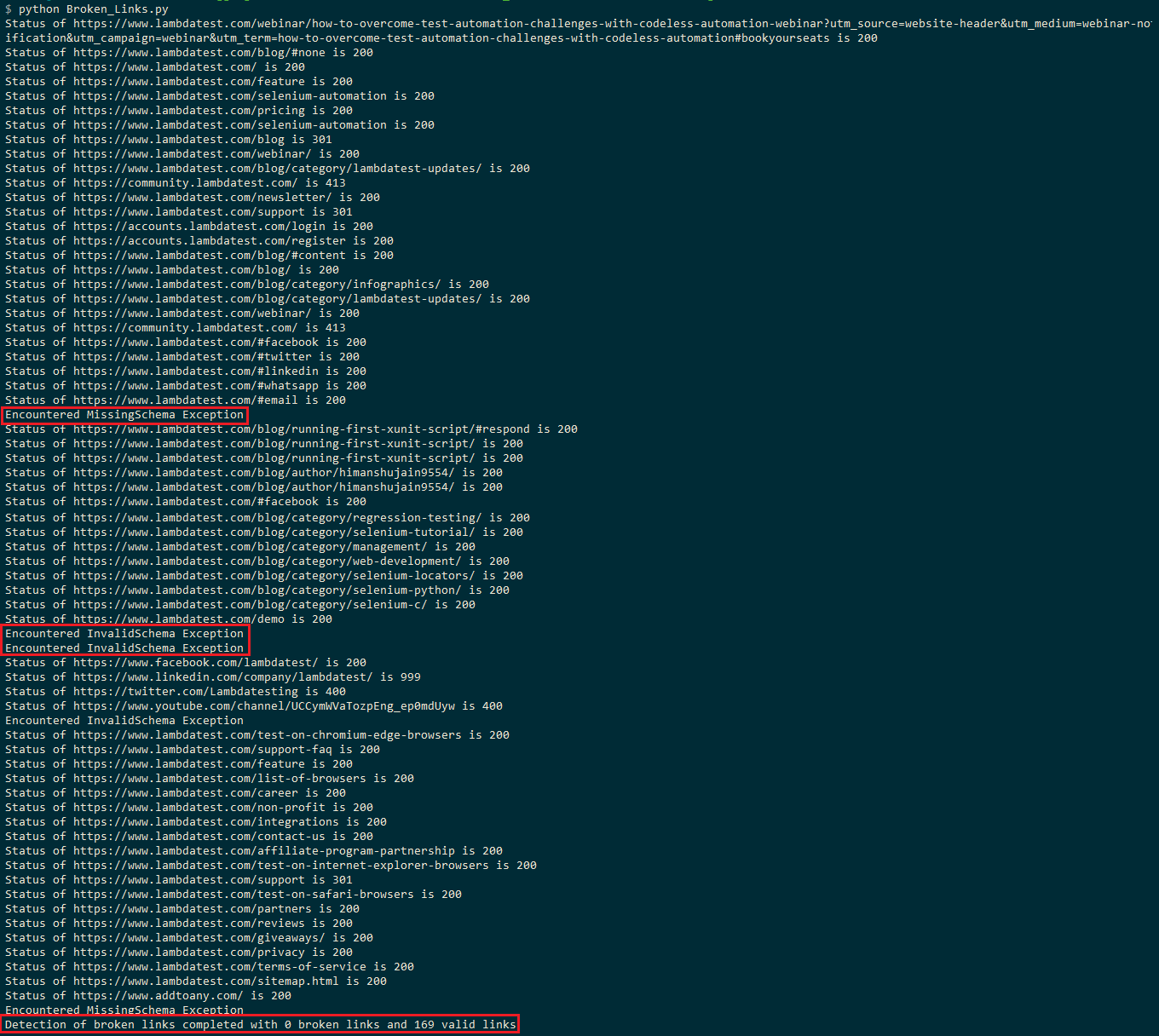
LinkedInへのHEAD要求(つまり)は、HTTPステータスコード999になります。 StackOverflowのこのスレッドで述べたように、LinkedInはuser-agentに基づいて要求をフィルタリングし、要求は「アクセス拒否」になりました(つまり、HTTPステータスコードとして999)。

ローカルのSeleniumグリッドで同じテストを実行することで、LambdaTestブログページに存在するLinkedInリンクが壊れているかどうかを確認し、HTTP/1.1 200OKになりました。
Selenium C#を使用した壊れたリンクテスト
実装
コードウォークスルー
NUnitフレームワークは自動化テストに使用されます; Selenium C#を使用したNUnit Test automationに関する以前のブログは、フレームワークの開始に役立ちます。
1. Include HttpClient
HttpClient名前空間は、usingディレクティブを使用して使用するために追加されます。 C#のHttpClientクラスは、HTTP要求を送信し、URIによって識別されるリソースからHTTP応答を受信するための基本クラスを提供します。
マイクロソフトは、System.Net.HttpWebRequestの代わりにSystem.Net.Http.HttpClientを使用することを推奨しています。HttpWebRequestは、Selenium C#で壊れたリンクを検出するためにも使用できます。
12System.Net.Httpを使用して;Systemを使用しています。スレッディング…タスク;2. Task
を返す非同期メソッドの定義非同期テストメソッドは、指定されたURIにGET要求を非同期操作として送信するGetAsyncメソッドを使用するものとして定義
12パブリック非同期タスクLt_Broken_Links_Test(){3. ページに存在するリンクを収集する
まず、HttpClientのインスタンスを作成します。
1var client=new HttpClient()を使用する;テスト対象のURL(つまり、LambdaTestブログ)に存在するリンクは、tagname”a”プロパティによってweb要素を検索することによって収集されます。
1varリンク=ドライバ。FindElements(By.TagName(“a”));Seleniumのfind_elementsメソッドは、リンクの実行可能性を検証するために反復できる配列(またはリスト)を返すときに、ページ上のリンクを検索するために使用され
4. 検証のためのUrlを反復処理
find_elementsメソッドを使用して配置されたリンクは、forループで検証されます。
12foreach(リンク内のvarリンク){私たちは、/電子メールアドレス/電話番号/LinkedInのアドレスを含むリンクをフィルタリングします。 リンクテキストのないリンクも除外されます。
12もし(!(リンク。テキスト。Contains(“Email”)||リンクを含みます。テキスト。Contains(“https://www.linkedin.com”)||リンクを含みます。テキスト==””//リンク。Equals(null))){HttpClientクラスのGetAsyncメソッドは、非同期操作として対応するURIにGET要求を送信します。 GetAsyncメソッドの引数は、getattributeメソッドを使用して収集されたアンカーの’href’属性の値です。
非同期メソッドの評価は、非同期操作が完了するまでawait演算子によって中断されます。 非同期操作が完了すると、await演算子は、データとステータスコードを含むHttpResponseMessageを返します。
123/* URIを取得*/HttpResponseMessage response=awaitクライアント。GetAsync(リンク.GetAttribute(“href”));システム。コンソール。WriteLine(“”URL:{リンク.GetAttribute(“href”)}ステータスは次のとおりです。{response。StatusCode}”);5. ステータスコード
を介してリンクを検証する場合は、HTTP応答コード(つまり、応答。ステップ(4)で送信されたHTTP要求のStatusCode)はHttpStatusCodeです。OK(すなわち、200)、それは要求が正常に完了したことを意味します。
123456789システム。Console.WriteLine($”URL: {link.GetAttribute(“href”)} status is :{response.StatusCode}”);if (response.StatusCode == HttpStatusCode.OK){valid_links++;}else{broken_links++;}NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
12345678catch (Exception ex){if ((ex is ArgumentNullException) ||(ex is NotSupportedException)){System.Console.WriteLine(“Exception occured\n”);}}Execution
テストが正常に実行されたことを示す実行スナップショットを次に示します。Selenium webdriverのテスト実行
「共有アイコン」へのリンク、つまりWhatsApp、Facebook、Twitterなどで例外が発生しました。
facebook これらのリンクとは別に、LambdaTestブログページの残りのリンクはHttpStatusCodeを返します。OK(すなわち200)。
セレンPHPを使用したリンク切れテスト
実装
コードウォークスルー
1. ページソースを読む
PHPのfile_get_contents関数は、ページのHTMLソースを文字列変数($htmlなど)に読み込むために使用されます。
12$test_url= “https://www.lambdatest.com/blog/”;$html=file_get_contents(test test_url);2. DOMDocumentクラスのインスタンス化
PHPのDOMDocumentクラスは、HTMLドキュメント全体を表し、ドキュメントツリーのルートとして機能します。
1$htmlDom=新しいDOMDocument;3. ページ
のHTMLを解析するDOMDocument::loadHTML()関数は、HTML htmlに含まれているHTMLソースを解析するために使用されます。 実行に成功すると、関数はDOMDocumentオブジェクトを返します。
1@$htmlDom->loadHTML(html html);4. ページからのリンクの抽出
ページ上に存在するリンクは、DOMDocumentクラスのgetElementsByTagNameメソッドを使用して抽出されます。 要素(またはリンク)は、解析されたHTMLソースからの’a’タグに基づいて検索されます。
getElementsByTagName関数は、ローカルタグ名の要素(またはリンク)を含むDOMNodeListの新しいインスタンスを返します。 タグ)
1$リンク=$htmlDom->getElementsByTagName(‘a’);5. 検証のためのUrlを反復処理する
ステップ(4)で作成されたDOMNodeListは、リンクの有効性をチェックするためにトラバースされます。
123foreach($link as link link){$linkText=link link->nodeValue;対応するリンクの詳細は、’href’属性を使用して取得されます。 GetAttributeメソッドは、同じために使用されます。
1$linkHref=$link->getAttribute(‘href’);次の場合、リンクのチェックをスキップします。
a.リンクが空です
1234if(strlen(trim(trim linkHref)) == 0){続きを読む;}b. リンクはハッシュタグまたはアンカーリンクです
1234if(link linkHref== ‘#’){続きを読む;}c.リンクにはmailtoまたはaddtoany(ソーシャル共有オプション)が含まれています。
123456789101112131415161718192021222324252627282930function check_nonlinks($test_url, $test_pattern){if(preg_match(pre test_pattern,$test_url)==false){falseを返す;}その他{trueを返す;}}パブリック関数test_broken_links(){$pattern_1=’/\baddtoany\b/’;$pattern_2=’/\bmailto\b/’;…………………………………………………………..…………………………………………………………..…………………………………………………………..if((check_nonlinks(link linkHref,pat pattern_1))||(check_nonlinks(check linkHref,$pattern_2))//(check_nonlinks($linkHref,$pattern_2))//(check_nonlinks($linkHref,$pattern_2))))){print(“\nadd_to_anyまたはメールが発生しました”);continue;}…………………………………………………………..…………………………………………………………..…………………………………………………………..}preg_match関数は、mailtoとaddtoanyの大文字と小文字を区別しない検索を実行するために正規表現(regex)を使用します。 Mailto&addtoanyの正規表現は、それぞれ’/\bmailto\b/’&’/\baddtoany\b/’です。
6. CURL
を使用してHTTPコードを検証します。curlを使用して、対応するリンクのステータスに関する情報を取得します。 最初のステップは、検証を行う必要がある「リンク」を使用してcURLセッションを初期化することです。 このメソッドは、実装の後半で使用されるcURLインスタンスを返します。
1$curl=curl_init(link linkHref);curl_setoptメソッドは、指定されたcURLセッションハンドル(つまり$curl)のオプションを設定するために使用されます。
1curl_setopt(curl curl,CURLOPT_NOBODY,true);指定されたcURLセッションの実行のためにcurl_execメソッドが呼び出されます。 成功した実行時にTrueを返します。
1$結果=curl_exec(curl curl);これは、ページ上のリンク切れをチェックするロジックの最も重要な部分です。 CURLセッションハンドル($curl)とCURLINFO_RESPONSE_CODE(i curl)を取得するcurl_getinfo関数(cur curl)は、次のように定義されています。 CURLINFO_HTTP_CODE)は、最後の転送に関する情報を取得するために使用されます。 応答でHTTPステータスコードを返します。
1$statusCode=curl_getinfo(curl curl,CURLINFO_HTTP_CODE);リクエストが正常に完了すると、HTTPステータスコード200が返され、有効なリンク数を保持する変数(つまり、$valid_links)が増分されます。 HTTPステータスコードが400(またはそれ以上)になるリンクについては、「テスト中のリンク」がLambdaTestのLinkedInページであった場合にチェックが実行されます。 前述したように、LinkedInページのステータスコードは999になります。
HTTPステータスコードが400(またはそれ以上)を返した他のすべてのリンクについては、壊れたリンク数を保持する変数(つまり、$broken_links)が増分されます。
12345678910if((link linkedin_page_status)&&(stat statusCode== 999)){print(“\nLink”. ├リンク集 “のページとステータスが表示されています。stat statusCode);$validlinks++;}その他{print(“\nLink”. ├リンク集 “リンク切れでステータスが”です。$statusCode);++;}実行
私たちは、ページ上の壊れたリンクのテストのためにPHPUnitフレームワークを使用しています。 PHPUnitフレームワークをダウンロードするには、file composerを追加します。ルートフォルダ内のjsonと端末上でcomposer requireを実行します。
端末で次のコマンドを実行して、Selenium PHPの壊れたリンクを確認します。
1vendor\bin\phpunit tests\BrokenLinksTest.phpここでは、LambdaTestブログ上の116の有効なリンクと0の壊れたリンクの合計を示す実行スナップショットです。 ソーシャル共有のリンク(つまり、addtoany)と電子メールアドレスは無視されるため、合計数は116(Selenium Pythonテストでは169)です。
結論

ソース 壊れたリンクは、デッドリンクまたは腐敗リンクとも呼ばれ、ウェブサイト上に存在する場合、ユーザーエクスペリエンスを妨げる可能性があります。 壊れたリンクはまた調査エンジンのランキングに影響を与えることができる。 それ故に、壊れたリンクテストはウェブサイトの開発およびテストと関連している活動のために周期的に運ばれるべきである。
ウェブサイト上の壊れたリンクをチェックするためのサードパーティのツールや手動の方法に頼るのではなく、Java、Python、C#、またはPHPでSelenium WebDriverを使用して壊れたリン Webページにアクセスするときに返されるHTTPステータスコードは、Seleniumフレームワークを使用して壊れたリンクをチェックするために使用する必要があります。
よくある質問
selenium Pythonで壊れたリンクを見つけるにはどうすればよいですか?
壊れたリンクを確認するには、タグに基づいてwebページ内のすべてのリンクを収集する必要があります。 次に、リンクのHTTP要求を送信し、HTTP応答コードを読み取ります。 HTTP応答コードに基づいて、リンクが有効か壊れているかを確認します。
壊れたリンクを確認するにはどうすればよいですか?
Google Search Consoleを使用してサイトのリンク切れを継続的に監視するには、次の手順に従います:
- Google Search Consoleアカウントにログインします。
- 監視するサイトをクリックします。
- “クロール”をクリックし、”Googleとして取得”をクリックします。
- Googleがサイトをクロールした後、結果にアクセスするには、[クロール]をクリックし、[クロールエラー]をクリックします。
- urlエラーの下に、クロールプロセス中にGoogleが発見した壊れたリンクが表示されます。
seleniumを使用してweb上で壊れた画像を見つけるにはどうすればよいですか?
HTTPアーカイブ内の各イメージを反復処理し、404ステータスコードがあるかどうかを確認します。 壊れた各画像をコレクションに保存します。 壊れた画像コレクションが空であることを確認します。
seleniumですべてのリンクを取得するにはどうすればよいですか?
あなたは、<に基づいて、webページ上に存在するすべてのリンクを取得することができます>タグの存在。 各<a>タグはリンクを表します。 Seleniumロケータを使用して、そのようなすべてのタグを簡単に検索します。
壊れたリンクが悪いのはなぜですか?
ユーザーがリンクをクリックして行き止まりの404エラーに達すると、イライラして戻ってこない可能性があります。 彼らはあなたのSEOの努力を切り下げる-壊れたリンクはあなたの場所中のリンク公平の流れを制限し、ランキングに否定的に影響を与える。
Himanshu Sheth
Himanshu Shethは、15年以上の多様な実務経験を持つベテランの技術者とブロガーです。 彼は現在、LambdaTestで”リード開発者エバンジェリスト”と”シニアマネージャー”として働いています。 彼はベンガルール(そして南)のスタートアップコミュニティと非常に活発であり、彼の個人的なブログ(彼は最後の15+年以来維持されている)で情熱的な発
