




So prüfen Sie auf doppelten Inhalt
So finden Sie doppelten Inhalt
Doppelte Inhalte sollten auf einer Website minimiert werden, da dies es Suchmaschinen erschweren kann, zu entscheiden, welche Version für eine Abfrage eingestuft werden soll.
Während eine ‚Duplicate Content Penalty‘ in SEO ein Mythos ist, können sehr ähnliche Inhalte Crawling-Ineffizienzen verursachen, den PageRank verwässern und ein Zeichen für Inhalte sein, die konsolidiert, entfernt oder verbessert werden könnten.
Es ist wichtig, sich daran zu erinnern, dass doppelte und ähnliche Inhalte ein natürlicher Teil des Webs sind, was für Suchmaschinen oft kein Problem darstellt, die URLs von Natur aus kanonisieren und gegebenenfalls filtern. Im Maßstab kann es jedoch problematischer sein.
Durch das Verhindern von Duplicate Content haben Sie die Kontrolle darüber, was indiziert und eingestuft wird, anstatt es den Suchmaschinen zu überlassen. Sie können die Verschwendung von Crawl-Budgets begrenzen und Indizierungs- und Linksignale konsolidieren, um das Ranking zu verbessern.
In diesem Tutorial erfahren Sie, wie Sie mit dem Screaming Frog SEO Spider sowohl exakten doppelten Inhalt als auch nahezu doppelten Inhalt finden, bei dem Text zwischen Seiten einer Website übereinstimmt.
Doppelte Inhalte, die von einem Tool, einschließlich des SEO Spider, identifiziert wurden, müssen im Kontext überprüft werden. Sehen Sie sich unser Video an oder lesen Sie unseren Leitfaden weiter unten.
Laden Sie zunächst den SEO Spider herunter, der kostenlos zum Crawlen von bis zu 500 URLs geeignet ist. Die ersten 2 Schritte sind nur mit einer Lizenz verfügbar. Wenn Sie ein kostenloser Benutzer sind, springen Sie zu Nummer 3 im Handbuch.
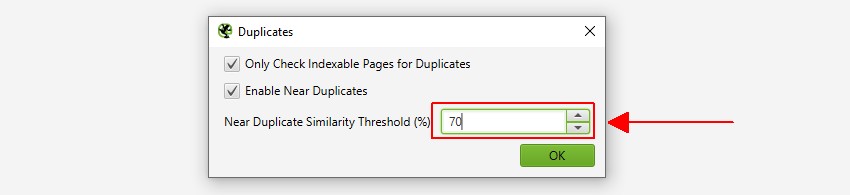
1) Aktivieren Sie ‚Near Duplicates‘ Über ‚Config > Content > Duplicates‘
Standardmäßig identifiziert der SEO Spider automatisch exakte doppelte Seiten. Um jedoch ‚Near Duplicates‘ zu identifizieren, muss die Konfiguration aktiviert sein, damit der Inhalt jeder Seite gespeichert werden kann.
Der SEO Spider identifiziert nahezu Duplikate mit einer Ähnlichkeitsübereinstimmung von 90%, die angepasst werden kann, um Inhalte mit einer niedrigeren Ähnlichkeitsschwelle zu finden.
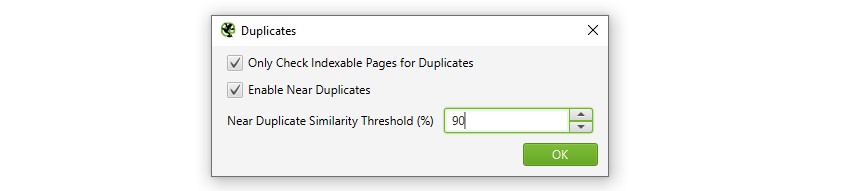
Der SEO Spider überprüft auch nur ‚indexierbare‘ Seiten auf Duplikate (sowohl für exakte als auch für nahezu Duplikate).
Wenn Sie also zwei URLs haben, die identisch sind, aber eine für die andere kanonisiert ist (und daher ’nicht indexierbar‘ ist), wird dies nicht gemeldet – es sei denn, diese Option ist deaktiviert.
Wenn Sie Probleme mit dem Crawling-Budget finden möchten, deaktivieren Sie die Option ‚Nur indizierbare Seiten auf Duplikate prüfen‘, da dies dazu beitragen kann, Bereiche mit potenzieller Crawling-Verschwendung zu finden.
2) ‚Inhaltsbereich‘ für die Analyse anpassen Über ‚Config > Content > Area‘
Sie können den Inhalt konfigurieren, der für die nahezu doppelte Analyse verwendet wird. Für eine neue Durchforstung empfehlen wir, die Standardeinstellung zu verwenden und sie später zu verfeinern, wenn der in der Analyse verwendete Inhalt angezeigt und berücksichtigt werden kann.
Der SEO Spider schließt automatisch sowohl die Nav- als auch die Footer-Elemente aus, um sich auf den Haupttext zu konzentrieren. Allerdings wird nicht jede Website mit diesen HTML5-Elementen erstellt, sodass Sie den für die Analyse verwendeten Inhaltsbereich bei Bedarf verfeinern können. Sie können HTML-Tags, Klassen und IDs in die Analyse einbeziehen oder ausschließen.
Die Screaming Frog-Website verfügt beispielsweise über ein mobiles Menü außerhalb des nav-Elements, das standardmäßig in der Inhaltsanalyse enthalten ist. Dies ist zwar kein großes Problem, aber in diesem Fall kann der Klassenname ‚mobile-menu__dropdown‘ in das Feld ‚Klassen ausschließen‘ eingegeben werden, um sich auf den Haupttext der Seite zu konzentrieren.
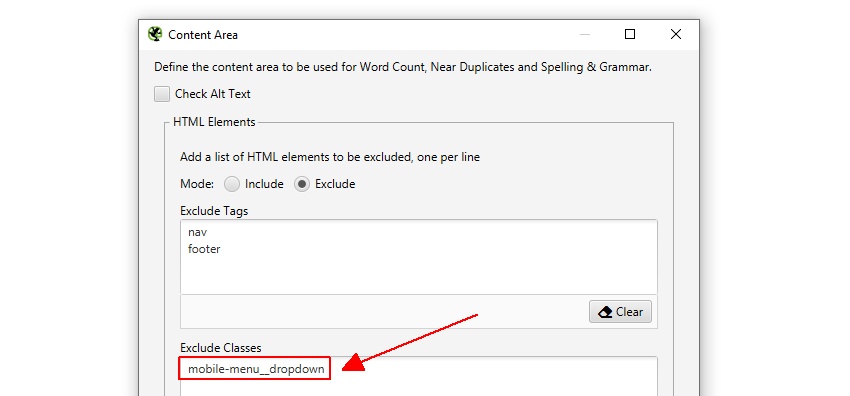
Dadurch wird das Menü von der Aufnahme in den Duplicate Content Analysis-Algorithmus ausgeschlossen. Dazu später mehr.
3) Crawlen Sie die Website
Öffnen Sie den SEO Spider, geben Sie die Website, die Sie crawlen möchten, in das Feld ‚URL zum Spider eingeben‘ ein oder kopieren Sie sie und klicken Sie auf ‚Start‘.
Warten Sie, bis der Crawling abgeschlossen ist und 100% erreicht hat.
4) Duplikate auf der Registerkarte ‚Inhalt‘ anzeigen
Die Registerkarte Inhalt verfügt über 2 Filter für doppelten Inhalt, ‚genaue Duplikate‘ und ’nahe Duplikate‘.
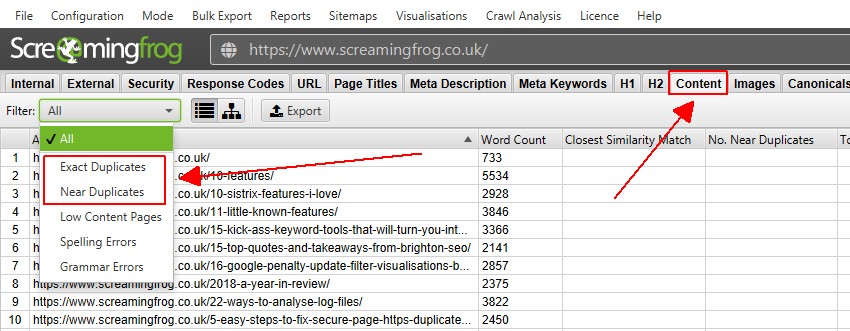
Nur ‚exakte Duplikate‘ können während eines Crawlings in Echtzeit angezeigt werden. ‚Near Duplicates‘ erfordern eine Berechnung am Ende des Crawls per Post ‚Crawl Analysis‘, damit es mit Daten gefüllt werden kann.
Im rechten Bereich ‚Übersicht‘ wird die Meldung ‚(Crawling-Analyse erforderlich)‘ für Filter angezeigt, für die eine Post-Crawling-Analyse mit Daten gefüllt werden muss.
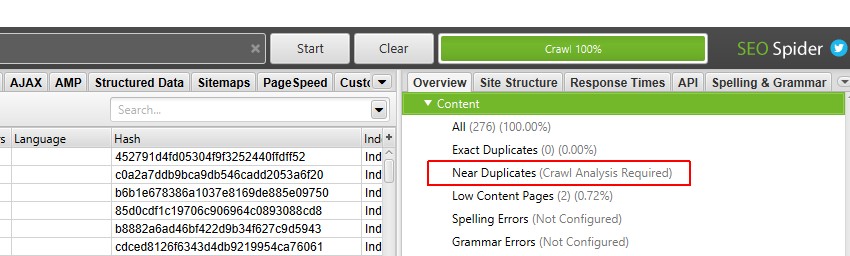
5) Klicken Sie auf ‚Crawling-Analyse > Start‘, um den Filter ‚In der Nähe von Duplikaten‘ zu füllen
Um den Filter ‚In der Nähe von Duplikaten‘, die ‚engste Ähnlichkeitsübereinstimmung‘ und ‚Nein. In der Nähe der Spalten von Duplikaten müssen Sie nur auf eine Schaltfläche am Ende des Crawls klicken.

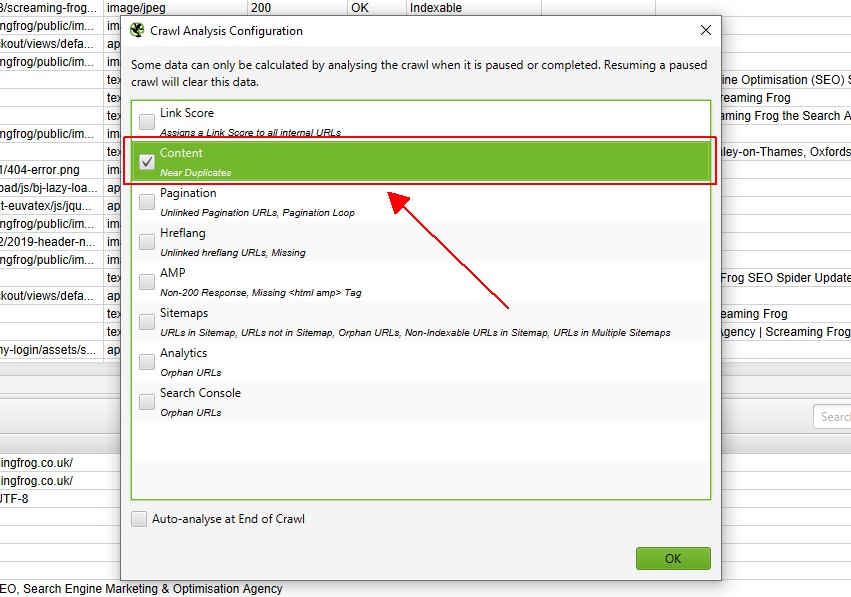
Wenn Sie jedoch ‚Durchforstungsanalyse‘ zuvor konfiguriert haben, sollten Sie unter ‚Durchforstungsanalyse > Konfigurieren‘ überprüfen, ob ‚Nahe Duplikate‘ aktiviert ist.
Sie können auch andere Elemente deaktivieren, die ebenfalls eine Analyse nach dem Crawlen erfordern, um diesen Schritt zu beschleunigen.
Wenn die Crawl-Analyse abgeschlossen ist, wird der Fortschrittsbalken ‚Analyse‘ auf 100% angezeigt und die Filter haben nicht mehr die Meldung ‚(Crawl-Analyse erforderlich)‘.
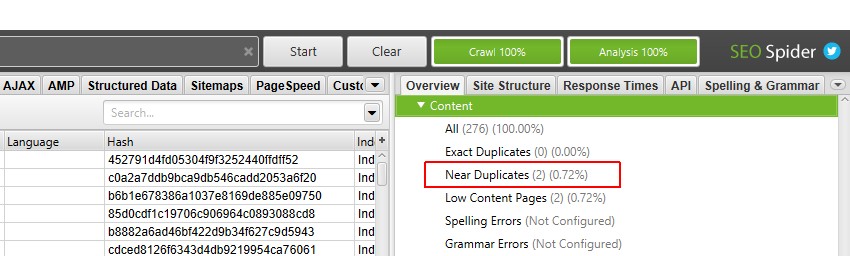
Sie können jetzt den ausgefüllten Filter und die Spalten für nahezu Duplikate anzeigen.
6) Registerkarte ‚Inhalt‘ anzeigen & ‚Genau‘ & ‚Nahe‘ Duplikatfilter
Nach Durchführung der Post-Crawl-Analyse werden der Filter ‚Nahe Duplikate‘, die ‚Engste Ähnlichkeitsübereinstimmung‘ und ‚Nein. Die Spalten in der Nähe von Duplikaten werden ausgefüllt. Nur URLs mit Inhalten über dem ausgewählten Ähnlichkeitsschwellenwert enthalten Daten, die anderen bleiben leer. In diesem Fall hat die Screaming Frog-Website nur zwei.
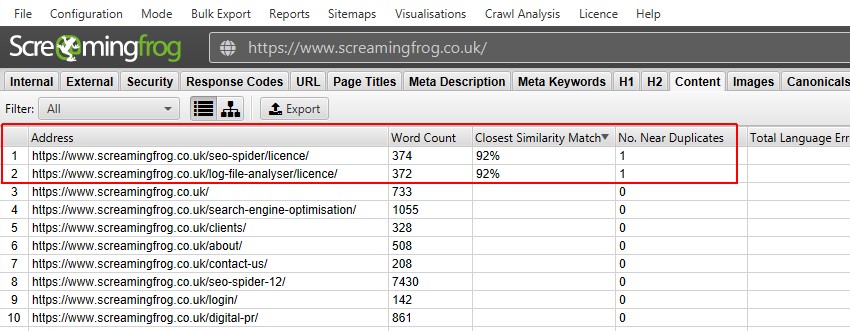
Ein Crawlen einer größeren Website wie der BBC wird viele weitere enthüllen.
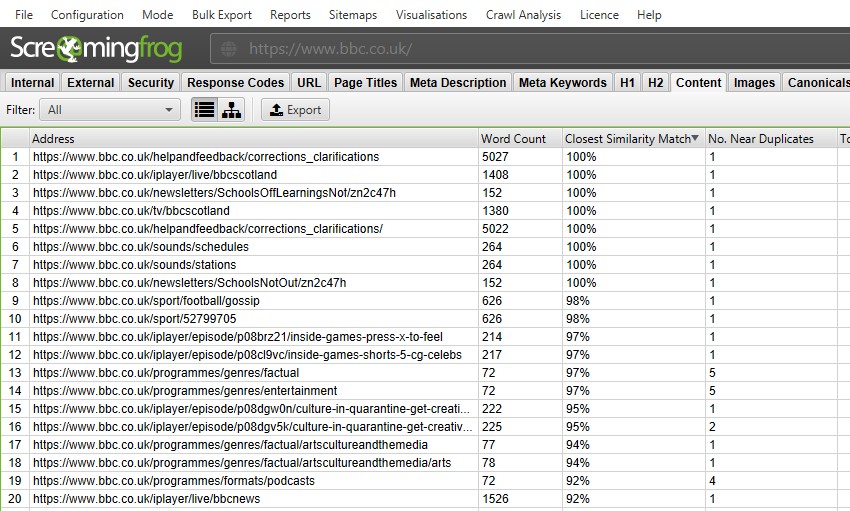
Sie können nach folgendem filtern –
- Exakte Duplikate – Dieser Filter zeigt Seiten an, die mit dem MD5-Algorithmus identisch sind, der für jede Seite einen Hash-Wert berechnet und in der Spalte Hash angezeigt wird. Diese Prüfung wird anhand des vollständigen HTML-Codes der Seite durchgeführt. Es werden alle Seiten mit übereinstimmenden Hash-Werten angezeigt, die genau gleich sind. Genaue doppelte Seiten können zur Aufteilung von PageRank-Signalen und Unvorhersehbarkeit im Ranking führen. Es sollte nur eine einzige kanonische Version einer URL geben, die existiert und mit der intern verlinkt wird. Andere Versionen sollten nicht verknüpft werden, und sie sollten 301 auf die kanonische Version umgeleitet werden.
- In der Nähe von Duplikaten – Dieser Filter zeigt ähnliche Seiten basierend auf dem konfigurierten Ähnlichkeitsschwellenwert mithilfe des Minhash-Algorithmus an. Der Schwellenwert kann unter ‚Config > Spider > Content‘ eingestellt werden und ist standardmäßig auf 90% eingestellt. In der Spalte ‚Nächste Ähnlichkeitsübereinstimmung‘ wird der höchste Prozentsatz der Ähnlichkeit mit einer anderen Seite angezeigt. Das ‚Nein. In der Spalte ‚Duplikate‘ wird die Anzahl der Seiten angezeigt, die der Seite ähnlich sind, basierend auf dem Ähnlichkeitsschwellenwert. Der Algorithmus wird gegen Text auf der Seite und nicht gegen den vollständigen HTML-Code wie exakte Duplikate ausgeführt. Der für diese Analyse verwendete Inhalt kann unter ‚Config > Content > Area‘ konfiguriert werden. Seiten können eine 100% ige Ähnlichkeit haben, aber nur ein ’near Duplicate‘ und kein exaktes Duplikat sein. Dies liegt daran, dass exakte Duplikate als nahe Duplikate ausgeschlossen werden, um zu vermeiden, dass sie zweimal markiert werden. Ähnlichkeitswerte werden ebenfalls gerundet, sodass 99,5% oder mehr als 100% angezeigt werden.
Nahezu doppelte Seiten sollten manuell überprüft werden, da es viele legitime Gründe dafür gibt, dass einige Seiten inhaltlich sehr ähnlich sind, z. B. Variationen von Produkten mit Suchvolumen um ihr spezifisches Attribut.
URLs, die als nahezu Duplikate gekennzeichnet sind, sollten jedoch überprüft werden, um zu prüfen, ob sie aufgrund ihres eindeutigen Werts für den Benutzer als separate Seiten vorhanden sein sollten oder ob sie entfernt, konsolidiert oder verbessert werden sollten, um den Inhalt detaillierter und einzigartiger zu machen.
7) Zeigen Sie doppelte URLs über die Registerkarte ‚Doppelte Details‘ an
Für ‚genaue Duplikate‘ ist es einfacher, sie mithilfe des Filters im oberen Fenster anzuzeigen – da sie gruppiert sind und denselben ‚Hash‘ -Wert haben.
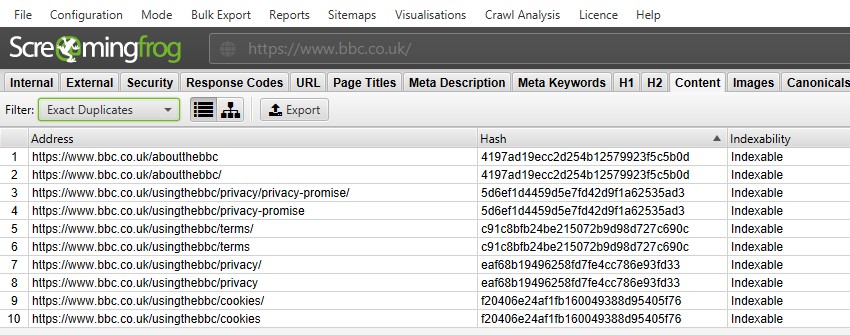
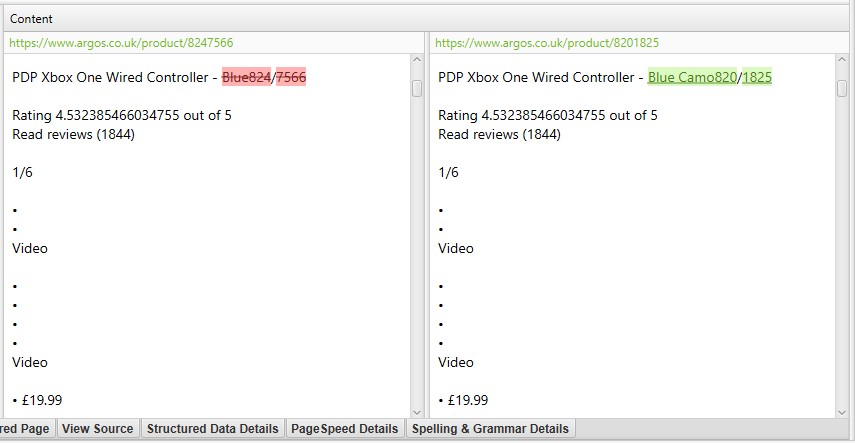
Im obigen Screenshot hat jede URL aufgrund eines Schrägstrichs und einer Version ohne Schrägstrich ein entsprechendes genaues Duplikat.
Klicken Sie für ’near duplicates‘ unten auf die Registerkarte ‚Duplicate Details‘, die den unteren Fensterbereich mit der ’near duplicate address‘ und der Ähnlichkeit jeder entdeckten Near-duplicate URL füllt.
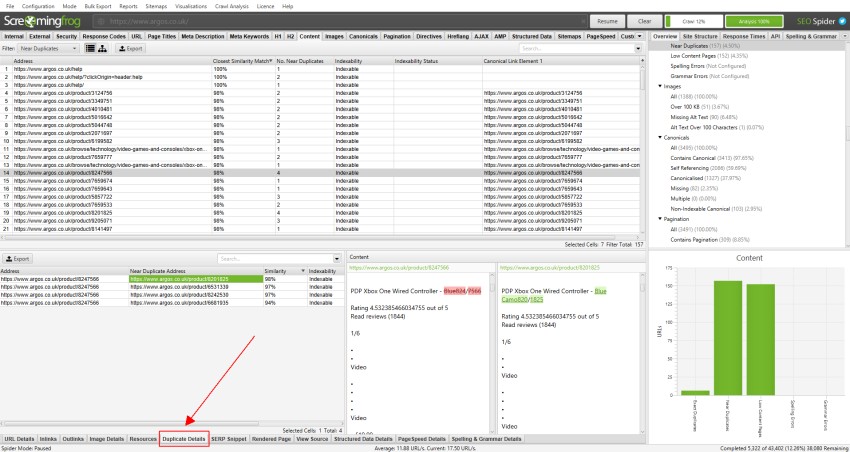
Wenn beispielsweise im oberen Fenster 4 nahezu Duplikate für eine URL gefunden wurden, können diese alle angezeigt werden.
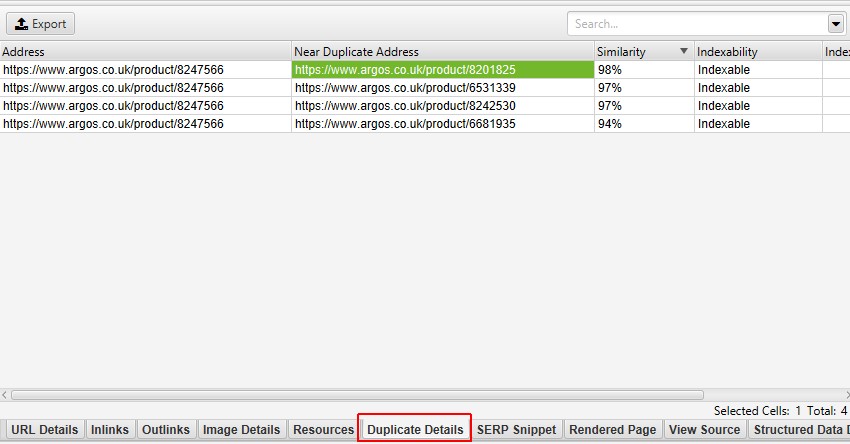
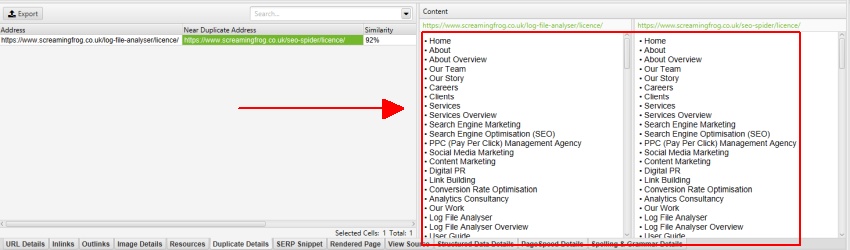
Die rechte Seite der Registerkarte ‚Doppelte Details‘ zeigt den nahezu doppelten Inhalt an, der auf den Seiten entdeckt wurde, und hebt die Unterschiede zwischen den Seiten hervor, wenn Sie auf jede ’nahezu doppelte Adresse‘ klicken.
Wenn auf der Registerkarte Duplicate Details Duplicate Content vorhanden ist, den Sie nicht an der Duplicate Content-Analyse teilnehmen möchten, schließen Sie HTML-Elemente, -Klassen oder -IDs aus oder schließen Sie sie ein (wie in Punkt 2 hervorgehoben), & Führen Sie die Crawling-Analyse erneut aus.
8) Massenexportduplikate
Über die Exporte ‚Massenexport > Inhalt > Genaue Duplikate‘ und ‚Nahe Duplikate‘ können sowohl exakte als auch nahezu Duplikate in großen Mengen exportiert werden.

Letzter Tipp! Ähnlichkeitsschwelle verfeinern & Inhaltsbereich, & Crawling-Analyse erneut ausführen
Nach dem Crawlen Sie können sowohl den Ähnlichkeitsschwellenwert für nahezu doppelte Ähnlichkeiten als auch den Inhaltsbereich für nahezu doppelte Analysen anpassen.
Sie können dann die Crawling-Analyse erneut ausführen, um mehr oder weniger ähnliche Inhalte zu finden – ohne die Website erneut zu crawlen.
Wie bereits erwähnt, verfügt die Screaming Frog-Website über ein mobiles Menü außerhalb des nav-Elements, das standardmäßig in der Inhaltsanalyse enthalten ist. Das mobile Menü ist in der Inhaltsvorschau der Registerkarte ‚Doppelte Details‘ zu sehen.
Durch Ausschluss des ‚mobile-menu__dropdown‘ im Feld ‚Exclude Classes‘ unter ‚Config > Content > Area‘ wird das mobile Menü aus der Inhaltsvorschau und der Near-Duplicate-Analyse entfernt.
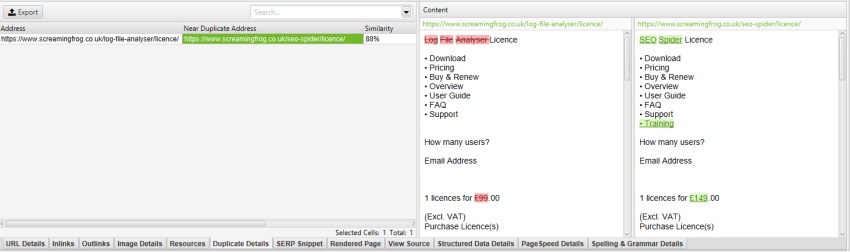
Dies kann bei der Feinabstimmung der Identifizierung nahezu doppelten Inhalts für Hauptinhaltsbereiche sehr hilfreich sein, ohne dass erneut gecrawlt werden muss.
Zusammenfassung
Die obige Anleitung soll veranschaulichen, wie Sie den SEO Spider als Duplicate Content Checker für Ihre Website verwenden. Um die genauesten Ergebnisse zu erzielen, verfeinern Sie den Inhaltsbereich für die Analyse und passen Sie den Schwellenwert für verschiedene Seitengruppen an.
Bitte lesen Sie auch unsere Screaming Frog SEO Spider FAQs und das vollständige Benutzerhandbuch, um weitere Informationen zum Tool zu erhalten.
Wenn Sie weitere Fragen, Feedback oder Vorschläge zur Verbesserung des Duplicate Content Tools im SEO Spider haben, dann kontaktieren Sie uns einfach über den Support.