




重複したコンテンツをチェックする方法
重複したコンテンツを見つける方法
重複したコンテンツは、検索エンジンがクエリのランク付けするバージョンを決定することが困難になる可能性があるため、ウェブサイト全体で最小限に抑える必要があります。
“重複したコンテンツのペナルティ”はSEOの神話ですが、非常に類似したコンテンツは、クロールの非効率性を引き起こし、PageRankを希釈し、統合、削除、または改善される可能性のあるコンテンツの兆候となる可能性があります。
重複したコンテンツや類似したコンテンツはウェブの自然な部分であり、設計上、Urlを正規化し、必要に応じてフィルタリングする検索エンジンに しかし、大規模では、より問題になる可能性があります。
重複したコンテンツを防ぐことで、検索エンジンに任せるのではなく、インデックスとランク付けの内容を制御できます。 クロール予算の無駄を制限し、インデックス作成とリンク信号を統合してランキングに役立てることができます。
このチュートリアルでは、Screaming Frog SEO Spiderを使用して、正確な重複コンテンツと、webサイト上のページ間でテキストが一致するほぼ重複コンテンツの両方を見つ
SEO Spiderを含む任意のツールによって識別された重複コンテンツは、コンテキストで確認する必要があります。 私たちのビデオを見るか、以下のガイドを読み続けてください。
開始するには、500までのUrlをクロールするための無料ですSEOのスパイダーをダウンロードしてくださ 最初の2つのステップは、ライセンスでのみ利用可能です。 無料のユーザーの場合は、ガイドの番号3にスキップしてください。
1)’Config>Content>Duplicates’
を介して’Near Duplicates’を有効にするデフォルトでは、SEOスパイダーは正確な重複ページを自動的に識別します。 ただし、「重複の近く」を識別するには、各ページのコンテンツを保存できるようにする構成を有効にする必要があります。
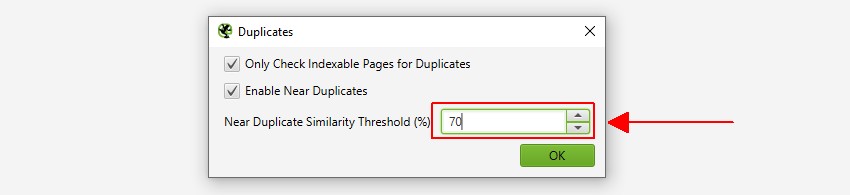
SEO Spiderは、類似度が90%一致する近くの重複を識別し、類似度のしきい値が低いコンテンツを検索するように調整できます。
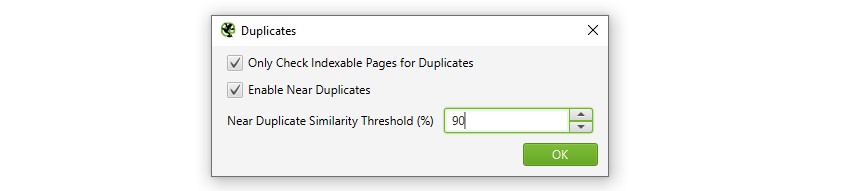
SEO Spiderは、重複のための”インデックス可能な”ページのみをチェックします(正確かつ重複に近い両方のために)。
これは、同じ二つのUrlがあるが、一方が他方に正規化されている(したがって’インデックスなし’)場合、このオプションが無効になっていない限り、これは報告されないことを意味します。
クロール予算の問題を見つけることに興味がある場合は、クロールの無駄の可能性のある領域を見つけるのに役立つため、”重複のインデックス可能なペー
2)’Config>Content>Area’
で分析のために’Content Area’を調整する重複した分析に使用するコンテンツを設定することができます。 新しいクロールの場合は、既定の設定を使用し、分析で使用されたコンテンツを確認し、検討できるようになったら、後で調整することをお勧めします。
SEO Spiderは、nav要素とfooter要素の両方を自動的に除外して、本体コンテンツに焦点を当てます。 ただし、すべてのwebサイトがこれらのHTML5要素を使用して構築されているわけではないため、必要に応じて分析に使用されるコンテンツ領域を精 分析にHTMLタグ、クラス、およびIdを「含める」または「除外」することができます。
たとえば、Screaming Frog webサイトにはnav要素の外側にモバイルメニューがあり、これはデフォルトでコンテンツ分析に含まれています。 これはあまり問題ではありませんが、この場合、ページの本文テキストに焦点を当てるために、クラス名’mobile-menu__dropdown’を’Exclude Classes’ボックスに入力できます。
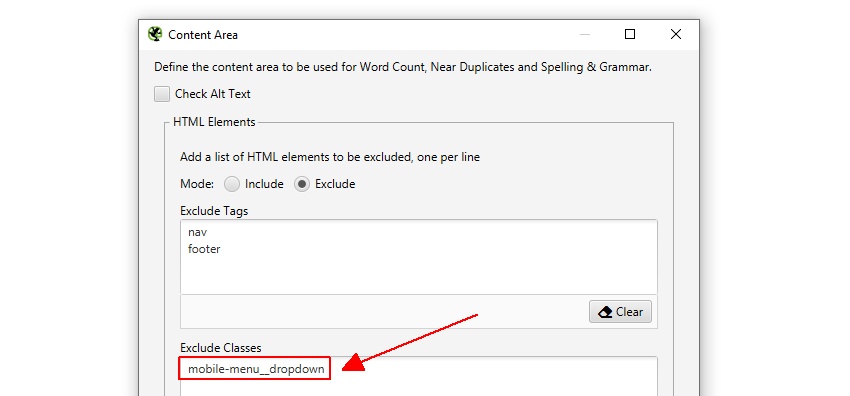
これにより、メニューが重複コンテンツ分析アルゴリズムに含まれないようになります。 これについては後で詳しく説明します。
3)ウェブサイトをクロール
SEOスパイダーを開き、”スパイダーにURLを入力”ボックスにクロールしたいウェブサイトに入力またはコピーし、”スタート”を押します。
クロールが終了して100%に達するまで待ちますが、一部の詳細をリアルタイムで表示することもできます。
4)”コンテンツ”タブで重複を表示
コンテンツタブには、重複したコンテンツに関連する2つのフィルタ、”正確な重複”と”重複の近く”があります。
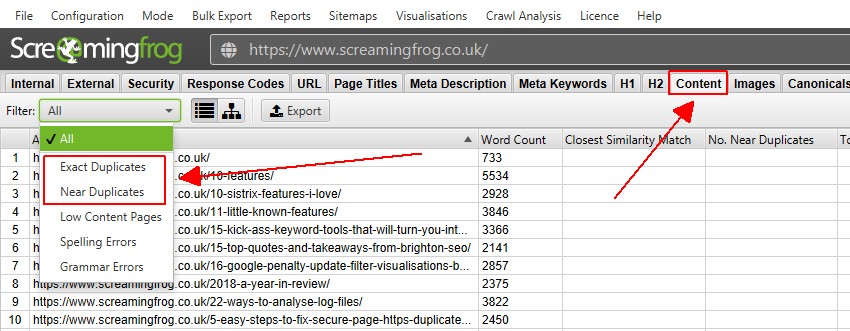
クロール中にリアルタイムで表示できるのは、”正確な重複”のみです。 ‘Near Duplicates’は、データを入力するためにpost’Crawl Analysis’を介してクロールの最後に計算する必要があります。
右側の”概要”ペインには、クロール分析後にデータを入力する必要があるフィルターに対して”(クロール分析が必要)”というメッセージが表示されます。
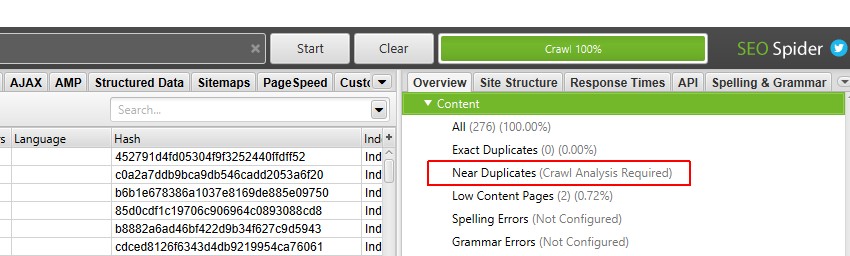
5)”クロール分析>開始”をクリックして”重複近傍”フィルタを設定します
“重複近傍”フィルタ、”最も近い類似性一致”および”いいえ”を設定します。 重複の列の近くでは、クロールの最後にあるボタンをクリックするだけです。

ただし、以前に”クロール分析”を構成している場合は、”クロール分析>構成”で”重複近傍”がチェックされていることを再確認すること
この手順をより迅速にするために、クロール後の分析が必要な他の項目のチェックを外すこともできます。
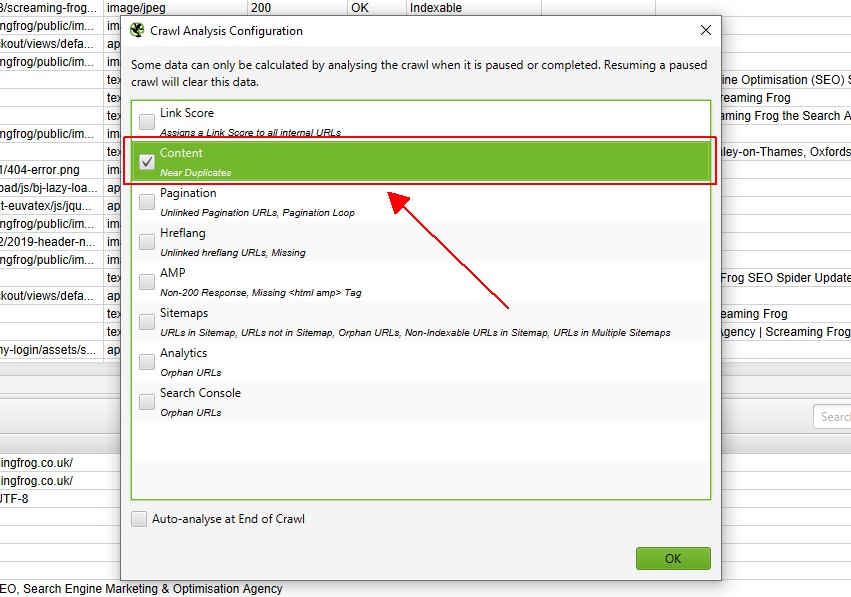
クロール分析が完了すると、”分析”プログレスバーは100%になり、フィルターには”(クロール分析が必要)”というメッセージがなくなります。
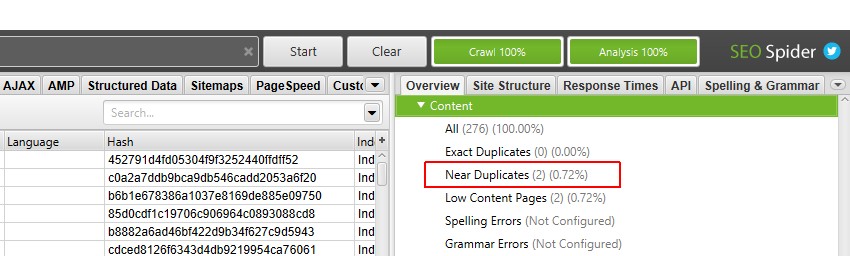
移入された重複近傍フィルタと列を表示できるようになりました。
6)’Content’タブを表示&’Exact’&’Near’重複フィルタ
ポストクロール分析を実行した後、’Near Duplicates’フィルタ、’Closest Similarity Match’および’No. Near Duplicatesの列が入力されます。 選択した類似度のしきい値を超えるコンテンツを持つUrlのみがデータを含み、他のUrlは空白のままです。 この場合、Screaming Frogのウェブサイトには2つしかありません。
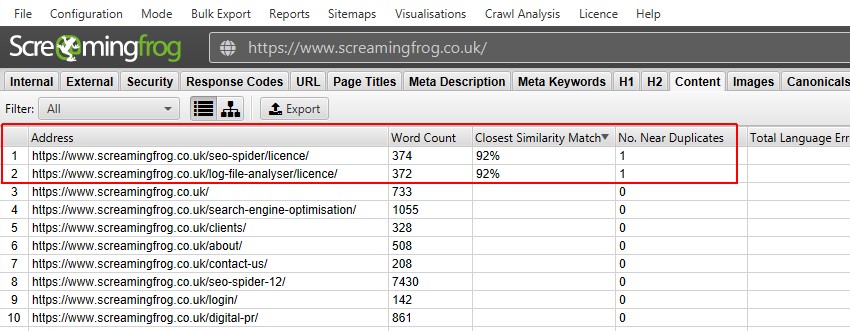
BBCのような大規模なウェブサイトをクロールすると、さらに多くのことが明らかになります。
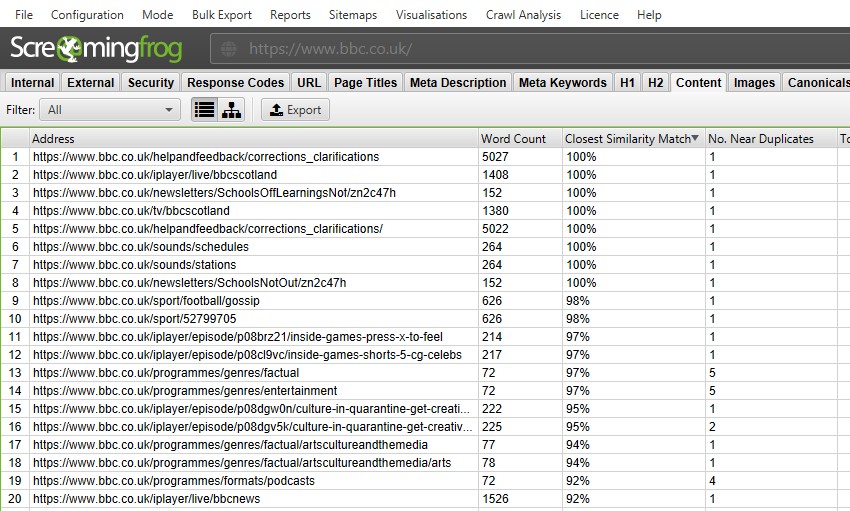
あなたは次のようにフィルタリングすることができます–
- 正確な重複–このフィルタは、各ページの’hash’値を計算し、’hash’列に見ることができるMD5アルゴリズムを使用して、互いに同一のページを表示します。 このチェックは、ページの完全なHTMLに対して実行されます。 まったく同じハッシュ値が一致するすべてのページが表示されます。 正確な重複したページは、ランキングでPageRank信号と予測不可能性の分割につながることができます。 存在し、内部的にリンクされているURLの単一の正規バージョンのみが存在する必要があります。 他のバージョンはリンクしてはならず、正規バージョンに301リダイレクトする必要があります。
- Near Duplicates–このフィルタは、minhashアルゴリズムを使用して設定された類似したしきい値に基づいて類似ページを表示します。 しきい値は’Config>Spider>Content’で調整でき、デフォルトでは90%に設定されています。 “最も近い類似性の一致”列には、別のページとの類似性の割合が最も高いことが表示されます。 “いいえ。 “重複の近く”列には、類似度のしきい値に基づいて、ページに類似しているページの数が表示されます。 このアルゴリズムは、正確な重複のような完全なHTMLではなく、ページ上のテキストに対して実行されます。 この分析に使用されるコンテンツは、「Config>Content>Area」で設定できます。 ページは100%の類似性を持つことができますが、正確な重複ではなく”近くの重複”のみになります。 これは、正確な重複が二度フラグが立てられるのを避けるために、近くの重複として除外されるためです。 類似度スコアも四捨五入されるため、99.5%以上は100%として表示されます。
特定の属性の周りに検索ボリュームを持つ製品のバリエーションなど、一部のページがコンテンツが非常に似ている正当な理由が多いため、重複ページの近くには手動でレビューする必要があります。
しかし、重複に近いとフラグが設定されたUrlは、ユーザーにとって一意の値のために別々のページとして存在する必要があるかどうか、またはコンテンツをよ
7)”重複詳細”タブで重複Urlを表示
“正確な重複”の場合、フィルタを使用してトップウィンドウでそれらを表示する方が簡単です。
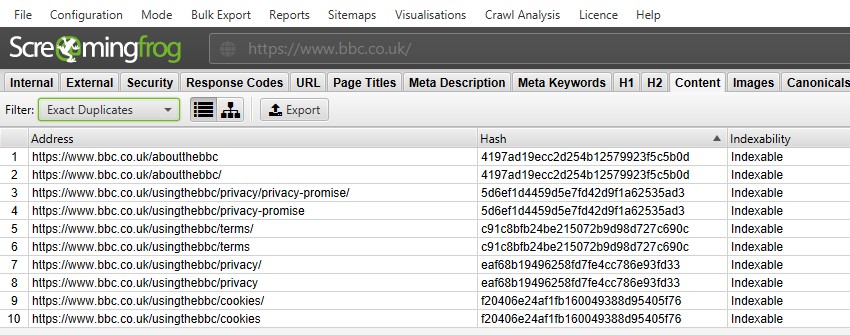
上のスクリーンショットでは、末尾のスラッシュと非末尾のスラッシュバージョンのために、各URLに対応する正確な重複があります。
“重複の近く”の場合は、下部の”重複の詳細”タブをクリックして、下部のウィンドウペインに”重複の近くのアドレス”と検出された各重複URLの類似性を設定します。
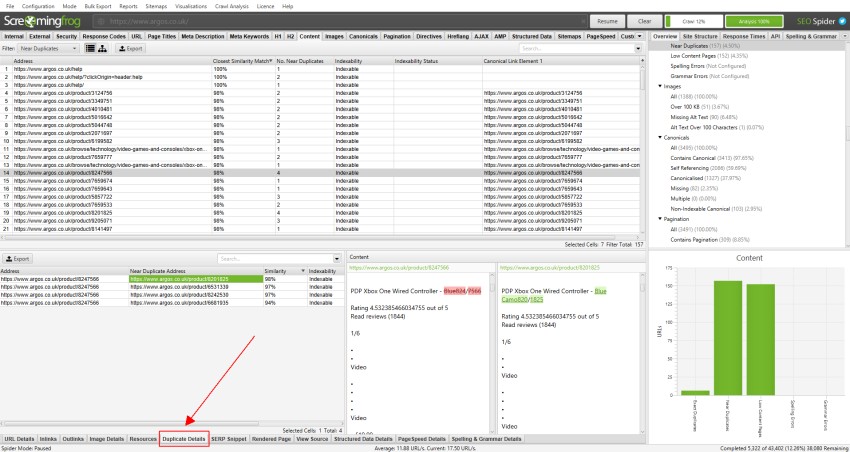
たとえば、トップウィンドウでURLに対して4つの重複に近いものが検出された場合、これらはすべて表示できます。
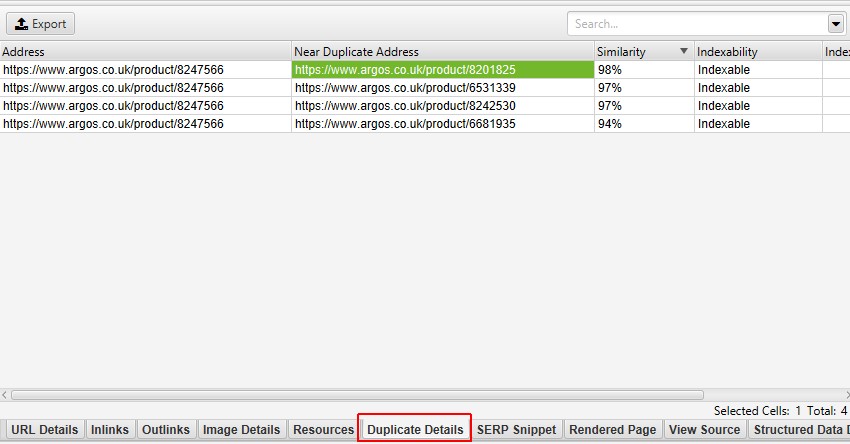
“重複詳細”タブの右側には、ページから検出された近くの重複コンテンツが表示され、各”近くの重複アドレス”をクリックすると、ページ間の違いが強調表示されます。
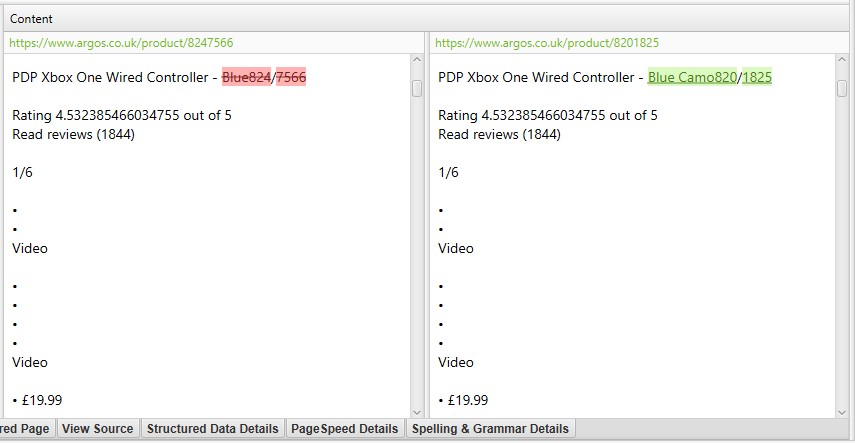
重複コンテンツ分析の一部になりたくない重複コンテンツが重複詳細タブにある場合は、HTML要素、クラス、またはId(ポイント2で強調表示されているように)を除外または含め、&クロール分析を再実行します。
8)重複の一括エクスポート
‘一括エクスポート>コンテンツ>正確な重複’および’重複の近く’エクスポートを使用して、正確な重複とほぼ重複の両方を一括でエクスポートすることができます。

最後のヒント! 類似度しきい値の絞り込み&コンテンツエリア、&クロール分析の再実行
クロール後重複に近い類似度しきい値と、重複に近い分析に使用されるコン
その後、クロール分析を再度実行して、webサイトを再クロールすることなく、多かれ少なかれ類似したコンテンツを検索できます。
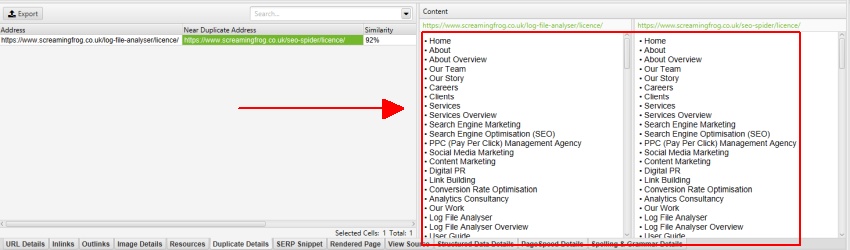
前述のように、Screaming Frogのウェブサイトにはnav要素の外側にモバイルメニューがあり、これはデフォルトでコンテンツ分析に含まれています。 モバイルメニューは、”詳細の複製”タブのコンテンツプレビューで見ることができます。
“Config>Content>Area”の”Exclude Classes”ボックスの”mobile-menu__dropdown”を除外すると、モバイルメニューはコンテンツプレビューおよびnear-duplicate analysisから削除されます。
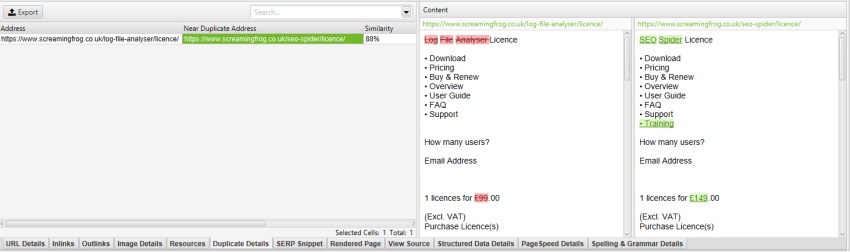
これは、再クロールすることなく、ほぼ重複したコンテンツの識別をメインコンテンツ領域に微調整するときに本当に役立ちます。
概要
上記のガイドは、あなたのウェブサイトの重複コンテンツチェッカーとしてSEOスパイダーを使用する方法を説明する必要があります。 最も正確な結果を得るには、分析のためにコンテンツ領域を調整し、異なるページグループのしきい値を調整します。
ツールの詳細については、Screaming Frog SEO SpiderのFaqと完全なユーザーガイドもお読みください。
SEO Spiderの重複コンテンツツールを改善するための質問、フィードバック、提案があれば、サポートから連絡を取るだけです。