




Come controllare il contenuto duplicato
Come trovare il contenuto duplicato
Il contenuto duplicato dovrebbe essere ridotto al minimo in un sito Web, in quanto può rendere difficile per i motori di ricerca decidere quale versione classificare per una query.
Mentre una “penalità di contenuto duplicato” è un mito nel SEO, contenuti molto simili possono causare inefficienze di scansione, diluire il PageRank ed essere un segno di contenuti che potrebbero essere consolidati, rimossi o migliorati.
Vale la pena ricordare che i contenuti duplicati e simili sono una parte naturale del web, che spesso non è un problema per i motori di ricerca che, per progettazione, canonicalizzano gli URL e li filtrano dove appropriato. Tuttavia, su scala può essere più problematico.
Prevenire contenuti duplicati ti mette in controllo su ciò che è indicizzato e classificato, piuttosto che lasciarlo ai motori di ricerca. È possibile limitare gli sprechi di budget di scansione e consolidare i segnali di indicizzazione e collegamento per aiutare nella classifica.
Questo tutorial ti guida su come utilizzare Screaming Frog SEO Spider per trovare sia contenuti duplicati esatti che contenuti quasi duplicati in cui alcuni testi corrispondono tra le pagine di un sito web.
Il contenuto duplicato identificato da qualsiasi strumento, incluso lo spider SEO, deve essere rivisto nel contesto. Guarda il nostro video o continua a leggere la nostra guida qui sotto.
Per iniziare, scaricare il SEO Spider che è gratuito per la scansione fino a 500 URL. I primi 2 passi sono disponibili solo con una licenza. Se sei un utente gratuito, quindi passare al numero 3 nella guida.
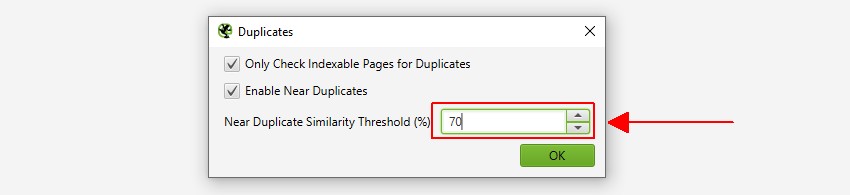
1) Abilita ‘Near Duplicates’ Tramite ‘Config > Content > Duplicates’
Per impostazione predefinita, SEO Spider identificherà automaticamente le pagine duplicate esatte. Tuttavia, per identificare ‘Quasi duplicati’ la configurazione deve essere abilitata, che consente di memorizzare il contenuto di ogni pagina.
Lo spider SEO identificherà i duplicati vicini con una corrispondenza di somiglianza del 90%, che può essere regolata per trovare contenuti con una soglia di somiglianza inferiore.
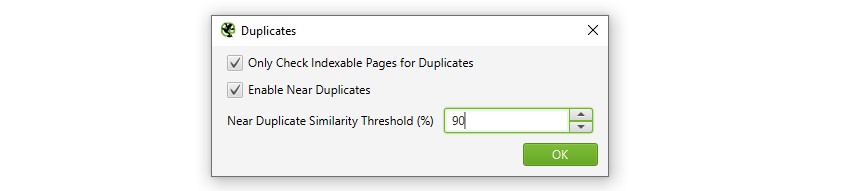
Il SEO Spider controllerà anche solo le pagine “indicizzabili” per i duplicati (sia per i duplicati esatti che quasi).
Ciò significa che se hai due URL uguali, ma uno è canonicalizzato all’altro (e quindi “non indicizzabile”), questo non verrà segnalato, a meno che questa opzione non sia disabilitata.
Se sei interessato a trovare problemi di budget di scansione, deseleziona l’opzione “Controlla solo le pagine indicizzabili per i duplicati”, in quanto ciò può aiutare a trovare aree di potenziali rifiuti di scansione.
2) Regolare ‘Area contenuto’ Per l’analisi Tramite ‘Config > Contenuto> Area’
È possibile configurare il contenuto utilizzato per l’analisi quasi duplicata. Per una nuova scansione, si consiglia di utilizzare la configurazione predefinita e perfezionarla in un secondo momento quando il contenuto utilizzato nell’analisi può essere visto e considerato.
Il SEO Spider escluderà automaticamente sia il nav e piè di pagina elementi di concentrarsi sul contenuto del corpo principale. Tuttavia, non tutti i siti Web sono costruiti utilizzando questi elementi HTML5, quindi sei in grado di perfezionare l’area del contenuto utilizzata per l’analisi, se necessario. Puoi scegliere di’ includere ‘o’ escludere ‘ tag HTML, classi e ID nell’analisi.
Ad esempio, il sito web Screaming Frog ha un menu mobile al di fuori dell’elemento nav, che è incluso nell’analisi dei contenuti per impostazione predefinita. Anche se questo non è molto di un problema, in questo caso, per aiutare a concentrarsi sul testo del corpo principale della pagina il suo nome di classe ‘mobile-menu__dropdown’ può essere inserito nella casella ‘Escludi classi’.
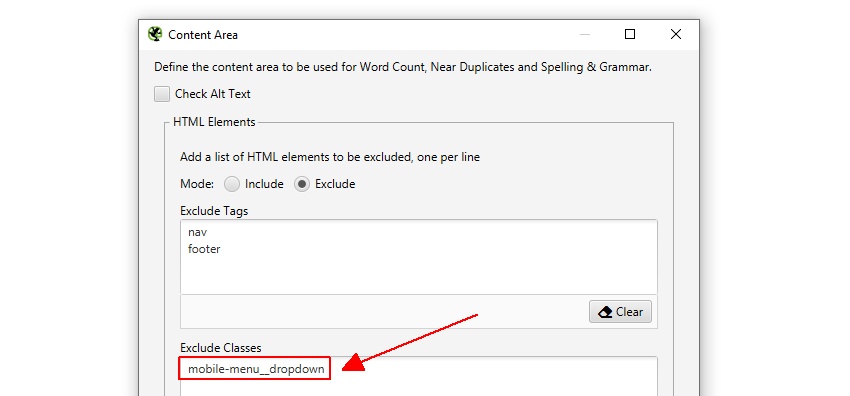
Questo escluderà il menu dall’inclusione nell’algoritmo di analisi del contenuto duplicato. Più su questo più tardi.
3) Eseguire la scansione del sito Web
Aprire il SEO Spider, digitare o copiare nel sito web che si desidera eseguire la scansione nella casella ‘Inserisci URL a spider’ e premere ‘Start’.
Attendi che la scansione finisca e raggiunga il 100%, ma puoi anche visualizzare alcuni dettagli in tempo reale.
4) Visualizza i duplicati Nella scheda’ Contenuto ‘
La scheda Contenuto ha 2 filtri relativi al contenuto duplicato,’ duplicati esatti ‘e’duplicati vicini’.
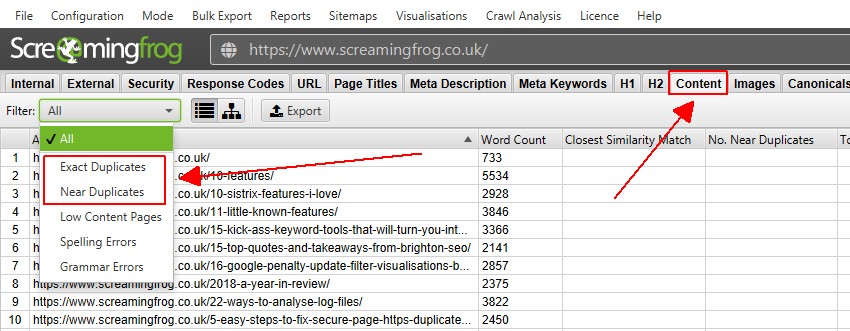
Solo ‘duplicati esatti’ è disponibile per la visualizzazione in tempo reale durante una scansione. ‘Near Duplicates’ richiede il calcolo alla fine della scansione tramite post ‘Crawl Analysis’ per essere popolato con i dati.
Il riquadro “panoramica” a destra visualizza un messaggio “(Analisi scansione richiesta) ” contro i filtri che richiedono che l’analisi scansione post venga compilata con i dati.
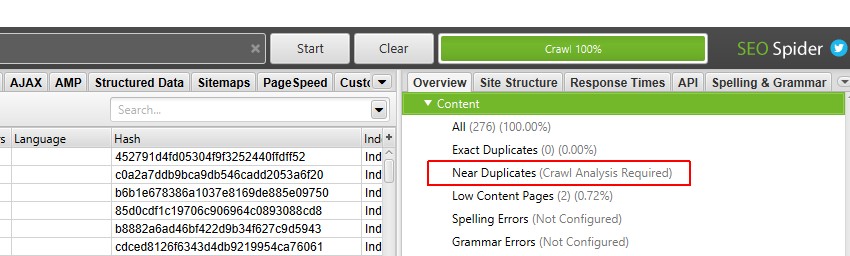
5) Fare clic su ‘Analisi scansione >Inizio’ Per popolare il filtro ‘Vicino duplicati’
Per popolare il filtro ‘Vicino duplicati’, la ‘Corrispondenza somiglianza più vicina’ e ‘No. Vicino alle colonne dei duplicati, devi solo fare clic su un pulsante alla fine della scansione.

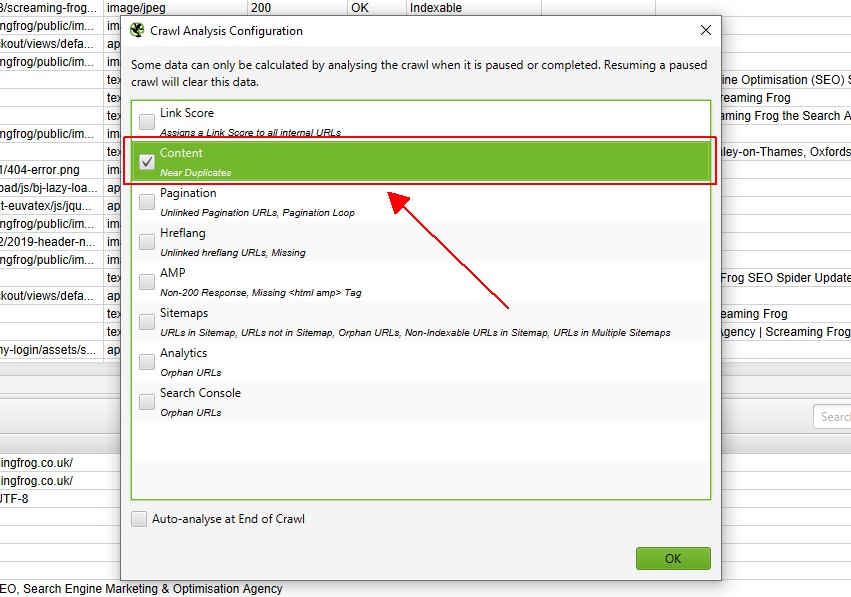
Tuttavia, se hai configurato “Analisi di scansione” in precedenza, potresti voler ricontrollare, sotto “Analisi di scansione > Configura” che “Vicino ai duplicati” è spuntato.
Puoi anche deselezionare altri elementi che richiedono anche l’analisi post crawl per rendere questo passaggio più veloce.
Quando l’analisi scansione è completata, la barra di avanzamento “analisi” sarà al 100% e i filtri non avranno più il messaggio ” (Analisi scansione richiesta)”.
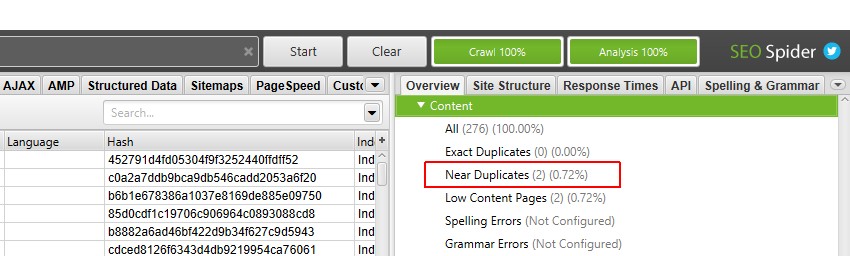
Ora è possibile visualizzare il filtro e le colonne near-duplicate popolate.
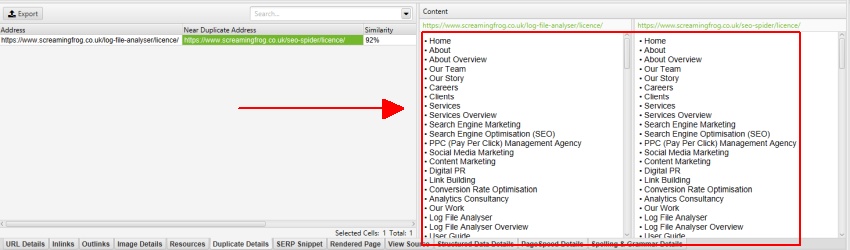
6) Visualizza la scheda’ Content ‘ &’ Exact ‘&’ Near ‘Duplica i filtri
Dopo aver eseguito l’analisi post crawl, il filtro ‘Near Duplicates’, il ‘ Closest Similarity Match ‘e’ No. Le colonne vicino ai duplicati verranno popolate. Solo gli URL con contenuto oltre la soglia di somiglianza selezionata conterranno dati, gli altri rimarranno vuoti. In questo caso, il sito web Urlando rana ha solo due.
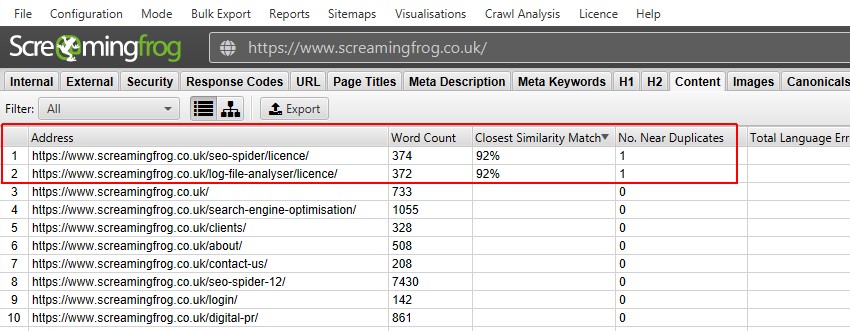
Una scansione di un sito web più grande, come la BBC rivelerà molti altri.
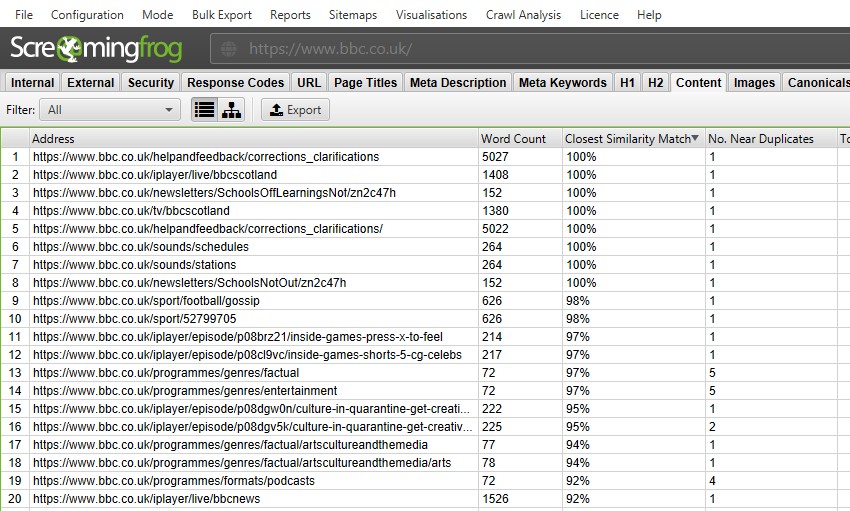
Sei in grado di filtrare in base alle seguenti–
- Duplicati esatti-Questo filtro mostrerà le pagine che sono identiche tra loro utilizzando l’algoritmo MD5 che calcola un valore ‘hash’ per ogni pagina e può essere visto nella colonna ‘hash’. Questo controllo viene eseguito contro l’intero HTML della pagina. Mostrerà tutte le pagine con valori hash corrispondenti che sono esattamente gli stessi. Le pagine duplicate esatte possono portare alla divisione dei segnali di PageRank e all’imprevedibilità nella classifica. Dovrebbe esserci solo una singola versione canonica di un URL che esiste ed è collegato internamente. Altre versioni non dovrebbero essere collegate a, e dovrebbero essere 301 reindirizzati alla versione canonica.
- Vicino ai duplicati: questo filtro mostrerà pagine simili in base alla soglia di somiglianza configurata utilizzando l’algoritmo minhash. La soglia può essere regolata in ‘Config > Spider > Contenuto’ ed è impostata al 90% per impostazione predefinita. La colonna “Corrispondenza somiglianza più vicina” mostra la percentuale più alta di somiglianza con un’altra pagina. Il ‘ No. La colonna Near Duplicates mostra il numero di pagine simili alla pagina in base alla soglia di somiglianza. L’algoritmo viene eseguito contro il testo sulla pagina, piuttosto che l’HTML completo come duplicati esatti. Il contenuto utilizzato per questa analisi può essere configurato in ‘Config > Content > Area’. Le pagine possono avere una somiglianza del 100%, ma essere solo un “duplicato vicino” piuttosto che un duplicato esatto. Questo perché i duplicati esatti sono esclusi come duplicati vicini, per evitare che vengano contrassegnati due volte. Anche i punteggi di somiglianza sono arrotondati, quindi il 99,5% o superiore verrà visualizzato come 100%.
Le pagine duplicate vicine dovrebbero essere riviste manualmente poiché ci sono molte ragioni legittime per cui alcune pagine sono molto simili nel contenuto, come le variazioni di prodotti che hanno un volume di ricerca attorno al loro attributo specifico.
Tuttavia, gli URL contrassegnati come quasi duplicati dovrebbero essere esaminati per valutare se dovrebbero esistere come pagine separate a causa del loro valore univoco per l’utente o se dovrebbero essere rimossi, consolidati o migliorati per rendere il contenuto più approfondito e unico.
7) Visualizza URL duplicati tramite la scheda ‘Dettagli duplicati’
Per ‘duplicati esatti’, è più facile visualizzarli nella finestra in alto utilizzando il filtro, poiché sono raggruppati e condividono lo stesso valore ‘hash’.
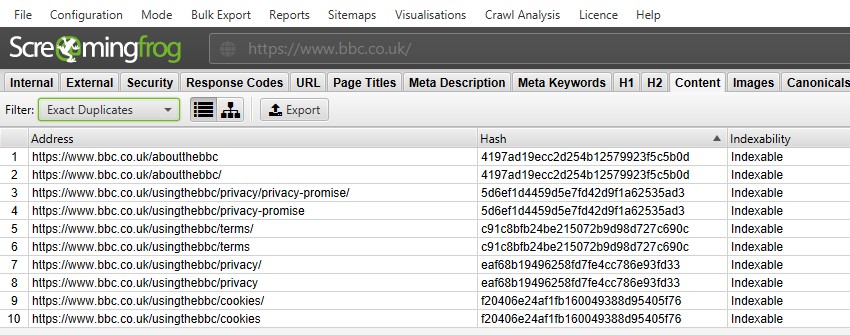
Nello screenshot qui sopra, ogni URL ha un duplicato esatto corrispondente a causa di una barra finale e di una versione barra non finale.
Per “duplicati vicini”, fai clic sulla scheda “Dettagli duplicati” in basso che popola il riquadro della finestra inferiore con l’indirizzo “quasi duplicato” e la somiglianza di ogni URL quasi duplicato scoperto.
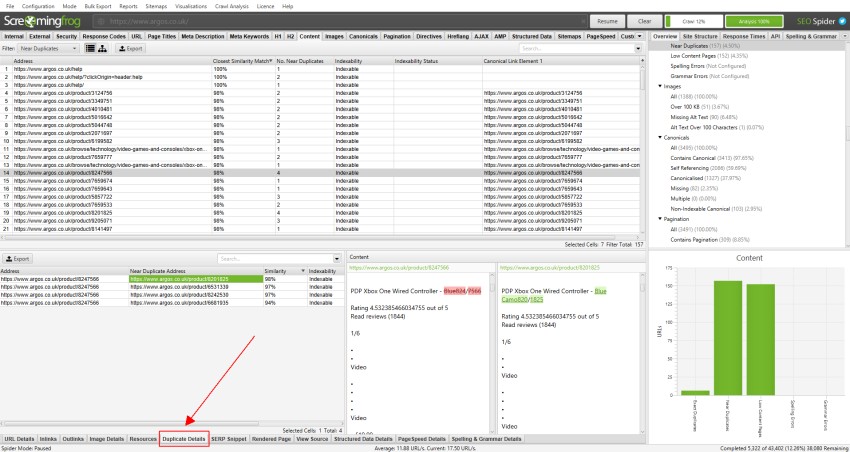
Ad esempio, se ci sono 4 duplicati quasi scoperti per un URL nella finestra in alto, questi possono essere visualizzati tutti.
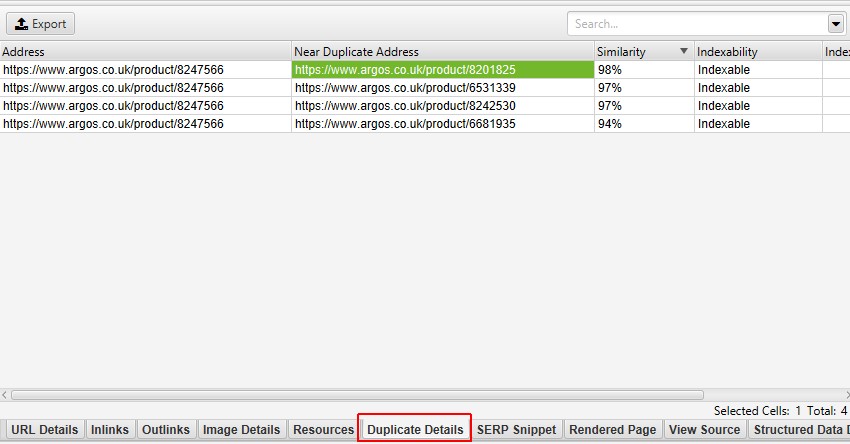
Il lato destro della scheda ‘Dettagli duplicati’ mostrerà il contenuto duplicato vicino scoperto dalle pagine ed evidenzierà le differenze tra le pagine quando si fa clic su ciascun ‘indirizzo duplicato vicino’.
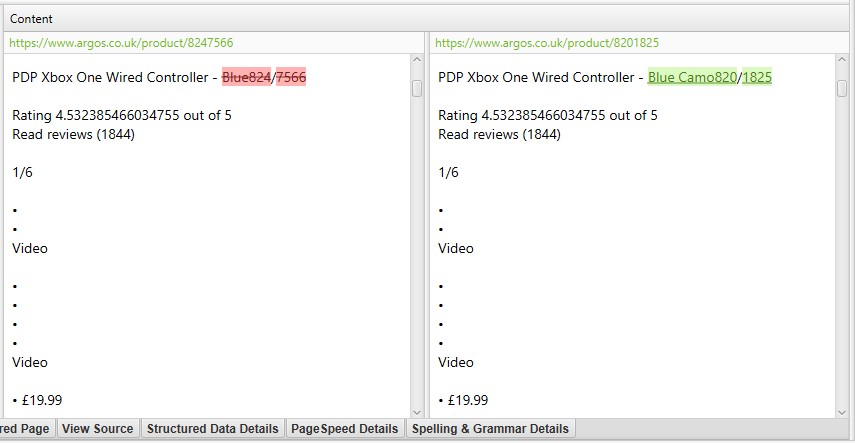
Se nella scheda Dettagli duplicati è presente un contenuto duplicato che non si desidera far parte dell’analisi dei contenuti duplicati, escludere o includere elementi HTML, classi o ID (come evidenziato al punto 2), & eseguire nuovamente l’analisi di scansione.
8) Duplicati di esportazione di massa
Sia i duplicati esatti che quelli vicini possono essere esportati in blocco tramite le esportazioni “Bulk Export > Content > Exact Duplicates” e “Near Duplicates”.

Suggerimento finale! Raffina soglia di similarità & Area contenuto,& Re-run Crawl Analysis
Post-crawl è possibile regolare sia la soglia di similarità quasi duplicata, sia l’area contenuto utilizzata per l’analisi quasi duplicata.
È quindi possibile eseguire nuovamente l’analisi di scansione per trovare contenuti più o meno simili, senza eseguire nuovamente la scansione del sito web.
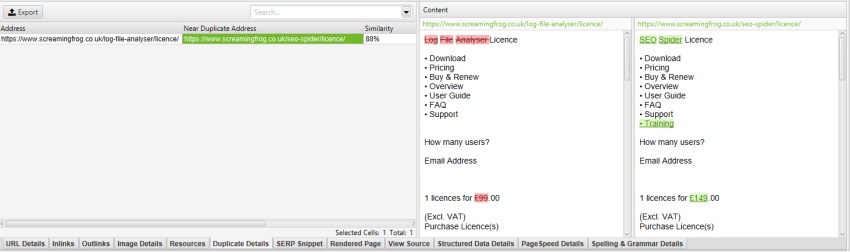
Come descritto in precedenza, il sito web Screaming Frog ha un menu mobile al di fuori dell’elemento nav, che è incluso nell’analisi dei contenuti per impostazione predefinita. Il menu mobile può essere visualizzato nell’anteprima del contenuto della scheda “dettagli duplicati”.
Escludendo l’area ‘mobile-menu__dropdown’ nella casella ‘Exclude Classes’ sotto ‘Config > Content >’, il menu mobile viene rimosso dall’anteprima del contenuto e dall’analisi near-duplicate.
Questo può davvero aiutare quando si ottimizza l’identificazione dei contenuti quasi duplicati nelle aree dei contenuti principali, senza la necessità di eseguire nuovamente la scansione.
Sommario
La guida di cui sopra dovrebbe illustrare come utilizzare il SEO Spider come un duplicato content checker per il tuo sito web. Per ottenere risultati più accurati, affinare l’area del contenuto per l’analisi e regolare la soglia per diversi gruppi di pagine.
Si prega di leggere anche il nostro Urlando rana SEO Spider FAQ e guida completa per l’utente per ulteriori informazioni sullo strumento.
Se avete ulteriori domande, commenti o suggerimenti per migliorare lo strumento di contenuti duplicati nel SEO Spider poi basta mettersi in contatto tramite il supporto.