




Wie finde ich defekte Links mit Selenium WebDriver?
Welche Gedanken kommen Ihnen in den Sinn, wenn Sie auf 404 / Seite nicht gefunden / Tote Hyperlinks auf einer Website stoßen? Aarhus! Sie würden es ärgerlich finden, wenn Sie auf defekte Hyperlinks stoßen, was der einzige Grund ist, warum Sie sich ständig darauf konzentrieren sollten, die Existenz defekter Links in Ihrem Webprodukt (oder Ihrer Website) zu entfernen. Anstelle einer manuellen Inspektion können Sie mithilfe von Selenium WebDriver die Automatisierung für das Testen defekter Links nutzen.

Wenn ein bestimmter Link defekt ist und ein Besucher auf der Seite landet, wirkt sich dies auf die Funktionalität dieser Seite aus und führt zu einer schlechten Benutzererfahrung. Tote Links könnten die Glaubwürdigkeit Ihres Produkts beeinträchtigen, da sie Ihren Besuchern den Eindruck vermitteln könnten, dass die Erfahrung nur minimal im Mittelpunkt steht.
Wenn Ihr Webprodukt viele Seiten (oder Links) enthält, die zu einem 404-Fehler (oder einer Seite nicht gefunden) führen, sind auch die Produktrankings in Suchmaschinen (z. B. Google) stark betroffen. Das Entfernen toter Links ist einer der wesentlichen Bestandteile der SEO-Aktivität (Suchmaschinenoptimierung).
In diesem Teil der Selenium WebDriver-Tutorial-Serie tauchen wir tief in die Suche nach defekten Links mit Selenium WebDriver ein. Wir haben Broken Link-Tests mit Selenium Python, Selenium Java, Selenium C # und Selenium PHP demonstriert.
Einführung in defekte Links im Webtest
In einfachen Worten, defekte Links (oder tote Links) in einer Website (oder Web-App) sind Links, die nicht erreichbar sind und nicht wie erwartet funktionieren. Die Links könnten aufgrund von Serverproblemen vorübergehend nicht verfügbar sein oder im Backend falsch konfiguriert sein.
Abgesehen von Seiten, die zu einem 404-Fehler führen, sind andere prominente Beispiele für defekte Links fehlerhafte URLs, Links zu Inhalten (z. B. Dokumente, PDF, Bilder usw.), die verschoben oder gelöscht wurden.
Prominente Gründe für defekte Links
Hier sind einige der häufigsten Gründe für das Auftreten von defekten Links (tote Links oder Link Rots):
- Falsche oder falsch geschriebene URL, die vom Benutzer eingegeben wurde.
- Strukturelle Änderungen in der Website (z. B. Permalinks) mit URL-Weiterleitungen oder internen Weiterleitungen sind nicht richtig konfiguriert.
- Links zu Inhalten wie Videos, Dokumenten usw. diese werden entweder verschoben oder gelöscht. Wenn der Inhalt verschoben wird, sollten die ‚internen Links‘ zu den angegebenen Links umgeleitet werden.
- Vorübergehende Ausfallzeit der Website aufgrund von Wartungsarbeiten an der Website, wodurch die Website vorübergehend nicht zugänglich ist.
- Defekte HTML-Tags, JavaScript-Fehler, falsche HTML / CSS-Anpassungen, defekte eingebettete Elemente usw., innerhalb der Seite führt, kann zu defekten Links führen.
- Geolokalisierungsbeschränkungen verhindern den Zugriff auf die Website von bestimmten IP-Adressen (wenn sie auf der schwarzen Liste stehen) oder bestimmten Ländern der Welt. Geolokalisierungstests mit Selenium stellen sicher, dass die Erfahrung für den Standort (oder das Land), von dem aus auf die Site zugegriffen wird, maßgeschneidert ist.
Warum sollten Sie defekte Links überprüfen?
Defekte Links sind eine große Abzweigung für die Besucher, die auf Ihrer Website landen. Hier sind einige der Hauptgründe, warum Sie auf Ihrer Website nach defekten Links suchen sollten:
- Defekte Links können die Benutzererfahrung beeinträchtigen.
- Das Entfernen defekter (oder toter) Links ist für SEO (Suchmaschinenoptimierung) unerlässlich, da dies die Platzierung der Website in Suchmaschinen (z. B. Google) beeinträchtigen kann.
Das Testen defekter Links kann mit Selenium WebDriver auf einer Webseite durchgeführt werden, mit dem wiederum die toten Links der Site entfernt werden können.
Defekte Links und HTTP-Statuscodes
Wenn ein Benutzer eine Website besucht, wird vom Browser eine Anfrage an den Server der Website gesendet. Der Server antwortet auf die Anfrage des Browsers mit einem dreistelligen Code, der als HTTP-Statuscode bezeichnet wird.‘
Ein HTTP-Statuscode ist die Antwort des Servers auf eine vom Webbrowser gesendete Anforderung. Diese HTTP-Statuscodes entsprechen der Konversation zwischen dem Browser (von dem die URL-Anforderung gesendet wird) und dem Server.
Obwohl verschiedene HTTP-Statuscodes für verschiedene Zwecke verwendet werden, sind die meisten Codes nützlich, um Probleme auf der Site zu diagnostizieren, Ausfallzeiten der Site, die Anzahl toter Links und mehr zu minimieren. Die erste Ziffer jedes dreistelligen Statuscodes beginnt mit den Nummern 1~5. Die Statuscodes werden als 1xx, 2xx dargestellt.., 5xx zur Anzeige der Statuscodes in diesem bestimmten Bereich. Da jeder dieser Bereiche aus einer anderen Klasse von Serverantworten besteht, würden wir die Diskussion auf HTTP-Statuscodes beschränken, die für fehlerhafte Links angezeigt werden.
Hier sind die allgemeinen Statuscodeklassen, die nützlich sind, um defekte Links mit Selenium zu erkennen:
| Klassen des HTTP-Statuscodes | Beschreibung |
|---|---|
| 1xx | Der Server durchdenkt die Anfrage noch. |
| 2xx | Die vom Browser gesendete Anforderung wurde erfolgreich abgeschlossen, und die erwartete Antwort wurde vom Server an den Browser gesendet. |
| 3xx | Dies zeigt an, dass eine Umleitung durchgeführt wird. Beispielsweise wird die 301-Weiterleitung im Volksmund zum Implementieren permanenter Weiterleitungen auf einer Website verwendet. |
| 4xx | Dies zeigt an, dass entweder eine bestimmte Seite (oder eine vollständige Site) nicht erreichbar ist. |
| 5xx | Dies zeigt an, dass der Server die Anforderung nicht abschließen konnte, obwohl eine gültige Anforderung vom Browser gesendet wurde. |
HTTP-Statuscodes bei Erkennung defekter Links
Hier sind einige der häufigsten HTTP-Statuscodes, die vom Webserver bei Auftreten eines defekten Links angezeigt werden:
| HTTP-Statuscode | Beschreibung |
|---|---|
| 400 ( Bad Request) | Der Server kann die Anfrage nicht verarbeiten, da die angegebene URL falsch ist. |
| 400 ( Bad Request – Bad Host) | Dies zeigt an, dass der Hostname ungültig ist, weshalb die Anforderung nicht verarbeitet werden kann. |
| 400 ( Bad Request – Bad URL) | Dies zeigt an, dass der Server die Anforderung nicht verarbeiten kann, da die eingegebene URL fehlerhaft ist (d. h. fehlende Klammern, Schrägstriche usw.). |
| 400 ( Bad Request – Timeout) | Dies zeigt an, dass die HTTP-Anforderungen abgelaufen sind. |
| 400 ( Bad Request – Empty) | Die vom Server zurückgegebene Antwort ist leer ohne Inhalt und ohne Antwortcode. |
| 400 ( Bad Request – Reset) | Dies zeigt an, dass der Server die Anforderung nicht verarbeiten kann, da er mit der Verarbeitung anderer Anforderungen beschäftigt ist oder vom Websitebesitzer falsch konfiguriert wurde. |
| 403 ( Verboten) | Eine echte Anfrage wird an den Server gesendet, weigert sich jedoch, dieselbe zu erfüllen, da eine Autorisierung erforderlich ist. |
| 404 ( Seite nicht gefunden) | Die Ressource (oder die Seite) ist auf dem Server nicht verfügbar. |
| 408 ( Anforderungszeitüberschreitung) | Der Server hat eine Zeitüberschreitung, die auf die Anforderung wartet. Der Client (dh der Browser) kann dieselbe Anfrage innerhalb der Wartezeit senden, die der Server bereit ist zu warten. |
| 410 ( Gone) | Ein HTTP-Statuscode, der dauerhafter als 404 ist (Seite nicht gefunden). 410 bedeutet, dass die Seite verschwunden ist. Die Seite ist weder auf dem Server verfügbar, noch wurde ein Weiterleitungs- (oder Umleitungs-)Mechanismus eingerichtet. Die Links, die auf eine 410-Seite verweisen, senden Besucher zu einer toten Ressource. |
| 503 ( Dienst nicht verfügbar) | Dies zeigt an, dass der Server vorübergehend überlastet ist, wodurch er die Anforderung nicht verarbeiten kann. Dies kann auch bedeuten, dass auf dem Server Wartungsarbeiten durchgeführt werden, die den Suchmaschinen die vorübergehende Ausfallzeit der Site anzeigen. |
Wie finde ich defekte Links mit Selenium WebDriver?
Unabhängig von der mit Selenium WebDriver verwendeten Sprache bleiben die Leitprinzipien für Broken Link-Tests mit Selenium gleich. Hier sind die Schritte zum Testen defekter Links mit Selenium WebDriver:
- Verwenden Sie das Tag, um Details zu allen auf der Webseite vorhandenen Links zu sammeln.
- Senden Sie für jeden Link eine HTTP-Anfrage.
- Überprüfen Sie den entsprechenden Antwortcode, der als Antwort auf die im vorherigen Schritt gesendete Anforderung empfangen wurde.
- Überprüfen Sie anhand des vom Server gesendeten Antwortcodes, ob die Verbindung unterbrochen ist oder nicht.
- Wiederholen Sie die Schritte (2-4) für jeden auf der Seite vorhandenen Link.
In diesem Selenium WebDriver-Tutorial zeigen wir Ihnen, wie Sie mit Selenium WebDriver in Python, Java, C # und PHP Broken Link-Tests durchführen. Die Tests werden auf einer Kombination (Chrome 85.0 + Windows 10) durchgeführt, und die Ausführung erfolgt auf dem Cloud-basierten Selenium Grid von LambdaTest.
Um mit LambdaTest zu beginnen, erstellen Sie ein Konto auf der Plattform und notieren Sie sich den Benutzernamen & access-key, der im Profilbereich von LambdaTest verfügbar ist. Die Browserfunktionen werden mit dem LambdaTest Capabilities Generator generiert.
Hier ist das Testszenario zum Auffinden defekter Links auf einer Website mit Selenium:
Testszenario
- Gehen Sie zum LambdaTest-Blog, dh https://www.lambdatest.com/blog/ unter Chrome 85.0
- Sammeln Sie alle auf der Seite vorhandenen Links
- Senden Sie für jeden Link eine HTTP-Anforderung
- Gibt aus, ob der Link auf dem Terminal defekt ist oder nicht
Es ist wichtig zu beachten, dass die Zeit, die für das Testen defekter Links mit Selenium aufgewendet wird, von der Anzahl der Links abhängt, die auf der zu testenden Webseite vorhanden sind. Je mehr Links auf der Seite vorhanden sind, desto mehr Zeit wird damit verbracht, defekte Links zu finden. Zum Beispiel hat LambdaTest eine große Anzahl von Links (~ 150+); Daher kann das Auffinden defekter Links einige Zeit dauern (ungefähr einige Minuten).

FÜHREN SIE IHR TESTSKRIPT AUF SELENIUM GRID AUS
2000+ Browser UND BETRIEBSSYSTEME
KOSTENLOSE ANMELDUNG
Broken Link Testen mit Selenium Java
Implementierung
Code WalkThrough
1. Importieren der erforderlichen Pakete
Die Methoden im Paket HttpURLConnection werden zum Senden von HTTP-Anforderungen und zum Erfassen des HTTP-Statuscodes (oder der Antwort) verwendet.
Die Methoden in der Regex.Musterpaket Überprüfen Sie, ob der entsprechende Link eine E-Mail-Adresse oder Telefonnummer enthält, indem Sie eine spezielle Syntax in einem Muster verwenden.
|
1
2
|
import java.net.HttpURLConnection;
java importieren.util.regex.Muster;
|
2. Sammeln Sie die Links auf der Seite
Die Links auf der zu testenden URL (dh LambdaTest Blog) befinden sich mit tagname in Selenium. Der Tag-Name, der zur Identifizierung des Elements (oder Links) verwendet wird, ist ‚a‘.
Die Links werden in einer Liste platziert, um die Liste zu durchlaufen und defekte Links auf der Seite zu überprüfen.
|
1
|
Liste<WebElement> Links = Treiber.findElements(Durch.tagName(„a“));
|
3. Iterieren durch die URLs
Das Iterator-Objekt wird zum Durchlaufen der in Schritt erstellten Liste verwendet (2)
|
1
|
Iterator<WebElement> Verknüpfung = Links.iterator();
|
4. Identifizieren und Überprüfen Sie die URLs
Eine while-Schleife wird ausgeführt, bis der Zeititerator (dh link) nicht mehr Elemente zum Iterieren hat. Die ‚href‘ des Anker-Tags wird abgerufen und in der URL-Variablen gespeichert.
|
1
2
3
|
während (Link.hasNext())
{
url = Verknüpfung.nächsten().getAttribute(„href“);
|
Überspringen Sie die Überprüfung der Links, wenn:
ein. Der Link ist null oder leer
|
1
2
3
4
5
|
wenn ((url == null) |/ (url.isEmpty()))
{
System.aus.println(„URL ist entweder nicht für Anker-Tag konfiguriert oder leer“);
weiter;
}
|
b. Der Link enthält Mailto oder Telefonnummer
|
1
2
3
4
5
|
wenn ((url.startsWith(mail_to)) || (url.startsWith(tel)))
{
System.aus.println(„E-Mail-Adresse oder Telefonnummer erkannt“);
weiter;
}
|
Wenn Sie nach der LinkedIn-Seite suchen, lautet der HTTP-Statuscode 999. Eine boolesche Variable (z., LinkedIn) wird auf true gesetzt, um anzuzeigen, dass es sich nicht um einen defekten Link handelt.
|
1
2
3
4
5
|
wenn(url.startsWith(Verlinktseite))
{
System.aus.println(„URL beginnt mit LinkedIn, erwarteter Statuscode ist 999“);
bLinkedIn = wahr;
}
|
5. Überprüfen Sie die Links über den Statuscode
Die Methoden in der HttpURLConnection-Klasse bieten die Möglichkeit, HTTP-Anforderungen zu senden und den HTTP-Statuscode zu erfassen.
Die openConnection-Methode der URL-Klasse öffnet die Verbindung zur angegebenen URL. Es gibt eine URLConnection-Instanz zurück, die eine Verbindung zu dem Remote-Objekt darstellt, auf das die URL verweist. Es wird in HttpURLConnection umgewandelt.
|
1
2
3
4
5
6
7
|
HttpURLConnection urlconnection = null;
……………………………………….
……………………………………….
……………………………………….
urlconnection = (HttpURLConnection) (neue URL(URL).openConnection());
urlverbindung.setRequestMethod(„KOPF“);
|
Die setRequestMethod in HttpURLConnection Klasse legt die Methode für URL-Anforderung. Der Anforderungstyp wird auf HEAD gesetzt, sodass nur Header zurückgegeben werden. Andererseits hätte der Anforderungstyp GET den Dokumententext zurückgegeben, der in diesem speziellen Testszenario nicht erforderlich ist.
Die connect-Methode in der HttpURLConnection-Klasse stellt die Verbindung zur URL her und sendet eine HTTP-Anforderung.
|
1
|
urlverbindung.verbinden();
|
Die Methode getResponseCode gibt den HTTP-Statuscode für die zuvor gesendete Anforderung zurück.
|
1
|
responseCode = urlconnection.getResponseCode();
|
Wenn der HTTP-Statuscode 400 (oder mehr) beträgt, wird die Variable, die die Anzahl der defekten Links enthält (d. h. broken_links), inkrementiert; Andernfalls wird die Variable, die gültige Links enthält (d. h. valid_links), inkrementiert.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
wenn (responseCode >= 400)
{
if ((bLinkedIn == wahr) && (responseCode == LinkedInStatus))
{
System.aus.println(url + “ ist eine LinkedIn-Seite und kein defekter Link“);
valid_links++;
}
sonst
{
System.aus.println(url + “ ist ein defekter Link“);
broken_links++;
}
}
sonst
{
System.aus.println(url + “ ist ein gültiger Link“);
valid_links++;
}
|
Ausführung
Zum Testen defekter Links mit Selenium Java haben wir ein Projekt in IntelliJ IDEA erstellt. Das grundlegende pom.XML-Datei war ausreichend für den Job!
Hier ist der Ausführungs-Snapshot, der 169 gültige Links und 0 defekte Links auf der LambdaTest-Blogseite anzeigt.
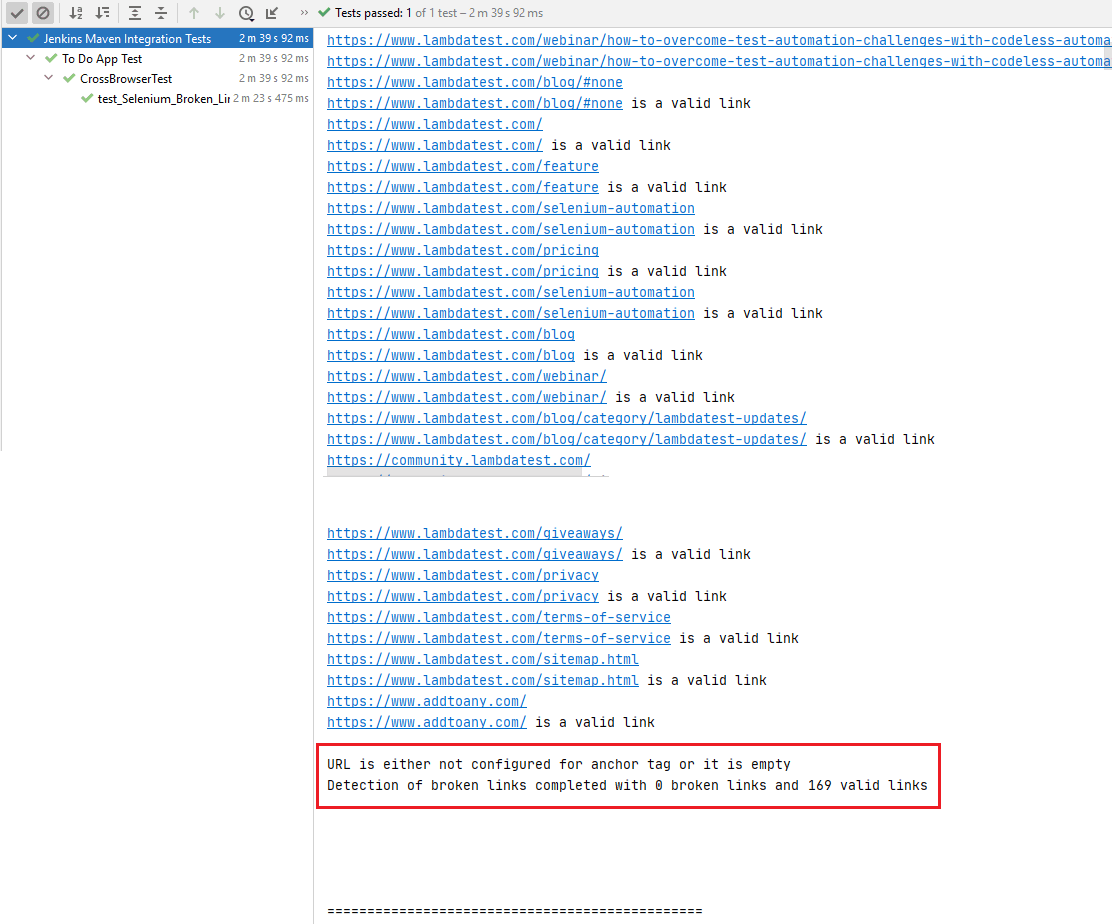
Die Links mit den E-Mail-Adressen und Telefonnummern wurden aus der Suchliste ausgeschlossen, wie unten gezeigt.
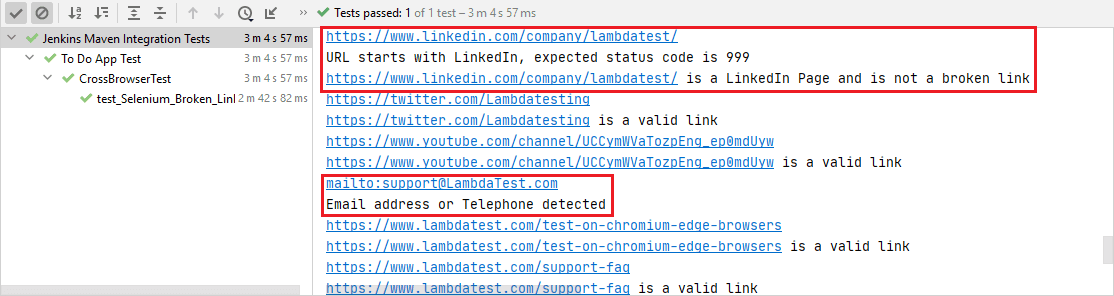
Sie können sehen, wie der Test im folgenden Screenshot ausgeführt und in 2 min 35 Sekunden abgeschlossen wird, wie in den Automatisierungsprotokollen von LambdaTest gezeigt.

Testen defekter Links mit Selenium Python
Implementierung
Code WalkThrough
1. Module importieren
Neben dem Import der Python-Module für Selenium WebDriver importieren wir auch das Anforderungsmodul. Mit dem Anforderungsmodul können Sie alle Arten von HTTP-Anforderungen senden. Es kann auch zum Übergeben von Parametern in URLs, zum Senden benutzerdefinierter Header und mehr verwendet werden.
|
1
2
3
|
importieren Sie Anforderungen
importieren Sie urllib3
aus Anforderungen.ausnahmen importieren MissingSchema, InvalidSchema, InvalidURL
|
2. Sammeln Sie die Links auf der Seite
Die Links auf der zu testenden URL (dh LambdaTest Blog) werden gefunden, indem die Webelemente über die CSS-Selektoreigenschaft „a“ gefunden werden.
|
1
|
links = Treiber.find_elements(Durch.CSS_SELECTOR, „ein“)
|
Da das Element iterierbar sein soll, verwenden wir die find_elements-Methode (und nicht die find_element-Methode).
3. Durchlaufen der URLs zur Validierung
Die head-Methode des requests-Moduls wird verwendet, um eine HEAD-Anforderung an die angegebene URL zu senden. Die Methode get_attribute wird für jeden Link verwendet, um das Attribut ‚href‘ des Anker-Tags abzurufen.
Die head-Methode wird hauptsächlich in Szenarien verwendet, in denen nur status_code- oder HTTP-Header erforderlich sind und der Inhalt der Datei (oder URL) nicht benötigt wird. Die head-Methode gibt Anforderungen zurück.Response-Objekt, das auch den HTTP-Statuscode enthält (dh request.Statuscode).
|
1
2
3
4
|
für Link in Links:
versuchen Sie:
request = Anfragen.kopf(Link.get_attribute(‚href‘), Daten ={‚Schlüssel‘:’wert‘})
print(„Status von “ + Link.get_attribute(‚href‘) + “ ist “ + str(Anfrage.status_code))
|
Die gleichen Operationen werden iterativ ausgeführt, bis alle auf der Seite vorhandenen Links erschöpft sind.
4. Überprüfen Sie die Links anhand des Statuscodes
Wenn der HTTP-Antwortcode für die in Schritt (3) gesendete HTTP-Anforderung 404 lautet (d. H. Seite nicht gefunden), bedeutet dies, dass der Link defekt ist. Für Links, die nicht beschädigt sind, lautet der HTTP-Statuscode 200.
|
1
2
3
4
|
wenn (Anfrage.status_code == 404):
broken_links = (broken_links + 1)
sonst:
valid_links = (valid_links + 1)
|
5. Überspringen Sie irrelevante Anfragen
, wenn sie auf Links angewendet werden, die nicht das Attribut ‚href‘ enthalten (z. B. mailto, Telefon usw.), führt die head-Methode zu einer Ausnahme (dh MissingSchema, InvalidSchema).
|
1
2
3
4
5
6
|
except requests.exceptions.MissingSchema:
print(„Encountered MissingSchema Exception“)
except requests.exceptions.InvalidSchema:
print(„Encountered InvalidSchema Exception“)
except:
print(„Eine andere Ausführung ist aufgetreten“)
|
Diese Ausnahmen werden abgefangen und auf dem Terminal gedruckt.
Ausführung
Wir haben hier PyUnit (oder unittest) verwendet, das Standard-Testframework in Python zum Testen defekter Links mit Selenium. Führen Sie den folgenden Befehl auf dem Terminal aus:
|
1
|
in: python Broken_Links.py
|
Die Ausführung würde ungefähr 2-3 Minuten dauern, da die LambdaTest-Blogseite aus ungefähr 150+ Links besteht. Der folgende Ausführungs-Screenshot zeigt, dass die Seite 169 gültige Links und null fehlerhafte Links enthält.
Sie würden an einigen Stellen die InvalidSchema-Ausnahme oder die MissingSchema-Ausnahme feststellen, was darauf hinweist, dass diese Links von der Auswertung übersprungen werden.
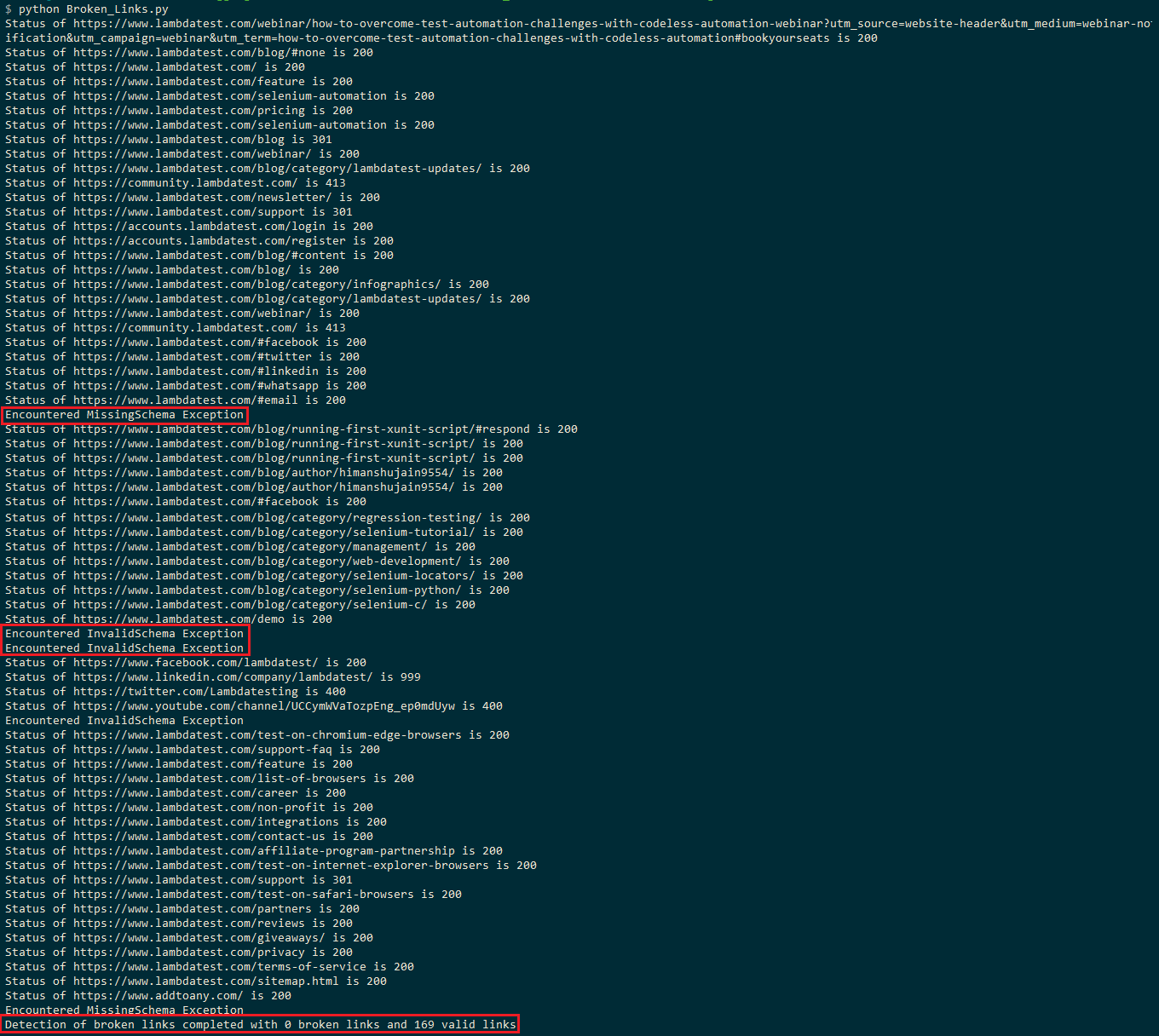
Die Kopfanforderung an LinkedIn (dh) führt zu einem HTTP-Statuscode von 999. Wie in diesem Thread zu StackOverflow angegeben, filtert LinkedIn die Anforderungen basierend auf dem Benutzeragenten, und die Anforderung führte zu ‚Zugriff verweigert‘ (dh 999 als HTTP-Statuscode).

Wir haben überprüft, ob der LinkedIn-Link auf der LambdaTest-Blogseite defekt ist oder nicht, indem wir denselben Test auf dem lokalen Selenium-Grid ausgeführt haben, was zu HTTP / 1.1 200 OK .
Broken Link Testing Mit Selenium C #
Implementierung
Code WalkThrough
Das NUnit-Framework wird für Automatisierungstests verwendet; unser früherer Blog über NUnit-Testautomatisierung mit Selenium C # kann Ihnen den Einstieg in das Framework erleichtern.
1. Include HttpClient
Der HttpClient-Namespace wird zur Verwendung über die using-Direktive hinzugefügt. Die HttpClient-Klasse in C # stellt eine Basisklasse zum Senden von HTTP-Anforderungen und zum Empfangen der HTTP-Antwort von einer Ressource bereit, die durch URI identifiziert wird.
Microsoft empfiehlt die Verwendung von System.Net.Http.HttpClient anstelle von System.Net.HttpWebRequest; HttpWebRequest könnte auch verwendet werden, um defekte Links in Selenium C # zu erkennen.
|
1
2
|
mit System.Net.Http;
mit System.Einfädeln.Aufgaben;
|
2. Definieren einer asynchronen Methode, die eine Aufgabe zurückgibt
Eine asynchrone Testmethode ist definiert als die Verwendung der GetAsync-Methode, die eine GET-Anforderung als asynchrone Operation an den angegebenen URI sendet.
|
1
2
|
öffentliche asynchrone Aufgabe LT_Broken_Links_Test()
{
|
3. Sammeln Sie die Links auf der Seite
Zunächst erstellen wir eine Instanz von HttpClient.
|
1
|
verwenden von var client = new HttpClient();
|
Die Links, die auf der zu testenden URL (dh LambdaTest Blog) vorhanden sind, werden gesammelt, indem die Web-Elemente durch die tagName „a“ -Eigenschaft gefunden werden.
|
1
|
var links = Treiber.findElements(Durch.tagName(„a“));
|
Die find_elements-Methode in Selenium wird zum Suchen der Links auf der Seite verwendet, da sie ein Array (oder eine Liste) zurückgibt, das iteriert werden kann, um die Funktionsfähigkeit der Links zu überprüfen.
4. Durchlaufen der URLs zur Validierung
Die mit der Methode find_elements gefundenen Links werden in einer for-Schleife überprüft.
|
1
2
|
foreach (var Verknüpfung in Links)
{
|
Wir filtern die Links, die / E-Mail-Adressen / Telefonnummern / LinkedIn-Adressen enthalten. Die Links ohne Linktext werden ebenfalls herausgefiltert.
|
1
2
|
wenn (!(verknüpfen.Text.Enthält(„E-Mail“) || Link.Text.Enthält(„https://www.linkedin.com“) || Verknüpfung.Text == „“ // Verknüpfung.Gleich (null)))
{
|
Die GetAsync-Methode der HttpClient-Klasse sendet eine GET-Anforderung als asynchrone Operation an den entsprechenden URI. Das Argument für die GetAsync-Methode ist der Wert des Attributs ‚href‘ des Ankers, das mit der getAttribute-Methode erfasst wird.
Die Auswertung der asynchronen Methode wird durch den Operator await bis zum Abschluss der asynchronen Operation ausgesetzt. Nach Abschluss des asynchronen Vorgangs gibt der Operator await die HttpResponseMessage zurück, die die Daten und den Statuscode enthält.
|
1
2
3
|
/* Holen Sie sich den URI */
HttpResponseMessage response = await client.GetAsync(Verknüpfung.getAttribute(„href“));
System.Konsole.WriteLine($“URL: {Verknüpfung.getAttribute(„href“)} Status ist:{Antwort.StatusCode}“);
|
5. Validieren Sie die Links über den Statuscode
, wenn der HTTP-Antwortcode (dh response.StatusCode) für die in Schritt(4) gesendete HTTP-Anforderung ist HttpStatusCode.OK (dh 200) bedeutet, dass die Anforderung erfolgreich abgeschlossen wurde.
|
1
2
3
4
5
6
7
8
9
|
System.Console.WriteLine($“URL: {link.GetAttribute(„href“)} status is :{response.StatusCode}“);
if (response.StatusCode == HttpStatusCode.OK)
{
valid_links++;
}
else
{
broken_links++;
}
|
NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
|
1
2
3
4
5
6
7
8
|
catch (Exception ex)
{
if ((ex is ArgumentNullException) ||
(ex is NotSupportedException))
{
System.Console.WriteLine(„Exception occured\n“);
}
}
|
Ausführung
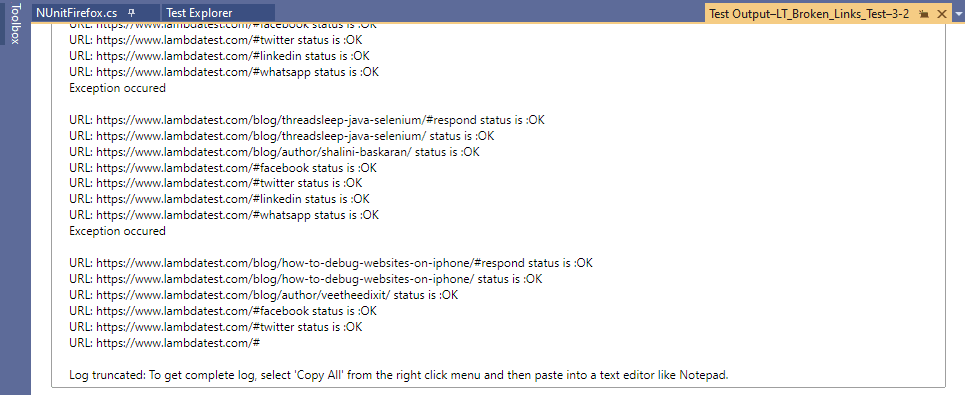
Hier ist der Ausführungs-Snapshot, der zeigt, dass der Test erfolgreich ausgeführt wurde.

Ausnahmen sind für Links zu den ‚Share Icons‘ aufgetreten, dh WhatsApp, Facebook, Twitter usw. Abgesehen von diesen Links geben die restlichen Links auf der LambdaTest-Blogseite HttpStatusCode zurück.OK (dh 200).
Testen defekter Links mit Selen PHP
Implementierung
Code WalkThrough
1. Lesen Sie die Seitenquelle
Die Funktion file_get_contents in PHP wird verwendet, um die HTML-Quelle der Seite in eine Zeichenfolgenvariable (z. B. $ html) einzulesen.
|
1
2
|
$ test_url = „https://www.lambdatest.com/blog/“;
$ html = datei_get_contents ($test_url);
|
2. Instanziieren der DOMDocument-Klasse
Die DOMDocument-Klasse in PHP repräsentiert ein gesamtes HTML-Dokument und dient als Stamm des Dokumentbaums.
|
1
|
$ htmlDom = neues DOMDocument;
|
3. HTML der Seite analysieren
Die Funktion DOMDocument::loadHTML() wird zum Analysieren der HTML-Quelle verwendet, die in $html enthalten ist. Bei erfolgreicher Ausführung gibt die Funktion ein DOMDocument-Objekt zurück.
|
1
|
@$ htmlDom->loadHTML($html);
|
4. Extrahieren Sie die Links von der Seite
Die auf der Seite vorhandenen Links werden mit der getElementsByTagName-Methode der DOMDocument-Klasse extrahiert. Die Elemente (oder Links) werden basierend auf dem ‚a‘-Tag aus der analysierten HTML-Quelle durchsucht.
Die Funktion getElementsByTagName gibt eine neue Instanz von DOMNodeList zurück, die die Elemente (oder Links) des lokalen Tag-Namens (z. tag)
|
1
|
$ links = $htmlDom->getElementsByTagName(‚a‘);
|
5. Durchlaufen der URLs zur Validierung
Die DOMNodeList, die in Schritt (4) erstellt wurde, wird durchlaufen, um die Gültigkeit der Links zu überprüfen.
|
1
2
3
|
foreach($links als $link)
{
$ linkText = $link->Knotenwert;
|
Die Details des entsprechenden Links werden mit dem Attribut ‚href‘ abgerufen. Die getAttribute-Methode wird für dasselbe verwendet.
|
1
|
$ linkHref = $link->getAttribute(‚href‘);
|
Überspringen Sie die Überprüfung der Links, wenn:
a. Der Link ist leer
|
1
2
3
4
|
wenn(strlen(trim($linkHref)) == 0)
{
weiter;
}
|
b. Der Link ist ein Hashtag oder ein Ankerlink
|
1
2
3
4
|
wenn($linkHref == ‚#‘)
{
weiter;
}
|
c. Der Link enthält mailto oder addtoany (d. h. Social-Sharing-Optionen).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
function check_nonlinks($test_url, $test_pattern)
{
wenn (preg_match($ test_pattern, $test_url) == falsch)
{
false zurückgeben;
}
sonst
{
rückgabe true;
}
}
öffentliche Funktion test_Broken_Links()
{
$ muster_1 = ‚/\baddtoany\b/‘;
$ pattern_2 = ‚/\bmailto\b/‘;
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
wenn ((check_nonlinks($linkHref, $pattern_1))||(check_nonlinks($linkHref, $pattern_2)))
{
print(„\nAdd_To_Any oder E-Mail gefunden“);
weiter;
}
…………………………………………………………..
…………………………………………………………..
…………………………………………………………..
}
|
die preg_match-Funktion verwendet einen regulären Ausdruck (regex), um eine Suche nach mailto und addtoany ohne Berücksichtigung der Groß- und Kleinschreibung durchzuführen. Die regulären Ausdrücke für mailto & addtoany sind ‚/\bmailto\b/‘ & ‚/\baddtoany\b/‘.
6. Validieren Sie den HTTP-Code mit cURL
Wir verwenden curl, um Informationen zum Status des entsprechenden Links zu erhalten. Der erste Schritt besteht darin, eine cURL-Sitzung mit dem ‚Link‘ zu initialisieren, für den die Validierung durchgeführt werden muss. Die Methode gibt eine cURL-Instanz zurück, die im letzten Teil der Implementierung verwendet wird.
|
1
|
$ curl = curl_init($linkHref);
|
Die Methode curl_setopt wird zum Festlegen von Optionen für das angegebene cURL-Sitzungshandle (dh $ curl) verwendet.
|
1
|
curl_setopt($curl, CURLOPT_NOBODY, wahr);
|
Die Methode curl_exec wird zur Ausführung der angegebenen cURL-Sitzung aufgerufen. Bei erfolgreicher Ausführung wird True zurückgegeben.
|
1
|
$ ergebnis = curl_exec($ curl);
|
Dies ist der wichtigste Teil der Logik, die nach defekten Links auf der Seite sucht. Die Funktion curl_getinfo, die das cURL-Sitzungshandle (dh $curl ) und CURLINFO_RESPONSE_CODE (dh. CURLINFO_HTTP_CODE) werden verwendet, um Informationen über die letzte Übertragung abzurufen. Es gibt HTTP-Statuscode als Antwort zurück.
|
1
|
$ statusCode = curl_getinfo($curl, CURLINFO_HTTP_CODE);
|
Nach erfolgreichem Abschluss der Anforderung wird der HTTP-Statuscode 200 zurückgegeben, und die Variable mit der Anzahl gültiger Links (d. h. $ valid_links) wird inkrementiert. Für Links, die den HTTP-Statuscode 400 (oder mehr) ergeben, wird geprüft, ob der ‚zu testende Link‘ die LinkedIn-Seite von LambdaTest war. Wie bereits erwähnt, lautet der Statuscode der LinkedIn-Seite 999; Daher wird $ valid_links inkrementiert.
Für alle anderen Links, die den HTTP-Statuscode 400 (oder mehr) zurückgegeben haben, wird die Variable, die die Anzahl der defekten Links enthält (d. h. $broken_links), inkrementiert.
|
1
2
3
4
5
6
7
8
9
10
|
wenn (($linkedin_page_status) && ($statusCode == 999))
{
drucken(„\nLink “ . $linkHref . “ ist LinkedIn-Seite und Status ist “ .$statusCode);
$validlinks++;
}
sonst
{
drucken(„\nLink “ . $linkHref . “ ist Link defekt und Status ist “ .$statusCode);
$gebrochene Links++;
}
|
Ausführung
Wir verwenden das PHPUnit-Framework zum Testen auf defekte Links auf der Seite. Fügen Sie zum Herunterladen des PHPUnit-Frameworks den Dateikomponisten hinzu.json im Stammordner und führen Sie composer require auf dem Terminal aus.
Führen Sie den folgenden Befehl auf dem Terminal aus, um defekte Links in Selenium PHP zu überprüfen.
|
1
|
hersteller \ bin \ phpunit tests \ BrokenLinksTest.php
|
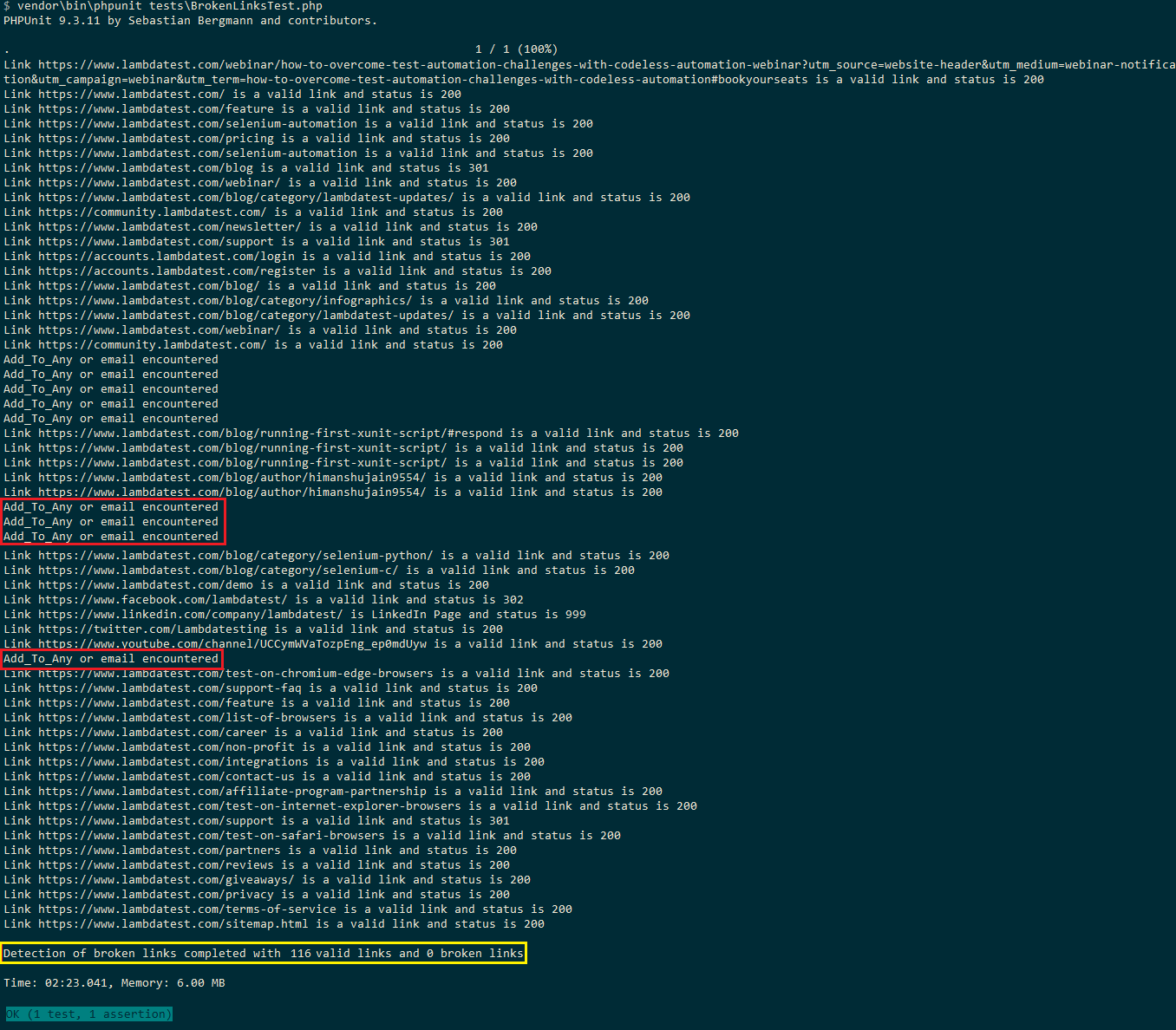
Hier ist der Ausführungs-Snapshot, der insgesamt 116 gültige Links und 0 defekte Links im LambdaTest-Blog zeigt. Da Links für das Teilen in sozialen Netzwerken (dh addtoany) und die E-Mail-Adresse ignoriert werden, beträgt die Gesamtzahl 116 (169 im Selenium Python-Test).
Fazit

Defekte Links, auch tote Links oder verrottete Links genannt, können die Benutzererfahrung beeinträchtigen, wenn sie auf der Website vorhanden sind. Defekte Links können sich auch auf das Ranking in Suchmaschinen auswirken. Daher sollten Broken Link-Tests regelmäßig für Aktivitäten im Zusammenhang mit der Entwicklung und dem Testen von Websites durchgeführt werden.
Anstatt sich auf Tools von Drittanbietern oder manuelle Methoden zum Überprüfen fehlerhafter Links auf einer Website zu verlassen, können fehlerhafte Links mit Selenium WebDriver mit Java, Python, C # oder PHP getestet werden. Der HTTP-Statuscode, der beim Zugriff auf eine Webseite zurückgegeben wird, sollte verwendet werden, um defekte Links mithilfe des Selenium-Frameworks zu überprüfen.
Häufig gestellte Fragen
Wie finde ich defekte Links in Selenium Python?
Um die defekten Links zu überprüfen, müssen Sie alle Links auf der Webseite basierend auf dem Tag sammeln. Senden Sie dann eine HTTP-Anforderung für die Links und lesen Sie den HTTP-Antwortcode. Finden Sie anhand des HTTP-Antwortcodes heraus, ob der Link gültig oder fehlerhaft ist.
Wie überprüfe ich defekte Links?
Gehen Sie folgendermaßen vor, um Ihre Website mithilfe der Google Search Console kontinuierlich auf fehlerhafte Links zu überwachen:
- Melden Sie sich bei Ihrem Google Search Console-Konto an.
- Klicken Sie auf die Site, die Sie überwachen möchten.
- Klicken Sie auf Crawlen und dann auf Als Google abrufen.
- Nachdem Google die Website gecrawlt hat, klicken Sie auf Crawlen und dann auf Crawling-Fehler, um auf die Ergebnisse zuzugreifen.
- Unter URL-Fehler können Sie alle defekten Links sehen, die Google während des Crawling-Prozesses entdeckt hat.
Wie finde ich defekte Bilder im Web mit Selenium?
Besuchen Sie die Seite. Durchlaufen Sie jedes Bild im HTTP-Archiv und prüfen Sie, ob es einen 404-Statuscode enthält. Speichern Sie jedes defekte Bild in einer Sammlung. Überprüfen Sie, ob die Sammlung defekter Bilder leer ist.
Wie bekomme ich alle Links in Selenium?
Sie können alle Links auf einer Webseite basierend auf dem <a> Tag vorhanden. Jedes <a> -Tag repräsentiert einen Link. Verwenden Sie die Selenium Locators, um alle diese Tags einfach zu finden.
Warum sind defekte Links schlecht?
Sie können die Benutzererfahrung beeinträchtigen – Wenn Benutzer auf Links klicken und Sackgassen-404-Fehler erreichen, werden sie frustriert und kehren möglicherweise nie wieder zurück. Sie entwerten Ihre SEO–Bemühungen – Defekte Links schränken den Fluss des Link-Equity auf Ihrer Website ein und wirken sich negativ auf das Ranking aus.

Himanshu Sheth
Himanshu Sheth ist ein erfahrener Technologe und Blogger mit mehr als 15 Jahren vielfältiger Berufserfahrung. Derzeit arbeitet er als ‚Lead Developer Evangelist‘ und ‚Senior Manager‘ bei LambdaTest. Er ist sehr aktiv in der Startup-Community in Bengaluru (und im Süden) und liebt es, mit leidenschaftlichen Gründern auf seinem persönlichen Blog (den er seit über 15 Jahren pflegt) zu interagieren.