




Hogyan ellenőrizzük a duplikált tartalmat
Hogyan keressünk duplikált tartalmat
A duplikált tartalmat minimálisra kell csökkenteni egy webhelyen, mivel ez megnehezítheti a keresőmotorok számára annak eldöntését, hogy melyik verziót rangsorolják egy lekérdezéshez.
míg a duplikált tartalom büntetése mítosz a SEO-ban, a nagyon hasonló tartalom a feltérképezés hatékonyságát eredményezheti, felhígíthatja a Pagerankot, és olyan tartalom jele lehet, amely konszolidálható, eltávolítható vagy javítható.
érdemes megjegyezni, hogy a duplikált és hasonló tartalom a web természetes része, ami gyakran nem jelent problémát a keresőmotorok számára, akik szándékosan kanonizálják az URL-eket, és szükség esetén szűrik őket. A skála azonban problémásabb lehet.
a duplikált tartalom megakadályozása lehetővé teszi az indexelt és rangsorolt tartalom ellenőrzését – ahelyett, hogy a keresőmotorokra bízná. Korlátozhatja a feltérképezési költségvetési pazarlást, és megszilárdíthatja az indexelést és a jelek összekapcsolását a rangsorolás elősegítése érdekében.
ez az oktatóanyag végigvezeti Önt, hogyan használhatja a Screaming Frog SEO Spider-t mind a pontos duplikált tartalom, mind a Közel duplikált tartalom megtalálásához, ahol néhány szöveg megegyezik a webhely oldalai között.
bármely eszköz által azonosított duplikált tartalmat, beleértve a SEO Spidert is, kontextusban felül kell vizsgálni. Nézze meg videónkat, vagy olvassa tovább az alábbi útmutatót.
az induláshoz töltse le a SEO Spider-t, amely ingyenes akár 500 url feltérképezéséhez. Az első 2 lépés csak licenccel érhető el. Ha ingyenes Felhasználó vagy, akkor ugorjon a 3.számra az útmutatóban.
1) engedélyezze a ‘Közel másolatokat’ keresztül ‘Config > tartalom > másolatok’
alapértelmezés szerint a SEO Spider automatikusan azonosítja a pontos duplikált oldalakat. A ‘közeli másolatok’ azonosításához azonban engedélyezni kell a konfigurációt, amely lehetővé teszi az egyes oldalak tartalmának tárolását.
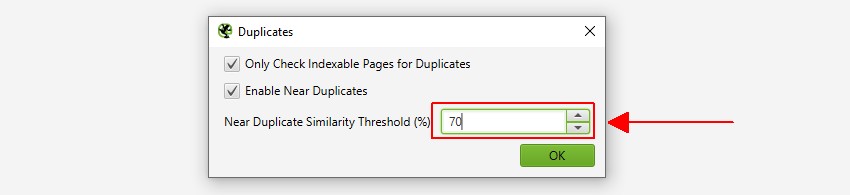
a SEO Spider 90% – os hasonlósági egyezéssel azonosítja a közeli másolatokat, amelyeket úgy lehet beállítani, hogy alacsonyabb hasonlósági küszöbértékű tartalmat találjanak.
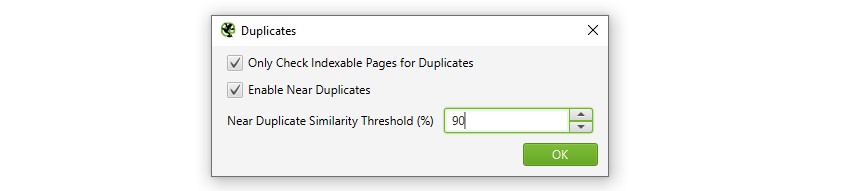
a SEO Spider szintén csak az ‘indexelhető’ oldalakat ellenőrzi ismétlődések után (mind a pontos, mind a közeli másolatok után).
ez azt jelenti, hogy ha két azonos URL-je van, de az egyik kanonizált a másikhoz (ezért nem indexelhető), akkor ez nem jelenik meg – kivéve, ha ez az opció le van tiltva.
ha érdeklik a feltérképezési költségkerettel kapcsolatos problémák, akkor szüntesse meg a ‘csak indexelhető oldalak ellenőrzése Duplikátumok esetén’ opciót, mivel ez segíthet megtalálni a feltérképezési hulladék területeit.
2) Állítsa be a ‘Content Area’ elemet az elemzéshez a ‘Config > Content > Area’
segítségével beállíthatja a Közel duplikált elemzéshez használt tartalmat. Új feltérképezéshez javasoljuk az alapértelmezett beállítás használatát, majd később finomítani, amikor az elemzésben használt tartalom látható és figyelembe vehető.
a SEO Spider automatikusan kizárja mind a nav, mind a lábléc elemeket, hogy a törzs fő tartalmára összpontosítson. Azonban nem minden webhely épül fel ezekkel a HTML5 elemekkel, így szükség esetén finomíthatja az elemzéshez használt tartalmi területet. Választhat, hogy’ tartalmazza ‘vagy’ kizárja ‘ HTML-címkéket, osztályokat és azonosítókat az elemzésben.
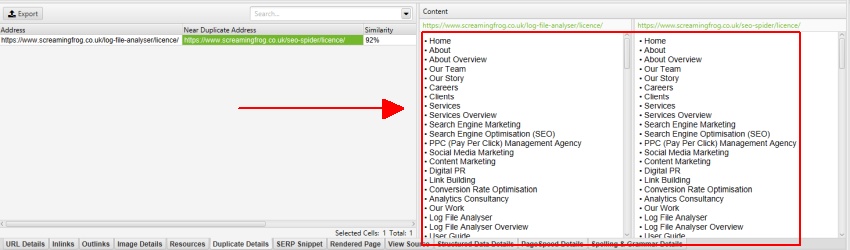
például a Screaming Frog webhelynek van egy mobil menüje a nav elemen kívül, amely alapértelmezés szerint a tartalomelemzésben szerepel. Bár ez nem nagy probléma, ebben az esetben az oldal fő törzsszövegére való összpontosítás érdekében az osztály neve ‘mobile-menu__dropdown’ beírható az ‘Exclude Classes’ mezőbe.
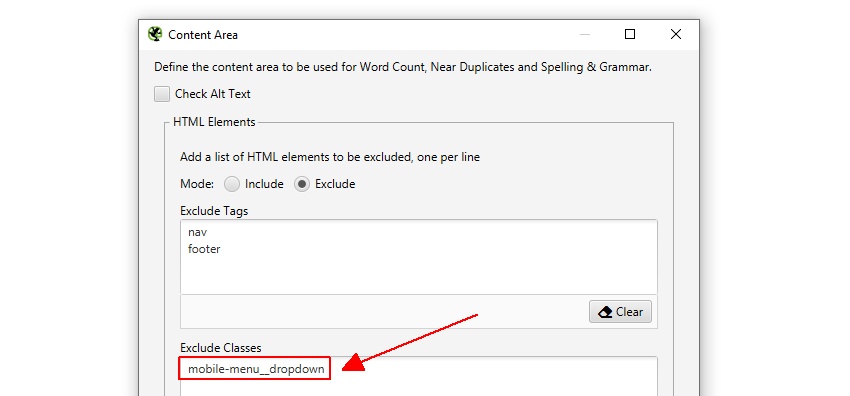
ez kizárja, hogy a menü szerepeljen a duplikált tartalomelemző algoritmusban. Erről bővebben később.
3) a weboldal feltérképezése
nyissa meg a SEO Spider-t, írja be vagy másolja be a feltérképezni kívánt webhelyet az ‘enter URL to spider’ mezőbe, majd nyomja meg a ‘Start’gombot.
várjon, amíg a feltérképezés befejeződik, és eléri a 100%-ot, de néhány részletet valós időben is megtekinthet.
4) tekintse meg a másolatokat a ‘Content’ lapon
a Content fül 2 szűrőt tartalmaz a duplikált tartalomhoz, az ‘exact duplicates’ – hez és a ‘near duplicates’ – hez.
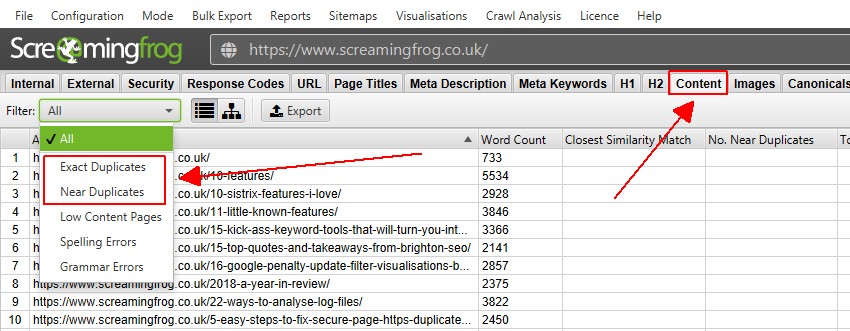
csak a ‘pontos másolatok’ látható valós időben feltérképezés közben. A’ Near Duplicates ‘a feltérképezés végén számítást igényel a feltérképezés utáni elemzésen keresztül, hogy adatokkal töltse fel.
a jobb oldali ‘áttekintés’ ablaktáblán megjelenik egy ‘(feltérképezési elemzés szükséges)’ üzenet azon szűrők ellen, amelyek megkövetelik, hogy a feltérképezés utáni elemzést adatokkal töltsék fel.
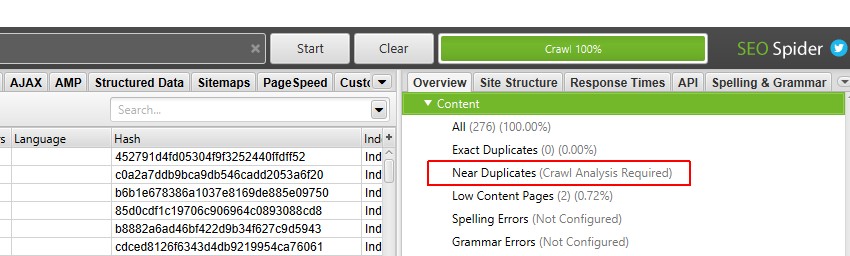
5) kattintson a ‘Crawl Analysis > Start’ gombra a ‘Near Duplicates’ szűrő feltöltéséhez
a ‘Near Duplicates’ szűrő feltöltéséhez, a ‘legközelebbi hasonlósági egyezéshez’ és a ‘No. A Duplikátumok oszlopai közelében csak egy gombra kell kattintania a feltérképezés végén.

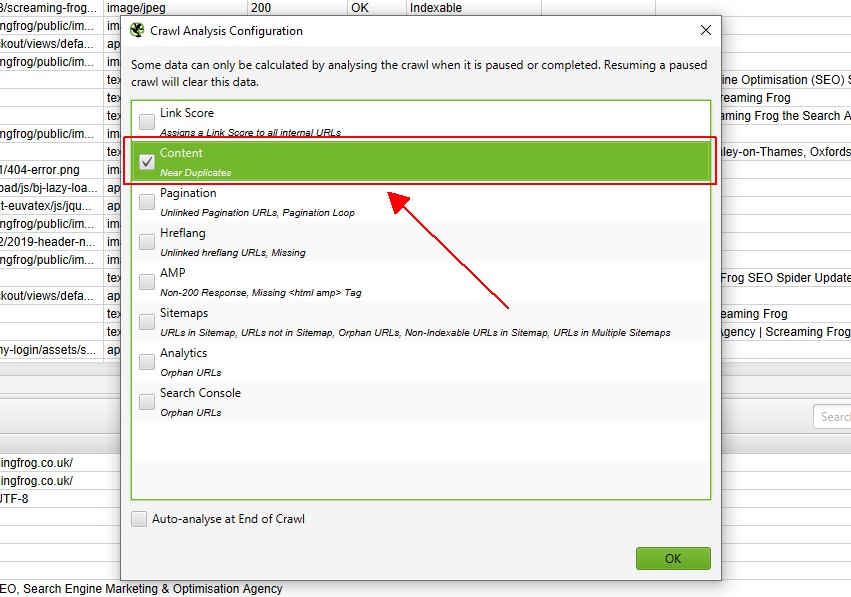
Ha azonban korábban beállította a ‘feltérképezési elemzést’, akkor a ‘feltérképezési elemzés > Konfigurálás’ alatt ellenőrizze, hogy a ‘közeli ismétlődések’ be van-e jelölve.
a lépés gyorsabbá tétele érdekében törölhet más elemeket is, amelyek szintén megkövetelik a feltérképezés utáni elemzést.
a feltérképezési elemzés befejezése után az ‘elemzés’ folyamatjelző sáv 100% – on áll, és a szűrőkön már nem jelenik meg a ‘(feltérképezési elemzés szükséges)’ üzenet.
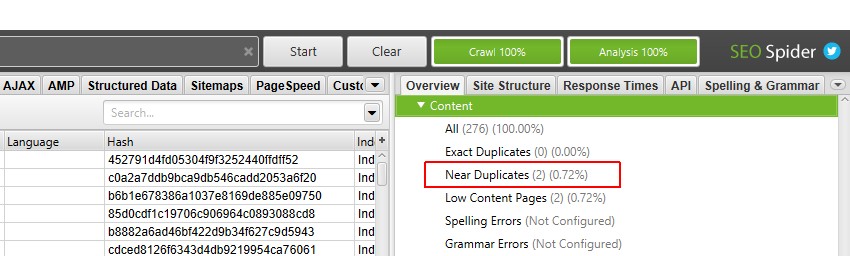
most megtekintheti a lakott közel duplikált szűrő és oszlopok.
6) nézet ‘Content’ fül & ‘Exact’ & ‘Near’ Duplikátumok szűrők
a feltérképezés utáni elemzés elvégzése után a ‘Near Duplikátumok’ szűrő, a ‘legközelebbi hasonlóság’ és a ‘No. A Duplikátumok közelében oszlopok lesznek feltöltve. Csak a kiválasztott hasonlósági küszöböt meghaladó tartalommal rendelkező URL-ek tartalmaznak adatokat, a többi üres marad. Ebben az esetben a Screaming Frog webhelynek csak kettő van.
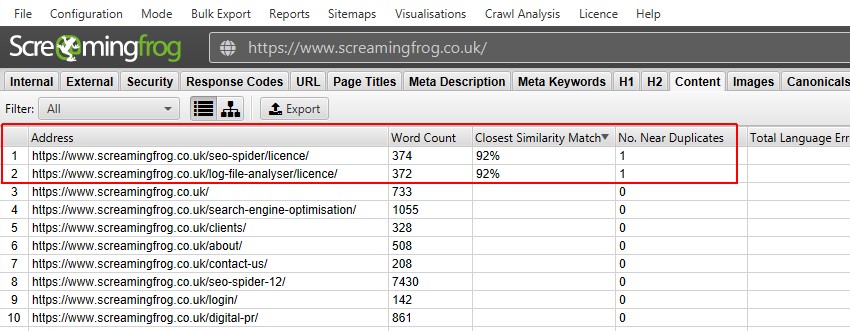
egy nagyobb weboldal, például a BBC feltérképezése sokkal többet fog feltárni.
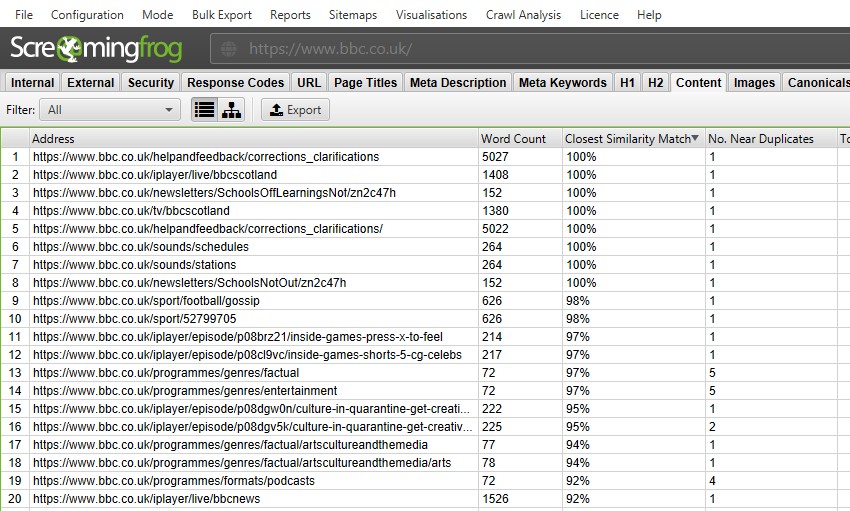
te képes szűrni a következő–
- Exact Duplicates – ez a szűrő az MD5 algoritmus segítségével jeleníti meg az egymással azonos oldalakat, amely minden oldalhoz kiszámítja a ‘hash’ értéket, és a ‘hash’ oszlopban látható. Ez az ellenőrzés az oldal teljes HTML-jével történik. Meg fogja jeleníteni az összes oldalt a megfelelő hash értékekkel, amelyek pontosan ugyanazok. A pontos duplikált oldalak a PageRank jelek felosztásához és a rangsorolás kiszámíthatatlanságához vezethetnek. Az URL-nek csak egyetlen kanonikus változata lehet, amely létezik, és belsőleg kapcsolódik hozzá. Más verziókat nem szabad összekapcsolni, és 301-et kell átirányítani a kanonikus változatra.
- near Duplicates – ez a szűrő hasonló oldalakat jelenít meg a minhash algoritmus által konfigurált hasonlósági küszöb alapján. A küszöbérték a ‘Config > Spider > Content’ alatt állítható be, és alapértelmezés szerint 90% – ban van beállítva. A ‘legközelebbi hasonlósági egyezés’ oszlop a másik oldalhoz való hasonlóság legnagyobb százalékát jeleníti meg. A ‘ Nem. A Near Duplicates oszlop megjeleníti az oldalhoz hasonló oldalak számát a hasonlósági küszöb alapján. Az algoritmus ellen fut szöveget az oldalon, ahelyett, hogy a teljes HTML, mint a pontos másolatok. Az elemzéshez használt tartalom a ‘Config > Content > Area’alatt konfigurálható. Az Oldalak 100% – os hasonlósággal rendelkezhetnek, de csak’ közel duplikáltak ‘ lehetnek, nem pedig pontos duplikáltak. Ennek oka az, hogy a pontos másolatokat kizárják a közeli másolatokként, hogy elkerüljék őket kétszer megjelölve. A hasonlósági pontszámok szintén lekerekítettek, így a 99,5% vagy annál magasabb 100% – ként jelenik meg.
a Közel ismétlődő oldalakat manuálisan kell felülvizsgálni, mivel számos jogos oka van annak, hogy egyes oldalak tartalma nagyon hasonló legyen, például olyan termékek variációi, amelyek Keresési mennyisége az adott attribútum körül van.
a majdnem duplikáltként megjelölt URL-eket azonban felül kell vizsgálni annak mérlegelése érdekében, hogy a felhasználó számára egyedi értékük miatt külön oldalakként kell-e létezniük, vagy el kell-e távolítani, konszolidálni vagy javítani kell-e a tartalom mélyebb és egyedibbé tétele érdekében.
7) tekintse meg az ismétlődő URL – eket a ‘Duplicate Details’ fülön
az ‘exact duplicates’ esetében könnyebb csak a felső ablakban megtekinteni őket a szűrő használatával-mivel csoportosítva vannak, és ugyanazt a ‘hash’ értéket osztják meg.
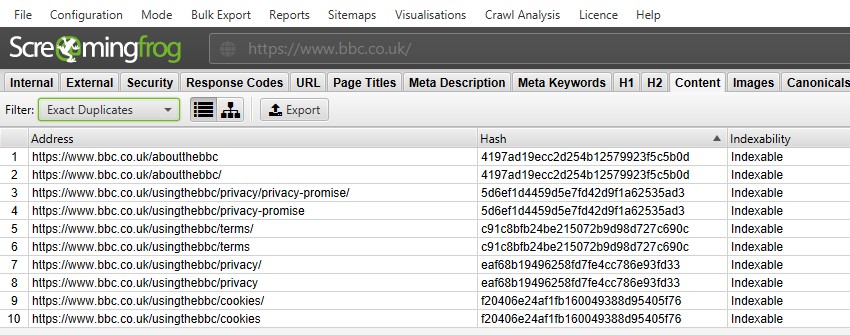
a fenti képernyőképen minden URL-nek van egy megfelelő pontos másolata a záró perjel és a nem záró perjel verzió miatt.
‘közeli másolatok’ esetén kattintson az alján található ‘duplikált Részletek’ fülre, amely az alsó ablaktáblán a ‘Közel duplikált cím’-et és a felfedezett közel duplikált URL-ek hasonlóságát jeleníti meg.
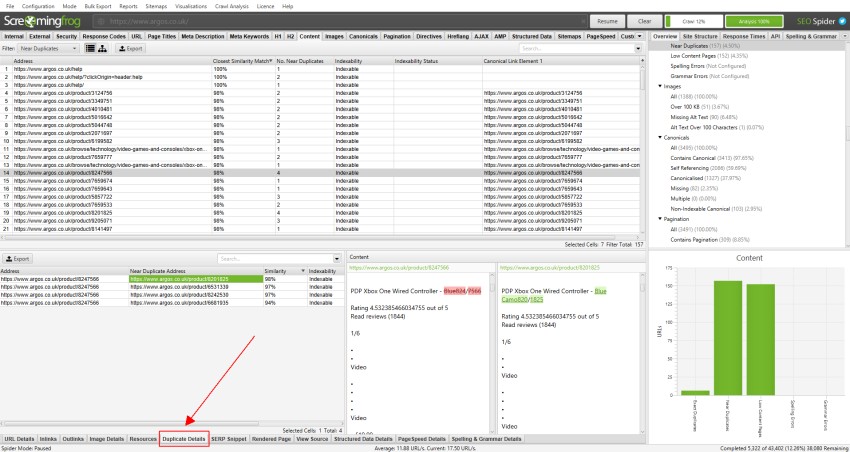
például, ha a felső ablakban 4 közeli duplikátum található egy URL-hez, ezek mind megtekinthetők.
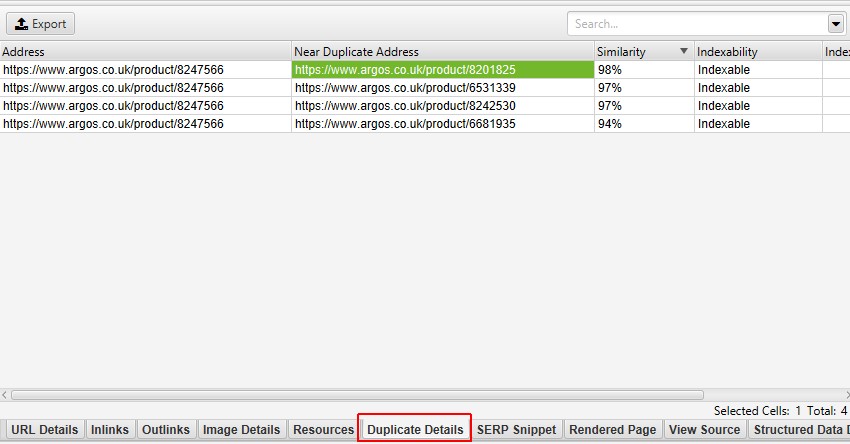
a ‘Duplicate Details’ fül jobb oldalán megjelenik az oldalakon talált majdnem duplikált tartalom, és kiemeli az oldalak közötti különbségeket, amikor az egyes ‘near duplicate address’-re kattint.
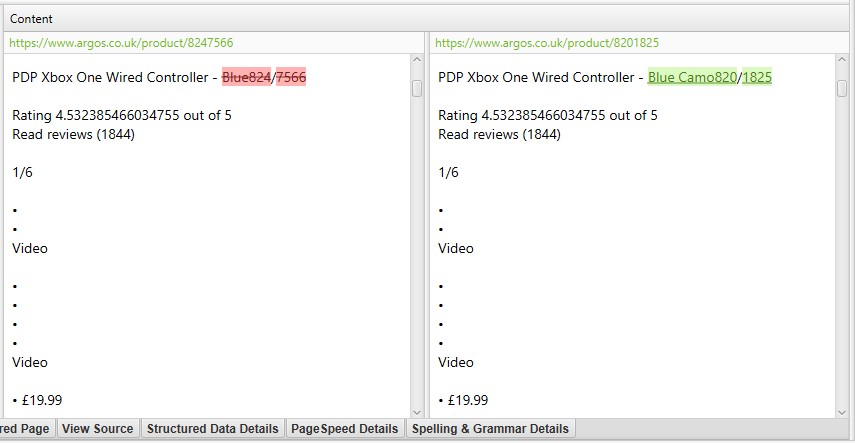
ha a duplicate details lapon olyan duplikált tartalom található, amely nem kíván részt venni a duplicate content analysisben, zárja ki vagy vegye fel a HTML elemeket, osztályokat vagy azonosítókat (a 2.pontban kiemeltek szerint), & futtassa újra a feltérképezési elemzést.
8) tömeges export másolatok
mind a pontos, mind a közeli másolatok ömlesztve exportálhatók a ‘tömeges Exportálás > tartalom > pontos másolatok’ és a ‘közeli másolatok’ exportálás segítségével.

Végső Tipp! A hasonlósági küszöb finomítása & tartalomterület, & feltérképezési elemzés újrafuttatása
feltérképezés után beállíthatja mind a Közel duplikált hasonlósági küszöbértéket, mind a Közel duplikált elemzéshez használt tartalomterületet.
ezután újra futtathatja a feltérképezési elemzést, hogy többé-kevésbé hasonló tartalmat találjon – anélkül, hogy újra feltérképezné a webhelyet.
amint azt korábban felvázoltuk, a Screaming Frog webhelynek van egy mobil menüje a nav elemen kívül, amely alapértelmezés szerint a tartalomelemzésben szerepel. A mobil menü a ‘duplicate details’ fül tartalmi előnézetében látható.
a ‘config > Content > terület’ ‘osztályok kizárása’ mezőjében a ‘mobile-menu__legördülő menü’ kizárásával a mobil menü eltávolításra kerül a tartalom előnézetéből és a Közel duplikált elemzésből.
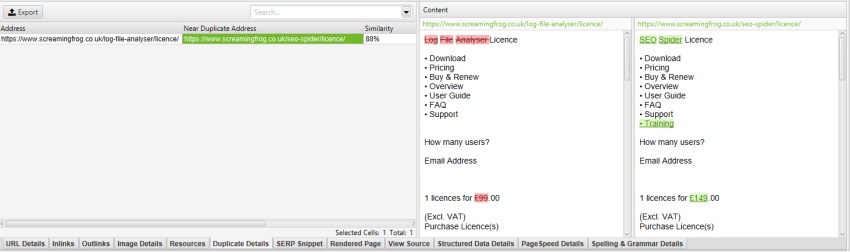
ez tényleg segít, ha finomhangolása azonosításának közel duplicate tartalom fő tartalmi területek, anélkül, hogy újra feltérképezni.
Összegzés
a fenti útmutatónak szemléltetnie kell, hogyan használhatja a SEO Spider-t duplikált tartalom-ellenőrzőként a webhelyén. A legpontosabb eredmények érdekében finomítsa a tartalomterületet elemzésre, és állítsa be a küszöbértéket a különböző oldalcsoportokhoz.
kérjük, olvassa el a Screaming Frog SEO Spider GYIK-et és a teljes felhasználói útmutatót az eszközzel kapcsolatos további információkért.
ha bármilyen további kérdése, visszajelzése vagy javaslata van a duplikált tartalom eszköz javítására a SEO Spiderben, akkor csak vegye fel a kapcsolatot a támogatással.