




Comment Trouver Des Liens Brisés À L’Aide De Selenium WebDriver?
Quelles pensées vous viennent à l’esprit lorsque vous rencontrez des liens hypertextes 404 / Page Introuvable / Morte sur un site Web? Aargh! Vous trouverez cela ennuyeux lorsque vous rencontrez des liens hypertextes brisés, ce qui est la seule raison pour laquelle vous devriez vous concentrer continuellement sur la suppression de l’existence de liens brisés dans votre produit Web (ou site Web). Au lieu d’une inspection manuelle, vous pouvez tirer parti de l’automatisation pour les tests de liens rompus à l’aide de Selenium WebDriver.

Lorsqu’un lien particulier est rompu et qu’un visiteur atterrit sur la page, cela affecte la fonctionnalité de cette page et entraîne une mauvaise expérience utilisateur. Les liens morts pourraient nuire à la crédibilité de votre produit, car cela « pourrait » donner l’impression à vos visiteurs qu’il y a un minimum d’attention sur l’expérience.
Si votre produit Web comporte de nombreuses pages (ou liens) qui entraînent une erreur 404 (ou une page introuvable), le classement des produits sur les moteurs de recherche (par exemple, Google) sera également gravement affecté. La suppression des liens morts est l’une des parties intégrantes de l’activité SEO (Search Engine Optimization).
Dans cette partie de la série de didacticiels Selenium WebDriver, nous explorons en profondeur la recherche de liens brisés à l’aide de Selenium WebDriver. Nous avons démontré des tests de liens brisés en utilisant Selenium Python, Selenium Java, Selenium C# et Selenium PHP.
Introduction aux liens brisés dans les tests Web
En termes simples, les liens brisés (ou les liens morts) dans un site Web (ou une application Web) sont des liens qui ne sont pas accessibles et ne fonctionnent pas comme prévu. Les liens peuvent être temporairement désactivés en raison de problèmes de serveur ou mal configurés à l’arrière.
En dehors des pages qui entraînent une erreur 404, d’autres exemples importants de liens brisés sont des URL mal formées, des liens vers du contenu (par exemple, documents, pdf, images, etc.) qui ont été déplacés ou supprimés.
Raisons principales des liens brisés
Voici quelques-unes des raisons courantes de l’apparition de liens brisés (liens morts ou pourritures de liens):
- URL incorrecte ou mal orthographiée saisie par l’utilisateur.
- Les modifications structurelles du site Web (c’est-à-dire les permaliens) avec des redirections d’URL ou des redirections internes ne sont pas correctement configurées.
- Liens vers des contenus tels que des vidéos, des documents, etc. qui sont déplacés ou supprimés. Si le contenu est déplacé, les « liens internes » doivent être redirigés vers les liens désignés.
- Temps d’arrêt temporaire du site Web en raison de la maintenance du site rendant le site Web temporairement inaccessible.
- Balises HTML cassées, erreurs JavaScript, personnalisations HTML/CSS incorrectes, éléments intégrés cassés, etc., dans le début de la page, peut conduire à des liens brisés.
- Les restrictions de géolocalisation empêchent l’accès au site Web à partir de certaines adresses IP (si elles sont sur liste noire) ou de pays spécifiques dans le monde. Les tests de géolocalisation avec Selenium permettent de s’assurer que l’expérience est adaptée à l’emplacement (ou au pays) d’où le site est accessible.
Pourquoi devriez-vous vérifier les liens brisés?
Les liens brisés sont un gros frein pour les visiteurs qui atterrissent sur votre site Web. Voici quelques-unes des principales raisons pour lesquelles vous devriez vérifier les liens rompus sur votre site Web:
- Des liens brisés peuvent nuire à l’expérience utilisateur.
- La suppression des liens brisés (ou morts) est essentielle pour le référencement (Optimisation des moteurs de recherche), car elle peut affecter le classement du site sur les moteurs de recherche (par exemple, Google).
Les tests de liens brisés peuvent être effectués à l’aide de Selenium WebDriver sur une page Web, qui peut à son tour être utilisée pour supprimer les liens morts du site.
Liens rompus et codes d’état HTTP
Lorsqu’un utilisateur visite un site Web, une demande est envoyée par le navigateur au serveur du site. Le serveur répond à la demande du navigateur avec un code à trois chiffres appelé » Code d’état HTTP « .’
Un code d’état HTTP est la réponse du serveur à une requête envoyée depuis le navigateur Web. Ces codes d’état HTTP sont considérés comme équivalents à la conversation entre le navigateur (à partir duquel la demande d’URL est envoyée) et le serveur.
Bien que différents codes d’état HTTP soient utilisés à des fins différentes, la plupart des codes sont utiles pour diagnostiquer les problèmes sur le site, minimiser les temps d’arrêt du site, le nombre de liens morts, etc. Le premier chiffre de chaque code d’état à trois chiffres commence par les nombres 1 ~ 5. Les codes d’état sont représentés par 1xx, 2xx.., 5xx pour indiquer les codes d’état dans cette plage particulière. Comme chacune de ces plages se compose d’une classe de réponse de serveur différente, nous limiterions la discussion aux codes d’état HTTP présentés pour les liens rompus.
Voici les classes de code d’état communes qui sont utiles pour détecter les liens rompus avec le sélénium:
| Classes de Code d’état HTTP | Description |
|---|---|
| 1xx | Le serveur réfléchit toujours à la demande. |
| 2xx | La demande envoyée par le navigateur a été complétée avec succès et la réponse attendue a été envoyée au navigateur par le serveur. |
| 3xx | Cela indique qu’une redirection est en cours. Par exemple, la redirection 301 est couramment utilisée pour implémenter des redirections permanentes sur un site Web. |
| 4xx | Cela indique qu’une page particulière (ou un site complet) n’est pas accessible. |
| 5xx | Cela indique que le serveur n’a pas pu compléter la demande, même si une demande valide a été envoyée par le navigateur. |
Codes d’état HTTP présentés lors de la détection de liens brisés
Voici quelques-uns des codes d’état HTTP courants présentés par le serveur Web lors de la rencontre d’un lien brisé:
| Code d’état HTTP | Description |
|---|---|
| 400 ( Mauvaise demande) | Le serveur ne peut pas traiter la demande car l’URL mentionnée est incorrecte. |
| 400 ( Bad Request – Mauvais hôte) | Cela indique que le nom d’hôte n’est pas valide en raison de laquelle la demande ne peut pas être traitée. |
| 400 ( Bad Request – Mauvaise URL) | Cela indique que le serveur ne peut pas traiter la demande car l’URL entrée est mal formée (c.-à-d. crochets manquants, barres obliques, etc.). |
| 400 ( Bad Request–Timeout) | Cela indique que les requêtes HTTP ont expiré. |
| 400 ( Bad Request – Empty) | La réponse renvoyée par le serveur est vide sans contenu ni code de réponse. |
| 400 ( Bad Request -Reset) | Cela indique que le serveur n’est pas en mesure de traiter la demande, car il est occupé à traiter d’autres demandes ou qu’il a été mal configuré par le propriétaire du site. |
| 403 ( Interdit) | Une requête authentique est envoyée au serveur mais il refuse de la remplir, car une autorisation est requise. |
| 404 ( Page non trouvée) | La ressource (ou la page) n’est pas disponible sur le serveur. |
| 408 ( Délai d’attente de la demande) | Le serveur a expiré en attendant la demande. Le client (c’est-à-dire le navigateur) peut envoyer la même demande dans le temps que le serveur est prêt à attendre. |
| 410 ( Gone) | Un Code d’état HTTP plus permanent que 404 (Page introuvable). 410 signifie que la page a disparu. La page n’est ni disponible sur le serveur, ni aucun mécanisme de transfert (ou de redirection) n’a été mis en place. Les liens pointant vers une page 410 envoient les visiteurs vers une ressource morte. |
| 503 ( Service indisponible) | Cela indique que le serveur est temporairement surchargé, ce qui empêche le traitement de la demande. Cela peut également signifier que la maintenance est effectuée sur le serveur, indiquant aux moteurs de recherche les temps d’arrêt temporaires du site. |
Comment Trouver des Liens Brisés À l’aide de Selenium WebDriver?
Quel que soit le langage utilisé avec Selenium WebDriver, les principes directeurs pour les tests de liens rompus utilisant Selenium restent les mêmes. Voici les étapes pour les tests de liens brisés à l’aide de Selenium WebDriver:
- Utilisez la balise pour collecter les détails de tous les liens présents sur la page Web.
- Envoyez une requête HTTP pour chaque lien.
- Vérifier le code de réponse correspondant reçu en réponse à la demande envoyée à l’étape précédente.
- Validez si le lien est rompu ou non en fonction du code de réponse envoyé par le serveur.
- Répétez les étapes (2-4) pour chaque lien présent sur la page.
Dans ce didacticiel Selenium WebDriver, nous démontrons comment effectuer des tests de liens brisés à l’aide de Selenium WebDriver en Python, Java, C# et PHP. Les tests sont effectués sur la combinaison (Chrome 85.0 + Windows 10), et l’exécution est effectuée sur la grille de sélénium basée sur le cloud fournie par LambdaTest.
Pour commencer avec LambdaTest, créez un compte sur la plateforme et notez le nom d’utilisateur & clé d’accès disponible dans la section profil sur LambdaTest. Les capacités du navigateur sont générées à l’aide du générateur de capacités LambdaTest.
Voici le scénario de test utilisé pour trouver des liens cassés sur un site Web utilisant Selenium :
Scénario de test
- Allez sur le blog LambdaTest i.e. https://www.lambdatest.com/blog/ sur Chrome 85.0
- Collectez tous les liens présents sur la page
- Envoyez une requête HTTP pour chaque lien
- Imprimer si le lien est rompu ou non sur le terminal
Il est important de noter que le temps passé dans les tests de liens rompus à l’aide de Sélénium dépend du nombre de liens présents sur la page web testée. »Plus le nombre de liens sur la page est élevé, plus le temps sera consacré à la recherche de liens brisés. Par exemple, LambdaTest a un grand nombre de liens (~ 150 +); par conséquent, le processus de recherche de liens brisés peut prendre un certain temps (environ quelques minutes).

EXÉCUTEZ VOTRE SCRIPT DE TEST SUR SELENIUM GRID
Plus DE 2000 Navigateurs ET Systèmes D’exploitation
INSCRIPTION GRATUITE
Test de lien cassé À L’aide de Selenium Java
Implémentation
PROCÉDURE PAS À PAS du code
1. Importer les paquets requis
Les méthodes du paquet HttpURLConnection sont utilisées pour envoyer des requêtes HTTP et capturer le Code d’état HTTP (ou la réponse).
Les méthodes dans l’expression régulière.Paquet de motifs vérifiez si le lien correspondant contient une adresse e-mail ou un numéro de téléphone en utilisant une syntaxe spécialisée contenue dans un motif.
|
1
2
|
importer java.net.HttpURLConnection;
importer java.util.expression régulière.Modèle;
|
2. Collecter les liens présents sur la page
Les liens présents sur l’URL testée (c’est-à-dire le Blog LambdaTest) sont localisés en utilisant tagname dans Selenium. Le nom de balise utilisé pour l’identification de l’élément (ou du lien) est » a « .
Les liens sont placés dans une liste pour parcourir la liste afin de vérifier les liens brisés sur la page.
|
1
|
Liste < WebElement > liens = pilote.findÉléments (Par.tagName (« a »));
|
3. Parcourir les URL
L’objet Itérateur est utilisé pour parcourir la liste créée à l’étape (2)
|
1
|
Itérateur < WebElement > link= liens.itérateur();
|
4. Identifiez et vérifiez les URL
Une boucle while est exécutée jusqu’à ce que l’itérateur temporel (c’est-à-dire le lien) n’ait plus d’éléments à itérer. Le ‘href’ de la balise d’ancrage est récupéré et le même est stocké dans la variable URL.
|
1
2
3
|
tandis que (lien.hasNext())
{
url = lien.prochain().Obtenir des contributions (« href »);
|
Ignorer la vérification des liens si :
a. Le lien est nul ou vide
|
1
2
3
4
5
|
si ((url == null) //(url.isEmpty()))
{
Système.hors.println(« L’URL n’est pas configurée pour la balise d’ancrage ou elle est vide »);
continuer;
}
|
d. Le lien contient le mailto ou le numéro de téléphone
|
1
2
3
4
5
|
si ((url.startsWith(mail_to)) //(url.Début avec (tel)))
{
Système.hors.println(« Adresse e-mail ou téléphone détecté »);
continuer;
}
|
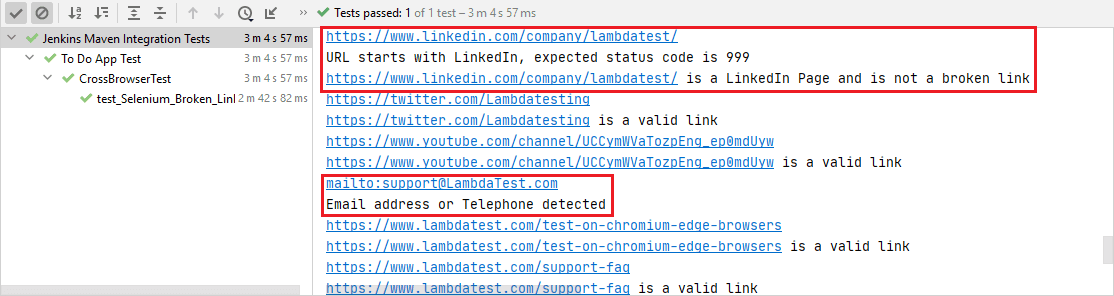
Lors de la vérification de la page LinkedIn, le code d’état HTTP est 999. Une variable booléenne (i.e., LinkedIn) est défini sur true pour indiquer qu’il ne s’agit pas d’un lien rompu.
|
1
2
3
4
5
|
si (url.Début avec (LinkedInPage))
{
Système.hors.println(« L’URL commence par LinkedIn, le code d’état attendu est 999 »);
bLinkedIn = vrai;
}
|
5. Validez les liens via le code d’état
Les méthodes de la classe HttpURLConnection fournissent la provision pour l’envoi de requêtes HTTP et la capture du code d’état HTTP.
La méthode openConnection de la classe URL ouvre la connexion à l’URL spécifiée. Il renvoie une instance URLConnection représentant une connexion à l’objet distant référencé par l’URL. Il est typé en HttpURLConnection.
|
1
2
3
4
5
6
7
|
HttpURLConnection urlconnection = null;
……………………………………….
……………………………………….
……………………………………….
urlconnection =(HttpURLConnection) (nouvelle URL (url).Connexion ouverte());
connexion url.setRequestMethod (« TÊTE »);
|
La méthode setRequestMethod de la classe HttpURLConnection définit la méthode pour la demande d’URL. Le type de requête est défini sur HEAD afin que seuls les en-têtes soient renvoyés. D’un autre côté, le type de requête GET aurait renvoyé le corps du document, ce qui n’est pas requis dans ce scénario de test particulier.
La méthode connect de la classe HttpURLConnection établit la connexion à l’URL et envoie une requête HTTP.
|
1
|
connexion url.connexion();
|
La méthode getResponseCode renvoie le code d’état HTTP de la requête envoyée précédemment.
|
1
|
responseCode = connexion url.getResponseCode();
|
Pour le code d’état HTTP est de 400 (ou plus), la variable contenant le nombre de liens brisés (c.-à-d., broken_links) est incrémentée ; sinon, la variable contenant des liens valides (c.-à-d., valid_links) est incrémentée.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
si (responseCode >= 400)
{
si ((bLinkedIn == true) & & (responseCode == LinkedInStatus))
{
Système.hors.println(url + »est une page LinkedIn et n’est pas un lien brisé »);
valid_links++;
}
autre
{
Système.hors.println(url + »est un lien brisé »);
broken_links++;
}
}
autre
{
Système.hors.println(url + »est un lien valide »);
valid_links++;
}
|
Exécution
Pour les tests de liens brisés à l’aide de Selenium Java, nous avons créé un projet dans IntelliJ IDEA. Le pom de base.le fichier xml était suffisant pour le travail!
Voici l’instantané d’exécution, qui indique 169 liens valides et 0 liens brisés sur la page du blog LambdaTest.
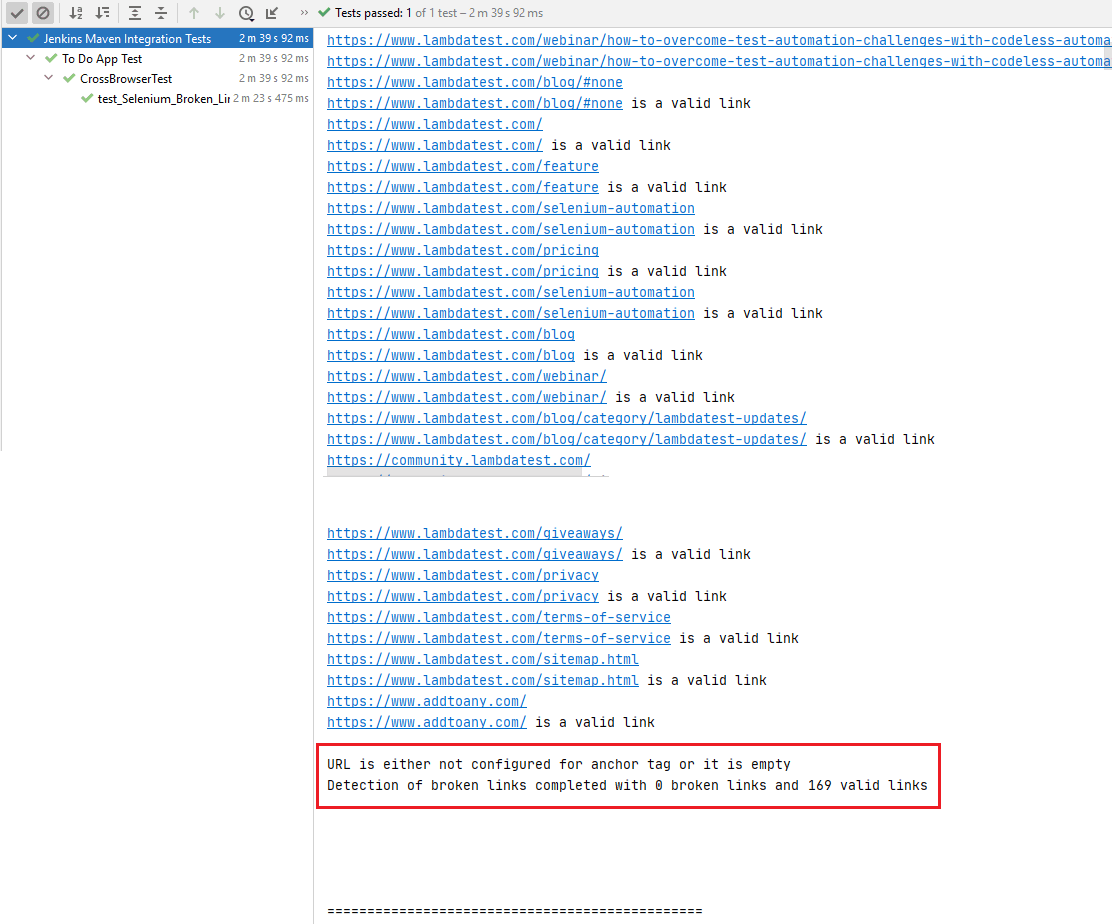
Les liens contenant les adresses e-mail et les numéros de téléphone ont été exclus de la liste de recherche, comme indiqué ci-dessous.
Vous pouvez voir le test en cours d’exécution dans la capture d’écran ci-dessous et se terminer en 2 min 35 secondes, comme indiqué sur les journaux d’automatisation de LambdaTest.

Test de Lien cassé À L’aide De Python Sélénium
Implémentation
Procédure pas À pas Du code
1. Importer des modules
En plus d’importer les modules Python pour Selenium WebDriver, nous importons également le module requests. Le module requêtes vous permet d’envoyer toutes sortes de requêtes HTTP. Il peut également être utilisé pour passer des paramètres dans l’URL, envoyer des en-têtes personnalisés, etc.
|
1
2
3
|
importer des requêtes
importer urllib3
à partir de requêtes.exceptions import MissingSchema, InvalidSchema, InvalidURL
|
2. Collecter les liens présents sur la page
Les liens présents sur l’URL testée (i.e., Blog LambdaTest) sont trouvés en localisant les éléments web par la propriété « a » du sélecteur CSS.
|
1
|
liens = pilote.find_elements (Par.CSS_SÉLECTEUR, « a »)
|
Puisque nous voulons que l’élément soit itérable, nous utilisons la méthode find_elements (et non la méthode find_element).
3. Parcourir les URL pour validation
La méthode head du module requests est utilisée pour envoyer une requête HEAD à l’URL spécifiée. La méthode get_attribute est utilisée sur chaque lien pour obtenir l’attribut ‘href’ de la balise d’ancrage.
La méthode head est principalement utilisée dans les scénarios où seuls les en-têtes status_code ou HTTP sont requis et où le contenu du fichier (ou de l’URL) n’est pas nécessaire. La méthode head renvoie des requêtes.Objet de réponse qui contient également le code d’état HTTP (c’est-à-dire request.code d’état).
|
1
2
3
4
|
pour le lien dans les liens:
essayez:
request=requests.tête (lien.j’ai un problème avec la clé.:’value’})
print (« Statut de » + lien.j’ai essayé de le faire, mais j’ai essayé de le faire.code d’état))
|
Le même ensemble d’opérations est effectué de manière itérative jusqu’à ce que tous les « liens » présents sur la page aient été épuisés.
4. Validez les liens via le Code d’état
Si le code de réponse HTTP pour la requête HTTP envoyée à l’étape (3) est 404 (c’est-à-dire, Page introuvable), cela signifie que le lien est un lien rompu. Pour les liens qui ne sont pas rompus, le code d’état HTTP est 200.
|
1
2
3
4
|
si (demande.code d’état == 404):
broken_links =(broken_links+1)
else:
valid_links =(valid_links + 1)
|
5. Ignorer les requêtes non pertinentes
Lorsqu’elles sont appliquées sur des liens qui ne contiennent pas l’attribut ‘href’ (par exemple, mailto, téléphone, etc.), la méthode head entraîne une exception (par exemple, MissingSchema, InvalidSchema).
|
1
2
3
4
5
6
|
except requests.exceptions.MissingSchema:
print(« Encountered MissingSchema Exception »)
except requests.exceptions.InvalidSchema:
print(« Encountered InvalidSchema Exception »)
except:
print(« Rencontré une autre exécution »)
|
Ces exceptions sont capturées et la même chose est imprimée sur le terminal.
Exécution
Nous avons utilisé le PyUnit (ou unittest) ici, le framework de test par défaut en Python pour les tests de liens brisés à l’aide de Sélénium. Exécutez la commande suivante sur le terminal:
|
1
|
python Broken_Links.py
|
L’exécution prendrait environ 2-3 minutes puisque la page de blog LambdaTest se compose d’environ 150+ liens. La capture d’écran d’exécution ci-dessous montre que la page contient 169 liens valides et zéro lien brisé.
Vous assisteriez à l’exception InvalidSchema ou MissingSchema à certains endroits, ce qui indique que ces liens sont ignorés de l’évaluation.
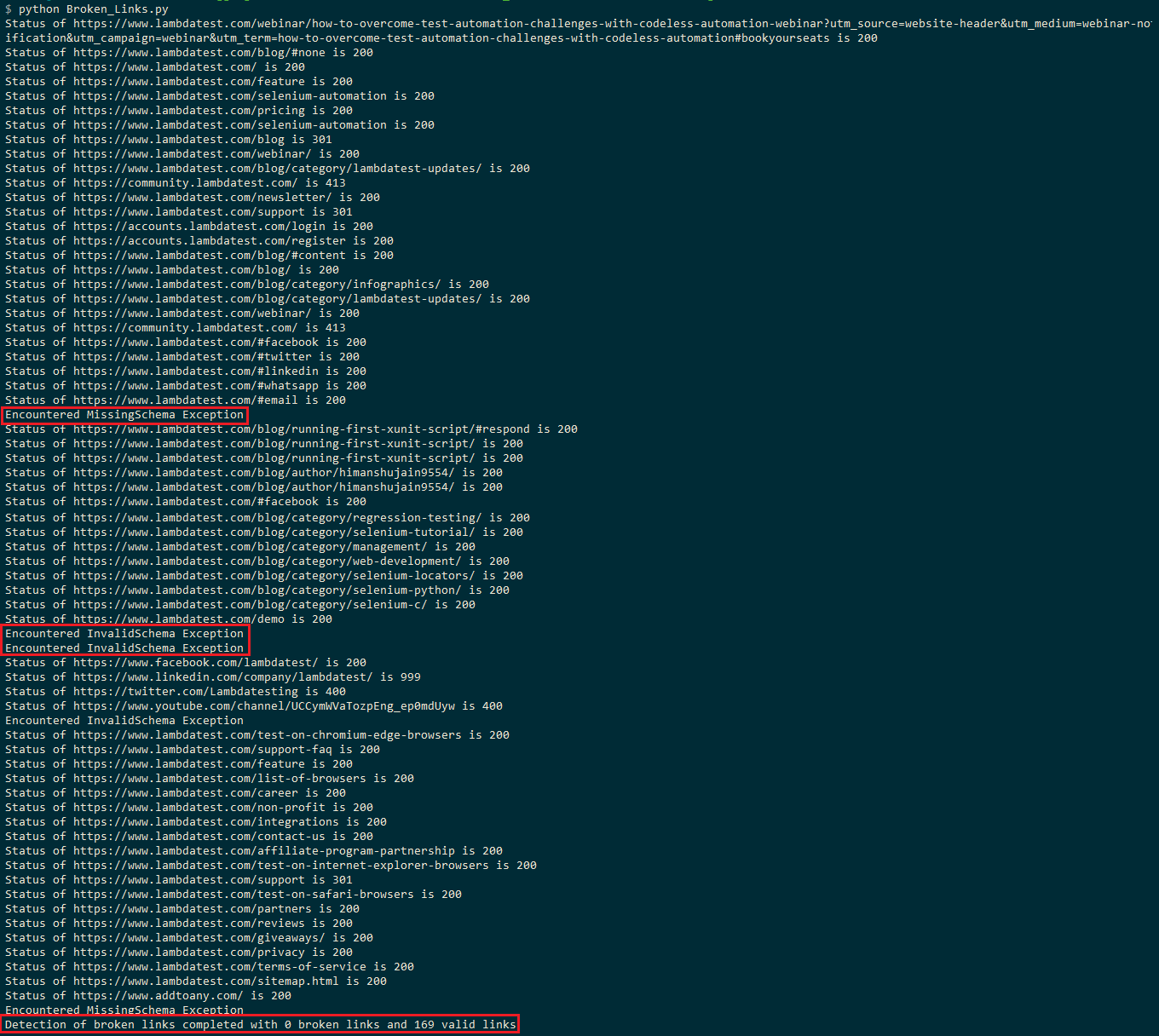
La requête HEAD à LinkedIn (c’est-à-dire) entraîne un code d’état HTTP de 999. Comme indiqué dans ce fil de discussion sur StackOverflow, LinkedIn filtre les demandes en fonction de l’agent utilisateur, et la demande a entraîné un « Accès refusé » (c’est-à-dire 999 en tant que code d’état HTTP).

Nous avons vérifié si le lien LinkedIn présent sur la page du blog LambdaTest était cassé ou non en exécutant le même test sur la grille de sélénium locale, ce qui a abouti à HTTP/1.1 200 OK.
Test de lien cassé Utilisant Selenium C #
Implémentation
Procédure pas à pas du code
Le framework NUnit est utilisé pour les tests d’automatisation; notre blog précédent sur l’automatisation des tests NUnit avec Selenium C # peut vous aider à démarrer avec le framework.
1. Include HttpClient
L’espace de noms HttpClient est ajouté pour utilisation via la directive using. La classe HttpClient en C# fournit une classe de base pour envoyer des requêtes HTTP et recevoir la réponse HTTP d’une ressource identifiée par l’URI.
Microsoft recommande d’utiliser System.Net.Http.HttpClient au lieu de System.Net.HttpWebRequest ; HttpWebRequest pourrait également être utilisé pour détecter les liens brisés dans Selenium C#.
|
1
2
|
utilisation de System.Net.Http;
utilisation de System.Enfilage.Tâches;
|
2. Définir une méthode asynchrone qui renvoie une tâche
Une méthode de test asynchrone est définie comme utilisant la méthode GetAsync qui envoie une requête GET à l’URI spécifié en tant qu’opération asynchrone.
|
1
2
|
tâche asynchrone publique LT_Broken_Links_Test()
{
|
3. Collectez les liens présents sur la page
Tout d’abord, nous créons une instance de HttpClient.
|
1
|
utilisation de var client = new HttpClient();
|
Les liens présents sur l’URL testée (c’est-à-dire le Blog LambdaTest) sont collectés en localisant les éléments Web par la propriété « a » de TagName.
|
1
|
liens var = pilote.FindÉléments (Par.TagName (« a »));
|
La méthode find_elements dans Selenium est utilisée pour localiser les liens sur la page car elle renvoie un tableau (ou une liste) qui peut être itéré pour vérifier la faisabilité des liens.
4. Parcourir les URL pour validation
Les liens situés à l’aide de la méthode find_elements sont vérifiés dans une boucle for.
|
1
2
|
foreach (lien var dans liens)
{
|
Nous filtrons les liens qui contiennent / adresses e-mail / numéros de téléphone / adresses LinkedIn. Les liens sans Texte de lien sont également filtrés.
|
1
2
|
si (!(lien.Texte.Contient (« Email ») || lien.Texte.Contient (« https://www.linkedin.com ») || lien.Texte == « » // lien.Égal à (null)))
{
|
La méthode GetAsync de la classe HttpClient envoie une requête GET à l’URI correspondant en tant qu’opération asynchrone. L’argument de la méthode GetAsync est la valeur de l’attribut ‘href’ de l’ancre collectée à l’aide de la méthode getAttribute.
L’évaluation de la méthode asynchrone est suspendue par l’opérateur await jusqu’à la fin de l’opération asynchrone. Une fois l’opération asynchrone terminée, l’opérateur await renvoie le HttpResponseMessage qui inclut les données et le code d’état.
|
1
2
3
|
/* Obtenez la réponse URI*/
HttpResponseMessage = await client.GetAsync (lien.Obtenir des contributions (« href »));
Système.Console.WriteLine(URL » URL: { lien.Le statut de getAttribute(« href »)} est : { réponse.Code de statut} »);
|
5. Validez les liens via le code d’état
Si le code de réponse HTTP (c’est-à-dire la réponse.StatusCode) pour la requête HTTP envoyée à l’étape (4) est HttpStatusCode.OK (c.-à-d., 200), cela signifie que la demande a été traitée avec succès.
|
1
2
3
4
5
6
7
8
9
|
Système.Console.WriteLine($ »URL: {link.GetAttribute(« href »)} status is :{response.StatusCode} »);
if (response.StatusCode == HttpStatusCode.OK)
{
valid_links++;
}
else
{
broken_links++;
}
|
NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
|
1
2
3
4
5
6
7
8
|
catch (Exception ex)
{
if ((ex is ArgumentNullException) ||
(ex is NotSupportedException))
{
System.Console.WriteLine(« Exception occured\n »);
}
}
|
Execution
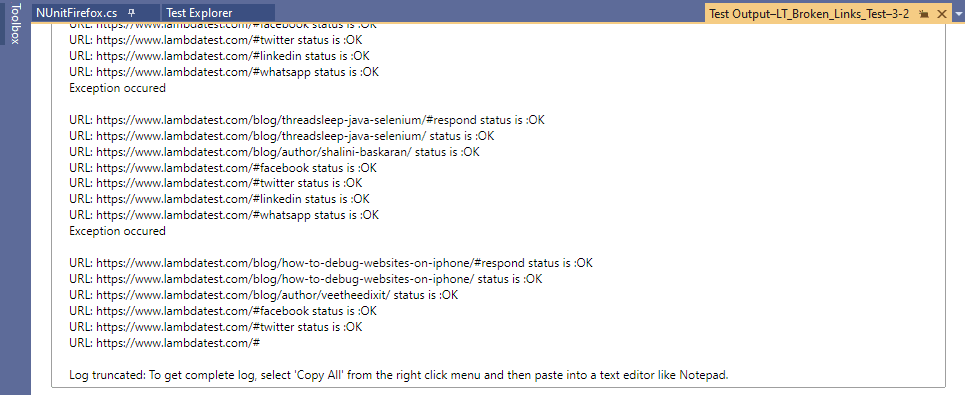
Voici l’instantané d’exécution, qui montre que le test a été exécuté avec succès.

Des exceptions ont été observées pour les liens vers les icônes de partage, c’est-à-dire WhatsApp, Facebook, Twitter, etc. En dehors de ces liens, le reste des liens sur la page du blog LambdaTest renvoie HttpStatusCode.OK (c’est-à-dire 200).
Test de Lien cassé En Utilisant Selenium PHP
Implémentation
Procédure pas À Pas Du Code
1. Lire la source de la page
La fonction file_get_contents en PHP est utilisée pour lire la source HTML de la page dans une variable de chaîne (par exemplehtmlhtml).
|
1
2
|
$ test_url = « https://www.lambdatest.com/blog/ »;
$ html =file_get_contents(testtest_url);
|
2. Instancier la classe DOMDocument
La classe DOMDocument en PHP représente un document HTML entier et sert de racine à l’arborescence des documents.
|
1
|
$ htmlDom = nouveau DOMDocument;
|
3. Parse HTML de la page
La fonction DOMDocument::loadHTML() est utilisée pour analyser la source HTML contenue danshtmlhtml. En cas d’exécution réussie, la fonction renvoie un objet DOMDocument.
|
1
|
@$ htmlDom – > loadHTML (htmlhtml);
|
4. Extraire les liens de la page
Les liens présents sur la page sont extraits à l’aide de la méthode getElementsByTagName de la classe DOMDocument. Les éléments (ou liens) sont recherchés en fonction de la balise « a » de la source HTML analysée.
La fonction getElementsByTagName renvoie une nouvelle instance de DOMNodeList qui contient les éléments (ou liens) du nom de balise local (i.e. tag)
|
1
|
$ j’ai besoin d’un nom de domaine pour créer des liens.’);
|
5. Parcourir les URL pour validation
Le DOMNodeList, créé à l’étape (4), est parcouru pour vérifier la validité des liens.
|
1
2
3
|
foreach(linksliens commelinklien)
{
$ linkText=linklink-> nodeValue;
|
Les détails du lien correspondant sont obtenus à l’aide de l’attribut ‘href’. La méthode getAttribute est utilisée pour la même chose.
|
1
|
$ J’ai besoin d’un lien pour créer un lien.;
|
Ignorer la vérification des liens si :
a. Le lien est vide
|
1
2
3
4
|
si (strlen(trim(linlinkHref)) == 0)
{
continuer;
}
|
d. Le lien est un hashtag ou un lien d’ancrage
|
1
2
3
4
|
si (linlinkHref == ‘#’)
{
continuer;
}
|
c. Le lien contient mailto ou addtoany (c’est-à-dire des options de partage social).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
function check_nonlinks($test_url, attest_pattern)
{
si (preg_match(testtest_pattern,testtest_url) == faux)
{
retourner false;
}
autre
{
retour vrai;
}
}
fonction publique test_Broken_Links()
{
$ pattern_1 = ‘/\baddtoany\b/’;
$ pattern_2 = ‘/\bmailto\b/’;
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
if((check_nonlinks(linlinkHref,patpattern_1)) ||(check_nonlinks(linlinkHref,patpattern_2)))
{
print(« \nAdd_To_Any ou email rencontré »);
continuer;
}
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
}
|
la fonction preg_match utilise une expression régulière (regex) pour effectuer une recherche insensible à la casse pour mailto et addtoany. Les expressions régulières pour mailto &addtoany sont respectivement ‘/\bmailto\b/’&’/\baddtoany\b/’.
6. Validez le code HTTP en utilisant cURL
Nous utilisons curl pour obtenir des informations sur l’état du lien correspondant. La première étape consiste à initialiser une session cURL avec le ‘lien’ sur lequel la validation doit être effectuée. La méthode renvoie une instance cURL qui sera utilisée dans la dernière partie de l’implémentation.
|
1
|
$ curl=curl_init(linlinkHref);
|
La méthode curl_setopt est utilisée pour définir des options sur le handle de session cURL donné (c’est-à-direcurlcurl).
|
1
|
curl_setopt (curlcurl, CURLOPT_NOBODY, true);
|
La méthode curl_exec est appelée pour l’exécution de la session cURL donnée. Il renvoie True en cas d’exécution réussie.
|
1
|
$ résultat = curl_exec(curlcurl);
|
C’est la partie la plus importante de la logique qui vérifie les liens brisés sur la page. La fonction curl_getinfo qui prend le handle de session cURL (c’est-à-direcurlcurl) et CURLINFO_RESPONSE_CODE (c’est-à-dire CURLINFO_HTTP_CODE) sont utilisés pour obtenir des informations sur le dernier transfert. Il renvoie le code d’état HTTP en réponse.
|
1
|
$ statusCode = curl_getinfo(curlcurl, CURLINFO_HTTP_CODE);
|
Une fois la requête terminée, le code d’état HTTP de 200 est renvoyé et la variable contenant le nombre de liens valides (c’est-à-dire $valid_links) est incrémentée. Pour les liens dont le code d’état HTTP est de 400 (ou plus), une vérification est effectuée si le » lien testé » était la page LinkedIn de LambdaTest. Comme mentionné précédemment, le code d’état de la page LinkedIn sera 999; par conséquent,validvalid_links est incrémenté.
Pour tous les autres liens qui ont renvoyé un code d’état HTTP de 400 (ou plus), la variable contenant le nombre de liens brisés (c’est-à-dire $broken_links) est incrémentée.
|
1
2
3
4
5
6
7
8
9
10
|
si (($linkedin_page_status) & & (odestatusCode == 999))
{
print(« \nLink ». linlinkHref. « est la page LinkedIn et le statut est ».$statusCode);
linksvalidlinks++;
}
autre
{
print(« \nLink ». linlinkHref. « est le lien cassé et le statut est ».odeCode d’état);
linksliens brisés++;
}
|
Exécution
Nous utilisons le framework PHPUnit pour tester les liens rompus sur la page. Pour télécharger le framework PHPUnit, ajoutez le compositeur de fichiers.json dans le dossier racine et exécuter composer require sur le terminal.
Exécutez la commande suivante sur le terminal pour vérifier les liens rompus dans Selenium PHP.
|
1
|
fournisseur \ bin\phpunit tests \ BrokenLinksTest.php
|
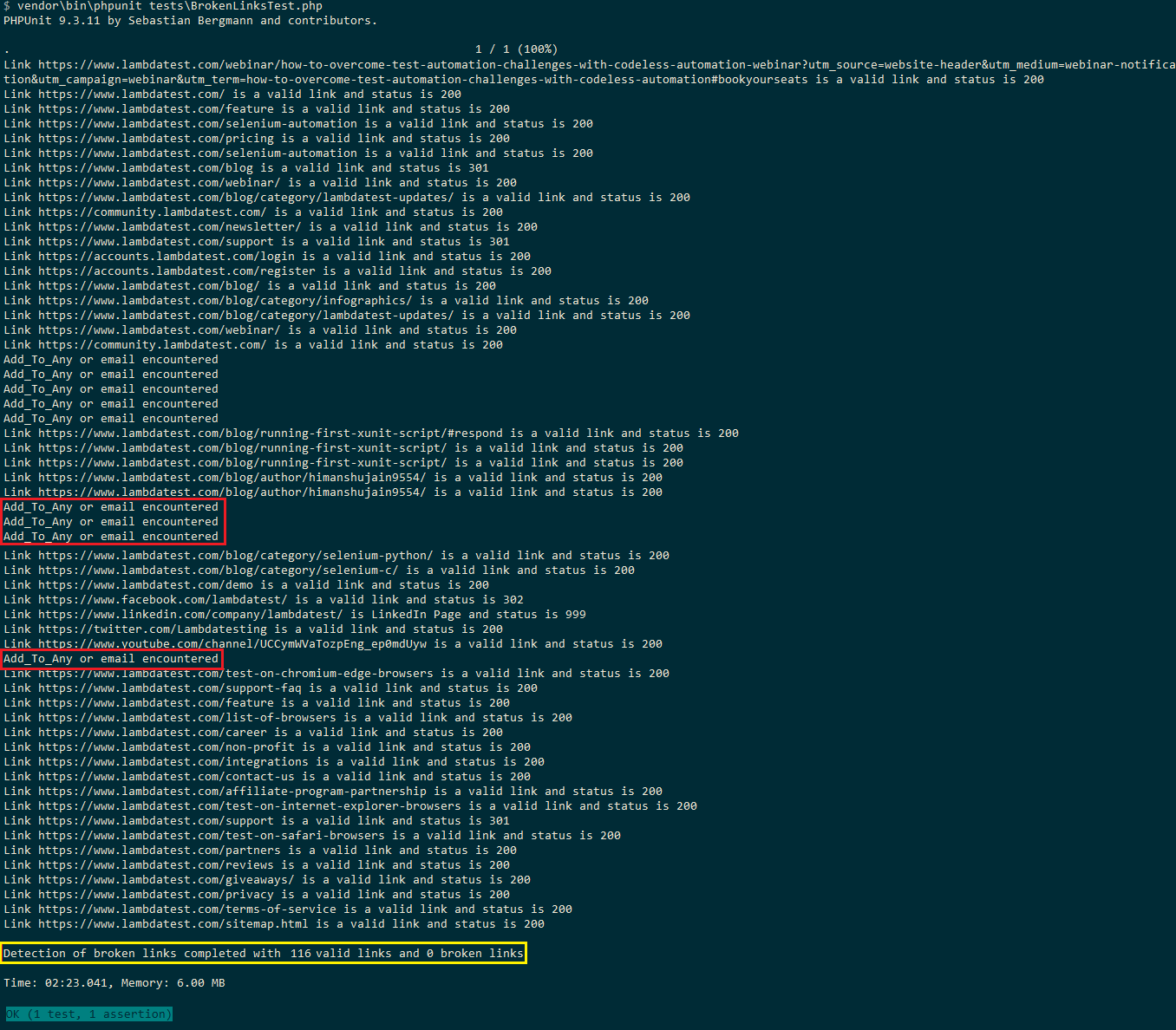
Voici l’instantané d’exécution qui affiche un total de 116 liens valides et 0 liens brisés sur le blog LambdaTest. Comme les liens pour le partage social (c’est-à-dire addtoany) et l’adresse e-mail sont ignorés, le nombre total est de 116 (169 dans le test Selenium Python).
Conclusion

Les liens brisés, également appelés liens morts ou liens pourris, peuvent gêner l’expérience utilisateur s’ils sont présents sur le site Web. Les liens brisés peuvent également avoir un impact sur le classement des moteurs de recherche. Par conséquent, des tests de liens brisés devraient être effectués périodiquement pour les activités liées au développement et aux tests de sites Web.
Plutôt que de s’appuyer sur des outils tiers ou des méthodes manuelles pour vérifier les liens brisés sur un site Web, les tests de liens brisés peuvent être effectués en utilisant Selenium WebDriver avec Java, Python, C# ou PHP. Le code d’état HTTP, renvoyé lors de l’accès à une page Web, doit être utilisé pour vérifier les liens rompus à l’aide du framework Selenium.
Foire aux questions
Comment trouver des liens brisés dans selenium Python?
Pour vérifier les liens rompus, vous devrez collecter tous les liens de la page Web en fonction de la balise. Envoyez ensuite une requête HTTP pour les liens et lisez le code de réponse HTTP. Découvrez si le lien est valide ou cassé en fonction du code de réponse HTTP.
Comment puis-je vérifier les liens rompus ?
Pour surveiller en permanence votre site à la recherche de liens rompus à l’aide de la console de recherche Google, procédez comme suit:
- Connectez-vous à votre compte Google Search Console.
- Cliquez sur le site que vous souhaitez surveiller.
- Cliquez sur Analyser, puis cliquez sur Récupérer en tant que Google.
- Une fois que Google analyse le site, pour accéder aux résultats, cliquez sur Analyser, puis sur Analyser les erreurs.
- Sous Erreurs d’URL, vous pouvez voir tous les liens brisés que Google a découverts pendant le processus d’analyse.
Comment puis-je trouver des images cassées sur le Web en utilisant le sélénium?
Visitez la page. Parcourez chaque image de l’archive HTTP et voyez si elle a un code d’état 404. Stockez chaque image brisée dans une collection. Vérifiez que la collection d’images cassées est vide.
Comment puis-je obtenir tous les liens dans selenium?
Vous pouvez obtenir tous les liens présents sur une page web en fonction de la balise <a > présente. Chaque balise < a > représente un lien. Utilisez les localisateurs de sélénium pour trouver facilement toutes ces balises.
Pourquoi les liens brisés sont-ils mauvais?
Ils peuvent nuire à l’expérience utilisateur – Lorsque les utilisateurs cliquent sur des liens et atteignent des erreurs sans issue 404, ils sont frustrés et peuvent ne jamais revenir. Ils dévaluent vos efforts de référencement – Des liens brisés limitent le flux d’équité de liens sur l’ensemble de votre site, ce qui a un impact négatif sur le classement.

Himanshu Sheth
Himanshu Sheth est un technologue et blogueur chevronné avec plus de 15 ans d’expérience de travail diversifiée. Il travaille actuellement en tant que « Lead Developer Evangelist » et » Senior Manager » chez LambdaTest. Il est très actif auprès de la communauté des startups de Bengaluru (et du Sud) et aime interagir avec des fondateurs passionnés sur son blog personnel (qu’il tient depuis plus de 15 ans).